remove blank line (+1 squashed commit) Squashed commits: [24ccd2061] [run-slow]vit_msn,vision_encoder_decoder (+24 squashed commits) Squashed commits: [08bd27e7a] [run-slow]vit_msn,vision_encoder_decoder [ec96a8db3] [run-slow]vit_msn [ead817eca] fix vit msn multi gpu [d12cdc8fd] [run-slow]audio_spectrogram_transformer,deit,vision_encoder_decoder,vision_text_dual_encoder,vit,vit_hybrid,vit_mae,vit_msn,videomae,yolos [3fdbfa88f] doc [a3ff33e4a] finish implementation [e20b7b7fb] Update test_modeling_common.py [e290c5810] Update test_modeling_flax_common.py [d3af86f46] comment [ff7dd32d8] more comments [59b137889] suggestion [7e2ba6d67] attn_implementation as attribute of the class [fe66ab71f] minor [38642b568] Apply suggestions from code review Accept comments Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com> [22cde7d52] Update tests/test_modeling_common.py Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com> [48e137cc6] Update tests/test_modeling_common.py Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com> [99f4c679f] Update tests/test_modeling_common.py Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com> [96cf20a6d] Update src/transformers/models/vit_msn/modeling_vit_msn.py Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com> [c59377d23] Update src/transformers/models/vit_mae/modeling_vit_mae.py Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com> [b70a47259] Update tests/models/vision_text_dual_encoder/test_modeling_vision_text_dual_encoder.py Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com> [00c84d216] [run-slow]audio_spectrogram_transformer,deit,vision_encoder_decoder,vision_text_dual_encoder,vit,vit_hybrid,vit_mae,vit_msn,videomae,yolos [61f00ebb0] all tests are passing locally [e9e0b82b7] vision encoder/decoder [4d5076b56] test-vision (+20 squashed commits) Squashed commits: [d1add8db9] yolo [9fde65716] fix flax [986566c28] minor [ca2f21d1f] vit [3333efd7a] easy models change [ebfc21402] [run-slow]audio_spectrogram_transformer,deit,vision_encoder_decoder,vision_text_dual_encoder,vit,vit_hybrid,vit_mae,vit_msn,videomae,yolos [b8b8603ed] [run-slow]vision_encoder_decoder,vision_text_dual_encoder,yolos [48ecc7e26] all tests are passing locally [bff7fc366] minor [62f88306f] fix yolo and text_encoder tests [121507555] [run-slow]audio_spectrogram_transformer,deit,vit,vit_hybrid,vit_mae,vit_msn,videomae [1064cae0a] [run-slow]vision_encoder_decoder,vision_text_dual_encoder,yolos [b7f52ff3a] [run-slow]audio_spectrogram_transformer,deit,vit,vit_hybrid,vit_mae,vit_msn,videomae [cffaa10dd] fix-copies [ef6c511c4] test vit hybrid [7d4ba8644] vit hybrid [66f919033] [run-slow]audio_spectrogram_transformer,deit,vit,vit_hybrid,vit_mae,vit_msn,videomae [1fcc0a031] fixes [cfde6eb21] fixup [e77df1ed3] all except yolo end encoder decoder (+17 squashed commits) Squashed commits: [602913e22] vit + vit_mae are working [547f6c4cc] RUN_SLOW=1 pytest tests/models/audio_spectrogram_transformer/ tests/models/deit/ tests/models/videomae/ passes [61a97dfa9] it s the complete opposite... [aefab37d4] fix more tests [71802a1b9] fix all torch tests [40b12eb58] encoder - decoder tests [941552b69] slow decorator where appropriate [14d055d80] has_attentions to yolo and msn [3381fa19f] add correct name [e261316a7] repo consistency [31c6d0c08] fixup [9d214276c] minor fix [11ed2e1b7] chore [eca6644c4] add sdpa to vit-based models [cffbf390b] make fix-copies result [6468319b0] fix style [d324cd02a] add sdpa for vit Co-authored-by: Liubov Yaronskaya <luba.yaronskaya@gmail.com>
6.0 KiB
YOLOS
Overview
The YOLOS model was proposed in You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu. YOLOS proposes to just leverage the plain Vision Transformer (ViT) for object detection, inspired by DETR. It turns out that a base-sized encoder-only Transformer can also achieve 42 AP on COCO, similar to DETR and much more complex frameworks such as Faster R-CNN.
The abstract from the paper is the following:
Can Transformer perform 2D object- and region-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the 2D spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a series of object detection models based on the vanilla Vision Transformer with the fewest possible modifications, region priors, as well as inductive biases of the target task. We find that YOLOS pre-trained on the mid-sized ImageNet-1k dataset only can already achieve quite competitive performance on the challenging COCO object detection benchmark, e.g., YOLOS-Base directly adopted from BERT-Base architecture can obtain 42.0 box AP on COCO val. We also discuss the impacts as well as limitations of current pre-train schemes and model scaling strategies for Transformer in vision through YOLOS.
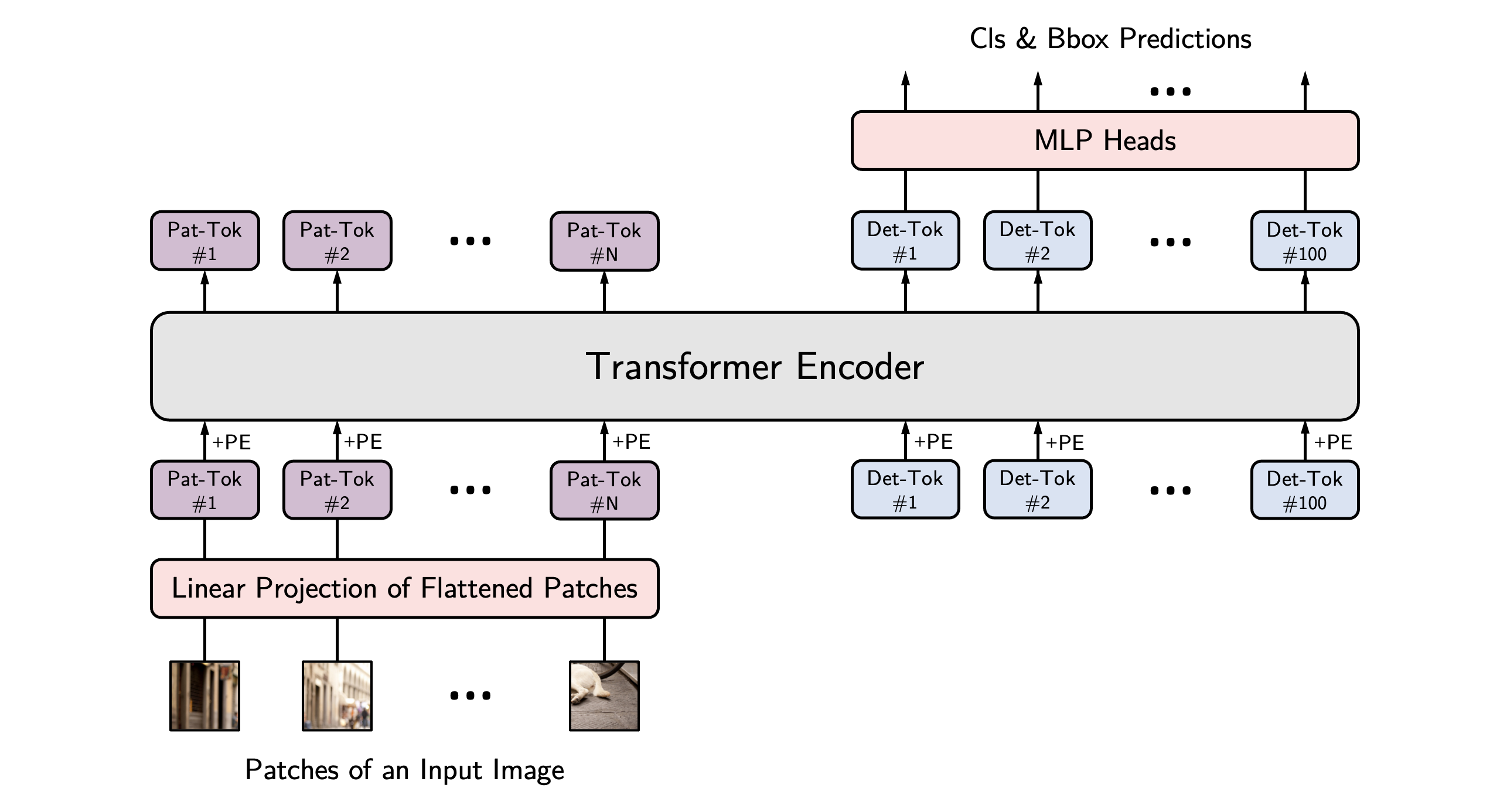
YOLOS architecture. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Using Scaled Dot Product Attention (SDPA)
PyTorch includes a native scaled dot-product attention (SDPA) operator as part of torch.nn.functional. This function
encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
official documentation
or the GPU Inference
page for more information.
SDPA is used by default for torch>=2.1.1 when an implementation is available, but you may also set
attn_implementation="sdpa" in from_pretrained() to explicitly request SDPA to be used.
from transformers import AutoModelForObjectDetection
model = AutoModelForObjectDetection.from_pretrained("hustvl/yolos-base", attn_implementation="sdpa", torch_dtype=torch.float16)
...
For the best speedups, we recommend loading the model in half-precision (e.g. torch.float16 or torch.bfloat16).
On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with float32 and hustvl/yolos-base model, we saw the following speedups during inference.
| Batch size | Average inference time (ms), eager mode | Average inference time (ms), sdpa model | Speed up, Sdpa / Eager (x) |
|---|---|---|---|
| 1 | 106 | 76 | 1.39 |
| 2 | 154 | 90 | 1.71 |
| 4 | 222 | 116 | 1.91 |
| 8 | 368 | 168 | 2.19 |
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with YOLOS.
- All example notebooks illustrating inference + fine-tuning [
YolosForObjectDetection] on a custom dataset can be found here. - Scripts for finetuning [
YolosForObjectDetection] with [Trainer] or Accelerate can be found here. - See also: Object detection task guide
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
Use [YolosImageProcessor] for preparing images (and optional targets) for the model. Contrary to DETR, YOLOS doesn't require a pixel_mask to be created.
YolosConfig
autodoc YolosConfig
YolosImageProcessor
autodoc YolosImageProcessor - preprocess - pad - post_process_object_detection
YolosFeatureExtractor
autodoc YolosFeatureExtractor - call - pad - post_process_object_detection
YolosModel
autodoc YolosModel - forward
YolosForObjectDetection
autodoc YolosForObjectDetection - forward