* Fixed typo: insted to instead * Fixed typo: relase to release * Fixed typo: nighlty to nightly * Fixed typos: versatible, benchamarks, becnhmark to versatile, benchmark, benchmarks * Fixed typo in comment: quantizd to quantized * Fixed typo: architecutre to architecture * Fixed typo: contibution to contribution * Fixed typo: Presequities to Prerequisites * Fixed typo: faste to faster * Fixed typo: extendeding to extending * Fixed typo: segmetantion_maps to segmentation_maps * Fixed typo: Alternativelly to Alternatively * Fixed incorrectly defined variable: output to output_disabled * Fixed typo in library name: tranformers.onnx to transformers.onnx * Fixed missing import: import tensorflow as tf * Fixed incorrectly defined variable: token_tensor to tokens_tensor * Fixed missing import: import torch * Fixed incorrectly defined variable and typo: uromaize to uromanize * Fixed incorrectly defined variable and typo: uromaize to uromanize * Fixed typo in function args: numpy.ndarry to numpy.ndarray * Fixed Inconsistent Library Name: Torchscript to TorchScript * Fixed Inconsistent Class Name: OneformerProcessor to OneFormerProcessor * Fixed Inconsistent Class Named Typo: TFLNetForMultipleChoice to TFXLNetForMultipleChoice * Fixed Inconsistent Library Name Typo: Pytorch to PyTorch * Fixed Inconsistent Function Name Typo: captureWarning to captureWarnings * Fixed Inconsistent Library Name Typo: Pytorch to PyTorch * Fixed Inconsistent Class Name Typo: TrainingArgument to TrainingArguments * Fixed Inconsistent Model Name Typo: Swin2R to Swin2SR * Fixed Inconsistent Model Name Typo: EART to BERT * Fixed Inconsistent Library Name Typo: TensorFLow to TensorFlow * Fixed Broken Link for Speech Emotion Classification with Wav2Vec2 * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed minor missing word Typo * Fixed Punctuation: Two commas * Fixed Punctuation: No Space between XLM-R and is * Fixed Punctuation: No Space between [~accelerate.Accelerator.backward] and method * Added backticks to display model.fit() in codeblock * Added backticks to display openai-community/gpt2 in codeblock * Fixed Minor Typo: will to with * Fixed Minor Typo: is to are * Fixed Minor Typo: in to on * Fixed Minor Typo: inhibits to exhibits * Fixed Minor Typo: they need to it needs * Fixed Minor Typo: cast the load the checkpoints To load the checkpoints * Fixed Inconsistent Class Name Typo: TFCamembertForCasualLM to TFCamembertForCausalLM * Fixed typo in attribute name: outputs.last_hidden_states to outputs.last_hidden_state * Added missing verbosity level: fatal * Fixed Minor Typo: take To takes * Fixed Minor Typo: heuristic To heuristics * Fixed Minor Typo: setting To settings * Fixed Minor Typo: Content To Contents * Fixed Minor Typo: millions To million * Fixed Minor Typo: difference To differences * Fixed Minor Typo: while extract To which extracts * Fixed Minor Typo: Hereby To Here * Fixed Minor Typo: addition To additional * Fixed Minor Typo: supports To supported * Fixed Minor Typo: so that benchmark results TO as a consequence, benchmark * Fixed Minor Typo: a To an * Fixed Minor Typo: a To an * Fixed Minor Typo: Chain-of-though To Chain-of-thought
8.9 KiB
Load pretrained instances with an AutoClass
With so many different Transformer architectures, it can be challenging to create one for your checkpoint. As a part of 🤗 Transformers core philosophy to make the library easy, simple and flexible to use, an AutoClass automatically infers and loads the correct architecture from a given checkpoint. The from_pretrained() method lets you quickly load a pretrained model for any architecture so you don't have to devote time and resources to train a model from scratch. Producing this type of checkpoint-agnostic code means if your code works for one checkpoint, it will work with another checkpoint - as long as it was trained for a similar task - even if the architecture is different.
Remember, architecture refers to the skeleton of the model and checkpoints are the weights for a given architecture. For example, BERT is an architecture, while google-bert/bert-base-uncased is a checkpoint. Model is a general term that can mean either architecture or checkpoint.
In this tutorial, learn to:
- Load a pretrained tokenizer.
- Load a pretrained image processor
- Load a pretrained feature extractor.
- Load a pretrained processor.
- Load a pretrained model.
- Load a model as a backbone.
AutoTokenizer
Nearly every NLP task begins with a tokenizer. A tokenizer converts your input into a format that can be processed by the model.
Load a tokenizer with [AutoTokenizer.from_pretrained]:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
Then tokenize your input as shown below:
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
AutoImageProcessor
For vision tasks, an image processor processes the image into the correct input format.
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
AutoBackbone
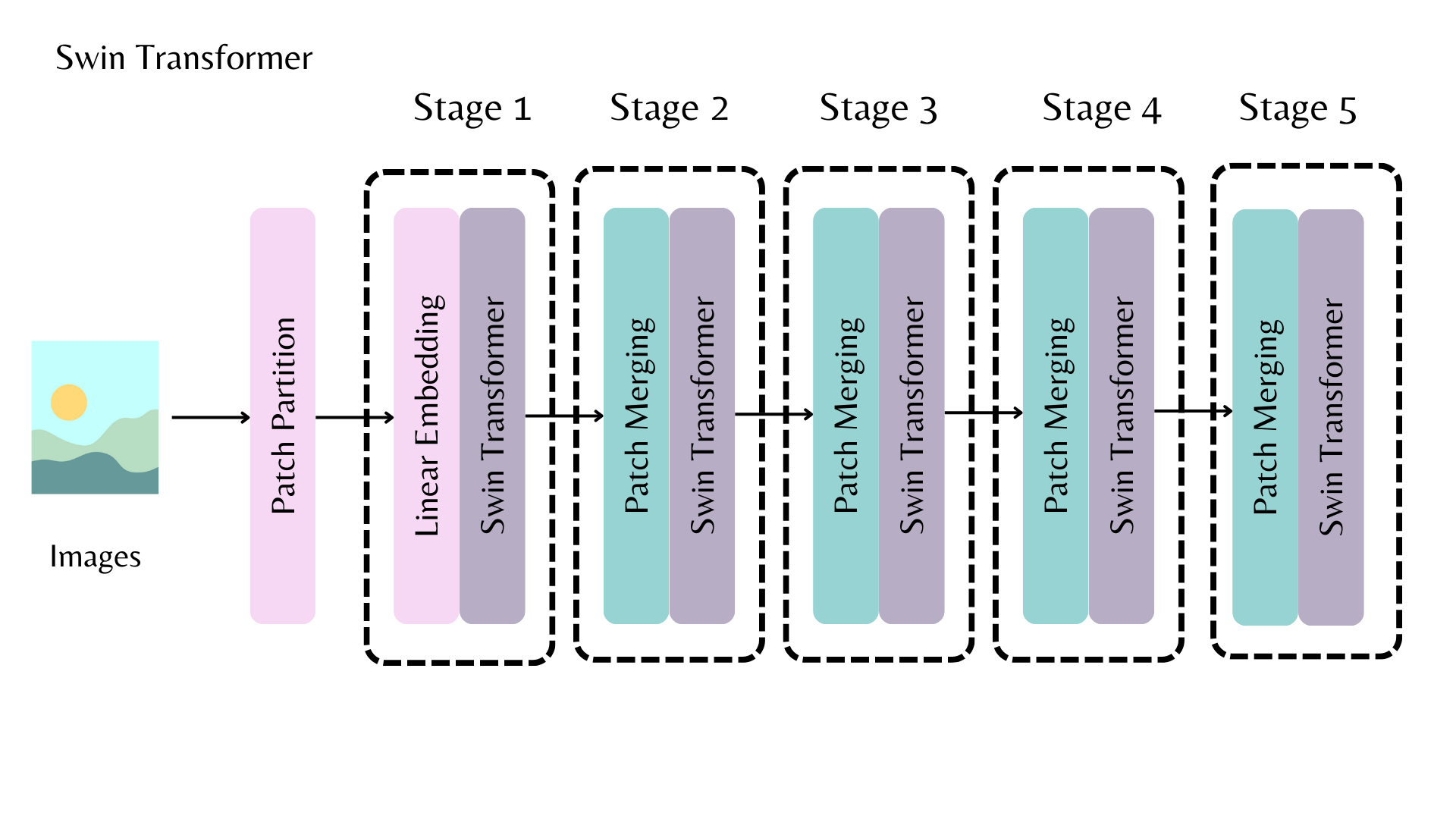
The [AutoBackbone] lets you use pretrained models as backbones to get feature maps from different stages of the backbone. You should specify one of the following parameters in [~PretrainedConfig.from_pretrained]:
out_indicesis the index of the layer you'd like to get the feature map fromout_featuresis the name of the layer you'd like to get the feature map from
These parameters can be used interchangeably, but if you use both, make sure they're aligned with each other! If you don't pass any of these parameters, the backbone returns the feature map from the last layer.
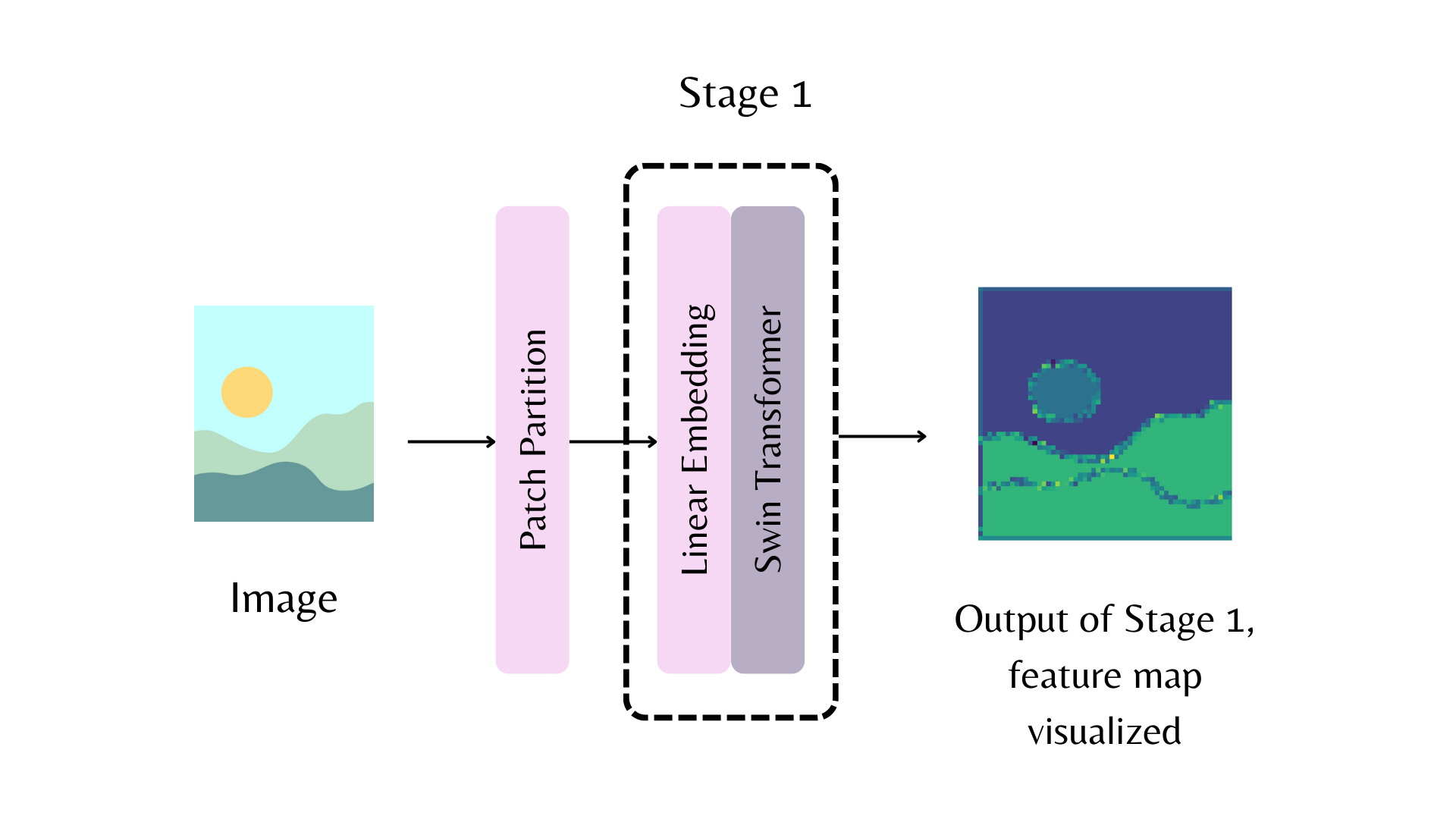
For example, in the above diagram, to return the feature map from the first stage of the Swin backbone, you can set out_indices=(1,):
>>> from transformers import AutoImageProcessor, AutoBackbone
>>> import torch
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
>>> model = AutoBackbone.from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(1,))
>>> inputs = processor(image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> feature_maps = outputs.feature_maps
Now you can access the feature_maps object from the first stage of the backbone:
>>> list(feature_maps[0].shape)
[1, 96, 56, 56]
AutoFeatureExtractor
For audio tasks, a feature extractor processes the audio signal into the correct input format.
Load a feature extractor with [AutoFeatureExtractor.from_pretrained]:
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
AutoProcessor
Multimodal tasks require a processor that combines two types of preprocessing tools. For example, the LayoutLMV2 model requires an image processor to handle images and a tokenizer to handle text; a processor combines both of them.
Load a processor with [AutoProcessor.from_pretrained]:
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
AutoModel
The `AutoModelFor` classes let you load a pretrained model for a given task (see [here](model_doc/auto) for a complete list of available tasks). For example, load a model for sequence classification with [`AutoModelForSequenceClassification.from_pretrained`]:>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
Easily reuse the same checkpoint to load an architecture for a different task:
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")
For PyTorch models, the from_pretrained() method uses torch.load() which internally uses pickle and is known to be insecure. In general, never load a model that could have come from an untrusted source, or that could have been tampered with. This security risk is partially mitigated for public models hosted on the Hugging Face Hub, which are scanned for malware at each commit. See the Hub documentation for best practices like signed commit verification with GPG.
TensorFlow and Flax checkpoints are not affected, and can be loaded within PyTorch architectures using the from_tf and from_flax kwargs for the from_pretrained method to circumvent this issue.
Generally, we recommend using the AutoTokenizer class and the AutoModelFor class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next tutorial, learn how to use your newly loaded tokenizer, image processor, feature extractor and processor to preprocess a dataset for fine-tuning.
Finally, the TFAutoModelFor classes let you load a pretrained model for a given task (see here for a complete list of available tasks). For example, load a model for sequence classification with [TFAutoModelForSequenceClassification.from_pretrained]:
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
Easily reuse the same checkpoint to load an architecture for a different task:
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")
Generally, we recommend using the AutoTokenizer class and the TFAutoModelFor class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next tutorial, learn how to use your newly loaded tokenizer, image processor, feature extractor and processor to preprocess a dataset for fine-tuning.