* init vilt image processor fast * Refactor image processor tests to use loop for all processors * Add ViltImageProcessorFast with PyTorch-based optimized image processing * Change made automatically by make fixup command * Change made automatically by make fix-copies command * Fix type hints in ViltImageProcessorFast for Python compatibility * Define constants for image resizing based on COCO dataset aspect ratio * Add missing property initializations to ViltImageProcessorFast * Extract resize logic into dedicated method in ViltImageProcessorFast * Extract padding logic into dedicated method * Implement shape-based image grouping for optimized processing in Vilt * Update test suite to verify ViltImageProcessorFast attributes * Move variable declarations to _preprocess method parameters * Remove unused parameters * Rename _resize method to resize to override existing function * Remove whitespace * Remove unnecessary type check and conversion for stacked_images * Remove redundant loop and apply padding directly to stacked images * Refactor pad function to return images and mask as tuple instead of dict * Add tests comparing padding masks in slow and fast implementations * Update ViltImageProcessor tests to ensure compatibility between slow and fast implementations * Replace add_start_docstrings with auto_docstring in ViltImageProcessorFast * Move docstrings of custom args to ViltFastImageProcessorKwargs * Use reorder_images function for both masks and images --------- Co-authored-by: Yoni Gozlan <74535834+yonigozlan@users.noreply.github.com>
4.6 KiB
ViLT
Overview
The ViLT model was proposed in ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision by Wonjae Kim, Bokyung Son, Ildoo Kim. ViLT incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design for Vision-and-Language Pre-training (VLP).
The abstract from the paper is the following:
Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-and-language downstream tasks. Current approaches to VLP heavily rely on image feature extraction processes, most of which involve region supervision (e.g., object detection) and the convolutional architecture (e.g., ResNet). Although disregarded in the literature, we find it problematic in terms of both (1) efficiency/speed, that simply extracting input features requires much more computation than the multimodal interaction steps; and (2) expressive power, as it is upper bounded to the expressive power of the visual embedder and its predefined visual vocabulary. In this paper, we present a minimal VLP model, Vision-and-Language Transformer (ViLT), monolithic in the sense that the processing of visual inputs is drastically simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of times faster than previous VLP models, yet with competitive or better downstream task performance.
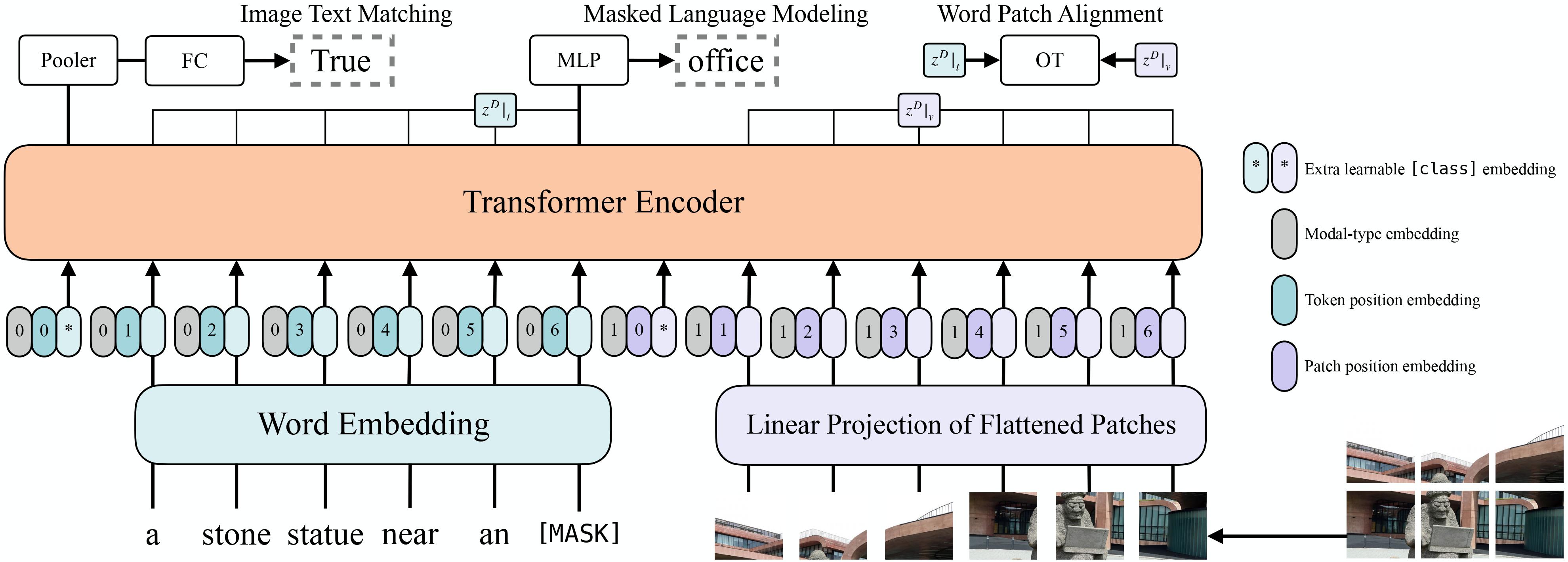
ViLT architecture. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Usage tips
- The quickest way to get started with ViLT is by checking the example notebooks (which showcase both inference and fine-tuning on custom data).
- ViLT is a model that takes both
pixel_valuesandinput_idsas input. One can use [ViltProcessor] to prepare data for the model. This processor wraps a image processor (for the image modality) and a tokenizer (for the language modality) into one. - ViLT is trained with images of various sizes: the authors resize the shorter edge of input images to 384 and limit the longer edge to
under 640 while preserving the aspect ratio. To make batching of images possible, the authors use a
pixel_maskthat indicates which pixel values are real and which are padding. [ViltProcessor] automatically creates this for you. - The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes additional embedding layers for the language modality.
- The PyTorch version of this model is only available in torch 1.10 and higher.
ViltConfig
autodoc ViltConfig
ViltFeatureExtractor
autodoc ViltFeatureExtractor - call
ViltImageProcessor
autodoc ViltImageProcessor - preprocess
ViltImageProcessorFast
autodoc ViltImageProcessorFast - preprocess
ViltProcessor
autodoc ViltProcessor - call
ViltModel
autodoc ViltModel - forward
ViltForMaskedLM
autodoc ViltForMaskedLM - forward
ViltForQuestionAnswering
autodoc ViltForQuestionAnswering - forward
ViltForImagesAndTextClassification
autodoc ViltForImagesAndTextClassification - forward
ViltForImageAndTextRetrieval
autodoc ViltForImageAndTextRetrieval - forward
ViltForTokenClassification
autodoc ViltForTokenClassification - forward