* add sdpa * wip * cleaning * add ref * yet more cleaning * and more :) * wip llama * working llama * add output_attentions=True support * bigcode sdpa support * fixes * gpt-bigcode support, require torch>=2.1.1 * add falcon support * fix conflicts falcon * style * fix attention_mask definition * remove output_attentions from attnmaskconverter * support whisper without removing any Copied from statement * fix mbart default to eager renaming * fix typo in falcon * fix is_causal in SDPA * check is_flash_attn_2_available in the models init as well in case the model is not initialized through from_pretrained * add warnings when falling back on the manual implementation * precise doc * wip replace _flash_attn_enabled by config.attn_implementation * fix typo * add tests * style * add a copy.deepcopy on the config in from_pretrained, as we do not want to modify it inplace * obey to config.attn_implementation if a config is passed in from_pretrained * fix is_torch_sdpa_available when torch is not installed * remove dead code * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/models/bart/modeling_bart.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * remove duplicate pretraining_tp code * add dropout in llama * precise comment on attn_mask * add fmt: off for _unmask_unattended docstring * precise num_masks comment * nuke pretraining_tp in LlamaSDPAAttention following Arthur's suggestion * cleanup modeling_utils * backward compatibility * fix style as requested * style * improve documentation * test pass * style * add _unmask_unattended tests * skip meaningless tests for idefics * hard_check SDPA requirements when specifically requested * standardize the use if XXX_ATTENTION_CLASSES * fix SDPA bug with mem-efficient backend on CUDA when using fp32 * fix test * rely on SDPA is_causal parameter to handle the causal mask in some cases * fix FALCON_ATTENTION_CLASSES * remove _flash_attn_2_enabled occurences * fix test * add OPT to the list of supported flash models * improve test * properly test on different SDPA backends, on different dtypes & properly handle separately the pad tokens in the test * remove remaining _flash_attn_2_enabled occurence * Update src/transformers/modeling_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update docs/source/en/perf_infer_gpu_one.md Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * remove use_attn_implementation * fix docstring & slight bug * make attn_implementation internal (_attn_implementation) * typos * fix tests * deprecate use_flash_attention_2=True * fix test * add back llama that was removed by mistake * fix tests * remove _flash_attn_2_enabled occurences bis * add check & test that passed attn_implementation is valid * fix falcon torchscript export * fix device of mask in tests * add tip about torch.jit.trace and move bt doc below sdpa * fix parameterized.expand order * move tests from test_modeling_attn_mask_utils to test_modeling_utils as a relevant test class is already there * update sdpaattention class with the new cache * Update src/transformers/configuration_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/models/bark/modeling_bark.py * address review comments * WIP torch.jit.trace fix. left: test both eager & sdpa * add test for torch.jit.trace for both eager/sdpa * fix falcon with torch==2.0 that needs to use sdpa * fix doc * hopefully last fix * fix key_value_length that has no default now in mask converter * is it flacky? * fix speculative decoding bug * tests do pass * fix following #27907 --------- Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
5.3 KiB
GPT-NeoX
Overview
We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge, the largest dense autoregressive model that has publicly available weights at the time of submission. In this work, we describe GPT-NeoX-20B's architecture and training and evaluate its performance on a range of language-understanding, mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source the training and evaluation code, as well as the model weights, at https://github.com/EleutherAI/gpt-neox.
Development of the model was led by Sid Black, Stella Biderman and Eric Hallahan, and the model was trained with generous the support of CoreWeave.
GPT-NeoX-20B was trained with fp16, thus it is recommended to initialize the model as follows:
model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b").half().cuda()
GPT-NeoX-20B also has a different tokenizer from the one used in GPT-J-6B and GPT-Neo. The new tokenizer allocates additional tokens to whitespace characters, making the model more suitable for certain tasks like code generation.
Usage example
The generate() method can be used to generate text using GPT Neo model.
>>> from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast
>>> model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b")
>>> tokenizer = GPTNeoXTokenizerFast.from_pretrained("EleutherAI/gpt-neox-20b")
>>> prompt = "GPTNeoX20B is a 20B-parameter autoregressive Transformer model developed by EleutherAI."
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
Using Flash Attention 2
Flash Attention 2 is an faster, optimized version of the model.
Installation
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the official documentation. If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered above.
Next, install the latest version of Flash Attention 2:
pip install -U flash-attn --no-build-isolation
Usage
To load a model using Flash Attention 2, we can pass the argument attn_implementation="flash_attention_2" to .from_pretrained. We'll also load the model in half-precision (e.g. torch.float16), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
>>> from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast
model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
...
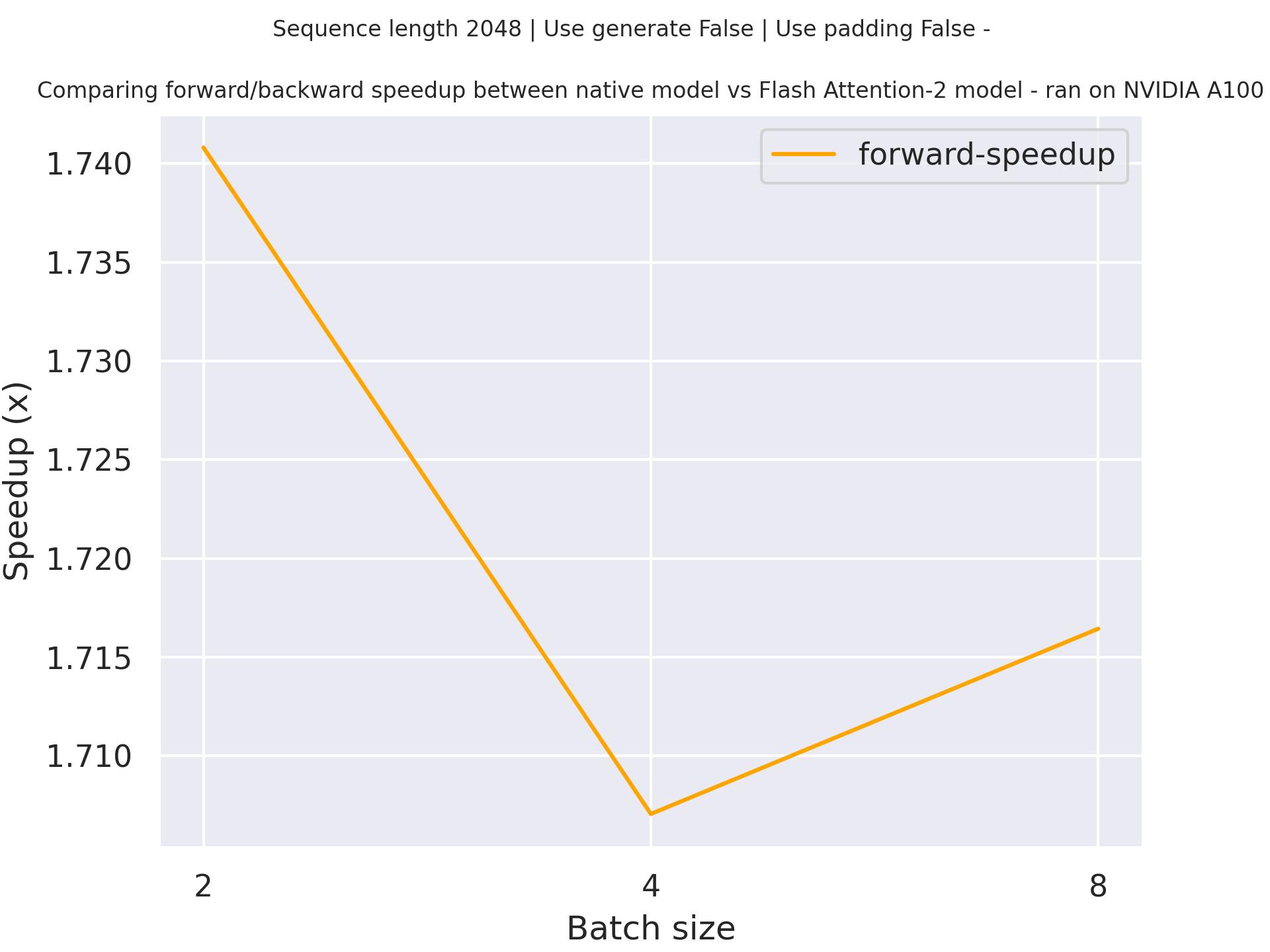
Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using stockmark/gpt-neox-japanese-1.4b checkpoint and the Flash Attention 2 version of the model using a sequence length of 2048.
Resources
GPTNeoXConfig
autodoc GPTNeoXConfig
GPTNeoXTokenizerFast
autodoc GPTNeoXTokenizerFast
GPTNeoXModel
autodoc GPTNeoXModel - forward
GPTNeoXForCausalLM
autodoc GPTNeoXForCausalLM - forward
GPTNeoXForQuestionAnswering
autodoc GPTNeoXForQuestionAnswering - forward
GPTNeoXForSequenceClassification
autodoc GPTNeoXForSequenceClassification - forward
GPTNeoXForTokenClassification
autodoc GPTNeoXForTokenClassification - forward