* toctree * not-doctested.txt * collapse sections * feedback * update * rewrite get started sections * fixes * fix * loading models * fix * customize models * share * fix link * contribute part 1 * contribute pt 2 * fix toctree * tokenization pt 1 * Add new model (#32615) * v1 - working version * fix * fix * fix * fix * rename to correct name * fix title * fixup * rename files * fix * add copied from on tests * rename to `FalconMamba` everywhere and fix bugs * fix quantization + accelerate * fix copies * add `torch.compile` support * fix tests * fix tests and add slow tests * copies on config * merge the latest changes * fix tests * add few lines about instruct * Apply suggestions from code review Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * fix * fix tests --------- Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * "to be not" -> "not to be" (#32636) * "to be not" -> "not to be" * Update sam.md * Update trainer.py * Update modeling_utils.py * Update test_modeling_utils.py * Update test_modeling_utils.py * fix hfoption tag * tokenization pt. 2 * image processor * fix toctree * backbones * feature extractor * fix file name * processor * update not-doctested * update * make style * fix toctree * revision * make fixup * fix toctree * fix * make style * fix hfoption tag * pipeline * pipeline gradio * pipeline web server * add pipeline * fix toctree * not-doctested * prompting * llm optims * fix toctree * fixes * cache * text generation * fix * chat pipeline * chat stuff * xla * torch.compile * cpu inference * toctree * gpu inference * agents and tools * gguf/tiktoken * finetune * toctree * trainer * trainer pt 2 * optims * optimizers * accelerate * parallelism * fsdp * update * distributed cpu * hardware training * gpu training * gpu training 2 * peft * distrib debug * deepspeed 1 * deepspeed 2 * chat toctree * quant pt 1 * quant pt 2 * fix toctree * fix * fix * quant pt 3 * quant pt 4 * serialization * torchscript * scripts * tpu * review * model addition timeline * modular * more reviews * reviews * fix toctree * reviews reviews * continue reviews * more reviews * modular transformers * more review * zamba2 * fix * all frameworks * pytorch * supported model frameworks * flashattention * rm check_table * not-doctested.txt * rm check_support_list.py * feedback * updates/feedback * review * feedback * fix * update * feedback * updates * update --------- Co-authored-by: Younes Belkada <49240599+younesbelkada@users.noreply.github.com> Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> Co-authored-by: Quentin Gallouédec <45557362+qgallouedec@users.noreply.github.com>
4.8 KiB
ConvNeXT
Overview
The ConvNeXT model was proposed in A ConvNet for the 2020s by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie. ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them.
The abstract from the paper is the following:
The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually "modernize" a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
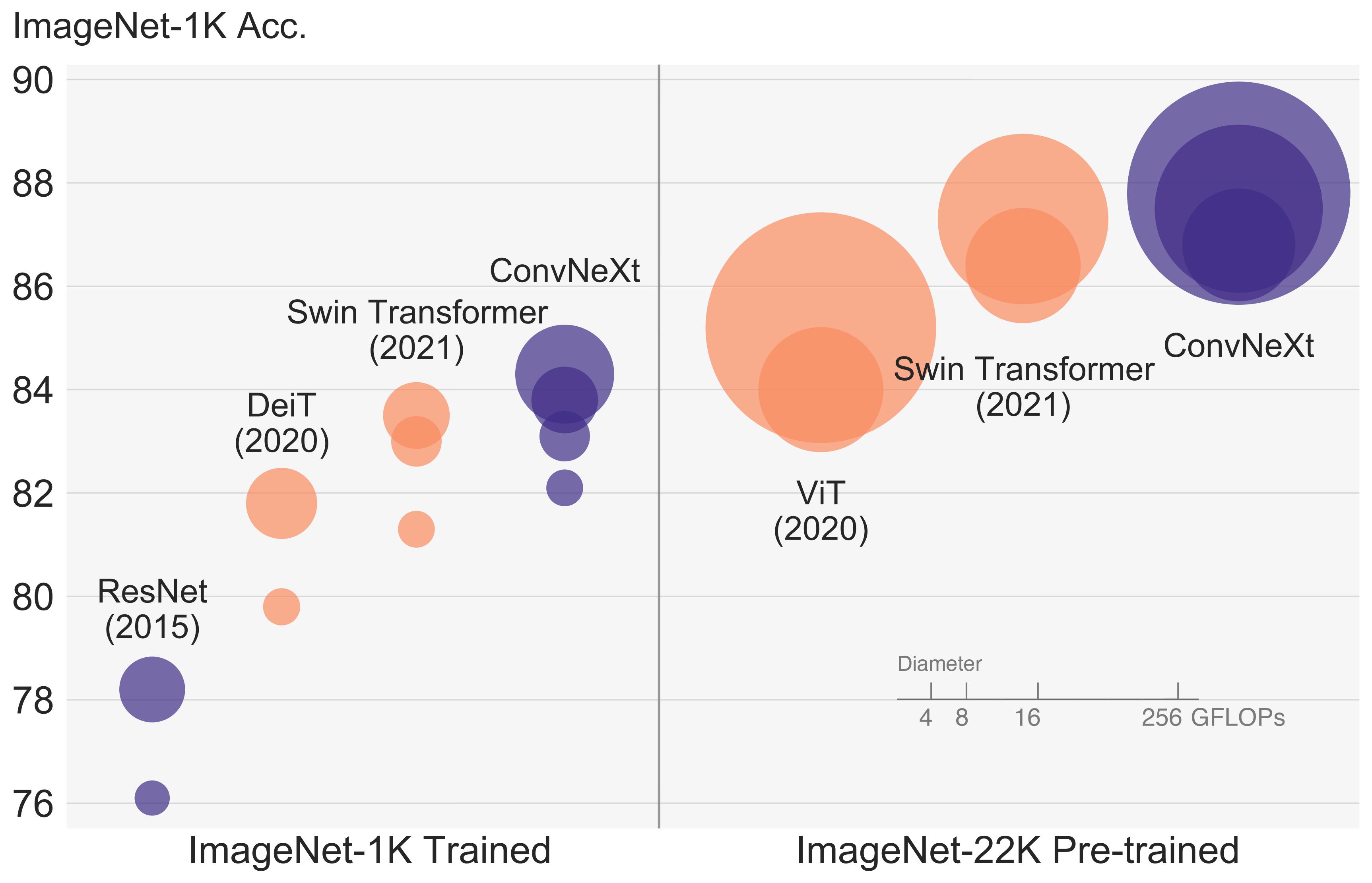
ConvNeXT architecture. Taken from the original paper.
This model was contributed by nielsr. TensorFlow version of the model was contributed by ariG23498, gante, and sayakpaul (equal contribution). The original code can be found here.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ConvNeXT.
- [
ConvNextForImageClassification] is supported by this example script and notebook. - See also: Image classification task guide
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
ConvNextConfig
autodoc ConvNextConfig
ConvNextFeatureExtractor
autodoc ConvNextFeatureExtractor
ConvNextImageProcessor
autodoc ConvNextImageProcessor - preprocess
ConvNextImageProcessorFast
autodoc ConvNextImageProcessorFast - preprocess
ConvNextModel
autodoc ConvNextModel - forward
ConvNextForImageClassification
autodoc ConvNextForImageClassification - forward
TFConvNextModel
autodoc TFConvNextModel - call
TFConvNextForImageClassification
autodoc TFConvNextForImageClassification - call