* add sdpa to OPT
* chore: remove redundant whitespace in OPTDecoder class
* fixup
* bug fix
* add sdpa and attention generate test
* fixup
* Refactor OPTAttention forward method for improved readability and maintainability
* undo refactor for _shape and key,val states
* add OPT to doc, fixup didn't find it for some reason
* change order
* change default attn_implemntation in testing to eager
* [run-slow] opt
* change test_eager_matches_sdpa_generate to the one llama
* Update default attention implementation in testing common
* [run-slow] opt
* remove uneeded print
* [run-slow] opt
* refactor model testers to have attn_implementation="eager"
* [run-slow] opt
* convert test_eager_matches_sdpa_generate to opt-350M
* bug fix when creating mask for opt
* [run-slow] opt
* if layer head mask default to eager
* if head mask is not none fall to eager
* [run-slow] opt
* Update src/transformers/models/opt/modeling_opt.py
Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com>
* Clean up Unpack imports (#33631)
clean up Unpack imports
* Fix DPT /Dinov2 sdpa regression on main (#33660)
* fallback to eager if output attentions.
* fix copies
* handle dependency errors in check_imports (#33622)
* handle dependency errors in check_imports
* change log level to warning
* add back self.max_position_embeddings = config.max_position_embeddings (#33550)
* add back self.max_position_embeddings = config.max_position_embeddings
* fix-copies
* Fix Llava conversion for LlavaQwen2ForCausalLM with Clip vision tower (#33613)
fix llavaqwen2 model conversion
* Uniformize kwargs for Udop processor and update docs (#33628)
* Add optional kwargs and uniformize udop
* cleanup Unpack
* nit Udop
* Generation: deprecate `PreTrainedModel` inheriting from `GenerationMixin` (#33203)
* Enable BNB multi-backend support (#31098)
* enable cpu bnb path
* fix style
* fix code style
* fix 4 bit path
* Update src/transformers/utils/import_utils.py
Co-authored-by: Aarni Koskela <akx@iki.fi>
* add multi backend refactor tests
* fix style
* tweak 4bit quantizer + fix corresponding tests
* tweak 8bit quantizer + *try* fixing corresponding tests
* fix dequant bnb 8bit
* account for Intel CPU in variability of expected outputs
* enable cpu and xpu device map
* further tweaks to account for Intel CPU
* fix autocast to work with both cpu + cuda
* fix comments
* fix comments
* switch to testing_utils.torch_device
* allow for xpu in multi-gpu tests
* fix tests 4bit for CPU NF4
* fix bug with is_torch_xpu_available needing to be called as func
* avoid issue where test reports attr err due to other failure
* fix formatting
* fix typo from resolving of merge conflict
* polish based on last PR review
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
* fix CI
* Update src/transformers/integrations/integration_utils.py
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
* Update src/transformers/integrations/integration_utils.py
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
* fix error log
* fix error msg
* add \n in error log
* make quality
* rm bnb cuda restriction in doc
* cpu model don't need dispatch
* fix doc
* fix style
* check cuda avaliable in testing
* fix tests
* Update docs/source/en/model_doc/chameleon.md
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
* Update docs/source/en/model_doc/llava_next.md
Co-authored-by: Aarni Koskela <akx@iki.fi>
* Update tests/quantization/bnb/test_4bit.py
Co-authored-by: Aarni Koskela <akx@iki.fi>
* Update tests/quantization/bnb/test_4bit.py
Co-authored-by: Aarni Koskela <akx@iki.fi>
* fix doc
* fix check multibackends
* fix import sort
* remove check torch in bnb
* docs: update bitsandbytes references with multi-backend info
* docs: fix small mistakes in bnb paragraph
* run formatting
* reveret bnb check
* move bnb multi-backend check to import_utils
* Update src/transformers/utils/import_utils.py
Co-authored-by: Aarni Koskela <akx@iki.fi>
* fix bnb check
* minor fix for bnb
* check lib first
* fix code style
* Revert "run formatting"
This reverts commit ac108c6d6b.
* fix format
* give warning when bnb version is low and no cuda found]
* fix device assignment check to be multi-device capable
* address akx feedback on get_avlbl_dev fn
* revert partially, as we don't want the function that public, as docs would be too much (enforced)
---------
Co-authored-by: Aarni Koskela <akx@iki.fi>
Co-authored-by: Titus von Koeller <9048635+Titus-von-Koeller@users.noreply.github.com>
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
* Fix error string after refactoring into get_chat_template (#33652)
* Fix error string after refactoring into get_chat_template
* Take suggestion from CR
Co-authored-by: Matt <Rocketknight1@users.noreply.github.com>
---------
Co-authored-by: Matt <Rocketknight1@users.noreply.github.com>
* uniformize git processor (#33668)
* uniformize git processor
* update doctring
* Modular `transformers`: modularity and inheritance for new model additions (#33248)
* update exampel
* update
* push the converted diff files for testing and ci
* correct one example
* fix class attributes and docstring
* nits
* oups
* fixed config!
* update
* nitd
* class attributes are not matched against the other, this is missing
* fixed overwriting self.xxx now onto the attributes I think
* partial fix, now order with docstring
* fix docstring order?
* more fixes
* update
* fix missing docstrings!
* examples don't all work yet
* fixup
* nit
* updated
* hick
* update
* delete
* update
* update
* update
* fix
* all default
* no local import
* fix more diff
* some fix related to "safe imports"
* push fixed
* add helper!
* style
* add a check
* all by default
* add the
* update
* FINALLY!
* nit
* fix config dependencies
* man that is it
* fix fix
* update diffs
* fix the last issue
* re-default to all
* alll the fixes
* nice
* fix properties vs setter
* fixup
* updates
* update dependencies
* make sure to install what needs to be installed
* fixup
* quick fix for now
* fix!
* fixup
* update
* update
* updates
* whitespaces
* nit
* fix
* simplify everything, and make it file agnostic (should work for image processors)
* style
* finish fixing all import issues
* fixup
* empty modeling should not be written!
* Add logic to find who depends on what
* update
* cleanup
* update
* update gemma to support positions
* some small nits
* this is the correct docstring for gemma2
* fix merging of docstrings
* update
* fixup
* update
* take doc into account
* styling
* update
* fix hidden activation
* more fixes
* final fixes!
* fixup
* fixup instruct blip video
* update
* fix bugs
* align gemma2 with the rest as well
* updats
* revert
* update
* more reversiom
* grind
* more
* arf
* update
* order will matter
* finish del stuff
* update
* rename to modular
* fixup
* nits
* update makefile
* fixup
* update order of the checks!
* fix
* fix docstring that has a call inside
* fiix conversion check
* style
* add some initial documentation
* update
* update doc
* some fixup
* updates
* yups
* Mostly todo gimme a minut
* update
* fixup
* revert some stuff
* Review docs for the modular transformers (#33472)
Docs
* good update
* fixup
* mmm current updates lead to this code
* okay, this fixes it
* cool
* fixes
* update
* nit
* updates
* nits
* fix doc
* update
* revert bad changes
* update
* updates
* proper update
* update
* update?
* up
* update
* cool
* nits
* nits
* bon bon
* fix
* ?
* minimise changes
* update
* update
* update
* updates?
* fixed gemma2
* kind of a hack
* nits
* update
* remove `diffs` in favor of `modular`
* fix make fix copies
---------
Co-authored-by: Lysandre Debut <hi@lysand.re>
* Fix CIs post merging modular transformers (#33681)
update
* Fixed docstring for cohere model regarding unavailability of prune_he… (#33253)
* Fixed docstring for cohere model regarding unavailability of prune_head() methods
The docstring mentions that cohere model supports prune_heads() methods. I have fixed the docstring by explicitly mentioning that it doesn't support that functionality.
* Update src/transformers/models/cohere/modeling_cohere.py
---------
Co-authored-by: Lysandre Debut <hi@lysand.re>
* Generation tests: update imagegpt input name, remove unused functions (#33663)
* Improve Error Messaging for Flash Attention 2 on CPU (#33655)
Update flash-attn error message on CPU
Rebased to latest branch
* Gemma2: fix config initialization (`cache_implementation`) (#33684)
* Fix ByteLevel alphabet missing when Sequence pretokenizer is used (#33556)
* Fix ByteLevel alphabet missing when Sequence pretokenizer is used
* Fixed formatting with `ruff`.
* Uniformize kwargs for image-text-to-text processors (#32544)
* uniformize FUYU processor kwargs
* Uniformize instructblip processor kwargs
* Fix processor kwargs and tests Fuyu, InstructBlip, Kosmos2
* Uniformize llava_next processor
* Fix save_load test for processor with chat_template only as extra init args
* Fix import Unpack
* Fix Fuyu Processor import
* Fix FuyuProcessor import
* Fix FuyuProcessor
* Add defaults for specific kwargs kosmos2
* Fix Udop to return BatchFeature instead of BatchEncoding and uniformize kwargs
* Add tests processor Udop
* remove Copied from in processing Udop as change of input orders caused by BatchEncoding -> BatchFeature
* Fix overwrite tests kwargs processors
* Add warnings and BC for changes in processor inputs order, change docs, add BC for text_pair as arg for Udop
* Fix processing test fuyu
* remove unnecessary pad_token check in instructblip ProcessorTest
* Fix BC tests and cleanup
* FIx imports fuyu
* Uniformize Pix2Struct
* Fix wrong name for FuyuProcessorKwargs
* Fix slow tests reversed inputs align fuyu llava-next, change udop warning
* Fix wrong logging import udop
* Add check images text input order
* Fix copies
* change text pair handling when positional arg
* rebase on main, fix imports in test_processing_common
* remove optional args and udop uniformization from this PR
* fix failing tests
* remove unnecessary test, fix processing utils and test processing common
* cleanup Unpack
* cleanup
* fix conflict grounding dino
* 🚨🚨 Setting default behavior of assisted decoding (#33657)
* tests: fix pytorch tensor placement errors (#33485)
This commit fixes the following errors:
* Fix "expected all tensors to be on the same device" error
* Fix "can't convert device type tensor to numpy"
According to pytorch documentation torch.Tensor.numpy(force=False)
performs conversion only if tensor is on CPU (plus few other restrictions)
which is not the case. For our case we need force=True since we just
need a data and don't care about tensors coherency.
Fixes: #33517
See: https://pytorch.org/docs/2.4/generated/torch.Tensor.numpy.html
Signed-off-by: Dmitry Rogozhkin <dmitry.v.rogozhkin@intel.com>
* bump tokenizers, fix added tokens fast (#32535)
* update based on tokenizers release
* update
* nits
* update
* revert re addition
* don't break that yet
* fmt
* revert unwanted
* update tokenizers version
* update dep table
* update
* update in conversion script as well
* some fix
* revert
* fully revert
* fix training
* remove set trace
* fixup
* update
* update
* [Pixtral] Improve docs, rename model (#33491)
* Improve docs, rename model
* Fix style
* Update repo id
* fix code quality after merge
* HFQuantizer implementation for compressed-tensors library (#31704)
* Add compressed-tensors HFQuantizer implementation
* flag serializable as False
* run
* revive lines deleted by ruff
* fixes to load+save from sparseml, edit config to quantization_config, and load back
* address satrat comment
* compressed_tensors to compressed-tensors and revert back is_serializable
* rename quant_method from sparseml to compressed-tensors
* tests
* edit tests
* clean up tests
* make style
* cleanup
* cleanup
* add test skip for when compressed tensors is not installed
* remove pydantic import + style
* delay torch import in test
* initial docs
* update main init for compressed tensors config
* make fix-copies
* docstring
* remove fill_docstring
* Apply suggestions from code review
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
* review comments
* review comments
* comments - suppress warnings on state dict load, tests, fixes
* bug-fix - remove unnecessary call to apply quant lifecycle
* run_compressed compatability
* revert changes not needed for compression
* no longer need unexpected keys fn
* unexpected keys not needed either
* Apply suggestions from code review
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
* add to_diff_dict
* update docs and expand testing
* Update _toctree.yml with compressed-tensors
* Update src/transformers/utils/quantization_config.py
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
* update doc
* add note about saving a loaded model
---------
Co-authored-by: George Ohashi <george@neuralmagic.com>
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
Co-authored-by: Sara Adkins <sara@neuralmagic.com>
Co-authored-by: Sara Adkins <sara.adkins65@gmail.com>
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
Co-authored-by: Dipika Sikka <ds3822@columbia.edu>
Co-authored-by: Dipika <dipikasikka1@gmail.com>
* update model card for opt
* add batch size to inference table
* [slow-run] opt
* [run-slow] opt
---------
Signed-off-by: Dmitry Rogozhkin <dmitry.v.rogozhkin@intel.com>
Co-authored-by: Avishai Elmakies <avishai.elma@cs.huji.ac.il>
Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com>
Co-authored-by: Pablo Montalvo <39954772+molbap@users.noreply.github.com>
Co-authored-by: chengchengpei <5881383+chengchengpei@users.noreply.github.com>
Co-authored-by: Isotr0py <2037008807@qq.com>
Co-authored-by: Yoni Gozlan <74535834+yonigozlan@users.noreply.github.com>
Co-authored-by: Joao Gante <joaofranciscocardosogante@gmail.com>
Co-authored-by: jiqing-feng <jiqing.feng@intel.com>
Co-authored-by: Aarni Koskela <akx@iki.fi>
Co-authored-by: Titus von Koeller <9048635+Titus-von-Koeller@users.noreply.github.com>
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
Co-authored-by: Tibor Reiss <75096465+tibor-reiss@users.noreply.github.com>
Co-authored-by: Matt <Rocketknight1@users.noreply.github.com>
Co-authored-by: Lysandre Debut <hi@lysand.re>
Co-authored-by: Muhammad Naufil <m.naufil1@gmail.com>
Co-authored-by: sizhky <yyeshr@gmail.com>
Co-authored-by: Umar Butler <umar@umar.au>
Co-authored-by: Jonathan Mamou <jonathan.mamou@intel.com>
Co-authored-by: Dmitry Rogozhkin <dmitry.v.rogozhkin@intel.com>
Co-authored-by: NielsRogge <48327001+NielsRogge@users.noreply.github.com>
Co-authored-by: Arthur Zucker <arthur.zucker@gmail.com>
Co-authored-by: Benjamin Fineran <bfineran@users.noreply.github.com>
Co-authored-by: George Ohashi <george@neuralmagic.com>
Co-authored-by: Sara Adkins <sara@neuralmagic.com>
Co-authored-by: Sara Adkins <sara.adkins65@gmail.com>
Co-authored-by: Dipika Sikka <ds3822@columbia.edu>
Co-authored-by: Dipika <dipikasikka1@gmail.com>
31 KiB
GPU inference
GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you'll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia and AMD GPUs.
The majority of the optimizations described here also apply to multi-GPU setups!
FlashAttention-2
FlashAttention-2 is experimental and may change considerably in future versions.
FlashAttention-2 is a faster and more efficient implementation of the standard attention mechanism that can significantly speedup inference by:
- additionally parallelizing the attention computation over sequence length
- partitioning the work between GPU threads to reduce communication and shared memory reads/writes between them
FlashAttention-2 is currently supported for the following architectures:
- Bark
- Bart
- Chameleon
- CLIP
- Cohere
- Dbrx
- DistilBert
- Gemma
- Gemma2
- GPT2
- GPTBigCode
- GPTNeo
- GPTNeoX
- GPT-J
- Granite
- GraniteMoe
- Idefics2
- Idefics3
- Falcon
- JetMoe
- Jamba
- Llama
- Llava
- Llava-NeXT
- Llava-NeXT-Video
- LLaVA-Onevision
- Mimi
- VipLlava
- VideoLlava
- M2M100
- MBart
- Mistral
- Mixtral
- Musicgen
- MusicGen Melody
- Nemotron
- NLLB
- OLMo
- OLMoE
- OPT
- Phi
- Phi3
- PhiMoE
- StableLm
- Starcoder2
- Qwen2
- Qwen2Audio
- Qwen2MoE
- Qwen2VL
- Whisper
- Wav2Vec2
- Hubert
- data2vec_audio
- Sew
- SigLIP
- UniSpeech
- unispeech_sat
You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
Before you begin, make sure you have FlashAttention-2 installed.
pip install flash-attn --no-build-isolation
We strongly suggest referring to the detailed installation instructions to learn more about supported hardware and data types!
FlashAttention-2 is also supported on AMD GPUs and current support is limited to Instinct MI210, Instinct MI250 and Instinct MI300. We strongly suggest using this Dockerfile to use FlashAttention-2 on AMD GPUs.
To enable FlashAttention-2, pass the argument attn_implementation="flash_attention_2" to [~AutoModelForCausalLM.from_pretrained]:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
FlashAttention-2 can only be used when the model's dtype is fp16 or bf16. Make sure to cast your model to the appropriate dtype and load them on a supported device before using FlashAttention-2.
You can also set use_flash_attention_2=True to enable FlashAttention-2 but it is deprecated in favor of attn_implementation="flash_attention_2".
FlashAttention-2 can be combined with other optimization techniques like quantization to further speedup inference. For example, you can combine FlashAttention-2 with 8-bit or 4-bit quantization:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# load in 8bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
attn_implementation="flash_attention_2",
)
# load in 4bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2",
)
Expected speedups
You can benefit from considerable speedups for inference, especially for inputs with long sequences. However, since FlashAttention-2 does not support computing attention scores with padding tokens, you must manually pad/unpad the attention scores for batched inference when the sequence contains padding tokens. This leads to a significant slowdown for batched generations with padding tokens.
To overcome this, you should use FlashAttention-2 without padding tokens in the sequence during training (by packing a dataset or concatenating sequences until reaching the maximum sequence length).
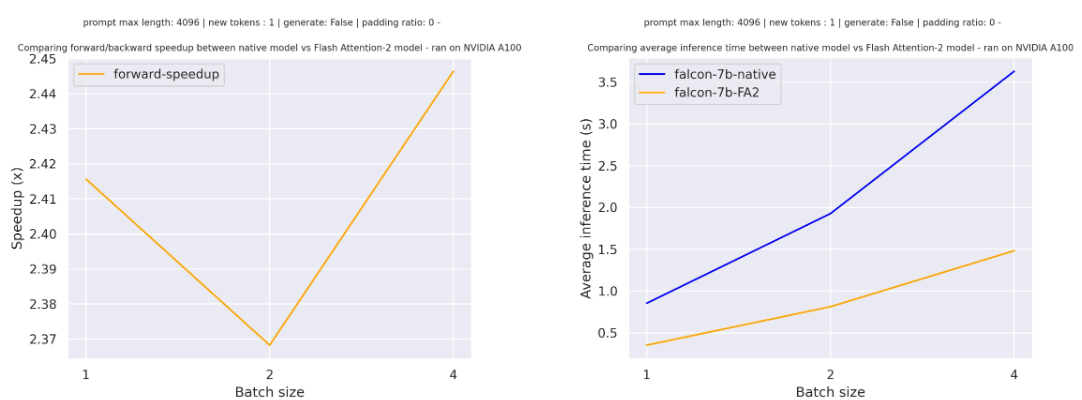
For a single forward pass on tiiuae/falcon-7b with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
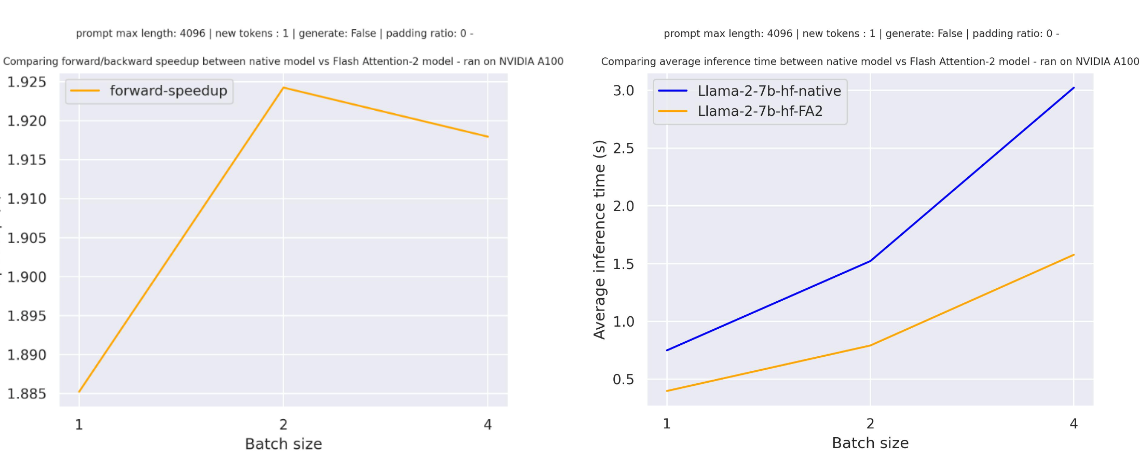
For a single forward pass on meta-llama/Llama-7b-hf with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
For sequences with padding tokens (generating with padding tokens), you need to unpad/pad the input sequences to correctly compute the attention scores. With a relatively small sequence length, a single forward pass creates overhead leading to a small speedup (in the example below, 30% of the input is filled with padding tokens):
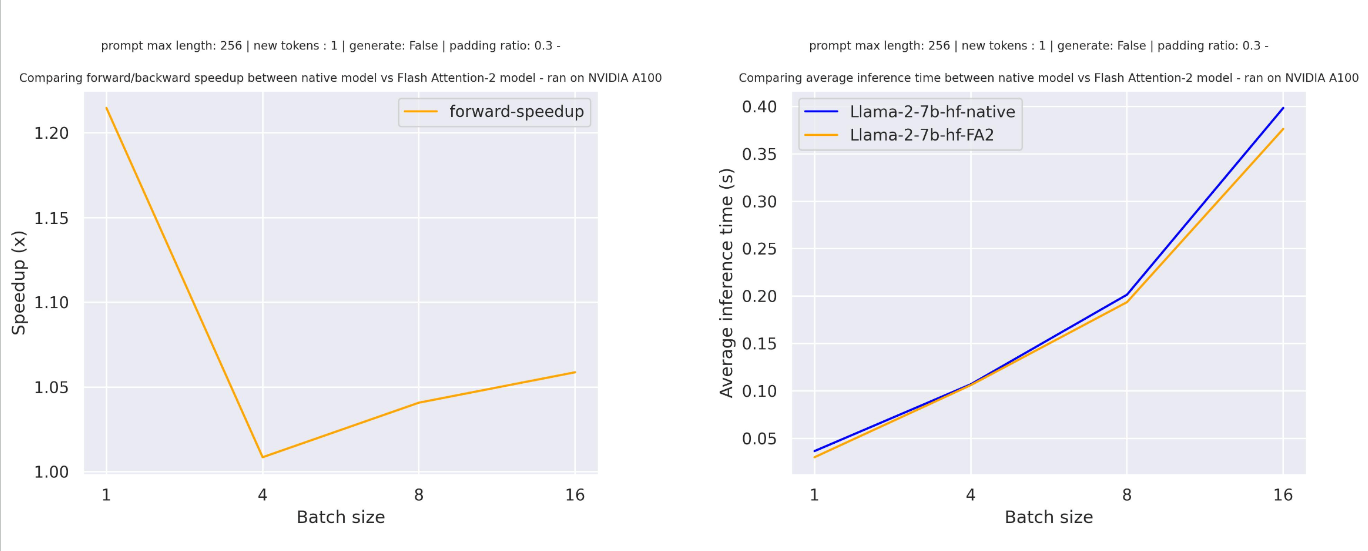
But for larger sequence lengths, you can expect even more speedup benefits:
FlashAttention is more memory efficient, meaning you can train on much larger sequence lengths without running into out-of-memory issues. You can potentially reduce memory usage up to 20x for larger sequence lengths. Take a look at the flash-attention repository for more details.

PyTorch scaled dot product attention
PyTorch's torch.nn.functional.scaled_dot_product_attention (SDPA) can also call FlashAttention and memory-efficient attention kernels under the hood. SDPA support is currently being added natively in Transformers and is used by default for torch>=2.1.1 when an implementation is available. You may also set attn_implementation="sdpa" in from_pretrained() to explicitly request SDPA to be used.
For now, Transformers supports SDPA inference and training for the following architectures:
- Albert
- Audio Spectrogram Transformer
- Bart
- Bert
- BioGpt
- CamemBERT
- Chameleon
- CLIP
- Cohere
- data2vec_audio
- Dbrx
- DeiT
- Dinov2
- DistilBert
- Dpr
- Falcon
- Gemma
- Gemma2
- GPT2
- GPTBigCode
- GPTNeoX
- Hubert
- Idefics
- Granite
- GraniteMoe
- JetMoe
- Jamba
- Llama
- LLaVA-Onevision
- M2M100
- Mimi
- Mistral
- Mllama
- Mixtral
- Musicgen
- MusicGen Melody
- NLLB
- OLMo
- OLMoE
- OPT
- PaliGemma
- Phi
- Phi3
- PhiMoE
- Idefics
- Whisper
- mBart
- Mistral
- Mixtral
- StableLm
- Starcoder2
- Qwen2
- Qwen2Audio
- Qwen2MoE
- RoBERTa
- Sew
- SigLIP
- StableLm
- Starcoder2
- UniSpeech
- unispeech_sat
- RoBERTa
- Qwen2VL
- Musicgen
- MusicGen Melody
- Nemotron
- ViT
- ViTHybrid
- ViTMAE
- ViTMSN
- VideoMAE
- wav2vec2
- Whisper
- XLM-RoBERTa
- XLM-RoBERTa-XL
- YOLOS
FlashAttention can only be used for models with the fp16 or bf16 torch type, so make sure to cast your model to the appropriate type first. The memory-efficient attention backend is able to handle fp32 models.
SDPA does not support certain sets of attention parameters, such as head_mask and output_attentions=True.
In that case, you should see a warning message and we will fall back to the (slower) eager implementation.
By default, SDPA selects the most performant kernel available but you can check whether a backend is available in a given setting (hardware, problem size) with torch.backends.cuda.sdp_kernel as a context manager:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16).to("cuda")
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
If you see a bug with the traceback below, try using the nightly version of PyTorch which may have broader coverage for FlashAttention:
RuntimeError: No available kernel. Aborting execution.
# install PyTorch nightly
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
BetterTransformer
Some BetterTransformer features are being upstreamed to Transformers with default support for native torch.nn.scaled_dot_product_attention. BetterTransformer still has a wider coverage than the Transformers SDPA integration, but you can expect more and more architectures to natively support SDPA in Transformers.
Check out our benchmarks with BetterTransformer and scaled dot product attention in the Out of the box acceleration and memory savings of 🤗 decoder models with PyTorch 2.0 and learn more about the fastpath execution in the BetterTransformer blog post.
BetterTransformer accelerates inference with its fastpath (native PyTorch specialized implementation of Transformer functions) execution. The two optimizations in the fastpath execution are:
- fusion, which combines multiple sequential operations into a single "kernel" to reduce the number of computation steps
- skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
BetterTransformer also converts all attention operations to use the more memory-efficient scaled dot product attention (SDPA), and it calls optimized kernels like FlashAttention under the hood.
Before you start, make sure you have 🤗 Optimum installed.
Then you can enable BetterTransformer with the [PreTrainedModel.to_bettertransformer] method:
model = model.to_bettertransformer()
You can return the original Transformers model with the [~PreTrainedModel.reverse_bettertransformer] method. You should use this before saving your model to use the canonical Transformers modeling:
model = model.reverse_bettertransformer()
model.save_pretrained("saved_model")
bitsandbytes
bitsandbytes is a quantization library that includes support for 4-bit and 8-bit quantization. Quantization reduces your model size compared to its native full precision version, making it easier to fit large models onto GPUs with limited memory.
Make sure you have bitsandbytes and 🤗 Accelerate installed:
# these versions support 8-bit and 4-bit
pip install bitsandbytes>=0.39.0 accelerate>=0.20.0
# install Transformers
pip install transformers
4-bit
To load a model in 4-bit for inference, use the load_in_4bit parameter. The device_map parameter is optional, but we recommend setting it to "auto" to allow 🤗 Accelerate to automatically and efficiently allocate the model given the available resources in the environment.
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)
To load a model in 4-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 600MB of memory to the first GPU and 1GB of memory to the second GPU:
max_memory_mapping = {0: "600MB", 1: "1GB"}
model_name = "bigscience/bloom-3b"
model_4bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_4bit=True, max_memory=max_memory_mapping
)
8-bit
If you're curious and interested in learning more about the concepts underlying 8-bit quantization, read the Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes blog post.
To load a model in 8-bit for inference, use the load_in_8bit parameter. The device_map parameter is optional, but we recommend setting it to "auto" to allow 🤗 Accelerate to automatically and efficiently allocate the model given the available resources in the environment:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
If you're loading a model in 8-bit for text generation, you should use the [~transformers.GenerationMixin.generate] method instead of the [Pipeline] function which is not optimized for 8-bit models and will be slower. Some sampling strategies, like nucleus sampling, are also not supported by the [Pipeline] for 8-bit models. You should also place all inputs on the same device as the model:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_name = "bigscience/bloom-2b5"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
prompt = "Hello, my llama is cute"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(**inputs)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
To load a model in 4-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 1GB of memory to the first GPU and 2GB of memory to the second GPU:
max_memory_mapping = {0: "1GB", 1: "2GB"}
model_name = "bigscience/bloom-3b"
model_8bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_8bit=True, max_memory=max_memory_mapping
)
Feel free to try running a 11 billion parameter T5 model or the 3 billion parameter BLOOM model for inference on Google Colab's free tier GPUs!
🤗 Optimum
Learn more details about using ORT with 🤗 Optimum in the Accelerated inference on NVIDIA GPUs and Accelerated inference on AMD GPUs guides. This section only provides a brief and simple example.
ONNX Runtime (ORT) is a model accelerator that supports accelerated inference on Nvidia GPUs, and AMD GPUs that use ROCm stack. ORT uses optimization techniques like fusing common operations into a single node and constant folding to reduce the number of computations performed and speedup inference. ORT also places the most computationally intensive operations on the GPU and the rest on the CPU to intelligently distribute the workload between the two devices.
ORT is supported by 🤗 Optimum which can be used in 🤗 Transformers. You'll need to use an [~optimum.onnxruntime.ORTModel] for the task you're solving, and specify the provider parameter which can be set to either CUDAExecutionProvider, ROCMExecutionProvider or TensorrtExecutionProvider. If you want to load a model that was not yet exported to ONNX, you can set export=True to convert your model on-the-fly to the ONNX format:
from optimum.onnxruntime import ORTModelForSequenceClassification
ort_model = ORTModelForSequenceClassification.from_pretrained(
"distilbert/distilbert-base-uncased-finetuned-sst-2-english",
export=True,
provider="CUDAExecutionProvider",
)
Now you're free to use the model for inference:
from optimum.pipelines import pipeline
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased-finetuned-sst-2-english")
pipeline = pipeline(task="text-classification", model=ort_model, tokenizer=tokenizer, device="cuda:0")
result = pipeline("Both the music and visual were astounding, not to mention the actors performance.")
Combine optimizations
It is often possible to combine several of the optimization techniques described above to get the best inference performance possible for your model. For example, you can load a model in 4-bit, and then enable BetterTransformer with FlashAttention:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# load model in 4-bit
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
# enable BetterTransformer
model = model.to_bettertransformer()
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
# enable FlashAttention
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))