* toctree * not-doctested.txt * collapse sections * feedback * update * rewrite get started sections * fixes * fix * loading models * fix * customize models * share * fix link * contribute part 1 * contribute pt 2 * fix toctree * tokenization pt 1 * Add new model (#32615) * v1 - working version * fix * fix * fix * fix * rename to correct name * fix title * fixup * rename files * fix * add copied from on tests * rename to `FalconMamba` everywhere and fix bugs * fix quantization + accelerate * fix copies * add `torch.compile` support * fix tests * fix tests and add slow tests * copies on config * merge the latest changes * fix tests * add few lines about instruct * Apply suggestions from code review Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * fix * fix tests --------- Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * "to be not" -> "not to be" (#32636) * "to be not" -> "not to be" * Update sam.md * Update trainer.py * Update modeling_utils.py * Update test_modeling_utils.py * Update test_modeling_utils.py * fix hfoption tag * tokenization pt. 2 * image processor * fix toctree * backbones * feature extractor * fix file name * processor * update not-doctested * update * make style * fix toctree * revision * make fixup * fix toctree * fix * make style * fix hfoption tag * pipeline * pipeline gradio * pipeline web server * add pipeline * fix toctree * not-doctested * prompting * llm optims * fix toctree * fixes * cache * text generation * fix * chat pipeline * chat stuff * xla * torch.compile * cpu inference * toctree * gpu inference * agents and tools * gguf/tiktoken * finetune * toctree * trainer * trainer pt 2 * optims * optimizers * accelerate * parallelism * fsdp * update * distributed cpu * hardware training * gpu training * gpu training 2 * peft * distrib debug * deepspeed 1 * deepspeed 2 * chat toctree * quant pt 1 * quant pt 2 * fix toctree * fix * fix * quant pt 3 * quant pt 4 * serialization * torchscript * scripts * tpu * review * model addition timeline * modular * more reviews * reviews * fix toctree * reviews reviews * continue reviews * more reviews * modular transformers * more review * zamba2 * fix * all frameworks * pytorch * supported model frameworks * flashattention * rm check_table * not-doctested.txt * rm check_support_list.py * feedback * updates/feedback * review * feedback * fix * update * feedback * updates * update --------- Co-authored-by: Younes Belkada <49240599+younesbelkada@users.noreply.github.com> Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> Co-authored-by: Quentin Gallouédec <45557362+qgallouedec@users.noreply.github.com>
4.9 KiB
Neighborhood Attention Transformer
This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
You can do so by running the following command: pip install -U transformers==4.40.2.
Overview
NAT was proposed in Neighborhood Attention Transformer by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
It is a hierarchical vision transformer based on Neighborhood Attention, a sliding-window self attention pattern.
The abstract from the paper is the following:
*We present Neighborhood Attention (NA), the first efficient and scalable sliding-window attention mechanism for vision. NA is a pixel-wise operation, localizing self attention (SA) to the nearest neighboring pixels, and therefore enjoys a linear time and space complexity compared to the quadratic complexity of SA. The sliding-window pattern allows NA's receptive field to grow without needing extra pixel shifts, and preserves translational equivariance, unlike Swin Transformer's Window Self Attention (WSA). We develop NATTEN (Neighborhood Attention Extension), a Python package with efficient C++ and CUDA kernels, which allows NA to run up to 40% faster than Swin's WSA while using up to 25% less memory. We further present Neighborhood Attention Transformer (NAT), a new hierarchical transformer design based on NA that boosts image classification and downstream vision performance. Experimental results on NAT are competitive; NAT-Tiny reaches 83.2% top-1 accuracy on ImageNet, 51.4% mAP on MS-COCO and 48.4% mIoU on ADE20K, which is 1.9% ImageNet accuracy, 1.0% COCO mAP, and 2.6% ADE20K mIoU improvement over a Swin model with similar size. *
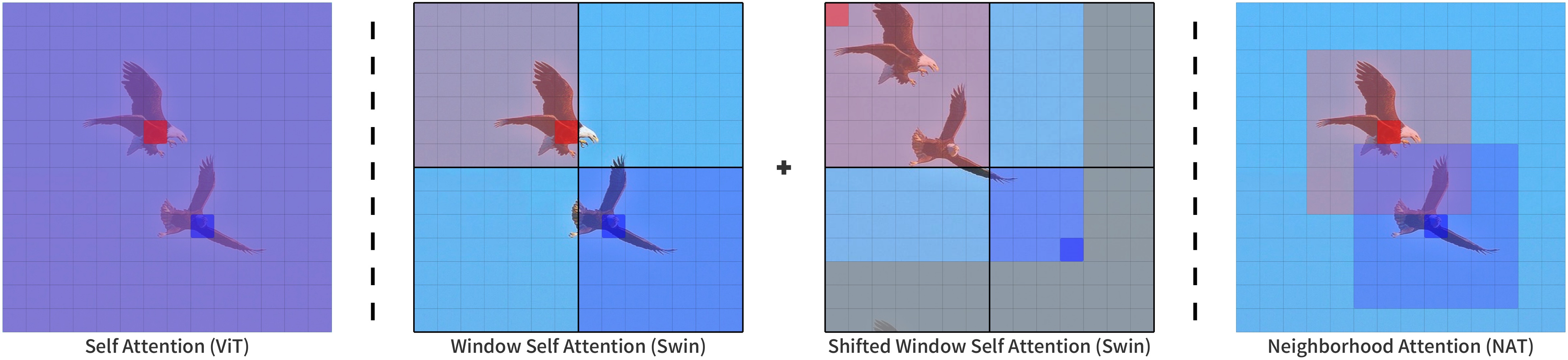
Neighborhood Attention compared to other attention patterns. Taken from the original paper.
This model was contributed by Ali Hassani. The original code can be found here.
Usage tips
- One can use the [
AutoImageProcessor] API to prepare images for the model. - NAT can be used as a backbone. When
output_hidden_states = True, it will output bothhidden_statesandreshaped_hidden_states. Thereshaped_hidden_stateshave a shape of(batch, num_channels, height, width)rather than(batch_size, height, width, num_channels).
Notes:
- NAT depends on NATTEN's implementation of Neighborhood Attention.
You can install it with pre-built wheels for Linux by referring to shi-labs.com/natten,
or build on your system by running
pip install natten. Note that the latter will likely take time to compile. NATTEN does not support Windows devices yet. - Patch size of 4 is only supported at the moment.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with NAT.
- [
NatForImageClassification] is supported by this example script and notebook. - See also: Image classification task guide
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
NatConfig
autodoc NatConfig
NatModel
autodoc NatModel - forward
NatForImageClassification
autodoc NatForImageClassification - forward