* add sdpa * wip * cleaning * add ref * yet more cleaning * and more :) * wip llama * working llama * add output_attentions=True support * bigcode sdpa support * fixes * gpt-bigcode support, require torch>=2.1.1 * add falcon support * fix conflicts falcon * style * fix attention_mask definition * remove output_attentions from attnmaskconverter * support whisper without removing any Copied from statement * fix mbart default to eager renaming * fix typo in falcon * fix is_causal in SDPA * check is_flash_attn_2_available in the models init as well in case the model is not initialized through from_pretrained * add warnings when falling back on the manual implementation * precise doc * wip replace _flash_attn_enabled by config.attn_implementation * fix typo * add tests * style * add a copy.deepcopy on the config in from_pretrained, as we do not want to modify it inplace * obey to config.attn_implementation if a config is passed in from_pretrained * fix is_torch_sdpa_available when torch is not installed * remove dead code * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/models/bart/modeling_bart.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * remove duplicate pretraining_tp code * add dropout in llama * precise comment on attn_mask * add fmt: off for _unmask_unattended docstring * precise num_masks comment * nuke pretraining_tp in LlamaSDPAAttention following Arthur's suggestion * cleanup modeling_utils * backward compatibility * fix style as requested * style * improve documentation * test pass * style * add _unmask_unattended tests * skip meaningless tests for idefics * hard_check SDPA requirements when specifically requested * standardize the use if XXX_ATTENTION_CLASSES * fix SDPA bug with mem-efficient backend on CUDA when using fp32 * fix test * rely on SDPA is_causal parameter to handle the causal mask in some cases * fix FALCON_ATTENTION_CLASSES * remove _flash_attn_2_enabled occurences * fix test * add OPT to the list of supported flash models * improve test * properly test on different SDPA backends, on different dtypes & properly handle separately the pad tokens in the test * remove remaining _flash_attn_2_enabled occurence * Update src/transformers/modeling_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update docs/source/en/perf_infer_gpu_one.md Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * remove use_attn_implementation * fix docstring & slight bug * make attn_implementation internal (_attn_implementation) * typos * fix tests * deprecate use_flash_attention_2=True * fix test * add back llama that was removed by mistake * fix tests * remove _flash_attn_2_enabled occurences bis * add check & test that passed attn_implementation is valid * fix falcon torchscript export * fix device of mask in tests * add tip about torch.jit.trace and move bt doc below sdpa * fix parameterized.expand order * move tests from test_modeling_attn_mask_utils to test_modeling_utils as a relevant test class is already there * update sdpaattention class with the new cache * Update src/transformers/configuration_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/models/bark/modeling_bark.py * address review comments * WIP torch.jit.trace fix. left: test both eager & sdpa * add test for torch.jit.trace for both eager/sdpa * fix falcon with torch==2.0 that needs to use sdpa * fix doc * hopefully last fix * fix key_value_length that has no default now in mask converter * is it flacky? * fix speculative decoding bug * tests do pass * fix following #27907 --------- Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
4.7 KiB
GPT Neo
Overview
The GPTNeo model was released in the EleutherAI/gpt-neo repository by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy. It is a GPT2 like causal language model trained on the Pile dataset.
The architecture is similar to GPT2 except that GPT Neo uses local attention in every other layer with a window size of 256 tokens.
This model was contributed by valhalla.
Usage example
The generate() method can be used to generate text using GPT Neo model.
>>> from transformers import GPTNeoForCausalLM, GPT2Tokenizer
>>> model = GPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> tokenizer = GPT2Tokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> prompt = (
... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
... "researchers was the fact that the unicorns spoke perfect English."
... )
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
Combining GPT-Neo and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature, and make sure your hardware is compatible with Flash-Attention 2. More details are available here concerning the installation.
Make sure as well to load your model in half-precision (e.g. torch.float16).
To load and run a model using Flash Attention 2, refer to the snippet below:
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-2.7B", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-2.7B")
>>> prompt = "def hello_world():"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"def hello_world():\n >>> run_script("hello.py")\n >>> exit(0)\n<|endoftext|>"
Expected speedups
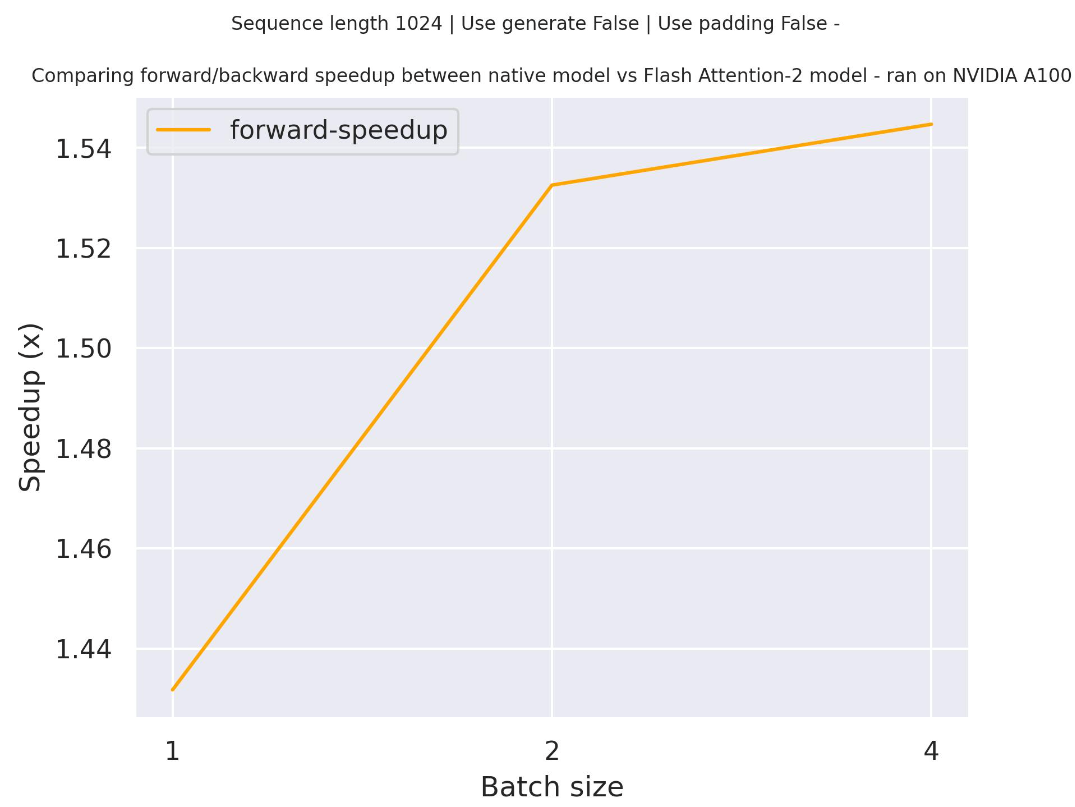
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using EleutherAI/gpt-neo-2.7B checkpoint and the Flash Attention 2 version of the model.
Note that for GPT-Neo it is not possible to train / run on very long context as the max position embeddings is limited to 2048 - but this is applicable to all gpt-neo models and not specific to FA-2
Resources
GPTNeoConfig
autodoc GPTNeoConfig
GPTNeoModel
autodoc GPTNeoModel - forward
GPTNeoForCausalLM
autodoc GPTNeoForCausalLM - forward
GPTNeoForQuestionAnswering
autodoc GPTNeoForQuestionAnswering - forward
GPTNeoForSequenceClassification
autodoc GPTNeoForSequenceClassification - forward
GPTNeoForTokenClassification
autodoc GPTNeoForTokenClassification - forward
FlaxGPTNeoModel
autodoc FlaxGPTNeoModel - call
FlaxGPTNeoForCausalLM
autodoc FlaxGPTNeoForCausalLM - call