* Add first draft * Use appropriate gelu function * More improvements * More improvements * More improvements * Convert checkpoint * More improvements * Improve docs, remove print statements * More improvements * Add link * remove unused masking function * begin tokenizer * do_lower_case * debug * set split_special_tokens=True * Remove script * Fix style * Fix rebase * Use same design as CLIP * Add fast tokenizer * Add SiglipTokenizer to init, remove extra_ids * Improve conversion script * Use smaller inputs in conversion script * Update conversion script * More improvements * Add processor to conversion script * Add tests * Remove print statements * Add tokenizer tests * Fix more tests * More improvements related to weight initialization * More improvements * Make more tests pass * More improvements * More improvements * Add copied from * Add canonicalize_text * Enable fast tokenizer tests * More improvements * Fix most slow tokenizer tests * Address comments * Fix style * Remove script * Address some comments * Add copied from to tests * Add more copied from * Add more copied from * Add more copied from * Remove is_flax_available * More updates * Address comment * Remove SiglipTokenizerFast for now * Add caching * Remove umt5 test * Add canonicalize_text inside _tokenize, thanks Arthur * Fix image processor tests * Skip tests which are not applicable * Skip test_initialization * More improvements * Compare pixel values * Fix doc tests, add integration test * Add do_normalize * Remove causal mask and leverage ignore copy * Fix attention_mask * Fix remaining tests * Fix dummies * Rename temperature and bias * Address comments * Add copied from to tokenizer tests * Add SiglipVisionModel to auto mapping * Add copied from to image processor tests * Improve doc * Remove SiglipVisionModel from index * Address comments * Improve docs * Simplify config * Add first draft * Make it like mistral * More improvements * Fix attention_mask * Fix output_attentions * Add note in docs * Convert multilingual model * Convert large checkpoint * Convert more checkpoints * Add pipeline support, correct image_mean and image_std * Use padding=max_length by default * Make processor like llava * Add code snippet * Convert more checkpoints * Set keep_punctuation_string=None as in OpenCLIP * Set normalized=False for special tokens * Fix doc test * Update integration test * Add figure * Update organization * Happy new year * Use AutoModel everywhere --------- Co-authored-by: patil-suraj <surajp815@gmail.com>
5.9 KiB
SigLIP
Overview
The SigLIP model was proposed in Sigmoid Loss for Language Image Pre-Training by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. SigLIP proposes to replace the loss function used in CLIP by a simple pairwise sigmoid loss. This results in better performance in terms of zero-shot classification accuracy on ImageNet.
The abstract from the paper is the following:
We propose a simple pairwise Sigmoid loss for Language-Image Pre-training (SigLIP). Unlike standard contrastive learning with softmax normalization, the sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. The sigmoid loss simultaneously allows further scaling up the batch size, while also performing better at smaller batch sizes. Combined with Locked-image Tuning, with only four TPUv4 chips, we train a SigLiT model that achieves 84.5% ImageNet zero-shot accuracy in two days. The disentanglement of the batch size from the loss further allows us to study the impact of examples vs pairs and negative to positive ratio. Finally, we push the batch size to the extreme, up to one million, and find that the benefits of growing batch size quickly diminish, with a more reasonable batch size of 32k being sufficient.
Usage tips
- Usage of SigLIP is similar to CLIP. The main difference is the training loss, which does not require a global view of all the pairwise similarities of images and texts within a batch. One needs to apply the sigmoid activation function to the logits, rather than the softmax.
- Training is not yet supported. If you want to fine-tune SigLIP or train from scratch, refer to the loss function from OpenCLIP, which leverages various
torch.distributedutilities. - When using the standalone [
SiglipTokenizer], make sure to passpadding="max_length"as that's how the model was trained. The multimodal [SiglipProcessor] takes care of this behind the scenes.
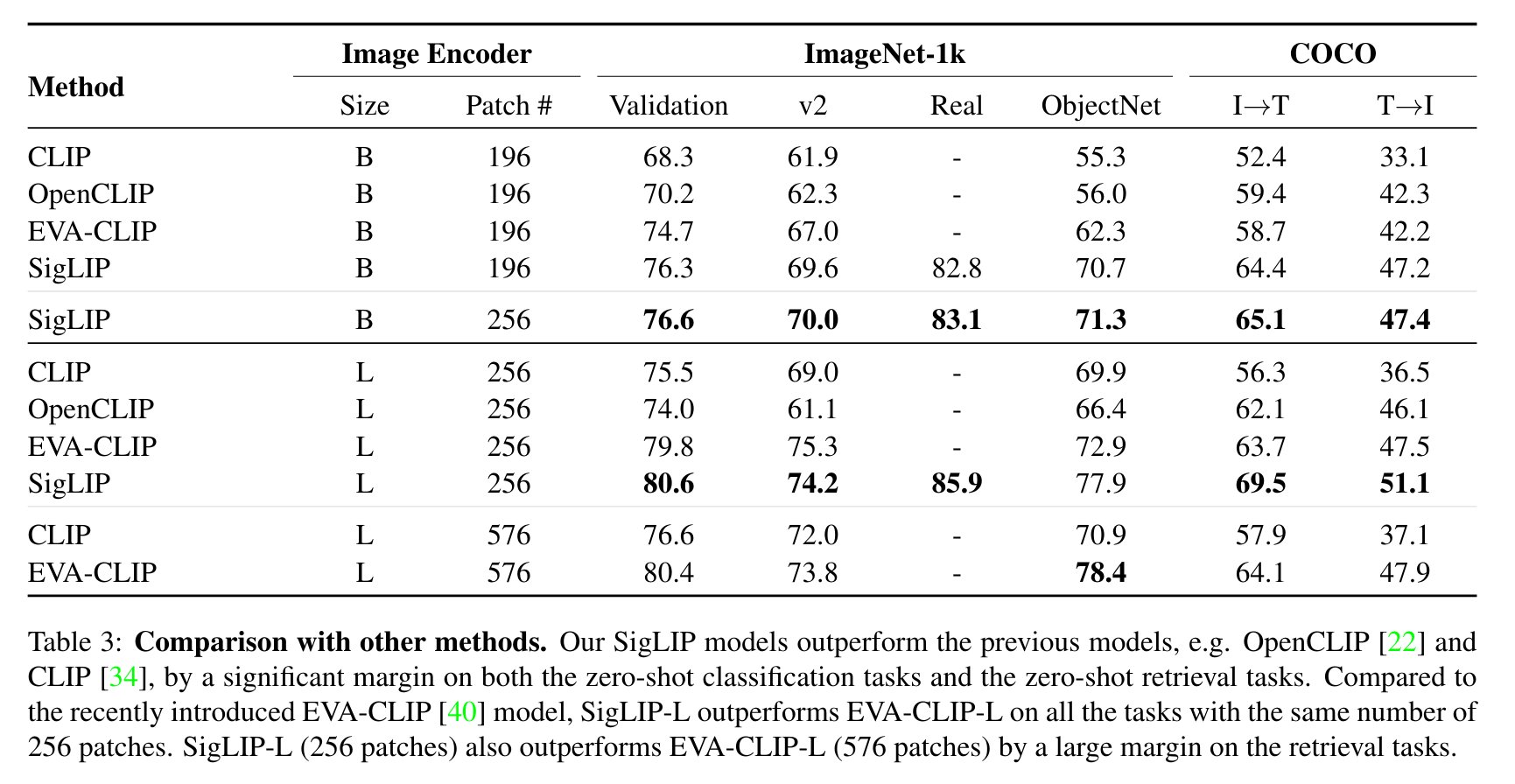
SigLIP evaluation results compared to CLIP. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Usage example
There are 2 main ways to use SigLIP: either using the pipeline API, which abstracts away all the complexity for you, or by using the SiglipModel class yourself.
Pipeline API
The pipeline allows to use the model in a few lines of code:
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> # load pipe
>>> image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
>>> # load image
>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # inference
>>> outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
>>> print(outputs)
[{'score': 0.1979, 'label': '2 cats'}, {'score': 0.0, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
Using the model yourself
If you want to do the pre- and postprocessing yourself, here's how to do that:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
>>> inputs = processor(text=texts, images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
>>> print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
31.9% that image 0 is 'a photo of 2 cats'
SiglipConfig
autodoc SiglipConfig - from_text_vision_configs
SiglipTextConfig
autodoc SiglipTextConfig
SiglipVisionConfig
autodoc SiglipVisionConfig
SiglipTokenizer
autodoc SiglipTokenizer - build_inputs_with_special_tokens - get_special_tokens_mask - create_token_type_ids_from_sequences - save_vocabulary
SiglipImageProcessor
autodoc SiglipImageProcessor - preprocess
SiglipProcessor
autodoc SiglipProcessor
SiglipModel
autodoc SiglipModel - forward - get_text_features - get_image_features
SiglipTextModel
autodoc SiglipTextModel - forward
SiglipVisionModel
autodoc SiglipVisionModel - forward