* direct copy from llama work * mistral modules forward pass working * flax mistral forward pass with sliding window * added tests * added layer collection approach * Revert "added layer collection approach" This reverts commit0e2905bf22. * Revert "Revert "added layer collection approach"" This reverts commitfb17b6187a. * fixed attention outputs * added mistral to init and auto * fixed import name * fixed layernorm weight dtype * freeze initialized weights * make sure conversion consideres bfloat16 * added backend * added docstrings * added cache * fixed sliding window causal mask * passes cache tests * passed all tests * applied make style * removed commented out code * applied fix-copies ignored other model changes * applied make fix-copies * removed unused functions * passed generation integration test * slow tests pass * fixed slow tests * changed default dtype from jax.numpy.float32 to float32 for docstring check * skip cache test for FlaxMistralForSequenceClassification since if pad_token_id in input_ids it doesn't score previous input_ids * updated checkpoint since from_pt not included * applied black style * removed unused args * Applied styling and fixup * changed checkpoint for doc back * fixed rf after adding it to hf hub * Add dummy ckpt * applied styling * added tokenizer to new ckpt * fixed slice format * fix init and slice * changed ref for placeholder TODO * added copies from Llama * applied styling * applied fix-copies * fixed docs * update weight dtype reconversion for sharded weights * removed Nullable input ids * Removed unnecessary output attentions in Module * added embedding weight initialziation * removed unused past_key_values * fixed deterministic * Fixed RMS Norm and added copied from * removed input_embeds * applied make style * removed nullable input ids from sequence classification model * added copied from GPTJ * added copied from Llama on FlaxMistralDecoderLayer * added copied from to FlaxMistralPreTrainedModel methods * fix test deprecation warning * freeze gpt neox random_params and fix copies * applied make style * fixed doc issue * skipped docstring test to allign # copied from * applied make style * removed FlaxMistralForSequenceClassification * removed unused padding_idx * removed more sequence classification * removed sequence classification * applied styling and consistency * added copied from in tests * removed sequence classification test logic * applied styling * applied make style * removed freeze and fixed copies * undo test change * changed repeat_kv to tile * fixed to key value groups * updated copyright year * split casual_mask * empty to rerun failed pt_flax_equivalence test FlaxWav2Vec2ModelTest * went back to 2023 for tests_pr_documentation_tests * went back to 2024 * changed tile to repeat * applied make style * empty for retry on Wav2Vec2
6.5 KiB
Mistral
Overview
Mistral-7B-v0.1 is Mistral AI's first Large Language Model (LLM).
Model Details
Mistral-7B-v0.1 is a decoder-based LM with the following architectural choices:
- Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
- GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
- Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
We also provide an instruction fine-tuned model: Mistral-7B-Instruct-v0.1 which can be used for chat-based inference.
For more details please read our release blog post
License
Both Mistral-7B-v0.1 and Mistral-7B-Instruct-v0.1 are released under the Apache 2.0 license.
Usage tips
Mistral-7B-v0.1 and Mistral-7B-Instruct-v0.1 can be found on the Huggingface Hub
These ready-to-use checkpoints can be downloaded and used via the HuggingFace Hub:
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> prompt = "My favourite condiment is"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"The expected output"
Raw weights for Mistral-7B-v0.1 and Mistral-7B-Instruct-v0.1 can be downloaded from:
| Model Name | Checkpoint |
|---|---|
Mistral-7B-v0.1 |
Raw Checkpoint |
Mistral-7B-Instruct-v0.1 |
Raw Checkpoint |
To use these raw checkpoints with HuggingFace you can use the convert_mistral_weights_to_hf.py script to convert them to the HuggingFace format:
python src/transformers/models/mistral/convert_mistral_weights_to_hf.py \
--input_dir /path/to/downloaded/mistral/weights --model_size 7B --output_dir /output/path
You can then load the converted model from the output/path:
from transformers import MistralForCausalLM, LlamaTokenizer
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
model = MistralForCausalLM.from_pretrained("/output/path")
Combining Mistral and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
pip install -U flash-attn --no-build-isolation
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. torch.float16)
To load and run a model using Flash Attention 2, refer to the snippet below:
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> prompt = "My favourite condiment is"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"The expected output"
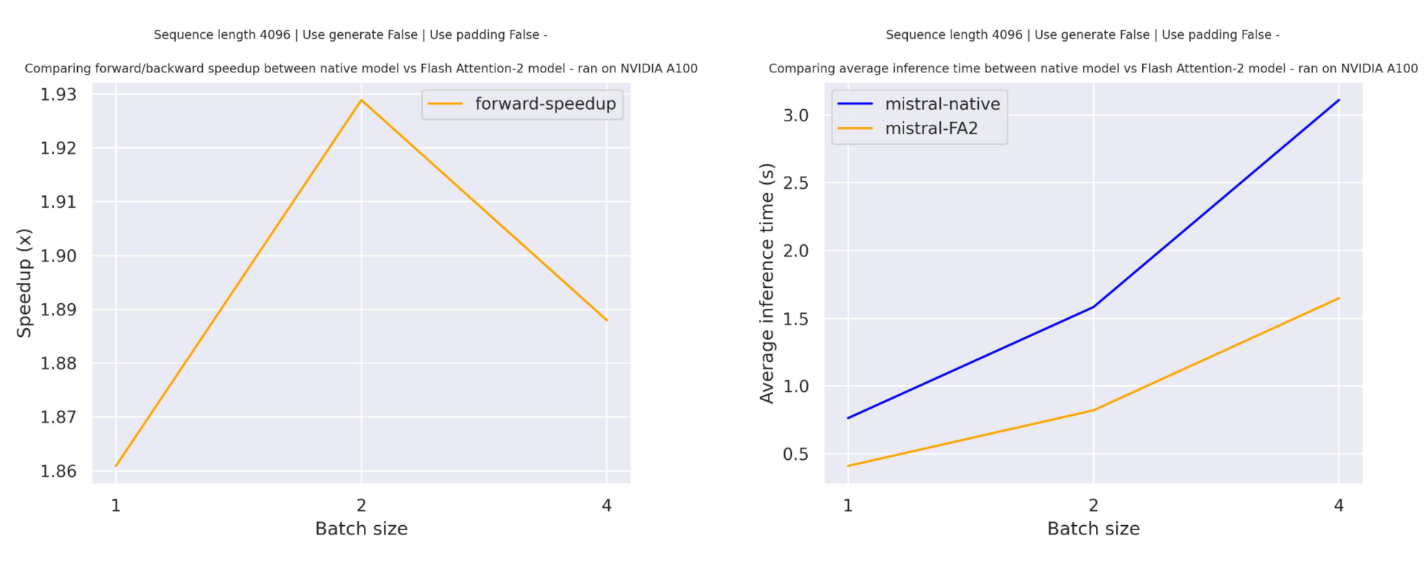
Expected speedups
Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using mistralai/Mistral-7B-v0.1 checkpoint and the Flash Attention 2 version of the model.
Sliding window Attention
The current implementation supports the sliding window attention mechanism and memory efficient cache management.
To enable sliding window attention, just make sure to have a flash-attn version that is compatible with sliding window attention (>=2.3.0).
The Flash Attention-2 model uses also a more memory efficient cache slicing mechanism - as recommended per the official implementation of Mistral model that use rolling cache mechanism we keep the cache size fixed (self.config.sliding_window), support batched generation only for padding_side="left" and use the absolute position of the current token to compute the positional embedding.
The Mistral Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
MistralConfig
autodoc MistralConfig
MistralModel
autodoc MistralModel - forward
MistralForCausalLM
autodoc MistralForCausalLM - forward
MistralForSequenceClassification
autodoc MistralForSequenceClassification - forward
FlaxMistralModel
autodoc FlaxMistralModel - call
FlaxMistralForCausalLM
autodoc FlaxMistralForCausalLM - call