* Squashed commit of the following:
commit 102842cd477219b9f9bcb23a0bca3a8b92bd732f
Author: Pavel Iakubovskii <qubvel@gmail.com>
Date: Fri Jul 12 18:23:52 2024 +0000
Add model-specific sdpa tests
commit 60e4c88581abf89ec098da84ed8e92aa904c997d
Author: Pavel Iakubovskii <qubvel@gmail.com>
Date: Fri Jul 12 18:20:53 2024 +0000
Add fallback to eager (expensive operation)
commit c29033d30e7ffde4327e8a15cbbc6bee37546f80
Author: Pavel Iakubovskii <qubvel@gmail.com>
Date: Thu Jul 11 17:09:55 2024 +0000
Fix attn_implementation propagation
commit 783aed05f0f38cb2f99e758f81db6838ac55b9f8
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Sat May 25 09:05:27 2024 +0530
style
commit e77e703ca75d00447cda277eca6b886cd32bddc0
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Sat May 25 09:04:57 2024 +0530
add comment to explain why I had to touch forbidden codebase.
commit ab9d8849758e7773a31778ccba71588d18552623
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Sat May 25 09:03:02 2024 +0530
fix: flax attribute access.
commit c570fc0abf9d1bd58c291aae3c7e384f995996d2
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Sat May 25 08:23:54 2024 +0530
fix tensorflow attribute name.
commit 32c812871cfdb268d8a6e3e2c61c5c925c8ed47e
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Sat May 25 07:57:10 2024 +0530
fix attribute access.
commit 4f41a0138b6c417aed9c9332278f8bcd979cb7c2
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Sat May 25 07:44:02 2024 +0530
_from_config.
commit 35aed64ff602422adcf41d7f677a0a24bd9eccae
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 24 18:46:52 2024 +0530
propagation of attn_implementation.
commit 4c25c19845438b1dc1d35a5adf9436151c8c5940
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 24 09:24:36 2024 +0530
style again
commit 5f7dc5c5015c0f8116408f737e8c318d1802c80c
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 24 09:19:05 2024 +0530
use from_config.
commit b70c409956d0359fa6ae5372275d2a20ba7e3389
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 24 09:13:43 2024 +0530
quality
commit a7b63beff53d0fc754c6564e2a7b51731ddee49d
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 10 14:35:10 2024 +0200
add benchmark numbers
commit 455b0eaea50862b8458c8f422b60fe60ae40fdcb
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 10 13:50:16 2024 +0200
Revert "reflect feedback more"
This reverts commit dc123e71ef.
commit ca674829d28787349c2a9593a14e0f1d41f04ea4
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 10 13:50:05 2024 +0200
Revert "fix"
This reverts commit 37a1cb35b8.
commit fab2dd8576c099eb1a3464958cb206a664d28247
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 10 13:47:46 2024 +0200
fix
commit fbc6ae50fd6f2d36294d31e191761631b701d696
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 10 13:38:30 2024 +0200
reflect feedback more
commit 87245bb020b2d60a89afe318a951df0159404fc9
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 3 08:54:34 2024 +0530
fixes
commit 1057cc26390ee839251e7f8b3326c4207595fb23
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 3 07:49:03 2024 +0530
don't explicit set attn_implementation in tests
commit e33f75916fc8a99f516b1cf449dbbe9d3aabda81
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 3 07:43:54 2024 +0530
explicitly override attn_implementation in the towers.
commit 4cf41cb1bc885c39df7cb8f2a0694ebf23299235
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 3 07:38:42 2024 +0530
import in one-line.
commit f2cc447ae9e74ccfacb448140cdf88259d4afc8c
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri May 3 07:34:58 2024 +0530
move sdpa mention to usage tips.
commit 92884766c64dbb456926a3a84dd427be1349fa95
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Mon Apr 29 10:58:26 2024 +0530
fix: memory allocation problem.
commit d7ffbbfe12f7750b7d0a361420f35c13e0ea787d
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Mon Apr 29 09:56:59 2024 +0530
fix-copies
commit 8dfc3731cedd02e36acd3fe56bb2e6d61efd25d8
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Fri Apr 26 20:16:12 2024 +0530
address arthur's comments.
commit d2ed7b4ce4ff15ae9aa4d3d0500f1544e3dcd9e9
Author: Sayak Paul <spsayakpaul@gmail.com>
Date: Fri Apr 26 20:08:15 2024 +0530
Apply suggestions from code review
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
commit 46e04361f37ded5c522ff05e9f725b9f82dce40e
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Wed Apr 24 09:55:27 2024 +0530
add to docs.
commit 831629158ad40d34d8983f209afb2740ba041af2
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Wed Apr 24 09:33:10 2024 +0530
styling.g
commit d263a119c77314250f4b4c8469caf42559197f22
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Wed Apr 24 09:15:20 2024 +0530
up
commit d44f9d3d7633d4c241a737a1bc317f791f6aedb3
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Tue Apr 23 18:40:42 2024 +0530
handle causal and attention mask
commit 122f1d60153df6666b634a94e38d073f3f260926
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Tue Apr 23 15:18:21 2024 +0530
test fixes.
commit 4382d8cff6fa1dee5dbcf0d06b3e2841231e36f5
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Tue Apr 23 09:39:25 2024 +0530
fix: scaling inside sdpa.
commit 0f629989efc48b7315cf19405a81e02955efe7e5
Author: Sayak Paul <spsayakpaul@gmail.com>
Date: Tue Apr 23 08:14:58 2024 +0530
Update src/transformers/models/clip/modeling_clip.py
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
commit 14367316877dc27ea40f767ad1aee38bbc97e4ce
Author: sayakpaul <spsayakpaul@gmail.com>
Date: Mon Apr 22 16:21:36 2024 +0530
add: sdpa support to clip.
* Remove fallback for empty attention mask (expensive operation)
* Fix typing in copies
* Add flash attention
* Add flash attention tests
* List CLIP in FA docs
* Fix embeddings attributes and tf
* [run-slow] clip
* Update clip documentation
* Remove commented code, skip compile dynamic for CLIPModel
* Fix doc
* Fix doc 2
* Remove double transpose
* Add torch version check for contiguous()
* Add comment to test mixin
* Fix copies
* Add comment for mask
* Update docs
* [run-slow] clip
27 KiB
GPU inference
GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you'll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia and AMD GPUs.
The majority of the optimizations described here also apply to multi-GPU setups!
FlashAttention-2
FlashAttention-2 is experimental and may change considerably in future versions.
FlashAttention-2 is a faster and more efficient implementation of the standard attention mechanism that can significantly speedup inference by:
- additionally parallelizing the attention computation over sequence length
- partitioning the work between GPU threads to reduce communication and shared memory reads/writes between them
FlashAttention-2 is currently supported for the following architectures:
- Bark
- Bart
- Chameleon
- CLIP
- Cohere
- Dbrx
- DistilBert
- Gemma
- Gemma2
- GPT2
- GPTBigCode
- GPTNeo
- GPTNeoX
- GPT-J
- Idefics2
- Falcon
- JetMoe
- Jamba
- Llama
- Llava
- Llava-NeXT
- Llava-NeXT-Video
- VipLlava
- VideoLlava
- M2M100
- MBart
- Mistral
- Mixtral
- Musicgen
- MusicGen Melody
- NLLB
- OLMo
- OPT
- Phi
- Phi3
- SigLIP
- StableLm
- Starcoder2
- Qwen2
- Qwen2MoE
- Whisper
- Wav2Vec2
- Hubert
- data2vec_audio
- Sew
- UniSpeech
- unispeech_sat
You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
Before you begin, make sure you have FlashAttention-2 installed.
pip install flash-attn --no-build-isolation
We strongly suggest referring to the detailed installation instructions to learn more about supported hardware and data types!
FlashAttention-2 is also supported on AMD GPUs and current support is limited to Instinct MI210, Instinct MI250 and Instinct MI300. We strongly suggest using this Dockerfile to use FlashAttention-2 on AMD GPUs.
To enable FlashAttention-2, pass the argument attn_implementation="flash_attention_2" to [~AutoModelForCausalLM.from_pretrained]:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
FlashAttention-2 can only be used when the model's dtype is fp16 or bf16. Make sure to cast your model to the appropriate dtype and load them on a supported device before using FlashAttention-2.
You can also set use_flash_attention_2=True to enable FlashAttention-2 but it is deprecated in favor of attn_implementation="flash_attention_2".
FlashAttention-2 can be combined with other optimization techniques like quantization to further speedup inference. For example, you can combine FlashAttention-2 with 8-bit or 4-bit quantization:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# load in 8bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
attn_implementation="flash_attention_2",
)
# load in 4bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2",
)
Expected speedups
You can benefit from considerable speedups for inference, especially for inputs with long sequences. However, since FlashAttention-2 does not support computing attention scores with padding tokens, you must manually pad/unpad the attention scores for batched inference when the sequence contains padding tokens. This leads to a significant slowdown for batched generations with padding tokens.
To overcome this, you should use FlashAttention-2 without padding tokens in the sequence during training (by packing a dataset or concatenating sequences until reaching the maximum sequence length).
For a single forward pass on tiiuae/falcon-7b with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
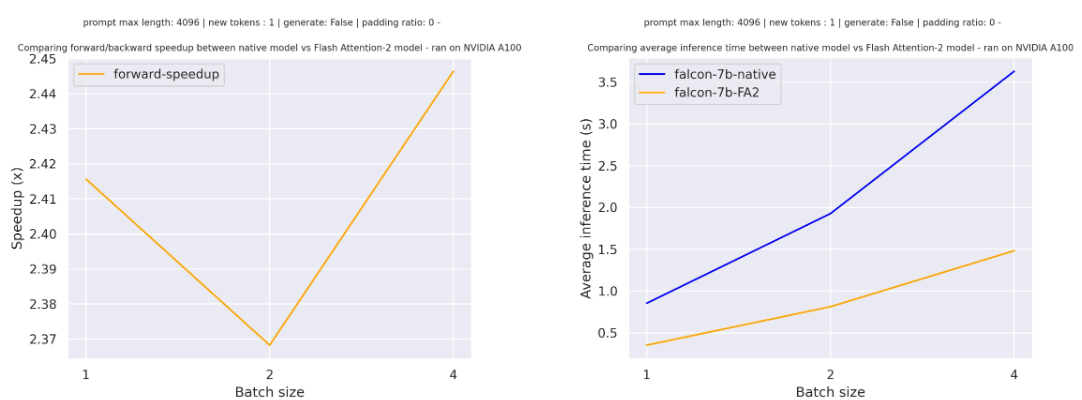
For a single forward pass on meta-llama/Llama-7b-hf with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
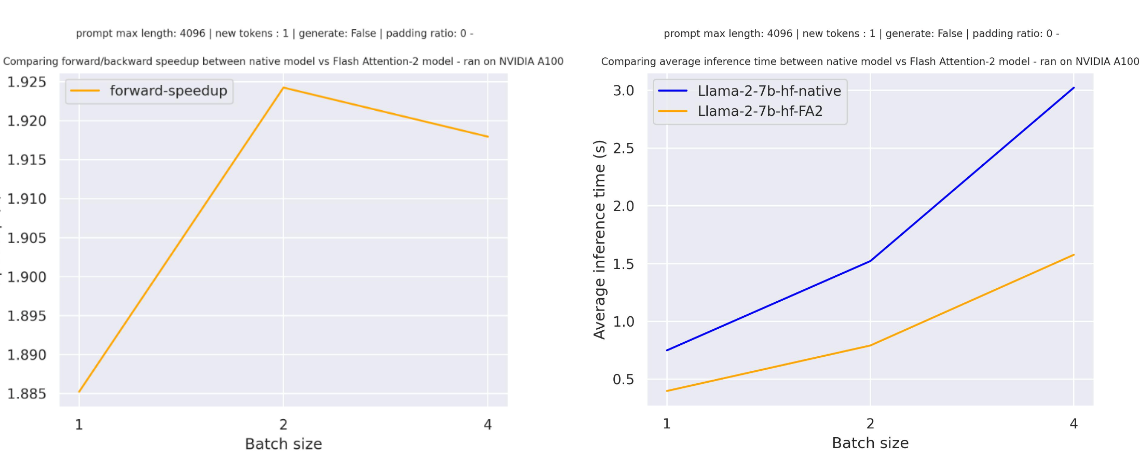
For sequences with padding tokens (generating with padding tokens), you need to unpad/pad the input sequences to correctly compute the attention scores. With a relatively small sequence length, a single forward pass creates overhead leading to a small speedup (in the example below, 30% of the input is filled with padding tokens):
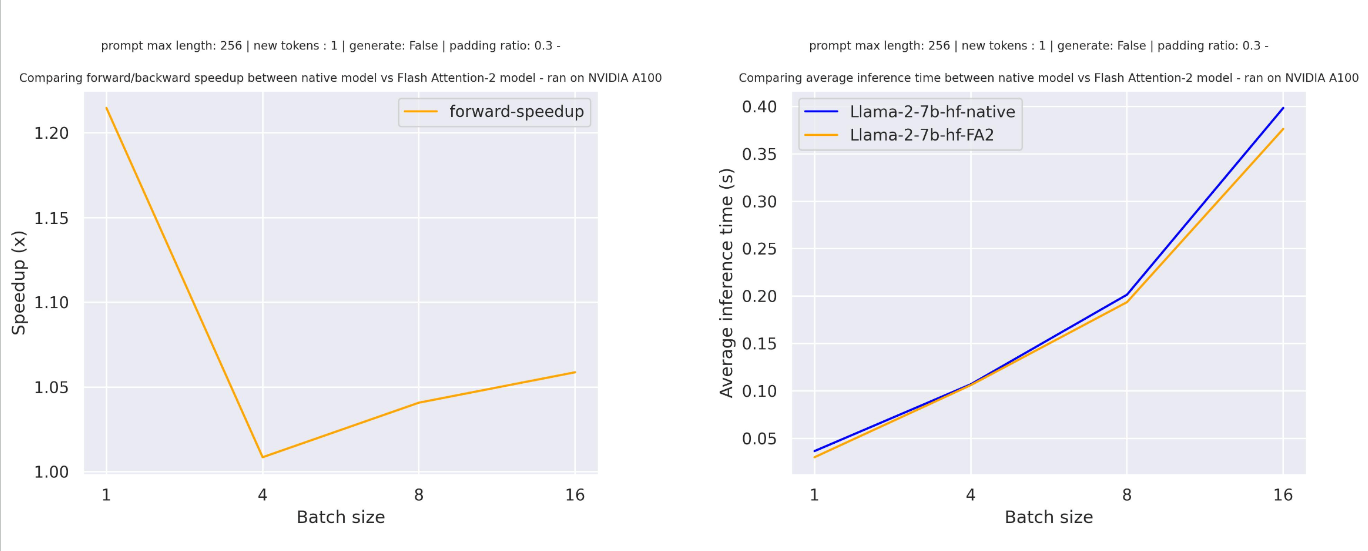
But for larger sequence lengths, you can expect even more speedup benefits:
FlashAttention is more memory efficient, meaning you can train on much larger sequence lengths without running into out-of-memory issues. You can potentially reduce memory usage up to 20x for larger sequence lengths. Take a look at the flash-attention repository for more details.

PyTorch scaled dot product attention
PyTorch's torch.nn.functional.scaled_dot_product_attention (SDPA) can also call FlashAttention and memory-efficient attention kernels under the hood. SDPA support is currently being added natively in Transformers and is used by default for torch>=2.1.1 when an implementation is available. You may also set attn_implementation="sdpa" in from_pretrained() to explicitly request SDPA to be used.
For now, Transformers supports SDPA inference and training for the following architectures:
- Audio Spectrogram Transformer
- Bart
- Bert
- Chameleon
- CLIP
- Cohere
- Dbrx
- DeiT
- Dpr
- Falcon
- Gemma
- Gemma2
- GPT2
- GPTBigCode
- GPTNeoX
- JetMoe
- Jamba
- Llama
- OLMo
- PaliGemma
- Phi
- Idefics
- Whisper
- Mistral
- Mixtral
- StableLm
- Starcoder2
- Qwen2
- Qwen2MoE
- Musicgen
- MusicGen Melody
- ViT
- ViTHybrid
- ViTMAE
- ViTMSN
- VideoMAE
- wav2vec2
- Hubert
- data2vec_audio
- SigLIP
- Sew
- UniSpeech
- unispeech_sat
- YOLOS
FlashAttention can only be used for models with the fp16 or bf16 torch type, so make sure to cast your model to the appropriate type first. The memory-efficient attention backend is able to handle fp32 models.
SDPA does not support certain sets of attention parameters, such as head_mask and output_attentions=True.
In that case, you should see a warning message and we will fall back to the (slower) eager implementation.
By default, SDPA selects the most performant kernel available but you can check whether a backend is available in a given setting (hardware, problem size) with torch.backends.cuda.sdp_kernel as a context manager:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16).to("cuda")
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
If you see a bug with the traceback below, try using the nightly version of PyTorch which may have broader coverage for FlashAttention:
RuntimeError: No available kernel. Aborting execution.
# install PyTorch nightly
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
BetterTransformer
Some BetterTransformer features are being upstreamed to Transformers with default support for native torch.nn.scaled_dot_product_attention. BetterTransformer still has a wider coverage than the Transformers SDPA integration, but you can expect more and more architectures to natively support SDPA in Transformers.
Check out our benchmarks with BetterTransformer and scaled dot product attention in the Out of the box acceleration and memory savings of 🤗 decoder models with PyTorch 2.0 and learn more about the fastpath execution in the BetterTransformer blog post.
BetterTransformer accelerates inference with its fastpath (native PyTorch specialized implementation of Transformer functions) execution. The two optimizations in the fastpath execution are:
- fusion, which combines multiple sequential operations into a single "kernel" to reduce the number of computation steps
- skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
BetterTransformer also converts all attention operations to use the more memory-efficient scaled dot product attention (SDPA), and it calls optimized kernels like FlashAttention under the hood.
Before you start, make sure you have 🤗 Optimum installed.
Then you can enable BetterTransformer with the [PreTrainedModel.to_bettertransformer] method:
model = model.to_bettertransformer()
You can return the original Transformers model with the [~PreTrainedModel.reverse_bettertransformer] method. You should use this before saving your model to use the canonical Transformers modeling:
model = model.reverse_bettertransformer()
model.save_pretrained("saved_model")
bitsandbytes
bitsandbytes is a quantization library that includes support for 4-bit and 8-bit quantization. Quantization reduces your model size compared to its native full precision version, making it easier to fit large models onto GPUs with limited memory.
Make sure you have bitsandbytes and 🤗 Accelerate installed:
# these versions support 8-bit and 4-bit
pip install bitsandbytes>=0.39.0 accelerate>=0.20.0
# install Transformers
pip install transformers
4-bit
To load a model in 4-bit for inference, use the load_in_4bit parameter. The device_map parameter is optional, but we recommend setting it to "auto" to allow 🤗 Accelerate to automatically and efficiently allocate the model given the available resources in the environment.
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)
To load a model in 4-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 600MB of memory to the first GPU and 1GB of memory to the second GPU:
max_memory_mapping = {0: "600MB", 1: "1GB"}
model_name = "bigscience/bloom-3b"
model_4bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_4bit=True, max_memory=max_memory_mapping
)
8-bit
If you're curious and interested in learning more about the concepts underlying 8-bit quantization, read the Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes blog post.
To load a model in 8-bit for inference, use the load_in_8bit parameter. The device_map parameter is optional, but we recommend setting it to "auto" to allow 🤗 Accelerate to automatically and efficiently allocate the model given the available resources in the environment:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
If you're loading a model in 8-bit for text generation, you should use the [~transformers.GenerationMixin.generate] method instead of the [Pipeline] function which is not optimized for 8-bit models and will be slower. Some sampling strategies, like nucleus sampling, are also not supported by the [Pipeline] for 8-bit models. You should also place all inputs on the same device as the model:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_name = "bigscience/bloom-2b5"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
prompt = "Hello, my llama is cute"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(**inputs)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
To load a model in 4-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 1GB of memory to the first GPU and 2GB of memory to the second GPU:
max_memory_mapping = {0: "1GB", 1: "2GB"}
model_name = "bigscience/bloom-3b"
model_8bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_8bit=True, max_memory=max_memory_mapping
)
Feel free to try running a 11 billion parameter T5 model or the 3 billion parameter BLOOM model for inference on Google Colab's free tier GPUs!
🤗 Optimum
Learn more details about using ORT with 🤗 Optimum in the Accelerated inference on NVIDIA GPUs and Accelerated inference on AMD GPUs guides. This section only provides a brief and simple example.
ONNX Runtime (ORT) is a model accelerator that supports accelerated inference on Nvidia GPUs, and AMD GPUs that use ROCm stack. ORT uses optimization techniques like fusing common operations into a single node and constant folding to reduce the number of computations performed and speedup inference. ORT also places the most computationally intensive operations on the GPU and the rest on the CPU to intelligently distribute the workload between the two devices.
ORT is supported by 🤗 Optimum which can be used in 🤗 Transformers. You'll need to use an [~optimum.onnxruntime.ORTModel] for the task you're solving, and specify the provider parameter which can be set to either CUDAExecutionProvider, ROCMExecutionProvider or TensorrtExecutionProvider. If you want to load a model that was not yet exported to ONNX, you can set export=True to convert your model on-the-fly to the ONNX format:
from optimum.onnxruntime import ORTModelForSequenceClassification
ort_model = ORTModelForSequenceClassification.from_pretrained(
"distilbert/distilbert-base-uncased-finetuned-sst-2-english",
export=True,
provider="CUDAExecutionProvider",
)
Now you're free to use the model for inference:
from optimum.pipelines import pipeline
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased-finetuned-sst-2-english")
pipeline = pipeline(task="text-classification", model=ort_model, tokenizer=tokenizer, device="cuda:0")
result = pipeline("Both the music and visual were astounding, not to mention the actors performance.")
Combine optimizations
It is often possible to combine several of the optimization techniques described above to get the best inference performance possible for your model. For example, you can load a model in 4-bit, and then enable BetterTransformer with FlashAttention:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# load model in 4-bit
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
# enable BetterTransformer
model = model.to_bettertransformer()
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
# enable FlashAttention
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))