* toctree * not-doctested.txt * collapse sections * feedback * update * rewrite get started sections * fixes * fix * loading models * fix * customize models * share * fix link * contribute part 1 * contribute pt 2 * fix toctree * tokenization pt 1 * Add new model (#32615) * v1 - working version * fix * fix * fix * fix * rename to correct name * fix title * fixup * rename files * fix * add copied from on tests * rename to `FalconMamba` everywhere and fix bugs * fix quantization + accelerate * fix copies * add `torch.compile` support * fix tests * fix tests and add slow tests * copies on config * merge the latest changes * fix tests * add few lines about instruct * Apply suggestions from code review Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * fix * fix tests --------- Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * "to be not" -> "not to be" (#32636) * "to be not" -> "not to be" * Update sam.md * Update trainer.py * Update modeling_utils.py * Update test_modeling_utils.py * Update test_modeling_utils.py * fix hfoption tag * tokenization pt. 2 * image processor * fix toctree * backbones * feature extractor * fix file name * processor * update not-doctested * update * make style * fix toctree * revision * make fixup * fix toctree * fix * make style * fix hfoption tag * pipeline * pipeline gradio * pipeline web server * add pipeline * fix toctree * not-doctested * prompting * llm optims * fix toctree * fixes * cache * text generation * fix * chat pipeline * chat stuff * xla * torch.compile * cpu inference * toctree * gpu inference * agents and tools * gguf/tiktoken * finetune * toctree * trainer * trainer pt 2 * optims * optimizers * accelerate * parallelism * fsdp * update * distributed cpu * hardware training * gpu training * gpu training 2 * peft * distrib debug * deepspeed 1 * deepspeed 2 * chat toctree * quant pt 1 * quant pt 2 * fix toctree * fix * fix * quant pt 3 * quant pt 4 * serialization * torchscript * scripts * tpu * review * model addition timeline * modular * more reviews * reviews * fix toctree * reviews reviews * continue reviews * more reviews * modular transformers * more review * zamba2 * fix * all frameworks * pytorch * supported model frameworks * flashattention * rm check_table * not-doctested.txt * rm check_support_list.py * feedback * updates/feedback * review * feedback * fix * update * feedback * updates * update --------- Co-authored-by: Younes Belkada <49240599+younesbelkada@users.noreply.github.com> Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> Co-authored-by: Quentin Gallouédec <45557362+qgallouedec@users.noreply.github.com>
6.8 KiB
OWL-ViT
Overview
The OWL-ViT (short for Vision Transformer for Open-World Localization) was proposed in Simple Open-Vocabulary Object Detection with Vision Transformers by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. OWL-ViT is an open-vocabulary object detection network trained on a variety of (image, text) pairs. It can be used to query an image with one or multiple text queries to search for and detect target objects described in text.
The abstract from the paper is the following:
Combining simple architectures with large-scale pre-training has led to massive improvements in image classification. For object detection, pre-training and scaling approaches are less well established, especially in the long-tailed and open-vocabulary setting, where training data is relatively scarce. In this paper, we propose a strong recipe for transferring image-text models to open-vocabulary object detection. We use a standard Vision Transformer architecture with minimal modifications, contrastive image-text pre-training, and end-to-end detection fine-tuning. Our analysis of the scaling properties of this setup shows that increasing image-level pre-training and model size yield consistent improvements on the downstream detection task. We provide the adaptation strategies and regularizations needed to attain very strong performance on zero-shot text-conditioned and one-shot image-conditioned object detection. Code and models are available on GitHub.
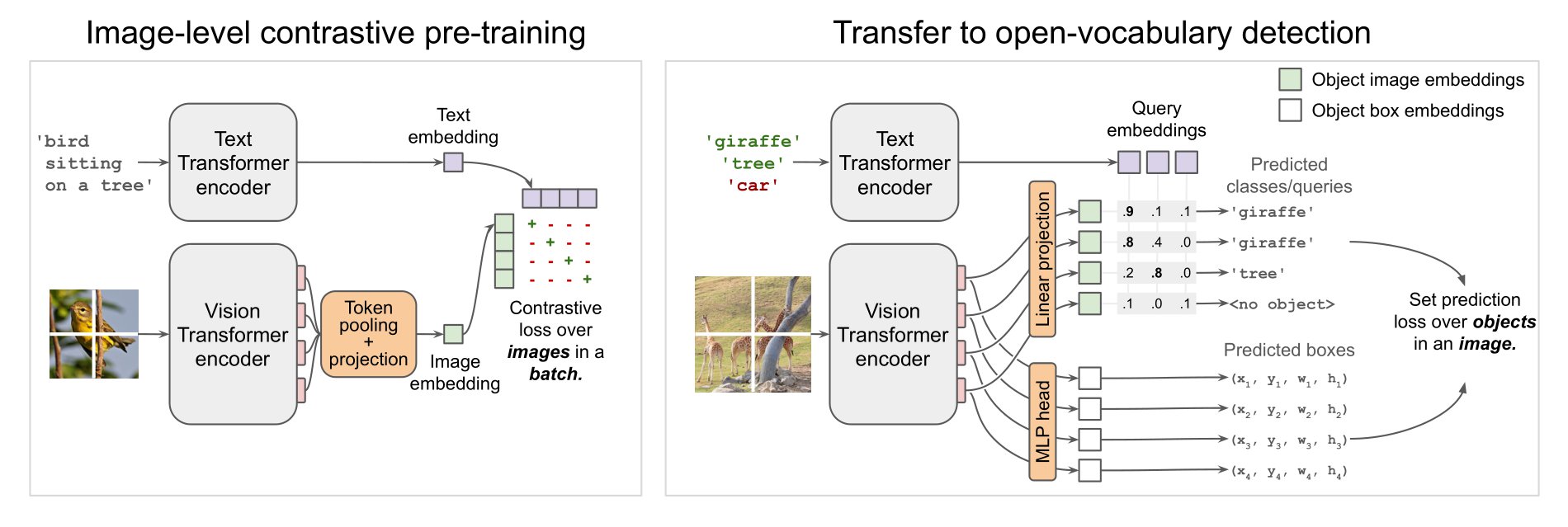
OWL-ViT architecture. Taken from the original paper.
This model was contributed by adirik. The original code can be found here.
Usage tips
OWL-ViT is a zero-shot text-conditioned object detection model. OWL-ViT uses CLIP as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[OwlViTImageProcessor] can be used to resize (or rescale) and normalize images for the model and [CLIPTokenizer] is used to encode the text. [OwlViTProcessor] wraps [OwlViTImageProcessor] and [CLIPTokenizer] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [OwlViTProcessor] and [OwlViTForObjectDetection].
>>> import requests
>>> from PIL import Image
>>> import torch
>>> from transformers import OwlViTProcessor, OwlViTForObjectDetection
>>> processor = OwlViTProcessor.from_pretrained("google/owlvit-base-patch32")
>>> model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch32")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text_labels = [["a photo of a cat", "a photo of a dog"]]
>>> inputs = processor(text=text_labels, images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
>>> target_sizes = torch.tensor([(image.height, image.width)])
>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
>>> results = processor.post_process_grounded_object_detection(
... outputs=outputs, target_sizes=target_sizes, threshold=0.1, text_labels=text_labels
... )
>>> # Retrieve predictions for the first image for the corresponding text queries
>>> result = results[0]
>>> boxes, scores, text_labels = result["boxes"], result["scores"], result["text_labels"]
>>> for box, score, text_label in zip(boxes, scores, text_labels):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected {text_label} with confidence {round(score.item(), 3)} at location {box}")
Detected a photo of a cat with confidence 0.707 at location [324.97, 20.44, 640.58, 373.29]
Detected a photo of a cat with confidence 0.717 at location [1.46, 55.26, 315.55, 472.17]
Resources
A demo notebook on using OWL-ViT for zero- and one-shot (image-guided) object detection can be found here.
OwlViTConfig
autodoc OwlViTConfig - from_text_vision_configs
OwlViTTextConfig
autodoc OwlViTTextConfig
OwlViTVisionConfig
autodoc OwlViTVisionConfig
OwlViTImageProcessor
autodoc OwlViTImageProcessor - preprocess - post_process_object_detection - post_process_image_guided_detection
OwlViTProcessor
autodoc OwlViTProcessor - call - post_process_grounded_object_detection - post_process_image_guided_detection
OwlViTModel
autodoc OwlViTModel - forward - get_text_features - get_image_features
OwlViTTextModel
autodoc OwlViTTextModel - forward
OwlViTVisionModel
autodoc OwlViTVisionModel - forward
OwlViTForObjectDetection
autodoc OwlViTForObjectDetection - forward - image_guided_detection