* toctree * not-doctested.txt * collapse sections * feedback * update * rewrite get started sections * fixes * fix * loading models * fix * customize models * share * fix link * contribute part 1 * contribute pt 2 * fix toctree * tokenization pt 1 * Add new model (#32615) * v1 - working version * fix * fix * fix * fix * rename to correct name * fix title * fixup * rename files * fix * add copied from on tests * rename to `FalconMamba` everywhere and fix bugs * fix quantization + accelerate * fix copies * add `torch.compile` support * fix tests * fix tests and add slow tests * copies on config * merge the latest changes * fix tests * add few lines about instruct * Apply suggestions from code review Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * fix * fix tests --------- Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> * "to be not" -> "not to be" (#32636) * "to be not" -> "not to be" * Update sam.md * Update trainer.py * Update modeling_utils.py * Update test_modeling_utils.py * Update test_modeling_utils.py * fix hfoption tag * tokenization pt. 2 * image processor * fix toctree * backbones * feature extractor * fix file name * processor * update not-doctested * update * make style * fix toctree * revision * make fixup * fix toctree * fix * make style * fix hfoption tag * pipeline * pipeline gradio * pipeline web server * add pipeline * fix toctree * not-doctested * prompting * llm optims * fix toctree * fixes * cache * text generation * fix * chat pipeline * chat stuff * xla * torch.compile * cpu inference * toctree * gpu inference * agents and tools * gguf/tiktoken * finetune * toctree * trainer * trainer pt 2 * optims * optimizers * accelerate * parallelism * fsdp * update * distributed cpu * hardware training * gpu training * gpu training 2 * peft * distrib debug * deepspeed 1 * deepspeed 2 * chat toctree * quant pt 1 * quant pt 2 * fix toctree * fix * fix * quant pt 3 * quant pt 4 * serialization * torchscript * scripts * tpu * review * model addition timeline * modular * more reviews * reviews * fix toctree * reviews reviews * continue reviews * more reviews * modular transformers * more review * zamba2 * fix * all frameworks * pytorch * supported model frameworks * flashattention * rm check_table * not-doctested.txt * rm check_support_list.py * feedback * updates/feedback * review * feedback * fix * update * feedback * updates * update --------- Co-authored-by: Younes Belkada <49240599+younesbelkada@users.noreply.github.com> Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com> Co-authored-by: Quentin Gallouédec <45557362+qgallouedec@users.noreply.github.com>
4.5 KiB
CLIPSeg
Overview
The CLIPSeg model was proposed in Image Segmentation Using Text and Image Prompts by Timo Lüddecke and Alexander Ecker. CLIPSeg adds a minimal decoder on top of a frozen CLIP model for zero-shot and one-shot image segmentation.
The abstract from the paper is the following:
Image segmentation is usually addressed by training a model for a fixed set of object classes. Incorporating additional classes or more complex queries later is expensive as it requires re-training the model on a dataset that encompasses these expressions. Here we propose a system that can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text or an image. This approach enables us to create a unified model (trained once) for three common segmentation tasks, which come with distinct challenges: referring expression segmentation, zero-shot segmentation and one-shot segmentation. We build upon the CLIP model as a backbone which we extend with a transformer-based decoder that enables dense prediction. After training on an extended version of the PhraseCut dataset, our system generates a binary segmentation map for an image based on a free-text prompt or on an additional image expressing the query. We analyze different variants of the latter image-based prompts in detail. This novel hybrid input allows for dynamic adaptation not only to the three segmentation tasks mentioned above, but to any binary segmentation task where a text or image query can be formulated. Finally, we find our system to adapt well to generalized queries involving affordances or properties
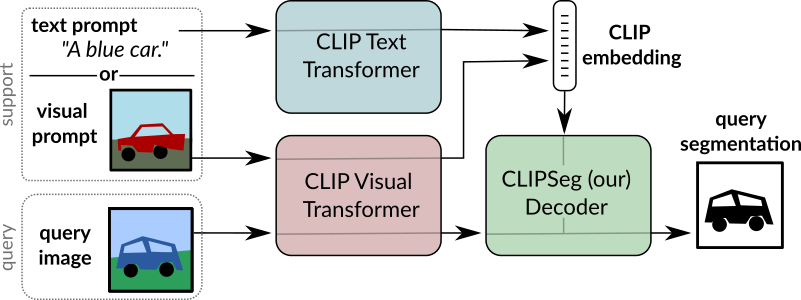
CLIPSeg overview. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Usage tips
- [
CLIPSegForImageSegmentation] adds a decoder on top of [CLIPSegModel]. The latter is identical to [CLIPModel]. - [
CLIPSegForImageSegmentation] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text (provided to the model asinput_ids) or an image (provided to the model asconditional_pixel_values). One can also provide custom conditional embeddings (provided to the model asconditional_embeddings).
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIPSeg. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- A notebook that illustrates zero-shot image segmentation with CLIPSeg.
CLIPSegConfig
autodoc CLIPSegConfig - from_text_vision_configs
CLIPSegTextConfig
autodoc CLIPSegTextConfig
CLIPSegVisionConfig
autodoc CLIPSegVisionConfig
CLIPSegProcessor
autodoc CLIPSegProcessor
CLIPSegModel
autodoc CLIPSegModel - forward - get_text_features - get_image_features
CLIPSegTextModel
autodoc CLIPSegTextModel - forward
CLIPSegVisionModel
autodoc CLIPSegVisionModel - forward
CLIPSegForImageSegmentation
autodoc CLIPSegForImageSegmentation - forward