mirror of
https://github.com/huggingface/transformers.git
synced 2025-07-04 13:20:12 +06:00
* Just import torch AdamW instead * Update docs too * Make AdamW undocumented * make fixup * Add a basic wrapper class * Add it back to the docs * Just remove AdamW entirely * Remove some AdamW references * Drop AdamW from the public init * make fix-copies * Cleanup some references * make fixup * Delete lots of transformers.AdamW references * Remove extra references to adamw_hf
2.2 KiB
2.2 KiB
Optimization
.optimization 模块提供了:
- 一个带有固定权重衰减的优化器,可用于微调模型
- 继承自
_LRSchedule多个调度器: - 一个梯度累积类,用于累积多个批次的梯度
AdaFactor (PyTorch)
autodoc Adafactor
AdamWeightDecay (TensorFlow)
autodoc AdamWeightDecay
autodoc create_optimizer
Schedules
Learning Rate Schedules (Pytorch)
autodoc SchedulerType
autodoc get_scheduler
autodoc get_constant_schedule
autodoc get_constant_schedule_with_warmup
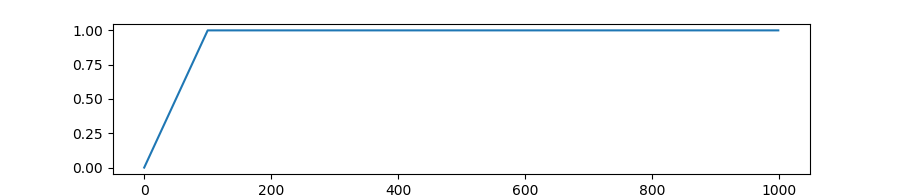
autodoc get_cosine_schedule_with_warmup
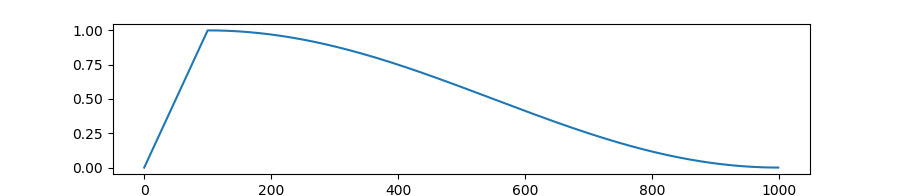
autodoc get_cosine_with_hard_restarts_schedule_with_warmup
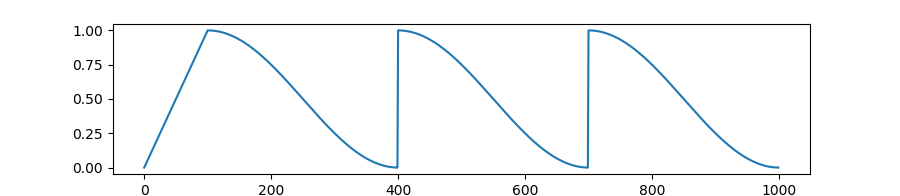
autodoc get_linear_schedule_with_warmup
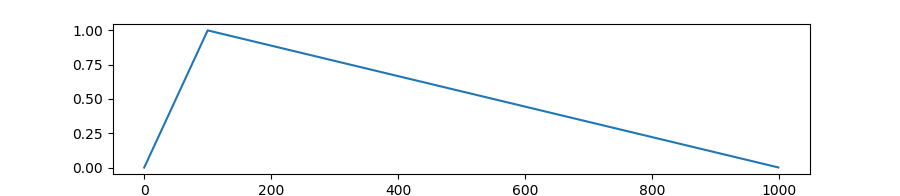
autodoc get_polynomial_decay_schedule_with_warmup
autodoc get_inverse_sqrt_schedule
Warmup (TensorFlow)
autodoc WarmUp
Gradient Strategies
GradientAccumulator (TensorFlow)
autodoc GradientAccumulator