* add sdpa * wip * cleaning * add ref * yet more cleaning * and more :) * wip llama * working llama * add output_attentions=True support * bigcode sdpa support * fixes * gpt-bigcode support, require torch>=2.1.1 * add falcon support * fix conflicts falcon * style * fix attention_mask definition * remove output_attentions from attnmaskconverter * support whisper without removing any Copied from statement * fix mbart default to eager renaming * fix typo in falcon * fix is_causal in SDPA * check is_flash_attn_2_available in the models init as well in case the model is not initialized through from_pretrained * add warnings when falling back on the manual implementation * precise doc * wip replace _flash_attn_enabled by config.attn_implementation * fix typo * add tests * style * add a copy.deepcopy on the config in from_pretrained, as we do not want to modify it inplace * obey to config.attn_implementation if a config is passed in from_pretrained * fix is_torch_sdpa_available when torch is not installed * remove dead code * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/models/bart/modeling_bart.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * remove duplicate pretraining_tp code * add dropout in llama * precise comment on attn_mask * add fmt: off for _unmask_unattended docstring * precise num_masks comment * nuke pretraining_tp in LlamaSDPAAttention following Arthur's suggestion * cleanup modeling_utils * backward compatibility * fix style as requested * style * improve documentation * test pass * style * add _unmask_unattended tests * skip meaningless tests for idefics * hard_check SDPA requirements when specifically requested * standardize the use if XXX_ATTENTION_CLASSES * fix SDPA bug with mem-efficient backend on CUDA when using fp32 * fix test * rely on SDPA is_causal parameter to handle the causal mask in some cases * fix FALCON_ATTENTION_CLASSES * remove _flash_attn_2_enabled occurences * fix test * add OPT to the list of supported flash models * improve test * properly test on different SDPA backends, on different dtypes & properly handle separately the pad tokens in the test * remove remaining _flash_attn_2_enabled occurence * Update src/transformers/modeling_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/modeling_attn_mask_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update docs/source/en/perf_infer_gpu_one.md Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * remove use_attn_implementation * fix docstring & slight bug * make attn_implementation internal (_attn_implementation) * typos * fix tests * deprecate use_flash_attention_2=True * fix test * add back llama that was removed by mistake * fix tests * remove _flash_attn_2_enabled occurences bis * add check & test that passed attn_implementation is valid * fix falcon torchscript export * fix device of mask in tests * add tip about torch.jit.trace and move bt doc below sdpa * fix parameterized.expand order * move tests from test_modeling_attn_mask_utils to test_modeling_utils as a relevant test class is already there * update sdpaattention class with the new cache * Update src/transformers/configuration_utils.py Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * Update src/transformers/models/bark/modeling_bark.py * address review comments * WIP torch.jit.trace fix. left: test both eager & sdpa * add test for torch.jit.trace for both eager/sdpa * fix falcon with torch==2.0 that needs to use sdpa * fix doc * hopefully last fix * fix key_value_length that has no default now in mask converter * is it flacky? * fix speculative decoding bug * tests do pass * fix following #27907 --------- Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
6.2 KiB
GPTBigCode
Overview
The GPTBigCode model was proposed in SantaCoder: don't reach for the stars! by BigCode. The listed authors are: Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
The abstract from the paper is the following:
The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at this https URL.
The model is an optimized GPT2 model with support for Multi-Query Attention.
Implementation details
The main differences compared to GPT2.
- Added support for Multi-Query Attention.
- Use
gelu_pytorch_tanhinstead of classicgelu. - Avoid unnecessary synchronizations (this has since been added to GPT2 in #20061, but wasn't in the reference codebase).
- Use Linear layers instead of Conv1D (good speedup but makes the checkpoints incompatible).
- Merge
_attnand_upcast_and_reordered_attn. Always merge the matmul with scaling. Renamereorder_and_upcast_attn->attention_softmax_in_fp32 - Cache the attention mask value to avoid recreating it every time.
- Use jit to fuse the attention fp32 casting, masking, softmax, and scaling.
- Combine the attention and causal masks into a single one, pre-computed for the whole model instead of every layer.
- Merge the key and value caches into one (this changes the format of layer_past/ present, does it risk creating problems?)
- Use the memory layout (self.num_heads, 3, self.head_dim) instead of
(3, self.num_heads, self.head_dim)for the QKV tensor with MHA. (prevents an overhead with the merged key and values, but makes the checkpoints incompatible with the original gpt2 model).
You can read more about the optimizations in the original pull request
Combining Starcoder and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
pip install -U flash-attn --no-build-isolation
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
To load and run a model using Flash Attention 2, refer to the snippet below:
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("bigcode/gpt_bigcode-santacoder", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("bigcode/gpt_bigcode-santacoder")
>>> prompt = "def hello_world():"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
>>> tokenizer.batch_decode(generated_ids)[0]
'def hello_world():\n print("hello world")\n\nif __name__ == "__main__":\n print("hello world")\n<|endoftext|>'
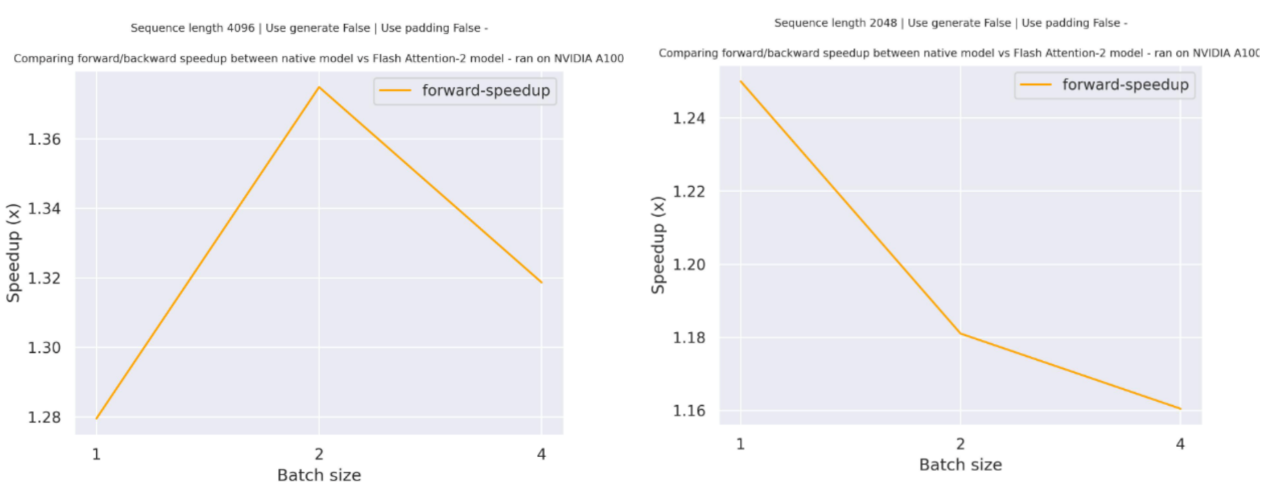
Expected speedups
Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using bigcode/starcoder checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
GPTBigCodeConfig
autodoc GPTBigCodeConfig
GPTBigCodeModel
autodoc GPTBigCodeModel - forward
GPTBigCodeForCausalLM
autodoc GPTBigCodeForCausalLM - forward
GPTBigCodeForSequenceClassification
autodoc GPTBigCodeForSequenceClassification - forward
GPTBigCodeForTokenClassification
autodoc GPTBigCodeForTokenClassification - forward