* toctree * not-doctested.txt * collapse sections * feedback * update * rewrite get started sections * fixes * fix * loading models * fix * customize models * share * fix link * contribute part 1 * contribute pt 2 * fix toctree * tokenization pt 1 * Add new model (#32615) * v1 - working version * fix * fix * fix * fix * rename to correct name * fix title * fixup * rename files * fix * add copied from on tests * rename to `FalconMamba` everywhere and fix bugs * fix quantization + accelerate * fix copies * add `torch.compile` support * fix tests * fix tests and add slow tests * copies on config * merge the latest changes * fix tests * add few lines about instruct * Apply suggestions from code review Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * fix * fix tests --------- Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * "to be not" -> "not to be" (#32636) * "to be not" -> "not to be" * Update sam.md * Update trainer.py * Update modeling_utils.py * Update test_modeling_utils.py * Update test_modeling_utils.py * fix hfoption tag * tokenization pt. 2 * image processor * fix toctree * backbones * feature extractor * fix file name * processor * update not-doctested * update * make style * fix toctree * revision * make fixup * fix toctree * fix * make style * fix hfoption tag * pipeline * pipeline gradio * pipeline web server * add pipeline * fix toctree * not-doctested * prompting * llm optims * fix toctree * fixes * cache * text generation * fix * chat pipeline * chat stuff * xla * torch.compile * cpu inference * toctree * gpu inference * agents and tools * gguf/tiktoken * finetune * toctree * trainer * trainer pt 2 * optims * optimizers * accelerate * parallelism * fsdp * update * distributed cpu * hardware training * gpu training * gpu training 2 * peft * distrib debug * deepspeed 1 * deepspeed 2 * chat toctree * quant pt 1 * quant pt 2 * fix toctree * fix * fix * quant pt 3 * quant pt 4 * serialization * torchscript * scripts * tpu * review * model addition timeline * modular * more reviews * reviews * fix toctree * reviews reviews * continue reviews * more reviews * modular transformers * more review * zamba2 * fix * all frameworks * pytorch * supported model frameworks * flashattention * rm check_table * not-doctested.txt * rm check_support_list.py * feedback * updates/feedback * review * feedback * fix * update * feedback * updates * update --------- Co-authored-by: Younes Belkada <49240599+younesbelkada@users.noreply.github.com> Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> Co-authored-by: Quentin Gallouédec <45557362+qgallouedec@users.noreply.github.com>
6.0 KiB
Depth Anything
Overview
The Depth Anything model was proposed in Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao. Depth Anything is based on the DPT architecture, trained on ~62 million images, obtaining state-of-the-art results for both relative and absolute depth estimation.
Depth Anything V2 was released in June 2024. It uses the same architecture as Depth Anything and therefore it is compatible with all code examples and existing workflows. However, it leverages synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions.
The abstract from the paper is the following:
This work presents Depth Anything, a highly practical solution for robust monocular depth estimation. Without pursuing novel technical modules, we aim to build a simple yet powerful foundation model dealing with any images under any circumstances. To this end, we scale up the dataset by designing a data engine to collect and automatically annotate large-scale unlabeled data (~62M), which significantly enlarges the data coverage and thus is able to reduce the generalization error. We investigate two simple yet effective strategies that make data scaling-up promising. First, a more challenging optimization target is created by leveraging data augmentation tools. It compels the model to actively seek extra visual knowledge and acquire robust representations. Second, an auxiliary supervision is developed to enforce the model to inherit rich semantic priors from pre-trained encoders. We evaluate its zero-shot capabilities extensively, including six public datasets and randomly captured photos. It demonstrates impressive generalization ability. Further, through fine-tuning it with metric depth information from NYUv2 and KITTI, new SOTAs are set. Our better depth model also results in a better depth-conditioned ControlNet.
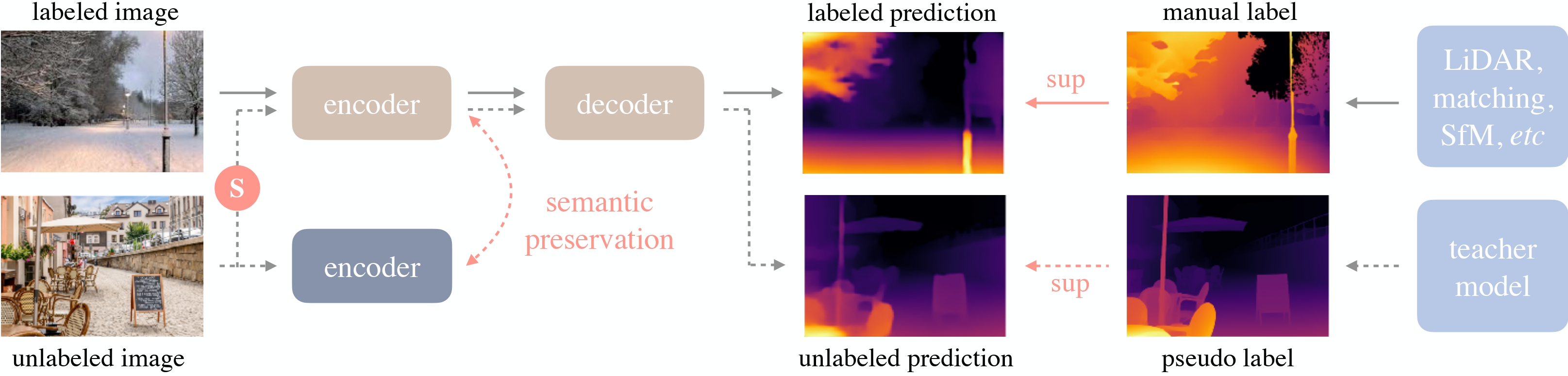
Depth Anything overview. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Usage example
There are 2 main ways to use Depth Anything: either using the pipeline API, which abstracts away all the complexity for you, or by using the DepthAnythingForDepthEstimation class yourself.
Pipeline API
The pipeline allows to use the model in a few lines of code:
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> # load pipe
>>> pipe = pipeline(task="depth-estimation", model="LiheYoung/depth-anything-small-hf")
>>> # load image
>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # inference
>>> depth = pipe(image)["depth"]
Using the model yourself
If you want to do the pre- and postprocessing yourself, here's how to do that:
>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("LiheYoung/depth-anything-small-hf")
>>> model = AutoModelForDepthEstimation.from_pretrained("LiheYoung/depth-anything-small-hf")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # interpolate to original size and visualize the prediction
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... target_sizes=[(image.height, image.width)],
... )
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
>>> depth = depth.detach().cpu().numpy() * 255
>>> depth = Image.fromarray(depth.astype("uint8"))
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Depth Anything.
- Monocular depth estimation task guide
- A notebook showcasing inference with [
DepthAnythingForDepthEstimation] can be found here. 🌎
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
DepthAnythingConfig
autodoc DepthAnythingConfig
DepthAnythingForDepthEstimation
autodoc DepthAnythingForDepthEstimation - forward