* docs: ko: siglip.md * feat: nmt draft * fix: manual edits * chore: Correct document title to kebab-case format Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com> * Apply suggestions from code review Convert unnatural language to natural Korean Co-authored-by: Yijun Lee <119404328+yijun-lee@users.noreply.github.com> --------- Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com> Co-authored-by: Yijun Lee <119404328+yijun-lee@users.noreply.github.com>
11 KiB
SigLIPsiglip
개요overview
SigLIP 모델은 Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer의 Sigmoid Loss for Language Image Pre-Training 논문에서 제안되었습니다. SigLIP은 CLIP에서 사용된 손실 함수를 간단한 쌍별 시그모이드 손실(pairwise sigmoid loss)로 대체할 것을 제안합니다. 이는 ImageNet에서 제로샷 분류 정확도 측면에서 더 나은 성능을 보입니다.
논문의 초록은 다음과 같습니다:
우리는 언어-이미지 사전 학습(Language-Image Pre-training, SigLIP)을 위한 간단한 쌍별 시그모이드 손실을 제안합니다. 소프트맥스 정규화를 사용하는 표준 대조 학습과 달리, 시그모이드 손실은 이미지-텍스트 쌍에만 작용하며 정규화를 위해 쌍별 유사성의 전역적 관점을 필요로 하지 않습니다. 시그모이드 손실은 배치 크기를 더욱 확장할 수 있게 하는 동시에 작은 배치 크기에서도 더 나은 성능을 보입니다. Locked-image Tuning과 결합하여, 단 4개의 TPUv4 칩만으로 이틀 만에 84.5%의 ImageNet 제로샷 정확도를 달성하는 SigLiT 모델을 학습했습니다. 손실 함수에서 배치 크기를 분리함으로써 예제 대 쌍의 영향과 Negative 대 Positive 비율을 연구할 수 있게 되었습니다. 마지막으로, 우리는 배치 크기를 100만 개까지 극단적으로 늘려보았고, 배치 크기 증가의 이점이 빠르게 감소하며 32k의 더 합리적인 배치 크기로도 충분하다는 것을 발견했습니다.
사용 팁usage-tips
- SigLIP의 사용법은 CLIP과 유사합니다. 주요 차이점은 학습 손실 함수로, 배치 내 모든 이미지와 텍스트 간의 쌍별 유사성에 대한 전역적 관점이 필요하지 않습니다. 소프트맥스 대신 로짓에 시그모이드 활성화 함수를 적용해야 합니다.
- 학습은 지원되지만
torch.distributed유틸리티를 사용하지 않아 배치 크기의 확장성이 제한될 수 있습니다. 그러나 단일 노드 다중 GPU 설정에서는 DDP와 FDSP가 작동합니다. - 독립형 [
SiglipTokenizer] 또는 [SiglipProcessor]를 사용할 때는 모델이 그렇게 학습되었으므로padding="max_length"를 전달해야 합니다. - 파이프라인과 동일한 결과를 얻으려면 "This is a photo of {label}."의 프롬프트 템플릿을 사용해야 합니다.
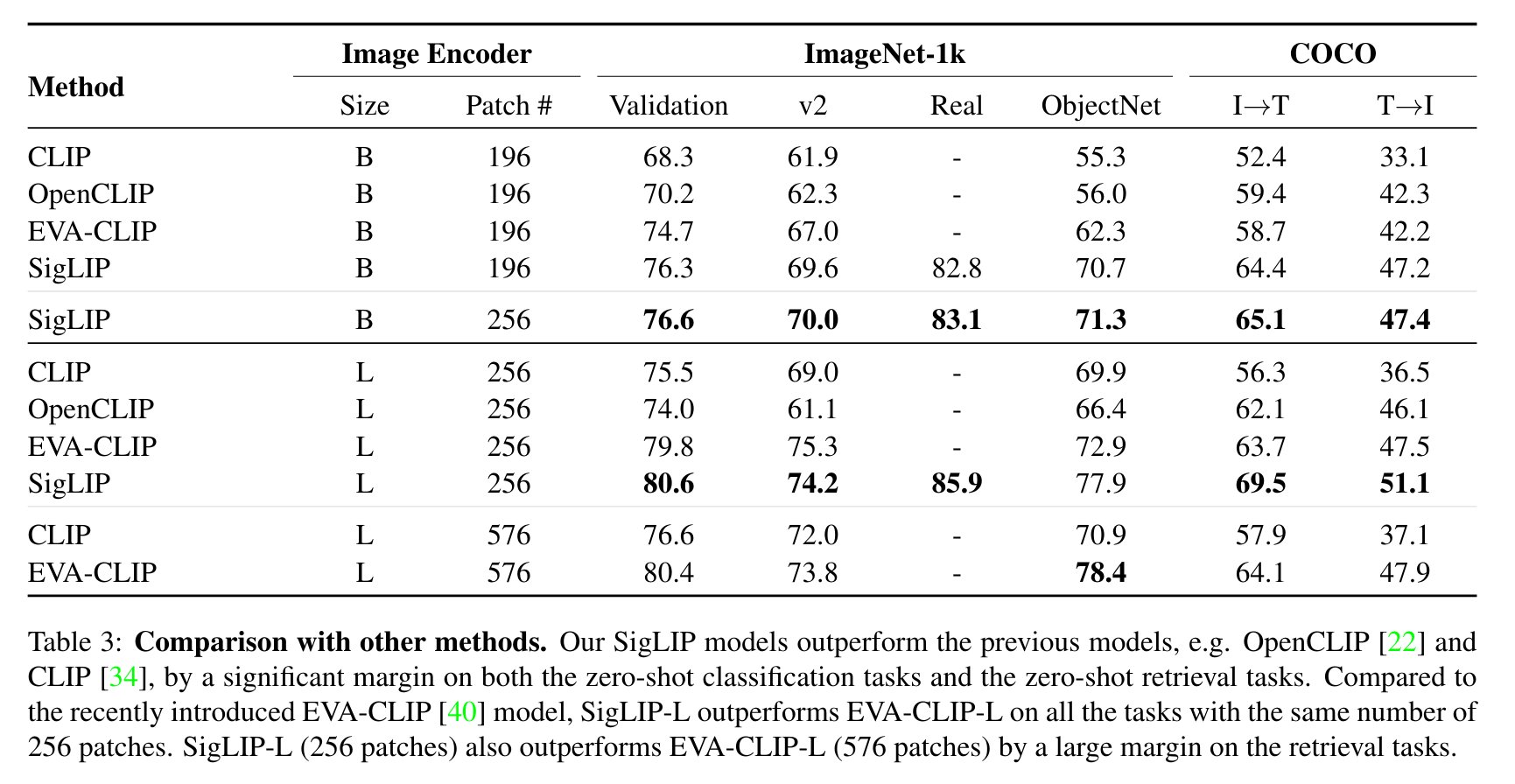
CLIP과 비교한 SigLIP 평가 결과. 원본 논문에서 발췌.
이 모델은 nielsr가 기여했습니다. 원본 코드는 여기에서 찾을 수 있습니다.
사용 예시usage-example
SigLIP을 사용하는 방법에는 두 가지 주요 방법이 있습니다: 모든 복잡성을 추상화하는 파이프라인 API를 사용하거나, 직접 SiglipModel 클래스를 사용하는 방법입니다.
파이프라인 APIpipeline-API
파이프라인을 사용하면 몇 줄의 코드로 모델을 사용할 수 있습니다:
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> # 파이프라인 로드
>>> image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
>>> # 이미지 로드
>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # 추론
>>> candidate_labels = ["2 cats", "a plane", "a remote"]
>>> outputs = image_classifier(image, candidate_labels=candidate_labels)
>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
>>> print(outputs)
[{'score': 0.1979, 'label': '2 cats'}, {'score': 0.0, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
직접 모델 사용하기using-the-model-yourself
전처리와 후처리를 직접 수행하려면 다음과 같이 하면 됩니다:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> candidate_labels = ["2 cats", "2 dogs"]
# 파이프라인 프롬프트 템플릿을 따라 동일한 결과를 얻습니다
>>> texts = [f'This is a photo of {label}.' for label in candidate_labels]
# 중요: 모델이 이렇게 학습되었으므로 `padding=max_length`를 전달합니다
>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # 시그모이드 활성화 함수를 적용한 확률입니다
>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
19.8% that image 0 is '2 cats'
리소스resources
SigLIP을 시작하는 데 도움이 되는 공식 Hugging Face 및 커뮤니티(🌎로 표시) 리소스 목록입니다.
- 제로샷 이미지 분류 작업 가이드
- SigLIP에 대한 데모 노트북은 여기에서 찾을 수 있습니다. 🌎
여기에 포함될 리소스를 제출하는 데 관심이 있으시면 Pull Request를 열어주시면 검토하겠습니다! 리소스는 이상적으로 기존 리소스를 복제하는 대신 새로운 것을 보여주어야 합니다.
SigLIP과 Flash Attention 2 결합하기combining-siglip-with-flash-attention-2
먼저 Flash Attention 2의 최신 버전을 설치해야 합니다.
pip install -U flash-attn --no-build-isolation
또한 Flash-Attention 2와 호환되는 하드웨어가 있는지 확인하세요. flash-attn 저장소의 공식 문서에서 자세히 알아보세요. 또한 모델을 반정밀도(예: torch.float16)로 로드해야 합니다.
Flash Attention 2를 사용하여 모델을 로드하고 실행하려면 아래 코드를 참조하세요:
>>> import torch
>>> import requests
>>> from PIL import Image
>>> from transformers import SiglipProcessor, SiglipModel
>>> device = "cuda" # 모델을 로드할 장치
>>> model = SiglipModel.from_pretrained(
... "google/siglip-so400m-patch14-384",
... attn_implementation="flash_attention_2",
... torch_dtype=torch.float16,
... device_map=device,
... )
>>> processor = SiglipProcessor.from_pretrained("google/siglip-so400m-patch14-384")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> candidate_labels = ["2 cats", "2 dogs"]
# 파이프라인 프롬프트 템플릿을 따라 동일한 결과를 얻습니다
>>> texts = [f'This is a photo of {label}.' for label in candidate_labels]
# 중요: 모델이 이렇게 학습되었으므로 `padding=max_length`를 전달합니다
>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt").to(device)
>>> with torch.no_grad():
... with torch.autocast(device):
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # 시그모이드 활성화 함수를 적용한 확률입니다
>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
19.8% that image 0 is '2 cats'
Scaled Dot Product Attention(SDPA) 사용하기[using-scaled-dot-product-attention(SDPA)]]
PyTorch는 torch.nn.functional의 일부로 스케일된 점곱 어텐션(SDPA) 연산자를 포함합니다. 이 함수는
입력과 사용 중인 하드웨어에 따라 적용할 수 있는 여러 구현을 포함합니다. 자세한 내용은
공식 문서
또는 GPU 추론
페이지를 참조하세요.
from_pretrained()에서 attn_implementation="sdpa"를 설정하여 SDPA를 명시적으로 요청할 수 있습니다. torch>=2.1.1이 설치되어 있는지 확인하세요.
>>> from transformers import SiglipModel
>>> model = SiglipModel.from_pretrained(
... "google/siglip-so400m-patch14-384",
... attn_implementation="sdpa",
... torch_dtype=torch.float16,
... device_map=device,
... )
최상의 속도 향상을 위해 모델을 반정밀도(예: torch.float16 또는 torch.bfloat16)로 로드하는 것이 좋습니다.
예상 속도 향상expected-speedups
아래는 google/siglip-so400m-patch14-384 체크포인트를 float16 정밀도로 사용하는 transformers의 네이티브 구현과 Flash Attention 2 / SDPA 버전의 모델을 다양한 배치 크기로 비교한 추론 시간의 예상 속도 향상 다이어그램입니다.

SiglipConfig
autodoc SiglipConfig - from_text_vision_configs
SiglipTextConfig
autodoc SiglipTextConfig
SiglipVisionConfig
autodoc SiglipVisionConfig
SiglipTokenizer
autodoc SiglipTokenizer - build_inputs_with_special_tokens - get_special_tokens_mask - create_token_type_ids_from_sequences - save_vocabulary
SiglipImageProcessor
autodoc SiglipImageProcessor - preprocess
SiglipImageProcessorFast
autodoc SiglipImageProcessorFast - preprocess
SiglipProcessor
autodoc SiglipProcessor
SiglipModel
autodoc SiglipModel - forward - get_text_features - get_image_features
SiglipTextModel
autodoc SiglipTextModel - forward
SiglipVisionModel
autodoc SiglipVisionModel - forward
SiglipForImageClassification
autodoc SiglipForImageClassification - forward