* toctree * not-doctested.txt * collapse sections * feedback * update * rewrite get started sections * fixes * fix * loading models * fix * customize models * share * fix link * contribute part 1 * contribute pt 2 * fix toctree * tokenization pt 1 * Add new model (#32615) * v1 - working version * fix * fix * fix * fix * rename to correct name * fix title * fixup * rename files * fix * add copied from on tests * rename to `FalconMamba` everywhere and fix bugs * fix quantization + accelerate * fix copies * add `torch.compile` support * fix tests * fix tests and add slow tests * copies on config * merge the latest changes * fix tests * add few lines about instruct * Apply suggestions from code review Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * fix * fix tests --------- Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * "to be not" -> "not to be" (#32636) * "to be not" -> "not to be" * Update sam.md * Update trainer.py * Update modeling_utils.py * Update test_modeling_utils.py * Update test_modeling_utils.py * fix hfoption tag * tokenization pt. 2 * image processor * fix toctree * backbones * feature extractor * fix file name * processor * update not-doctested * update * make style * fix toctree * revision * make fixup * fix toctree * fix * make style * fix hfoption tag * pipeline * pipeline gradio * pipeline web server * add pipeline * fix toctree * not-doctested * prompting * llm optims * fix toctree * fixes * cache * text generation * fix * chat pipeline * chat stuff * xla * torch.compile * cpu inference * toctree * gpu inference * agents and tools * gguf/tiktoken * finetune * toctree * trainer * trainer pt 2 * optims * optimizers * accelerate * parallelism * fsdp * update * distributed cpu * hardware training * gpu training * gpu training 2 * peft * distrib debug * deepspeed 1 * deepspeed 2 * chat toctree * quant pt 1 * quant pt 2 * fix toctree * fix * fix * quant pt 3 * quant pt 4 * serialization * torchscript * scripts * tpu * review * model addition timeline * modular * more reviews * reviews * fix toctree * reviews reviews * continue reviews * more reviews * modular transformers * more review * zamba2 * fix * all frameworks * pytorch * supported model frameworks * flashattention * rm check_table * not-doctested.txt * rm check_support_list.py * feedback * updates/feedback * review * feedback * fix * update * feedback * updates * update --------- Co-authored-by: Younes Belkada <49240599+younesbelkada@users.noreply.github.com> Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> Co-authored-by: Quentin Gallouédec <45557362+qgallouedec@users.noreply.github.com>
5.6 KiB
PoolFormer
Overview
The PoolFormer model was proposed in MetaFormer is Actually What You Need for Vision by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
The abstract from the paper is the following:
Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.
The figure below illustrates the architecture of PoolFormer. Taken from the original paper.
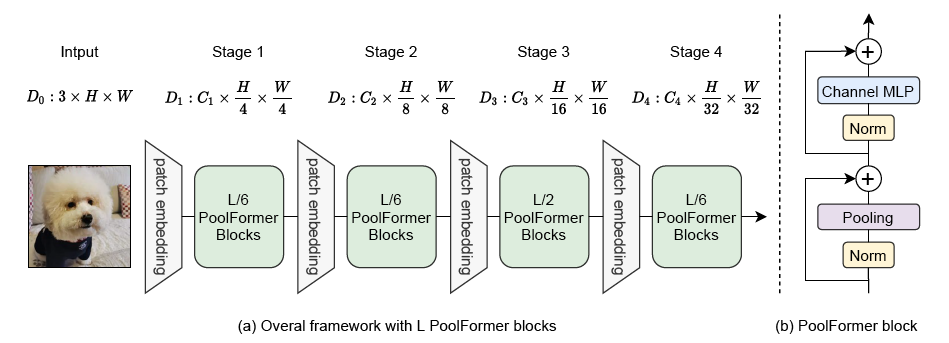
This model was contributed by heytanay. The original code can be found here.
Usage tips
- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the hub.
- One can use [
PoolFormerImageProcessor] to prepare images for the model. - As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
| Model variant | Depths | Hidden sizes | Params (M) | ImageNet-1k Top 1 |
|---|---|---|---|---|
| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
- [
PoolFormerForImageClassification] is supported by this example script and notebook. - See also: Image classification task guide
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
PoolFormerConfig
autodoc PoolFormerConfig
PoolFormerFeatureExtractor
autodoc PoolFormerFeatureExtractor - call
PoolFormerImageProcessor
autodoc PoolFormerImageProcessor - preprocess
PoolFormerModel
autodoc PoolFormerModel - forward
PoolFormerForImageClassification
autodoc PoolFormerForImageClassification - forward