* add sdpa * wip * cleaning * add ref * yet more cleaning * and more :) * wip llama * working llama * add output_attentions=True support * bigcode sdpa support * fixes * gpt-bigcode support, require torch>=2.1.1 * add falcon support * fix conflicts falcon * style * fix attention_mask definition * remove output_attentions from attnmaskconverter * support whisper without removing any Copied from statement * fix mbart default to eager renaming * fix typo in falcon * fix is_causal in SDPA * check is_flash_attn_2_available in the models init as well in case the model is not initialized through from_pretrained * add warnings when falling back on the manual implementation * precise doc * wip replace _flash_attn_enabled by config.attn_implementation * fix typo * add tests * style * add a copy.deepcopy on the config in from_pretrained, as we do not want to modify it inplace * obey to config.attn_implementation if a config is passed in from_pretrained * fix is_torch_sdpa_available when torch is not installed * remove dead code * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/models/bart/modeling_bart.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * remove duplicate pretraining_tp code * add dropout in llama * precise comment on attn_mask * add fmt: off for _unmask_unattended docstring * precise num_masks comment * nuke pretraining_tp in LlamaSDPAAttention following Arthur's suggestion * cleanup modeling_utils * backward compatibility * fix style as requested * style * improve documentation * test pass * style * add _unmask_unattended tests * skip meaningless tests for idefics * hard_check SDPA requirements when specifically requested * standardize the use if XXX_ATTENTION_CLASSES * fix SDPA bug with mem-efficient backend on CUDA when using fp32 * fix test * rely on SDPA is_causal parameter to handle the causal mask in some cases * fix FALCON_ATTENTION_CLASSES * remove _flash_attn_2_enabled occurences * fix test * add OPT to the list of supported flash models * improve test * properly test on different SDPA backends, on different dtypes & properly handle separately the pad tokens in the test * remove remaining _flash_attn_2_enabled occurence * Update src/transformers/modeling_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update docs/source/en/perf_infer_gpu_one.md Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * remove use_attn_implementation * fix docstring & slight bug * make attn_implementation internal (_attn_implementation) * typos * fix tests * deprecate use_flash_attention_2=True * fix test * add back llama that was removed by mistake * fix tests * remove _flash_attn_2_enabled occurences bis * add check & test that passed attn_implementation is valid * fix falcon torchscript export * fix device of mask in tests * add tip about torch.jit.trace and move bt doc below sdpa * fix parameterized.expand order * move tests from test_modeling_attn_mask_utils to test_modeling_utils as a relevant test class is already there * update sdpaattention class with the new cache * Update src/transformers/configuration_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/models/bark/modeling_bark.py * address review comments * WIP torch.jit.trace fix. left: test both eager & sdpa * add test for torch.jit.trace for both eager/sdpa * fix falcon with torch==2.0 that needs to use sdpa * fix doc * hopefully last fix * fix key_value_length that has no default now in mask converter * is it flacky? * fix speculative decoding bug * tests do pass * fix following #27907 --------- Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
7.8 KiB
Phi
Overview
The Phi-1 model was proposed in Textbooks Are All You Need by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li.
The Phi-1.5 model was proposed in Textbooks Are All You Need II: phi-1.5 technical report by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
Summary
In Phi-1 and Phi-1.5 papers, the authors showed how important the quality of the data is in training relative to the model size. They selected high quality "textbook" data alongside with synthetically generated data for training their small sized Transformer based model Phi-1 with 1.3B parameters. Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. They follow the same strategy for Phi-1.5 and created another 1.3B parameter model with performance on natural language tasks comparable to models 5x larger, and surpassing most non-frontier LLMs. Phi-1.5 exhibits many of the traits of much larger LLMs such as the ability to “think step by step” or perform some rudimentary in-context learning. With these two experiments the authors successfully showed the huge impact of quality of training data when training machine learning models.
The abstract from the Phi-1 paper is the following:
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of “textbook quality” data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.
The abstract from the Phi-1.5 paper is the following:
We continue the investigation into the power of smaller Transformer-based language models as initiated by TinyStories – a 10 million parameter model that can produce coherent English – and the follow-up work on phi-1, a 1.3 billion parameter model with Python coding performance close to the state-of-the-art. The latter work proposed to use existing Large Language Models (LLMs) to generate “textbook quality” data as a way to enhance the learning process compared to traditional web data. We follow the “Textbooks Are All You Need” approach, focusing this time on common sense reasoning in natural language, and create a new 1.3 billion parameter model named phi-1.5, with performance on natural language tasks comparable to models 5x larger, and surpassing most non-frontier LLMs on more complex reasoning tasks such as grade-school mathematics and basic coding. More generally, phi-1.5 exhibits many of the traits of much larger LLMs, both good –such as the ability to “think step by step” or perform some rudimentary in-context learning– and bad, including hallucinations and the potential for toxic and biased generations –encouragingly though, we are seeing improvement on that front thanks to the absence of web data. We open-source phi-1.5 to promote further research on these urgent topics.
This model was contributed by Susnato Dhar. The original code for Phi-1 and Phi-1.5 can be found here and here respectively.
Usage tips
- This model is quite similar to
Llamawith the main difference in [PhiDecoderLayer], where they used [PhiAttention] and [PhiMLP] layers in parallel configuration. - The tokenizer used for this model is identical to the [
CodeGenTokenizer].
Example :
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer.
>>> model = PhiForCausalLM.from_pretrained("susnato/phi-1_5_dev")
>>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-1_5_dev")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'
Combining Phi and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
pip install -U flash-attn --no-build-isolation
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
To load and run a model using Flash Attention 2, refer to the snippet below:
>>> import torch
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer and push the model and tokens to the GPU.
>>> model = PhiForCausalLM.from_pretrained("susnato/phi-1_5_dev", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda")
>>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-1_5_dev")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt").to("cuda")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'
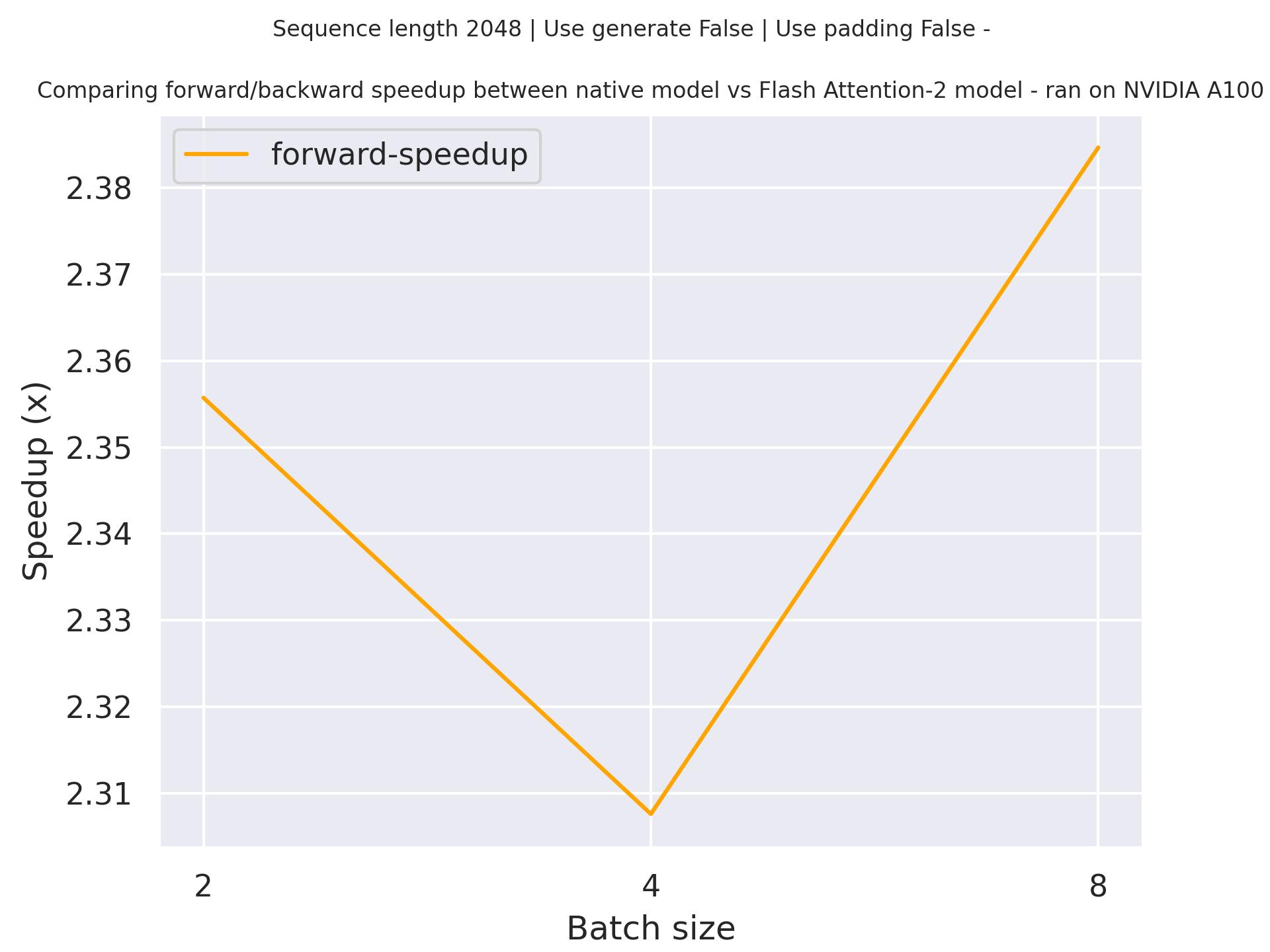
Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using susnato/phi-1_dev checkpoint and the Flash Attention 2 version of the model using a sequence length of 2048.
PhiConfig
autodoc PhiConfig
PhiModel
autodoc PhiModel - forward
PhiForCausalLM
autodoc PhiForCausalLM - forward - generate
PhiForSequenceClassification
autodoc PhiForSequenceClassification - forward
PhiForTokenClassification
autodoc PhiForTokenClassification - forward