| .. | ||
| README.md | ||
| requirements.txt | ||
| run_mae.py | ||
Image pretraining examples
NOTE: If you encounter problems/have suggestions for improvement, open an issue on Github and tag @NielsRogge.
This directory contains a script, run_mae.py, that can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in Masked Autoencoders Are Scalable Vision Learners. The script can be used to train a ViTMAEForPreTraining model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a ViTForImageClassification. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
The goal for the model is to predict raw pixel values for the masked patches. As the model internally masks patches and learns to reconstruct them, there's no need for any labels. The model uses the mean squared error (MSE) between the reconstructed and original images in the pixel space.
Using datasets from 🤗 datasets
One can use the following command to pre-train a ViTMAEForPreTraining model from scratch on the cifar10 dataset:
python run_mae.py \
--dataset_name cifar10 \
--output_dir ./vit-mae-demo \
--remove_unused_columns False \
--label_names pixel_values \
--mask_ratio 0.75 \
--norm_pix_loss \
--do_train \
--do_eval \
--base_learning_rate 1.5e-4 \
--lr_scheduler_type cosine \
--weight_decay 0.05 \
--num_train_epochs 800 \
--warmup_ratio 0.05 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 10 \
--evaluation_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337
Here we set:
mask_ratioto 0.75 (to mask 75% of the patches for each image)norm_pix_lossto use normalized pixel values as target (the authors reported better representations with this enabled)base_learning_rateto 1.5e-4. Note that the effective learning rate is computed by the linear schedule:lr=blr* total training batch size / 256. The total training batch size is computed astraining_args.train_batch_size*training_args.gradient_accumulation_steps*training_args.world_size.
This replicates the same hyperparameters as used in the original implementation, as shown in the table below.
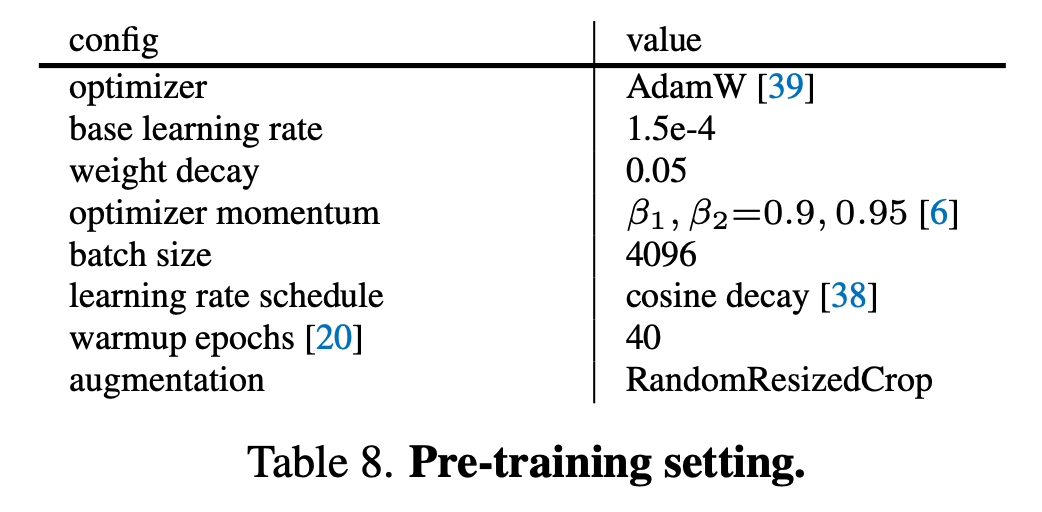
Original hyperparameters. Taken from the original paper.
Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the hub. This can be done by setting the model_name_or_path argument to "facebook/vit-mae-base" for example.
Using your own data
To use your own dataset, the training script expects the following directory structure:
root/dog/xxx.png
root/dog/xxy.png
root/dog/[...]/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/[...]/asd932_.png
Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
python run_mae.py \
--model_type vit_mae \
--dataset_name nateraw/image-folder \
--train_dir <path-to-train-root> \
--output_dir ./outputs/ \
--remove_unused_columns False \
--label_names pixel_values \
--do_train \
--do_eval
💡 The above will split the train dir into training and evaluation sets
- To control the split amount, use the
--train_val_splitflag. - To provide your own validation split in its own directory, you can pass the
--validation_dir <path-to-val-root>flag.
Sharing your model on 🤗 Hub
-
If you haven't already, sign up for a 🤗 account
-
Make sure you have
git-lfsinstalled and git set up.
$ apt install git-lfs
$ git config --global user.email "you@example.com"
$ git config --global user.name "Your Name"
- Log in with your HuggingFace account credentials using
huggingface-cli
$ huggingface-cli login
# ...follow the prompts
- When running the script, pass the following arguments:
python run_mae.py \
--push_to_hub \
--push_to_hub_model_id <name-of-your-model> \
...