mirror of
https://github.com/huggingface/transformers.git
synced 2025-07-05 13:50:13 +06:00
* Rename index.mdx to index.md * With saved modifs * Address review comment * Treat all files * .mdx -> .md * Remove special char * Update utils/tests_fetcher.py Co-authored-by: Lysandre Debut <lysandre.debut@reseau.eseo.fr> --------- Co-authored-by: Lysandre Debut <lysandre.debut@reseau.eseo.fr>
2.3 KiB
2.3 KiB
Optimization
The .optimization module provides:
- an optimizer with weight decay fixed that can be used to fine-tuned models, and
- several schedules in the form of schedule objects that inherit from
_LRSchedule: - a gradient accumulation class to accumulate the gradients of multiple batches
AdamW (PyTorch)
autodoc AdamW
AdaFactor (PyTorch)
autodoc Adafactor
AdamWeightDecay (TensorFlow)
autodoc AdamWeightDecay
autodoc create_optimizer
Schedules
Learning Rate Schedules (Pytorch)
autodoc SchedulerType
autodoc get_scheduler
autodoc get_constant_schedule
autodoc get_constant_schedule_with_warmup
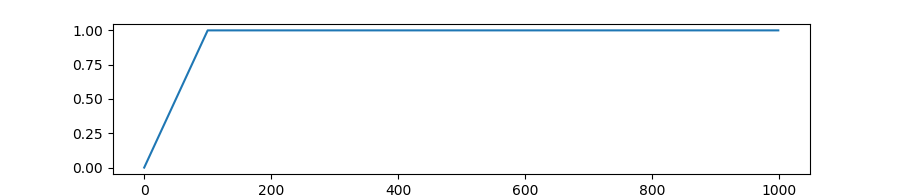
autodoc get_cosine_schedule_with_warmup
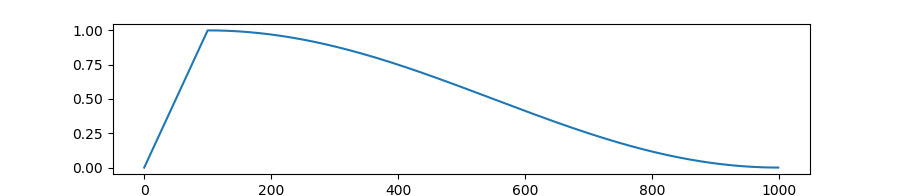
autodoc get_cosine_with_hard_restarts_schedule_with_warmup
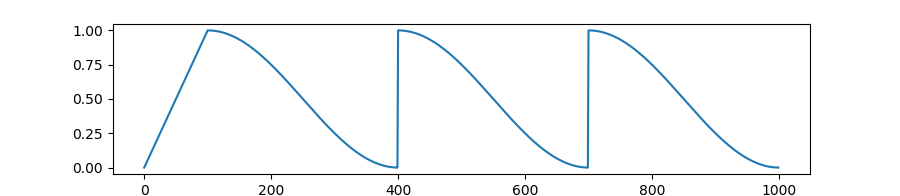
autodoc get_linear_schedule_with_warmup
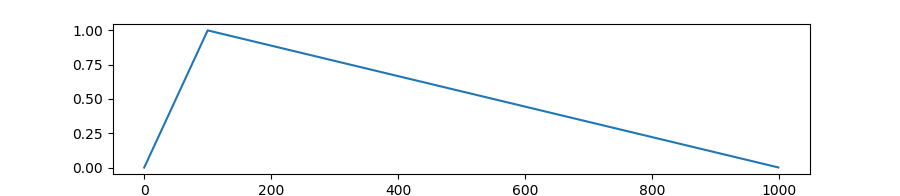
autodoc get_polynomial_decay_schedule_with_warmup
autodoc get_inverse_sqrt_schedule
Warmup (TensorFlow)
autodoc WarmUp
Gradient Strategies
GradientAccumulator (TensorFlow)
autodoc GradientAccumulator