* add sdpa to OPT
* chore: remove redundant whitespace in OPTDecoder class
* fixup
* bug fix
* add sdpa and attention generate test
* fixup
* Refactor OPTAttention forward method for improved readability and maintainability
* undo refactor for _shape and key,val states
* add OPT to doc, fixup didn't find it for some reason
* change order
* change default attn_implemntation in testing to eager
* [run-slow] opt
* change test_eager_matches_sdpa_generate to the one llama
* Update default attention implementation in testing common
* [run-slow] opt
* remove uneeded print
* [run-slow] opt
* refactor model testers to have attn_implementation="eager"
* [run-slow] opt
* convert test_eager_matches_sdpa_generate to opt-350M
* bug fix when creating mask for opt
* [run-slow] opt
* if layer head mask default to eager
* if head mask is not none fall to eager
* [run-slow] opt
* Update src/transformers/models/opt/modeling_opt.py
Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com>
* Clean up Unpack imports (#33631)
clean up Unpack imports
* Fix DPT /Dinov2 sdpa regression on main (#33660)
* fallback to eager if output attentions.
* fix copies
* handle dependency errors in check_imports (#33622)
* handle dependency errors in check_imports
* change log level to warning
* add back self.max_position_embeddings = config.max_position_embeddings (#33550)
* add back self.max_position_embeddings = config.max_position_embeddings
* fix-copies
* Fix Llava conversion for LlavaQwen2ForCausalLM with Clip vision tower (#33613)
fix llavaqwen2 model conversion
* Uniformize kwargs for Udop processor and update docs (#33628)
* Add optional kwargs and uniformize udop
* cleanup Unpack
* nit Udop
* Generation: deprecate `PreTrainedModel` inheriting from `GenerationMixin` (#33203)
* Enable BNB multi-backend support (#31098)
* enable cpu bnb path
* fix style
* fix code style
* fix 4 bit path
* Update src/transformers/utils/import_utils.py
Co-authored-by: Aarni Koskela <akx@iki.fi>
* add multi backend refactor tests
* fix style
* tweak 4bit quantizer + fix corresponding tests
* tweak 8bit quantizer + *try* fixing corresponding tests
* fix dequant bnb 8bit
* account for Intel CPU in variability of expected outputs
* enable cpu and xpu device map
* further tweaks to account for Intel CPU
* fix autocast to work with both cpu + cuda
* fix comments
* fix comments
* switch to testing_utils.torch_device
* allow for xpu in multi-gpu tests
* fix tests 4bit for CPU NF4
* fix bug with is_torch_xpu_available needing to be called as func
* avoid issue where test reports attr err due to other failure
* fix formatting
* fix typo from resolving of merge conflict
* polish based on last PR review
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
* fix CI
* Update src/transformers/integrations/integration_utils.py
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
* Update src/transformers/integrations/integration_utils.py
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
* fix error log
* fix error msg
* add \n in error log
* make quality
* rm bnb cuda restriction in doc
* cpu model don't need dispatch
* fix doc
* fix style
* check cuda avaliable in testing
* fix tests
* Update docs/source/en/model_doc/chameleon.md
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
* Update docs/source/en/model_doc/llava_next.md
Co-authored-by: Aarni Koskela <akx@iki.fi>
* Update tests/quantization/bnb/test_4bit.py
Co-authored-by: Aarni Koskela <akx@iki.fi>
* Update tests/quantization/bnb/test_4bit.py
Co-authored-by: Aarni Koskela <akx@iki.fi>
* fix doc
* fix check multibackends
* fix import sort
* remove check torch in bnb
* docs: update bitsandbytes references with multi-backend info
* docs: fix small mistakes in bnb paragraph
* run formatting
* reveret bnb check
* move bnb multi-backend check to import_utils
* Update src/transformers/utils/import_utils.py
Co-authored-by: Aarni Koskela <akx@iki.fi>
* fix bnb check
* minor fix for bnb
* check lib first
* fix code style
* Revert "run formatting"
This reverts commit ac108c6d6b.
* fix format
* give warning when bnb version is low and no cuda found]
* fix device assignment check to be multi-device capable
* address akx feedback on get_avlbl_dev fn
* revert partially, as we don't want the function that public, as docs would be too much (enforced)
---------
Co-authored-by: Aarni Koskela <akx@iki.fi>
Co-authored-by: Titus von Koeller <9048635+Titus-von-Koeller@users.noreply.github.com>
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
* Fix error string after refactoring into get_chat_template (#33652)
* Fix error string after refactoring into get_chat_template
* Take suggestion from CR
Co-authored-by: Matt <Rocketknight1@users.noreply.github.com>
---------
Co-authored-by: Matt <Rocketknight1@users.noreply.github.com>
* uniformize git processor (#33668)
* uniformize git processor
* update doctring
* Modular `transformers`: modularity and inheritance for new model additions (#33248)
* update exampel
* update
* push the converted diff files for testing and ci
* correct one example
* fix class attributes and docstring
* nits
* oups
* fixed config!
* update
* nitd
* class attributes are not matched against the other, this is missing
* fixed overwriting self.xxx now onto the attributes I think
* partial fix, now order with docstring
* fix docstring order?
* more fixes
* update
* fix missing docstrings!
* examples don't all work yet
* fixup
* nit
* updated
* hick
* update
* delete
* update
* update
* update
* fix
* all default
* no local import
* fix more diff
* some fix related to "safe imports"
* push fixed
* add helper!
* style
* add a check
* all by default
* add the
* update
* FINALLY!
* nit
* fix config dependencies
* man that is it
* fix fix
* update diffs
* fix the last issue
* re-default to all
* alll the fixes
* nice
* fix properties vs setter
* fixup
* updates
* update dependencies
* make sure to install what needs to be installed
* fixup
* quick fix for now
* fix!
* fixup
* update
* update
* updates
* whitespaces
* nit
* fix
* simplify everything, and make it file agnostic (should work for image processors)
* style
* finish fixing all import issues
* fixup
* empty modeling should not be written!
* Add logic to find who depends on what
* update
* cleanup
* update
* update gemma to support positions
* some small nits
* this is the correct docstring for gemma2
* fix merging of docstrings
* update
* fixup
* update
* take doc into account
* styling
* update
* fix hidden activation
* more fixes
* final fixes!
* fixup
* fixup instruct blip video
* update
* fix bugs
* align gemma2 with the rest as well
* updats
* revert
* update
* more reversiom
* grind
* more
* arf
* update
* order will matter
* finish del stuff
* update
* rename to modular
* fixup
* nits
* update makefile
* fixup
* update order of the checks!
* fix
* fix docstring that has a call inside
* fiix conversion check
* style
* add some initial documentation
* update
* update doc
* some fixup
* updates
* yups
* Mostly todo gimme a minut
* update
* fixup
* revert some stuff
* Review docs for the modular transformers (#33472)
Docs
* good update
* fixup
* mmm current updates lead to this code
* okay, this fixes it
* cool
* fixes
* update
* nit
* updates
* nits
* fix doc
* update
* revert bad changes
* update
* updates
* proper update
* update
* update?
* up
* update
* cool
* nits
* nits
* bon bon
* fix
* ?
* minimise changes
* update
* update
* update
* updates?
* fixed gemma2
* kind of a hack
* nits
* update
* remove `diffs` in favor of `modular`
* fix make fix copies
---------
Co-authored-by: Lysandre Debut <hi@lysand.re>
* Fix CIs post merging modular transformers (#33681)
update
* Fixed docstring for cohere model regarding unavailability of prune_he… (#33253)
* Fixed docstring for cohere model regarding unavailability of prune_head() methods
The docstring mentions that cohere model supports prune_heads() methods. I have fixed the docstring by explicitly mentioning that it doesn't support that functionality.
* Update src/transformers/models/cohere/modeling_cohere.py
---------
Co-authored-by: Lysandre Debut <hi@lysand.re>
* Generation tests: update imagegpt input name, remove unused functions (#33663)
* Improve Error Messaging for Flash Attention 2 on CPU (#33655)
Update flash-attn error message on CPU
Rebased to latest branch
* Gemma2: fix config initialization (`cache_implementation`) (#33684)
* Fix ByteLevel alphabet missing when Sequence pretokenizer is used (#33556)
* Fix ByteLevel alphabet missing when Sequence pretokenizer is used
* Fixed formatting with `ruff`.
* Uniformize kwargs for image-text-to-text processors (#32544)
* uniformize FUYU processor kwargs
* Uniformize instructblip processor kwargs
* Fix processor kwargs and tests Fuyu, InstructBlip, Kosmos2
* Uniformize llava_next processor
* Fix save_load test for processor with chat_template only as extra init args
* Fix import Unpack
* Fix Fuyu Processor import
* Fix FuyuProcessor import
* Fix FuyuProcessor
* Add defaults for specific kwargs kosmos2
* Fix Udop to return BatchFeature instead of BatchEncoding and uniformize kwargs
* Add tests processor Udop
* remove Copied from in processing Udop as change of input orders caused by BatchEncoding -> BatchFeature
* Fix overwrite tests kwargs processors
* Add warnings and BC for changes in processor inputs order, change docs, add BC for text_pair as arg for Udop
* Fix processing test fuyu
* remove unnecessary pad_token check in instructblip ProcessorTest
* Fix BC tests and cleanup
* FIx imports fuyu
* Uniformize Pix2Struct
* Fix wrong name for FuyuProcessorKwargs
* Fix slow tests reversed inputs align fuyu llava-next, change udop warning
* Fix wrong logging import udop
* Add check images text input order
* Fix copies
* change text pair handling when positional arg
* rebase on main, fix imports in test_processing_common
* remove optional args and udop uniformization from this PR
* fix failing tests
* remove unnecessary test, fix processing utils and test processing common
* cleanup Unpack
* cleanup
* fix conflict grounding dino
* 🚨🚨 Setting default behavior of assisted decoding (#33657)
* tests: fix pytorch tensor placement errors (#33485)
This commit fixes the following errors:
* Fix "expected all tensors to be on the same device" error
* Fix "can't convert device type tensor to numpy"
According to pytorch documentation torch.Tensor.numpy(force=False)
performs conversion only if tensor is on CPU (plus few other restrictions)
which is not the case. For our case we need force=True since we just
need a data and don't care about tensors coherency.
Fixes: #33517
See: https://pytorch.org/docs/2.4/generated/torch.Tensor.numpy.html
Signed-off-by: Dmitry Rogozhkin <dmitry.v.rogozhkin@intel.com>
* bump tokenizers, fix added tokens fast (#32535)
* update based on tokenizers release
* update
* nits
* update
* revert re addition
* don't break that yet
* fmt
* revert unwanted
* update tokenizers version
* update dep table
* update
* update in conversion script as well
* some fix
* revert
* fully revert
* fix training
* remove set trace
* fixup
* update
* update
* [Pixtral] Improve docs, rename model (#33491)
* Improve docs, rename model
* Fix style
* Update repo id
* fix code quality after merge
* HFQuantizer implementation for compressed-tensors library (#31704)
* Add compressed-tensors HFQuantizer implementation
* flag serializable as False
* run
* revive lines deleted by ruff
* fixes to load+save from sparseml, edit config to quantization_config, and load back
* address satrat comment
* compressed_tensors to compressed-tensors and revert back is_serializable
* rename quant_method from sparseml to compressed-tensors
* tests
* edit tests
* clean up tests
* make style
* cleanup
* cleanup
* add test skip for when compressed tensors is not installed
* remove pydantic import + style
* delay torch import in test
* initial docs
* update main init for compressed tensors config
* make fix-copies
* docstring
* remove fill_docstring
* Apply suggestions from code review
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
* review comments
* review comments
* comments - suppress warnings on state dict load, tests, fixes
* bug-fix - remove unnecessary call to apply quant lifecycle
* run_compressed compatability
* revert changes not needed for compression
* no longer need unexpected keys fn
* unexpected keys not needed either
* Apply suggestions from code review
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
* add to_diff_dict
* update docs and expand testing
* Update _toctree.yml with compressed-tensors
* Update src/transformers/utils/quantization_config.py
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
* update doc
* add note about saving a loaded model
---------
Co-authored-by: George Ohashi <george@neuralmagic.com>
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
Co-authored-by: Sara Adkins <sara@neuralmagic.com>
Co-authored-by: Sara Adkins <sara.adkins65@gmail.com>
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
Co-authored-by: Dipika Sikka <ds3822@columbia.edu>
Co-authored-by: Dipika <dipikasikka1@gmail.com>
* update model card for opt
* add batch size to inference table
* [slow-run] opt
* [run-slow] opt
---------
Signed-off-by: Dmitry Rogozhkin <dmitry.v.rogozhkin@intel.com>
Co-authored-by: Avishai Elmakies <avishai.elma@cs.huji.ac.il>
Co-authored-by: amyeroberts <22614925+amyeroberts@users.noreply.github.com>
Co-authored-by: Pablo Montalvo <39954772+molbap@users.noreply.github.com>
Co-authored-by: chengchengpei <5881383+chengchengpei@users.noreply.github.com>
Co-authored-by: Isotr0py <2037008807@qq.com>
Co-authored-by: Yoni Gozlan <74535834+yonigozlan@users.noreply.github.com>
Co-authored-by: Joao Gante <joaofranciscocardosogante@gmail.com>
Co-authored-by: jiqing-feng <jiqing.feng@intel.com>
Co-authored-by: Aarni Koskela <akx@iki.fi>
Co-authored-by: Titus von Koeller <9048635+Titus-von-Koeller@users.noreply.github.com>
Co-authored-by: Marc Sun <57196510+SunMarc@users.noreply.github.com>
Co-authored-by: Arthur <48595927+ArthurZucker@users.noreply.github.com>
Co-authored-by: Tibor Reiss <75096465+tibor-reiss@users.noreply.github.com>
Co-authored-by: Matt <Rocketknight1@users.noreply.github.com>
Co-authored-by: Lysandre Debut <hi@lysand.re>
Co-authored-by: Muhammad Naufil <m.naufil1@gmail.com>
Co-authored-by: sizhky <yyeshr@gmail.com>
Co-authored-by: Umar Butler <umar@umar.au>
Co-authored-by: Jonathan Mamou <jonathan.mamou@intel.com>
Co-authored-by: Dmitry Rogozhkin <dmitry.v.rogozhkin@intel.com>
Co-authored-by: NielsRogge <48327001+NielsRogge@users.noreply.github.com>
Co-authored-by: Arthur Zucker <arthur.zucker@gmail.com>
Co-authored-by: Benjamin Fineran <bfineran@users.noreply.github.com>
Co-authored-by: George Ohashi <george@neuralmagic.com>
Co-authored-by: Sara Adkins <sara@neuralmagic.com>
Co-authored-by: Sara Adkins <sara.adkins65@gmail.com>
Co-authored-by: Dipika Sikka <ds3822@columbia.edu>
Co-authored-by: Dipika <dipikasikka1@gmail.com>
16 KiB
OPT
Overview
The OPT model was proposed in Open Pre-trained Transformer Language Models by Meta AI. OPT is a series of open-sourced large causal language models which perform similar in performance to GPT3.
The abstract from the paper is the following:
Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.
This model was contributed by Arthur Zucker, Younes Belkada, and Patrick Von Platen. The original code can be found here.
Tips:
- OPT has the same architecture as [
BartDecoder]. - Contrary to GPT2, OPT adds the EOS token
</s>to the beginning of every prompt.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OPT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it. The resource should ideally demonstrate something new instead of duplicating an existing resource.
- A notebook on fine-tuning OPT with PEFT, bitsandbytes, and Transformers. 🌎
- A blog post on decoding strategies with OPT.
- Causal language modeling chapter of the 🤗 Hugging Face Course.
- [
OPTForCausalLM] is supported by this causal language modeling example script and notebook. - [
TFOPTForCausalLM] is supported by this causal language modeling example script and notebook. - [
FlaxOPTForCausalLM] is supported by this causal language modeling example script.
- Text classification task guide
- [
OPTForSequenceClassification] is supported by this example script and notebook.
- [
OPTForQuestionAnswering] is supported by this question answering example script and notebook. - Question answering chapter of the 🤗 Hugging Face Course.
⚡️ Inference
- A blog post on How 🤗 Accelerate runs very large models thanks to PyTorch with OPT.
Combining OPT and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
pip install -U flash-attn --no-build-isolation
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
To load and run a model using Flash Attention 2, refer to the snippet below:
>>> import torch
>>> from transformers import OPTForCausalLM, GPT2Tokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
>>> prompt = ("A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the "
"Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived "
"there?")
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
>>> tokenizer.batch_decode(generated_ids)[0]
'</s>A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived there?\nStatue: I have lived here for about a year.\nHuman: What is your favorite place to eat?\nStatue: I love'
Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using facebook/opt-2.7b checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
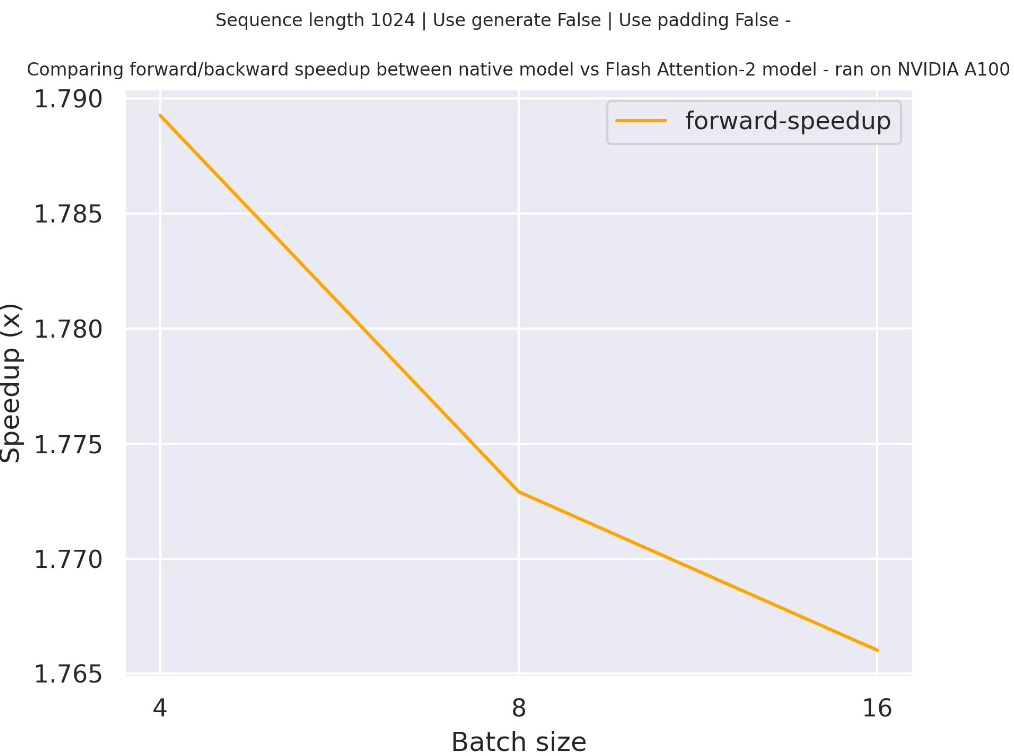
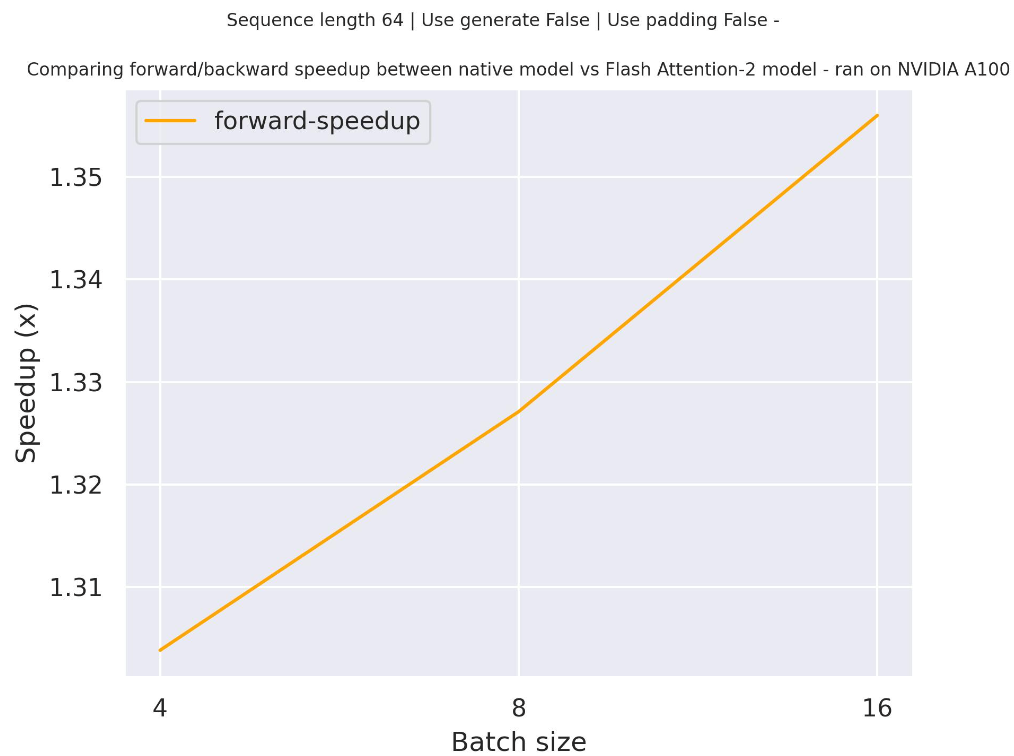
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using facebook/opt-350m checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
Using Scaled Dot Product Attention (SDPA)
PyTorch includes a native scaled dot-product attention (SDPA) operator as part of torch.nn.functional. This function
encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
official documentation
or the GPU Inference
page for more information.
SDPA is used by default for torch>=2.1.1 when an implementation is available, but you may also set
attn_implementation="sdpa" in from_pretrained() to explicitly request SDPA to be used.
from transformers import OPTForCausalLM
model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="sdpa")
...
For the best speedups, we recommend loading the model in half-precision (e.g. torch.float16 or torch.bfloat16).
On a local benchmark (L40S-45GB, PyTorch 2.4.0, OS Debian GNU/Linux 11) using float16 with
facebook/opt-350m, we saw the
following speedups during training and inference.
Training
| batch_size | seq_len | Time per batch (eager - s) | Time per batch (sdpa - s) | Speedup (%) | Eager peak mem (MB) | sdpa peak mem (MB) | Mem saving (%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 0.047 | 0.037 | 26.360 | 1474.611 | 1474.32 | 0.019 |
| 1 | 256 | 0.046 | 0.037 | 24.335 | 1498.541 | 1499.49 | -0.063 |
| 1 | 512 | 0.046 | 0.037 | 24.959 | 1973.544 | 1551.35 | 27.215 |
| 1 | 1024 | 0.062 | 0.038 | 65.135 | 4867.113 | 1698.35 | 186.578 |
| 1 | 2048 | 0.230 | 0.039 | 483.933 | 15662.224 | 2715.75 | 476.718 |
| 2 | 128 | 0.045 | 0.037 | 20.455 | 1498.164 | 1499.49 | -0.089 |
| 2 | 256 | 0.046 | 0.037 | 24.027 | 1569.367 | 1551.35 | 1.161 |
| 2 | 512 | 0.045 | 0.037 | 20.965 | 3257.074 | 1698.35 | 91.778 |
| 2 | 1024 | 0.122 | 0.038 | 225.958 | 9054.405 | 2715.75 | 233.403 |
| 2 | 2048 | 0.464 | 0.067 | 593.646 | 30572.058 | 4750.55 | 543.548 |
| 4 | 128 | 0.045 | 0.037 | 21.918 | 1549.448 | 1551.35 | -0.123 |
| 4 | 256 | 0.044 | 0.038 | 18.084 | 2451.768 | 1698.35 | 44.361 |
| 4 | 512 | 0.069 | 0.037 | 84.421 | 5833.180 | 2715.75 | 114.791 |
| 4 | 1024 | 0.262 | 0.062 | 319.475 | 17427.842 | 4750.55 | 266.860 |
| 4 | 2048 | OOM | 0.062 | Eager OOM | OOM | 4750.55 | Eager OOM |
| 8 | 128 | 0.044 | 0.037 | 18.436 | 2049.115 | 1697.78 | 20.694 |
| 8 | 256 | 0.048 | 0.036 | 32.887 | 4222.567 | 2715.75 | 55.484 |
| 8 | 512 | 0.153 | 0.06 | 154.862 | 10985.391 | 4750.55 | 131.245 |
| 8 | 1024 | 0.526 | 0.122 | 330.697 | 34175.763 | 8821.18 | 287.428 |
| 8 | 2048 | OOM | 0.122 | Eager OOM | OOM | 8821.18 | Eager OOM |
Inference
| batch_size | seq_len | Per token latency eager (ms) | Per token latency SDPA (ms) | Speedup (%) | Mem eager (MB) | Mem BT (MB) | Mem saved (%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 11.634 | 8.647 | 34.546 | 717.676 | 717.674 | 0 |
| 1 | 256 | 11.593 | 8.86 | 30.851 | 742.852 | 742.845 | 0.001 |
| 1 | 512 | 11.515 | 8.816 | 30.614 | 798.232 | 799.593 | -0.17 |
| 1 | 1024 | 11.556 | 8.915 | 29.628 | 917.265 | 895.538 | 2.426 |
| 2 | 128 | 12.724 | 11.002 | 15.659 | 762.434 | 762.431 | 0 |
| 2 | 256 | 12.704 | 11.063 | 14.83 | 816.809 | 816.733 | 0.009 |
| 2 | 512 | 12.757 | 10.947 | 16.535 | 917.383 | 918.339 | -0.104 |
| 2 | 1024 | 13.018 | 11.018 | 18.147 | 1162.65 | 1114.81 | 4.291 |
| 4 | 128 | 12.739 | 10.959 | 16.243 | 856.335 | 856.483 | -0.017 |
| 4 | 256 | 12.718 | 10.837 | 17.355 | 957.298 | 957.674 | -0.039 |
| 4 | 512 | 12.813 | 10.822 | 18.393 | 1158.44 | 1158.45 | -0.001 |
| 4 | 1024 | 13.416 | 11.06 | 21.301 | 1653.42 | 1557.19 | 6.18 |
| 8 | 128 | 12.763 | 10.891 | 17.193 | 1036.13 | 1036.51 | -0.036 |
| 8 | 256 | 12.89 | 11.104 | 16.085 | 1236.98 | 1236.87 | 0.01 |
| 8 | 512 | 13.327 | 10.939 | 21.836 | 1642.29 | 1641.78 | 0.031 |
| 8 | 1024 | 15.181 | 11.175 | 35.848 | 2634.98 | 2443.35 | 7.843 |
OPTConfig
autodoc OPTConfig
OPTModel
autodoc OPTModel - forward
OPTForCausalLM
autodoc OPTForCausalLM - forward
OPTForSequenceClassification
autodoc OPTForSequenceClassification - forward
OPTForQuestionAnswering
autodoc OPTForQuestionAnswering - forward
TFOPTModel
autodoc TFOPTModel - call
TFOPTForCausalLM
autodoc TFOPTForCausalLM - call
FlaxOPTModel
autodoc FlaxOPTModel - call
FlaxOPTForCausalLM
autodoc FlaxOPTForCausalLM - call