* add colorize_depth and matplotlib availability check * add post_process_depth_estimation for zoedepth + tests * add post_process_depth_estimation for DPT + tests * add post_process_depth_estimation in DepthEstimationPipeline & special case for zoedepth * run `make fixup` * fix import related error on tests * fix more import related errors on test * forgot some `torch` calls in declerations * remove `torch` call in zoedepth tests that caused error * updated docs for depth estimation * small fix for `colorize` input/output types * remove `colorize_depth`, fix various names, remove matplotlib dependency * fix formatting * run fixup * different images for test * update examples in `forward` functions * fixed broken links * fix output types for docs * possible format fix inside `<Tip>` * Readability related updates Co-authored-by: Pavel Iakubovskii <qubvel@gmail.com> * Readability related update * cleanup after merge * refactor `post_process_depth_estimation` to return dict; simplify ZoeDepth's `post_process_depth_estimation` * rewrite dict merging to support python 3.8 --------- Co-authored-by: Pavel Iakubovskii <qubvel@gmail.com>
5.6 KiB
Depth Anything V2
Overview
Depth Anything V2 was introduced in the paper of the same name by Lihe Yang et al. It uses the same architecture as the original Depth Anything model, but uses synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions.
The abstract from the paper is the following:
This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with precise annotations and diverse scenes to facilitate future research.
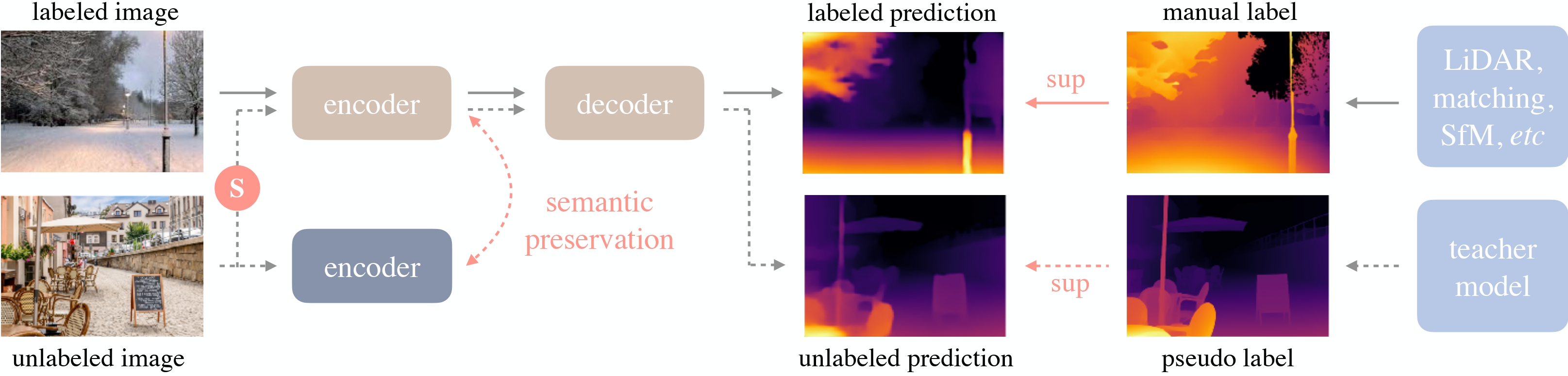
Depth Anything overview. Taken from the original paper.
The Depth Anything models were contributed by nielsr. The original code can be found here.
Usage example
There are 2 main ways to use Depth Anything V2: either using the pipeline API, which abstracts away all the complexity for you, or by using the DepthAnythingForDepthEstimation class yourself.
Pipeline API
The pipeline allows to use the model in a few lines of code:
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> # load pipe
>>> pipe = pipeline(task="depth-estimation", model="depth-anything/Depth-Anything-V2-Small-hf")
>>> # load image
>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # inference
>>> depth = pipe(image)["depth"]
Using the model yourself
If you want to do the pre- and post-processing yourself, here's how to do that:
>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("depth-anything/Depth-Anything-V2-Small-hf")
>>> model = AutoModelForDepthEstimation.from_pretrained("depth-anything/Depth-Anything-V2-Small-hf")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # interpolate to original size and visualize the prediction
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... target_sizes=[(image.height, image.width)],
... )
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
>>> depth = depth.detach().cpu().numpy() * 255
>>> depth = Image.fromarray(depth.astype("uint8"))
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Depth Anything.
- Monocular depth estimation task guide
- Depth Anything V2 demo.
- A notebook showcasing inference with [
DepthAnythingForDepthEstimation] can be found here. 🌎 - Core ML conversion of the
smallvariant for use on Apple Silicon.
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
DepthAnythingConfig
autodoc DepthAnythingConfig
DepthAnythingForDepthEstimation
autodoc DepthAnythingForDepthEstimation - forward