* Fixed typo: insted to instead * Fixed typo: relase to release * Fixed typo: nighlty to nightly * Fixed typos: versatible, benchamarks, becnhmark to versatile, benchmark, benchmarks * Fixed typo in comment: quantizd to quantized * Fixed typo: architecutre to architecture * Fixed typo: contibution to contribution * Fixed typo: Presequities to Prerequisites * Fixed typo: faste to faster * Fixed typo: extendeding to extending * Fixed typo: segmetantion_maps to segmentation_maps * Fixed typo: Alternativelly to Alternatively * Fixed incorrectly defined variable: output to output_disabled * Fixed typo in library name: tranformers.onnx to transformers.onnx * Fixed missing import: import tensorflow as tf * Fixed incorrectly defined variable: token_tensor to tokens_tensor * Fixed missing import: import torch * Fixed incorrectly defined variable and typo: uromaize to uromanize * Fixed incorrectly defined variable and typo: uromaize to uromanize * Fixed typo in function args: numpy.ndarry to numpy.ndarray * Fixed Inconsistent Library Name: Torchscript to TorchScript * Fixed Inconsistent Class Name: OneformerProcessor to OneFormerProcessor * Fixed Inconsistent Class Named Typo: TFLNetForMultipleChoice to TFXLNetForMultipleChoice * Fixed Inconsistent Library Name Typo: Pytorch to PyTorch * Fixed Inconsistent Function Name Typo: captureWarning to captureWarnings * Fixed Inconsistent Library Name Typo: Pytorch to PyTorch * Fixed Inconsistent Class Name Typo: TrainingArgument to TrainingArguments * Fixed Inconsistent Model Name Typo: Swin2R to Swin2SR * Fixed Inconsistent Model Name Typo: EART to BERT * Fixed Inconsistent Library Name Typo: TensorFLow to TensorFlow * Fixed Broken Link for Speech Emotion Classification with Wav2Vec2 * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed Punctuation: Two commas * Fixed Punctuation: No Space between XLM-R and is * Fixed Punctuation: No Space between [~accelerate.Accelerator.backward] and method * Added backticks to display model.fit() in codeblock * Added backticks to display openai-community/gpt2 in codeblock * Fixed Minor Typo: will to with * Fixed Minor Typo: is to are * Fixed Minor Typo: in to on * Fixed Minor Typo: inhibits to exhibits * Fixed Minor Typo: they need to it needs * Fixed Minor Typo: cast the load the checkpoints To load the checkpoints * Fixed Inconsistent Class Name Typo: TFCamembertForCasualLM to TFCamembertForCausalLM * Fixed typo in attribute name: outputs.last_hidden_states to outputs.last_hidden_state * Added missing verbosity level: fatal * Fixed Minor Typo: take To takes * Fixed Minor Typo: heuristic To heuristics * Fixed Minor Typo: setting To settings * Fixed Minor Typo: Content To Contents * Fixed Minor Typo: millions To million * Fixed Minor Typo: difference To differences * Fixed Minor Typo: while extract To which extracts * Fixed Minor Typo: Hereby To Here * Fixed Minor Typo: addition To additional * Fixed Minor Typo: supports To supported * Fixed Minor Typo: so that benchmark results TO as a consequence, benchmark * Fixed Minor Typo: a To an * Fixed Minor Typo: a To an * Fixed Minor Typo: Chain-of-though To Chain-of-thought
3.3 KiB
Quanto
Try Quanto + transformers with this notebook!
🤗 Quanto library is a versatile pytorch quantization toolkit. The quantization method used is the linear quantization. Quanto provides several unique features such as:
- weights quantization (
float8,int8,int4,int2) - activation quantization (
float8,int8) - modality agnostic (e.g CV,LLM)
- device agnostic (e.g CUDA,MPS,CPU)
- compatibility with
torch.compile - easy to add custom kernel for specific device
- supports quantization aware training
Before you begin, make sure the following libraries are installed:
pip install quanto accelerate transformers
Now you can quantize a model by passing [QuantoConfig] object in the [~PreTrainedModel.from_pretrained] method. This works for any model in any modality, as long as it contains torch.nn.Linear layers.
The integration with transformers only supports weights quantization. For the more complex use case such as activation quantization, calibration and quantization aware training, you should use quanto library instead.
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = QuantoConfig(weights="int8")
quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0", quantization_config=quantization_config)
Note that serialization is not supported yet with transformers but it is coming soon! If you want to save the model, you can use quanto library instead.
Quanto library uses linear quantization algorithm for quantization. Even though this is a basic quantization technique, we get very good results! Have a look at the following benchmark (llama-2-7b on perplexity metric). You can find more benchmarks here
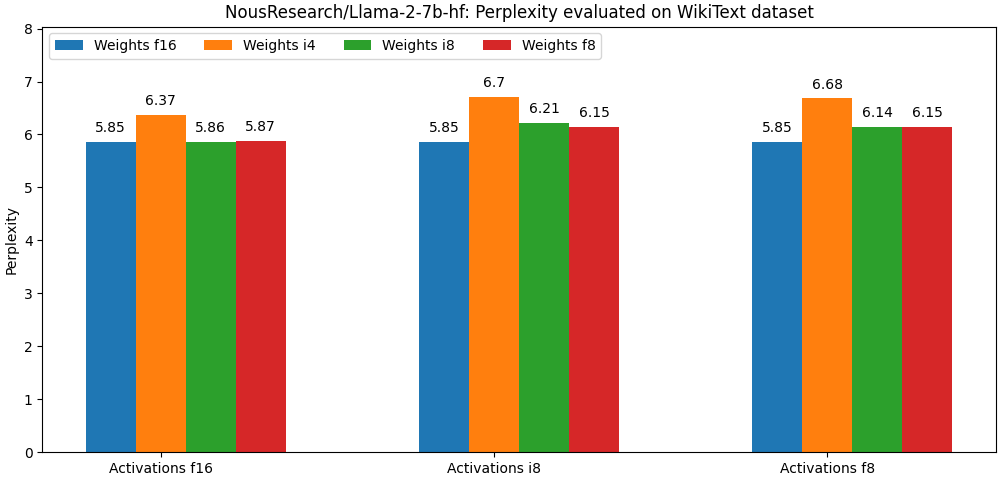
The library is versatile enough to be compatible with most PTQ optimization algorithms. The plan in the future is to integrate the most popular algorithms in the most seamless possible way (AWQ, Smoothquant).