mirror of
https://github.com/huggingface/transformers.git
synced 2025-07-23 06:20:22 +06:00
* added template files for LXMERT and competed the configuration_lxmert.py * added modeling, tokization, testing, and finishing touched for lxmert [yet to be tested] * added model card for lxmert * cleaning up lxmert code * Update src/transformers/modeling_lxmert.py Co-authored-by: Lysandre Debut <lysandre@huggingface.co> * Update src/transformers/modeling_tf_lxmert.py Co-authored-by: Lysandre Debut <lysandre@huggingface.co> * Update src/transformers/modeling_tf_lxmert.py Co-authored-by: Lysandre Debut <lysandre@huggingface.co> * Update src/transformers/modeling_lxmert.py Co-authored-by: Lysandre Debut <lysandre@huggingface.co> * tested torch lxmert, changed documtention, updated outputs, and other small fixes * Update src/transformers/convert_pytorch_checkpoint_to_tf2.py Co-authored-by: Lysandre Debut <lysandre@huggingface.co> * Update src/transformers/convert_pytorch_checkpoint_to_tf2.py Co-authored-by: Lysandre Debut <lysandre@huggingface.co> * Update src/transformers/convert_pytorch_checkpoint_to_tf2.py Co-authored-by: Lysandre Debut <lysandre@huggingface.co> * renaming, other small issues, did not change TF code in this commit * added lxmert question answering model in pytorch * added capability to edit number of qa labels for lxmert * made answer optional for lxmert question answering * add option to return hidden_states for lxmert * changed default qa labels for lxmert * changed config archive path * squshing 3 commits: merged UI + testing improvments + more UI and testing * changed some variable names for lxmert * TF LXMERT * Various fixes to LXMERT * Final touches to LXMERT * AutoTokenizer order * Add LXMERT to index.rst and README.md * Merge commit test fixes + Style update * TensorFlow 2.3.0 sequential model changes variable names Remove inherited test * Update src/transformers/modeling_tf_pytorch_utils.py * Update docs/source/model_doc/lxmert.rst Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com> * Update docs/source/model_doc/lxmert.rst Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com> * Update src/transformers/modeling_tf_lxmert.py Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com> * added suggestions * Fixes * Final fixes for TF model * Fix docs Co-authored-by: Lysandre Debut <lysandre@huggingface.co> Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr> Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
1.8 KiB
1.8 KiB
LXMERT
Model Description
LXMERT is a pre-trained multimodal transformer. The model takes an image and a sentence as input and compute cross-modal representions. The model is converted from LXMERT github by Antonio Mendoza and is authored by Hao Tan.
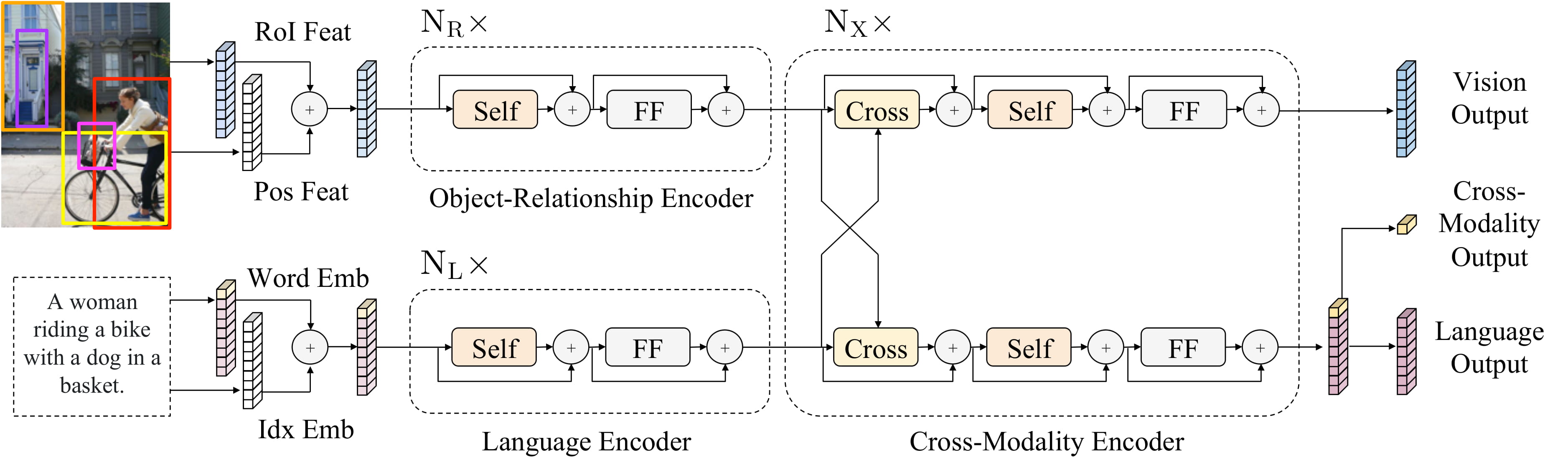
Usage
Training Data and Prodcedure
The model is jointly trained on multiple vision-and-language datasets. We included two image captioning datsets (i.e., MS COCO, Visual Genome) and three image-question answering datasets (i.e., VQA, GQA, VG QA). The model is pre-trained on the above datasets for 20 epochs (roughly 670K iterations with batch size 256), which takes around 8 days on 4 Titan V cards. The details of training could be found in the LXMERT paper.
Eval Results
| Split | VQA | GQA | NLVR2 |
|---|---|---|---|
| Local Validation | 69.90% | 59.80% | 74.95% |
| Test-Dev | 72.42% | 60.00% | 74.45% (Test-P) |
| Test-Standard | 72.54% | 60.33% | 76.18% (Test-U) |
Reference
@inproceedings{tan2019lxmert,
title={LXMERT: Learning Cross-Modality Encoder Representations from Transformers},
author={Tan, Hao and Bansal, Mohit},
booktitle={Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing},
year={2019}
}