* toctree * not-doctested.txt * collapse sections * feedback * update * rewrite get started sections * fixes * fix * loading models * fix * customize models * share * fix link * contribute part 1 * contribute pt 2 * fix toctree * tokenization pt 1 * Add new model (#32615) * v1 - working version * fix * fix * fix * fix * rename to correct name * fix title * fixup * rename files * fix * add copied from on tests * rename to `FalconMamba` everywhere and fix bugs * fix quantization + accelerate * fix copies * add `torch.compile` support * fix tests * fix tests and add slow tests * copies on config * merge the latest changes * fix tests * add few lines about instruct * Apply suggestions from code review Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * fix * fix tests --------- Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * "to be not" -> "not to be" (#32636) * "to be not" -> "not to be" * Update sam.md * Update trainer.py * Update modeling_utils.py * Update test_modeling_utils.py * Update test_modeling_utils.py * fix hfoption tag * tokenization pt. 2 * image processor * fix toctree * backbones * feature extractor * fix file name * processor * update not-doctested * update * make style * fix toctree * revision * make fixup * fix toctree * fix * make style * fix hfoption tag * pipeline * pipeline gradio * pipeline web server * add pipeline * fix toctree * not-doctested * prompting * llm optims * fix toctree * fixes * cache * text generation * fix * chat pipeline * chat stuff * xla * torch.compile * cpu inference * toctree * gpu inference * agents and tools * gguf/tiktoken * finetune * toctree * trainer * trainer pt 2 * optims * optimizers * accelerate * parallelism * fsdp * update * distributed cpu * hardware training * gpu training * gpu training 2 * peft * distrib debug * deepspeed 1 * deepspeed 2 * chat toctree * quant pt 1 * quant pt 2 * fix toctree * fix * fix * quant pt 3 * quant pt 4 * serialization * torchscript * scripts * tpu * review * model addition timeline * modular * more reviews * reviews * fix toctree * reviews reviews * continue reviews * more reviews * modular transformers * more review * zamba2 * fix * all frameworks * pytorch * supported model frameworks * flashattention * rm check_table * not-doctested.txt * rm check_support_list.py * feedback * updates/feedback * review * feedback * fix * update * feedback * updates * update --------- Co-authored-by: Younes Belkada <49240599+younesbelkada@users.noreply.github.com> Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> Co-authored-by: Quentin Gallouédec <45557362+qgallouedec@users.noreply.github.com>
4.1 KiB
Table Transformer
Overview
The Table Transformer model was proposed in PubTables-1M: Towards comprehensive table extraction from unstructured documents by Brandon Smock, Rohith Pesala, Robin Abraham. The authors introduce a new dataset, PubTables-1M, to benchmark progress in table extraction from unstructured documents, as well as table structure recognition and functional analysis. The authors train 2 DETR models, one for table detection and one for table structure recognition, dubbed Table Transformers.
The abstract from the paper is the following:
Recently, significant progress has been made applying machine learning to the problem of table structure inference and extraction from unstructured documents. However, one of the greatest challenges remains the creation of datasets with complete, unambiguous ground truth at scale. To address this, we develop a new, more comprehensive dataset for table extraction, called PubTables-1M. PubTables-1M contains nearly one million tables from scientific articles, supports multiple input modalities, and contains detailed header and location information for table structures, making it useful for a wide variety of modeling approaches. It also addresses a significant source of ground truth inconsistency observed in prior datasets called oversegmentation, using a novel canonicalization procedure. We demonstrate that these improvements lead to a significant increase in training performance and a more reliable estimate of model performance at evaluation for table structure recognition. Further, we show that transformer-based object detection models trained on PubTables-1M produce excellent results for all three tasks of detection, structure recognition, and functional analysis without the need for any special customization for these tasks.
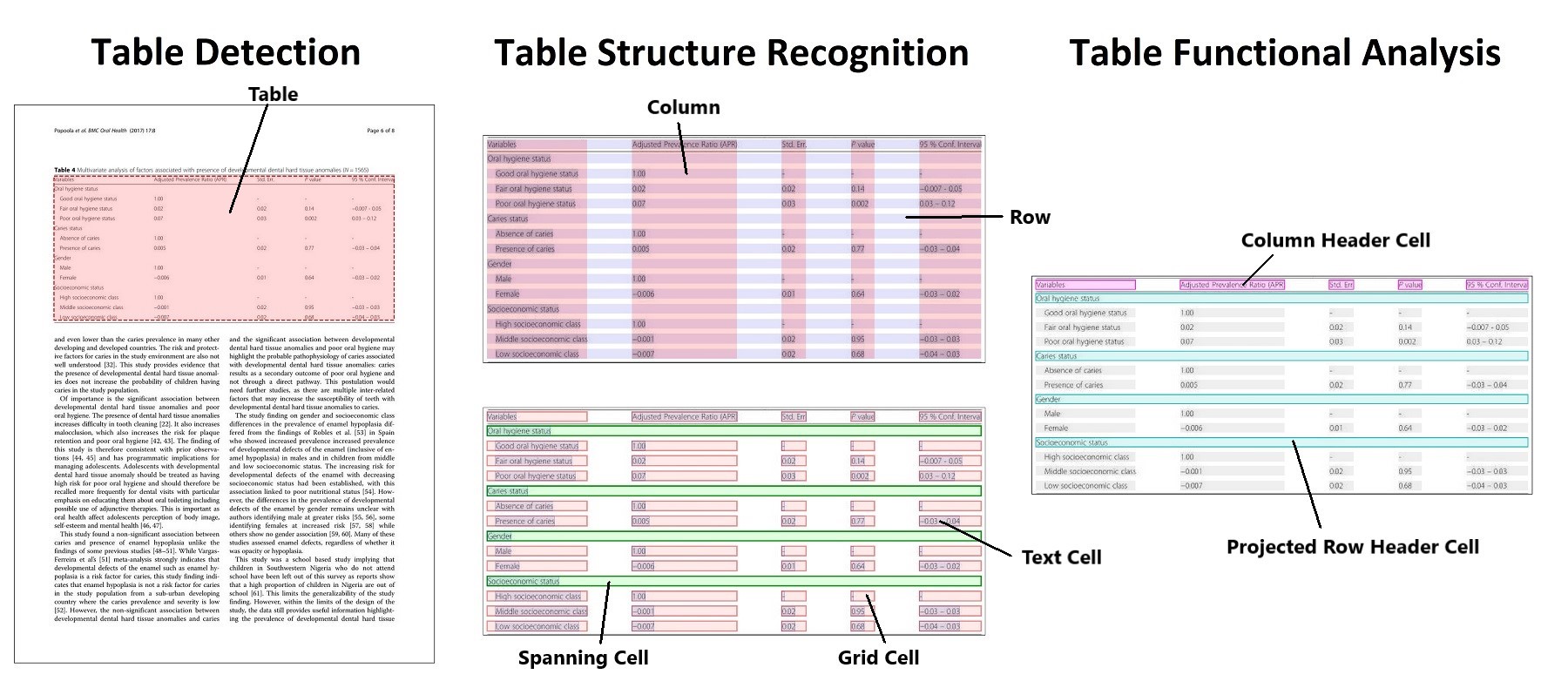
Table detection and table structure recognition clarified. Taken from the original paper.
The authors released 2 models, one for table detection in documents, one for table structure recognition (the task of recognizing the individual rows, columns etc. in a table).
This model was contributed by nielsr. The original code can be found here.
Resources
- A demo notebook for the Table Transformer can be found here.
- It turns out padding of images is quite important for detection. An interesting Github thread with replies from the authors can be found here.
TableTransformerConfig
autodoc TableTransformerConfig
TableTransformerModel
autodoc TableTransformerModel - forward
TableTransformerForObjectDetection
autodoc TableTransformerForObjectDetection - forward