mirror of
https://github.com/huggingface/transformers.git
synced 2025-07-03 12:50:06 +06:00
Add FastSpeech2Conformer (#23439)
* start - docs, SpeechT5 copy and rename * add relevant code from FastSpeech2 draft, have tests pass * make it an actual conformer, demo ex. * matching inference with original repo, includes debug code * refactor nn.Sequentials, start more desc. var names * more renaming * more renaming * vocoder scratchwork * matching vocoder outputs * hifigan vocoder conversion script * convert model script, rename some config vars * replace postnet with speecht5's implementation * passing common tests, file cleanup * expand testing, add output hidden states and attention * tokenizer + passing tokenizer tests * variety of updates and tests * g2p_en pckg setup * import structure edits * docstrings and cleanup * repo consistency * deps * small cleanup * forward signature param order * address comments except for masks and labels * address comments on attention_mask and labels * address second round of comments * remove old unneeded line * address comments part 1 * address comments pt 2 * rename auto mapping * fixes for failing tests * address comments part 3 (bart-like, train loss) * make style * pass config where possible * add forward method + tests to WithHifiGan model * make style * address arg passing and generate_speech comments * address Arthur comments * address Arthur comments pt2 * lint changes * Sanchit comment * add g2p-en to doctest deps * move up self.encoder * onnx compatible tensor method * fix is symbolic * fix paper url * move models to espnet org * make style * make fix-copies * update docstring * Arthur comments * update docstring w/ new updates * add model architecture images * header size * md wording update * make style
This commit is contained in:
parent
6eba901d88
commit
d83ff5eeff
@ -515,6 +515,7 @@ doc_test_job = CircleCIJob(
|
||||
"pip install -U --upgrade-strategy eager -e git+https://github.com/huggingface/accelerate@main#egg=accelerate",
|
||||
"pip install --upgrade --upgrade-strategy eager pytest pytest-sugar",
|
||||
"pip install -U --upgrade-strategy eager natten",
|
||||
"pip install -U --upgrade-strategy eager g2p-en",
|
||||
"find -name __pycache__ -delete",
|
||||
"find . -name \*.pyc -delete",
|
||||
# Add an empty file to keep the test step running correctly even no file is selected to be tested.
|
||||
|
||||
@ -358,6 +358,7 @@ Current number of checkpoints: ** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
|
||||
@ -333,6 +333,7 @@ Número actual de puntos de control: ** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
|
||||
@ -307,6 +307,7 @@ conda install -c huggingface transformers
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (Baidu से) Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang. द्वाराअनुसंधान पत्र [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) के साथ जारी किया गया
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (मेटा AI से) ट्रांसफॉर्मर प्रोटीन भाषा मॉडल हैं। **ESM-1b** पेपर के साथ जारी किया गया था [ अलेक्जेंडर राइव्स, जोशुआ मेयर, टॉम सर्कु, सिद्धार्थ गोयल, ज़ेमिंग लिन द्वारा जैविक संरचना और कार्य असुरक्षित सीखने को 250 मिलियन प्रोटीन अनुक्रमों तक स्केल करने से उभरता है] (https://www.pnas.org/content/118/15/e2016239118) जेसन लियू, डेमी गुओ, मायल ओट, सी. लॉरेंस ज़िटनिक, जेरी मा और रॉब फर्गस। **ESM-1v** को पेपर के साथ जारी किया गया था [भाषा मॉडल प्रोटीन फ़ंक्शन पर उत्परिवर्तन के प्रभावों की शून्य-शॉट भविष्यवाणी को सक्षम करते हैं] (https://doi.org/10.1101/2021.07.09.450648) जोशुआ मेयर, रोशन राव, रॉबर्ट वेरकुइल, जेसन लियू, टॉम सर्कु और अलेक्जेंडर राइव्स द्वारा। **ESM-2** को पेपर के साथ जारी किया गया था [भाषा मॉडल विकास के पैमाने पर प्रोटीन अनुक्रम सटीक संरचना भविष्यवाणी को सक्षम करते हैं](https://doi.org/10.1101/2022.07.20.500902) ज़ेमिंग लिन, हलील अकिन, रोशन राव, ब्रायन ही, झोंगकाई झू, वेंटिंग लू, ए द्वारा लान डॉस सैंटोस कोस्टा, मरियम फ़ज़ल-ज़रंडी, टॉम सर्कू, साल कैंडिडो, अलेक्जेंडर राइव्स।
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (ESPnet and Microsoft Research से) Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang. द्वाराअनुसंधान पत्र [Fastspeech 2: Fast And High-quality End-to-End Text To Speech](https://arxiv.org/pdf/2006.04558.pdf) के साथ जारी किया गया
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (CNRS से) साथ वाला पेपर [FlauBERT: Unsupervised Language Model Pre-training for फ़्रेंच](https://arxiv .org/abs/1912.05372) Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, बेंजामिन लेकोउटेक्स, अलेक्जेंड्रे अल्लाउज़ेन, बेनोइट क्रैबे, लॉरेंट बेसेसियर, डिडिएर श्वाब द्वारा।
|
||||
|
||||
@ -367,6 +367,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (Baidu から) Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang. から公開された研究論文 [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674)
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (Meta AI から) はトランスフォーマープロテイン言語モデルです. **ESM-1b** は Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus から公開された研究論文: [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118). **ESM-1v** は Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives から公開された研究論文: [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648). **ESM-2** と **ESMFold** は Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives から公開された研究論文: [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902)
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (ESPnet and Microsoft Research から) Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang. から公開された研究論文 [Fastspeech 2: Fast And High-quality End-to-End Text To Speech](https://arxiv.org/pdf/2006.04558.pdf)
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (Google AI から) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V から公開されたレポジトリー [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (CNRS から) Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab から公開された研究論文: [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372)
|
||||
|
||||
@ -282,6 +282,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (Baidu 에서 제공)은 Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.의 [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674)논문과 함께 발표했습니다.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (ESPnet and Microsoft Research 에서 제공)은 Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.의 [Fastspeech 2: Fast And High-quality End-to-End Text To Speech](https://arxiv.org/pdf/2006.04558.pdf)논문과 함께 발표했습니다.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
|
||||
@ -306,6 +306,7 @@ conda install -c huggingface transformers
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (来自 Baidu) 伴随论文 [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) 由 Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang 发布。
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (来自 ESPnet and Microsoft Research) 伴随论文 [Fastspeech 2: Fast And High-quality End-to-End Text To Speech](https://arxiv.org/pdf/2006.04558.pdf) 由 Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang 发布。
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (来自 CNRS) 伴随论文 [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) 由 Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab 发布。
|
||||
|
||||
@ -318,6 +318,7 @@ conda install -c huggingface transformers
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (from ESPnet and Microsoft Research) released with the paper [Fastspeech 2: Fast And High-quality End-to-End Text To Speech](https://arxiv.org/pdf/2006.04558.pdf) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
|
||||
@ -332,6 +332,8 @@
|
||||
title: ESM
|
||||
- local: model_doc/falcon
|
||||
title: Falcon
|
||||
- local: model_doc/fastspeech2_conformer
|
||||
title: FastSpeech2Conformer
|
||||
- local: model_doc/flan-t5
|
||||
title: FLAN-T5
|
||||
- local: model_doc/flan-ul2
|
||||
|
||||
@ -132,6 +132,7 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
|
||||
| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
|
||||
| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
|
||||
| [FastSpeech2Conformer](model_doc/fastspeech2_conformer) | ✅ | ❌ | ❌ |
|
||||
| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
|
||||
| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
|
||||
| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
|
||||
|
||||
134
docs/source/en/model_doc/fastspeech2_conformer.md
Normal file
134
docs/source/en/model_doc/fastspeech2_conformer.md
Normal file
@ -0,0 +1,134 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# FastSpeech2Conformer
|
||||
|
||||
## Overview
|
||||
|
||||
The FastSpeech2Conformer model was proposed with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
|
||||
The abstract from the original FastSpeech2 paper is the following:
|
||||
|
||||
*Non-autoregressive text to speech (TTS) models such as FastSpeech (Ren et al., 2019) can synthesize speech significantly faster than previous autoregressive models with comparable quality. The training of FastSpeech model relies on an autoregressive teacher model for duration prediction (to provide more information as input) and knowledge distillation (to simplify the data distribution in output), which can ease the one-to-many mapping problem (i.e., multiple speech variations correspond to the same text) in TTS. However, FastSpeech has several disadvantages: 1) the teacher-student distillation pipeline is complicated and time-consuming, 2) the duration extracted from the teacher model is not accurate enough, and the target mel-spectrograms distilled from teacher model suffer from information loss due to data simplification, both of which limit the voice quality. In this paper, we propose FastSpeech 2, which addresses the issues in FastSpeech and better solves the one-to-many mapping problem in TTS by 1) directly training the model with ground-truth target instead of the simplified output from teacher, and 2) introducing more variation information of speech (e.g., pitch, energy and more accurate duration) as conditional inputs. Specifically, we extract duration, pitch and energy from speech waveform and directly take them as conditional inputs in training and use predicted values in inference. We further design FastSpeech 2s, which is the first attempt to directly generate speech waveform from text in parallel, enjoying the benefit of fully end-to-end inference. Experimental results show that 1) FastSpeech 2 achieves a 3x training speed-up over FastSpeech, and FastSpeech 2s enjoys even faster inference speed; 2) FastSpeech 2 and 2s outperform FastSpeech in voice quality, and FastSpeech 2 can even surpass autoregressive models. Audio samples are available at https://speechresearch.github.io/fastspeech2/.*
|
||||
|
||||
This model was contributed by [Connor Henderson](https://huggingface.co/connor-henderson). The original code can be found [here](https://github.com/espnet/espnet/blob/master/espnet2/tts/fastspeech2/fastspeech2.py).
|
||||
|
||||
|
||||
## 🤗 Model Architecture
|
||||
FastSpeech2's general structure with a Mel-spectrogram decoder was implemented, and the traditional transformer blocks were replaced with with conformer blocks as done in the ESPnet library.
|
||||
|
||||
#### FastSpeech2 Model Architecture
|
||||

|
||||
|
||||
#### Conformer Blocks
|
||||

|
||||
|
||||
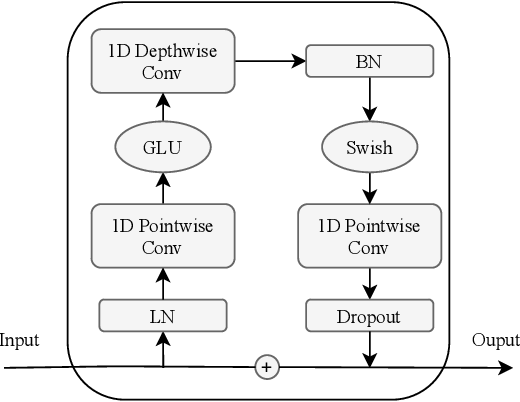
#### Convolution Module
|
||||
|
||||
|
||||
## 🤗 Transformers Usage
|
||||
|
||||
You can run FastSpeech2Conformer locally with the 🤗 Transformers library.
|
||||
|
||||
1. First install the 🤗 [Transformers library](https://github.com/huggingface/transformers), g2p-en:
|
||||
|
||||
```
|
||||
pip install --upgrade pip
|
||||
pip install --upgrade transformers g2p-en
|
||||
```
|
||||
|
||||
2. Run inference via the Transformers modelling code with the model and hifigan separately
|
||||
|
||||
```python
|
||||
|
||||
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerModel, FastSpeech2ConformerHifiGan
|
||||
import soundfile as sf
|
||||
|
||||
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
|
||||
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
|
||||
input_ids = inputs["input_ids"]
|
||||
|
||||
model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
|
||||
output_dict = model(input_ids, return_dict=True)
|
||||
spectrogram = output_dict["spectrogram"]
|
||||
|
||||
hifigan = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
|
||||
waveform = hifigan(spectrogram)
|
||||
|
||||
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)
|
||||
```
|
||||
|
||||
3. Run inference via the Transformers modelling code with the model and hifigan combined
|
||||
|
||||
```python
|
||||
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerWithHifiGan
|
||||
import soundfile as sf
|
||||
|
||||
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
|
||||
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
|
||||
input_ids = inputs["input_ids"]
|
||||
|
||||
model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
|
||||
output_dict = model(input_ids, return_dict=True)
|
||||
waveform = output_dict["waveform"]
|
||||
|
||||
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)
|
||||
```
|
||||
|
||||
4. Run inference with a pipeline and specify which vocoder to use
|
||||
```python
|
||||
from transformers import pipeline, FastSpeech2ConformerHifiGan
|
||||
import soundfile as sf
|
||||
|
||||
vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
|
||||
synthesiser = pipeline(model="espnet/fastspeech2_conformer", vocoder=vocoder)
|
||||
|
||||
speech = synthesiser("Hello, my dog is cooler than you!")
|
||||
|
||||
sf.write("speech.wav", speech["audio"].squeeze(), samplerate=speech["sampling_rate"])
|
||||
```
|
||||
|
||||
|
||||
## FastSpeech2ConformerConfig
|
||||
|
||||
[[autodoc]] FastSpeech2ConformerConfig
|
||||
|
||||
## FastSpeech2ConformerHifiGanConfig
|
||||
|
||||
[[autodoc]] FastSpeech2ConformerHifiGanConfig
|
||||
|
||||
## FastSpeech2ConformerWithHifiGanConfig
|
||||
|
||||
[[autodoc]] FastSpeech2ConformerWithHifiGanConfig
|
||||
|
||||
## FastSpeech2ConformerTokenizer
|
||||
|
||||
[[autodoc]] FastSpeech2ConformerTokenizer
|
||||
- __call__
|
||||
- save_vocabulary
|
||||
- decode
|
||||
- batch_decode
|
||||
|
||||
## FastSpeech2ConformerModel
|
||||
|
||||
[[autodoc]] FastSpeech2ConformerModel
|
||||
- forward
|
||||
|
||||
## FastSpeech2ConformerHifiGan
|
||||
|
||||
[[autodoc]] FastSpeech2ConformerHifiGan
|
||||
- forward
|
||||
|
||||
## FastSpeech2ConformerWithHifiGan
|
||||
|
||||
[[autodoc]] FastSpeech2ConformerWithHifiGan
|
||||
- forward
|
||||
@ -44,10 +44,8 @@ Here's a code snippet you can use to listen to the resulting audio in a notebook
|
||||
For more examples on what Bark and other pretrained TTS models can do, refer to our
|
||||
[Audio course](https://huggingface.co/learn/audio-course/chapter6/pre-trained_models).
|
||||
|
||||
If you are looking to fine-tune a TTS model, you can currently fine-tune SpeechT5 only. SpeechT5 is pre-trained on a combination of
|
||||
speech-to-text and text-to-speech data, allowing it to learn a unified space of hidden representations shared by both text
|
||||
and speech. This means that the same pre-trained model can be fine-tuned for different tasks. Furthermore, SpeechT5
|
||||
supports multiple speakers through x-vector speaker embeddings.
|
||||
If you are looking to fine-tune a TTS model, the only text-to-speech models currently available in 🤗 Transformers
|
||||
are [SpeechT5](model_doc/speecht5) and [FastSpeech2Conformer](model_doc/fastspeech2_conformer), though more will be added in the future. SpeechT5 is pre-trained on a combination of speech-to-text and text-to-speech data, allowing it to learn a unified space of hidden representations shared by both text and speech. This means that the same pre-trained model can be fine-tuned for different tasks. Furthermore, SpeechT5 supports multiple speakers through x-vector speaker embeddings.
|
||||
|
||||
The remainder of this guide illustrates how to:
|
||||
|
||||
|
||||
@ -108,6 +108,7 @@ La documentation est organisée en 5 parties:
|
||||
1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
|
||||
1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
|
||||
1. **[ESM](model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FLAN-T5](model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
|
||||
@ -290,6 +291,7 @@ Le tableau ci-dessous représente la prise en charge actuelle dans la bibliothè
|
||||
| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| FastSpeech2Conformer | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
|
||||
@ -30,6 +30,7 @@ from .utils import (
|
||||
is_bitsandbytes_available,
|
||||
is_essentia_available,
|
||||
is_flax_available,
|
||||
is_g2p_en_available,
|
||||
is_keras_nlp_available,
|
||||
is_librosa_available,
|
||||
is_pretty_midi_available,
|
||||
@ -423,11 +424,16 @@ _import_structure = {
|
||||
"models.ernie_m": ["ERNIE_M_PRETRAINED_CONFIG_ARCHIVE_MAP", "ErnieMConfig"],
|
||||
"models.esm": ["ESM_PRETRAINED_CONFIG_ARCHIVE_MAP", "EsmConfig", "EsmTokenizer"],
|
||||
"models.falcon": ["FALCON_PRETRAINED_CONFIG_ARCHIVE_MAP", "FalconConfig"],
|
||||
"models.flaubert": [
|
||||
"FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP",
|
||||
"FlaubertConfig",
|
||||
"FlaubertTokenizer",
|
||||
"models.fastspeech2_conformer": [
|
||||
"FASTSPEECH2_CONFORMER_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP",
|
||||
"FASTSPEECH2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP",
|
||||
"FASTSPEECH2_CONFORMER_WITH_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP",
|
||||
"FastSpeech2ConformerConfig",
|
||||
"FastSpeech2ConformerHifiGanConfig",
|
||||
"FastSpeech2ConformerTokenizer",
|
||||
"FastSpeech2ConformerWithHifiGanConfig",
|
||||
],
|
||||
"models.flaubert": ["FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "FlaubertConfig", "FlaubertTokenizer"],
|
||||
"models.flava": [
|
||||
"FLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP",
|
||||
"FlavaConfig",
|
||||
@ -2126,6 +2132,15 @@ else:
|
||||
"FalconPreTrainedModel",
|
||||
]
|
||||
)
|
||||
_import_structure["models.fastspeech2_conformer"].extend(
|
||||
[
|
||||
"FASTSPEECH2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
|
||||
"FastSpeech2ConformerHifiGan",
|
||||
"FastSpeech2ConformerModel",
|
||||
"FastSpeech2ConformerPreTrainedModel",
|
||||
"FastSpeech2ConformerWithHifiGan",
|
||||
]
|
||||
)
|
||||
_import_structure["models.flaubert"].extend(
|
||||
[
|
||||
"FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST",
|
||||
@ -5081,11 +5096,16 @@ if TYPE_CHECKING:
|
||||
from .models.ernie_m import ERNIE_M_PRETRAINED_CONFIG_ARCHIVE_MAP, ErnieMConfig
|
||||
from .models.esm import ESM_PRETRAINED_CONFIG_ARCHIVE_MAP, EsmConfig, EsmTokenizer
|
||||
from .models.falcon import FALCON_PRETRAINED_CONFIG_ARCHIVE_MAP, FalconConfig
|
||||
from .models.flaubert import (
|
||||
FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
FlaubertConfig,
|
||||
FlaubertTokenizer,
|
||||
from .models.fastspeech2_conformer import (
|
||||
FASTSPEECH2_CONFORMER_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
FASTSPEECH2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
FASTSPEECH2_CONFORMER_WITH_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
FastSpeech2ConformerConfig,
|
||||
FastSpeech2ConformerHifiGanConfig,
|
||||
FastSpeech2ConformerTokenizer,
|
||||
FastSpeech2ConformerWithHifiGanConfig,
|
||||
)
|
||||
from .models.flaubert import FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, FlaubertConfig, FlaubertTokenizer
|
||||
from .models.flava import (
|
||||
FLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
FlavaConfig,
|
||||
@ -6652,6 +6672,13 @@ if TYPE_CHECKING:
|
||||
FalconModel,
|
||||
FalconPreTrainedModel,
|
||||
)
|
||||
from .models.fastspeech2_conformer import (
|
||||
FASTSPEECH2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
|
||||
FastSpeech2ConformerHifiGan,
|
||||
FastSpeech2ConformerModel,
|
||||
FastSpeech2ConformerPreTrainedModel,
|
||||
FastSpeech2ConformerWithHifiGan,
|
||||
)
|
||||
from .models.flaubert import (
|
||||
FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST,
|
||||
FlaubertForMultipleChoice,
|
||||
|
||||
@ -84,6 +84,7 @@ from .utils import (
|
||||
is_faiss_available,
|
||||
is_flax_available,
|
||||
is_ftfy_available,
|
||||
is_g2p_en_available,
|
||||
is_in_notebook,
|
||||
is_ipex_available,
|
||||
is_librosa_available,
|
||||
|
||||
@ -83,6 +83,7 @@ from . import (
|
||||
ernie_m,
|
||||
esm,
|
||||
falcon,
|
||||
fastspeech2_conformer,
|
||||
flaubert,
|
||||
flava,
|
||||
fnet,
|
||||
|
||||
@ -93,6 +93,7 @@ CONFIG_MAPPING_NAMES = OrderedDict(
|
||||
("ernie_m", "ErnieMConfig"),
|
||||
("esm", "EsmConfig"),
|
||||
("falcon", "FalconConfig"),
|
||||
("fastspeech2_conformer", "FastSpeech2ConformerConfig"),
|
||||
("flaubert", "FlaubertConfig"),
|
||||
("flava", "FlavaConfig"),
|
||||
("fnet", "FNetConfig"),
|
||||
@ -319,6 +320,7 @@ CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
|
||||
("ernie_m", "ERNIE_M_PRETRAINED_CONFIG_ARCHIVE_MAP"),
|
||||
("esm", "ESM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
|
||||
("falcon", "FALCON_PRETRAINED_CONFIG_ARCHIVE_MAP"),
|
||||
("fastspeech2_conformer", "FASTSPEECH2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
|
||||
("flaubert", "FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
|
||||
("flava", "FLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
|
||||
("fnet", "FNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
|
||||
@ -542,6 +544,7 @@ MODEL_NAMES_MAPPING = OrderedDict(
|
||||
("ernie_m", "ErnieM"),
|
||||
("esm", "ESM"),
|
||||
("falcon", "Falcon"),
|
||||
("fastspeech2_conformer", "FastSpeech2Conformer"),
|
||||
("flan-t5", "FLAN-T5"),
|
||||
("flan-ul2", "FLAN-UL2"),
|
||||
("flaubert", "FlauBERT"),
|
||||
|
||||
@ -95,6 +95,7 @@ MODEL_MAPPING_NAMES = OrderedDict(
|
||||
("ernie_m", "ErnieMModel"),
|
||||
("esm", "EsmModel"),
|
||||
("falcon", "FalconModel"),
|
||||
("fastspeech2_conformer", "FastSpeech2ConformerModel"),
|
||||
("flaubert", "FlaubertModel"),
|
||||
("flava", "FlavaModel"),
|
||||
("fnet", "FNetModel"),
|
||||
@ -1075,6 +1076,7 @@ MODEL_FOR_AUDIO_XVECTOR_MAPPING_NAMES = OrderedDict(
|
||||
MODEL_FOR_TEXT_TO_SPECTROGRAM_MAPPING_NAMES = OrderedDict(
|
||||
[
|
||||
# Model for Text-To-Spectrogram mapping
|
||||
("fastspeech2_conformer", "FastSpeech2ConformerModel"),
|
||||
("speecht5", "SpeechT5ForTextToSpeech"),
|
||||
]
|
||||
)
|
||||
@ -1083,6 +1085,7 @@ MODEL_FOR_TEXT_TO_WAVEFORM_MAPPING_NAMES = OrderedDict(
|
||||
[
|
||||
# Model for Text-To-Waveform mapping
|
||||
("bark", "BarkModel"),
|
||||
("fastspeech2_conformer", "FastSpeech2ConformerWithHifiGan"),
|
||||
("musicgen", "MusicgenForConditionalGeneration"),
|
||||
("seamless_m4t", "SeamlessM4TForTextToSpeech"),
|
||||
("seamless_m4t_v2", "SeamlessM4Tv2ForTextToSpeech"),
|
||||
|
||||
@ -25,7 +25,14 @@ from ...configuration_utils import PretrainedConfig
|
||||
from ...dynamic_module_utils import get_class_from_dynamic_module, resolve_trust_remote_code
|
||||
from ...tokenization_utils import PreTrainedTokenizer
|
||||
from ...tokenization_utils_base import TOKENIZER_CONFIG_FILE
|
||||
from ...utils import cached_file, extract_commit_hash, is_sentencepiece_available, is_tokenizers_available, logging
|
||||
from ...utils import (
|
||||
cached_file,
|
||||
extract_commit_hash,
|
||||
is_g2p_en_available,
|
||||
is_sentencepiece_available,
|
||||
is_tokenizers_available,
|
||||
logging,
|
||||
)
|
||||
from ..encoder_decoder import EncoderDecoderConfig
|
||||
from .auto_factory import _LazyAutoMapping
|
||||
from .configuration_auto import (
|
||||
@ -163,6 +170,10 @@ else:
|
||||
("ernie_m", ("ErnieMTokenizer" if is_sentencepiece_available() else None, None)),
|
||||
("esm", ("EsmTokenizer", None)),
|
||||
("falcon", (None, "PreTrainedTokenizerFast" if is_tokenizers_available() else None)),
|
||||
(
|
||||
"fastspeech2_conformer",
|
||||
("FastSpeech2ConformerTokenizer" if is_g2p_en_available() else None, None),
|
||||
),
|
||||
("flaubert", ("FlaubertTokenizer", None)),
|
||||
("fnet", ("FNetTokenizer", "FNetTokenizerFast" if is_tokenizers_available() else None)),
|
||||
("fsmt", ("FSMTTokenizer", None)),
|
||||
|
||||
77
src/transformers/models/fastspeech2_conformer/__init__.py
Normal file
77
src/transformers/models/fastspeech2_conformer/__init__.py
Normal file
@ -0,0 +1,77 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ...utils import (
|
||||
OptionalDependencyNotAvailable,
|
||||
_LazyModule,
|
||||
is_torch_available,
|
||||
)
|
||||
|
||||
|
||||
_import_structure = {
|
||||
"configuration_fastspeech2_conformer": [
|
||||
"FASTSPEECH2_CONFORMER_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP",
|
||||
"FASTSPEECH2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP",
|
||||
"FASTSPEECH2_CONFORMER_WITH_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP",
|
||||
"FastSpeech2ConformerConfig",
|
||||
"FastSpeech2ConformerHifiGanConfig",
|
||||
"FastSpeech2ConformerWithHifiGanConfig",
|
||||
],
|
||||
"tokenization_fastspeech2_conformer": ["FastSpeech2ConformerTokenizer"],
|
||||
}
|
||||
|
||||
try:
|
||||
if not is_torch_available():
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
pass
|
||||
else:
|
||||
_import_structure["modeling_fastspeech2_conformer"] = [
|
||||
"FASTSPEECH2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
|
||||
"FastSpeech2ConformerWithHifiGan",
|
||||
"FastSpeech2ConformerHifiGan",
|
||||
"FastSpeech2ConformerModel",
|
||||
"FastSpeech2ConformerPreTrainedModel",
|
||||
]
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from .configuration_fastspeech2_conformer import (
|
||||
FASTSPEECH2_CONFORMER_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
FASTSPEECH2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
FASTSPEECH2_CONFORMER_WITH_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP,
|
||||
FastSpeech2ConformerConfig,
|
||||
FastSpeech2ConformerHifiGanConfig,
|
||||
FastSpeech2ConformerWithHifiGanConfig,
|
||||
)
|
||||
from .tokenization_fastspeech2_conformer import FastSpeech2ConformerTokenizer
|
||||
|
||||
try:
|
||||
if not is_torch_available():
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
pass
|
||||
else:
|
||||
from .modeling_fastspeech2_conformer import (
|
||||
FASTSPEECH2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
|
||||
FastSpeech2ConformerHifiGan,
|
||||
FastSpeech2ConformerModel,
|
||||
FastSpeech2ConformerPreTrainedModel,
|
||||
FastSpeech2ConformerWithHifiGan,
|
||||
)
|
||||
|
||||
else:
|
||||
import sys
|
||||
|
||||
sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
|
||||
@ -0,0 +1,488 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" FastSpeech2Conformer model configuration"""
|
||||
|
||||
from typing import Dict
|
||||
|
||||
from ...configuration_utils import PretrainedConfig
|
||||
from ...utils import logging
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
FASTSPEECH2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
|
||||
"espnet/fastspeech2_conformer": "https://huggingface.co/espnet/fastspeech2_conformer/raw/main/config.json",
|
||||
}
|
||||
|
||||
FASTSPEECH2_CONFORMER_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
|
||||
"espnet/fastspeech2_conformer_hifigan": "https://huggingface.co/espnet/fastspeech2_conformer_hifigan/raw/main/config.json",
|
||||
}
|
||||
|
||||
FASTSPEECH2_CONFORMER_WITH_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
|
||||
"espnet/fastspeech2_conformer_with_hifigan": "https://huggingface.co/espnet/fastspeech2_conformer_with_hifigan/raw/main/config.json",
|
||||
}
|
||||
|
||||
|
||||
class FastSpeech2ConformerConfig(PretrainedConfig):
|
||||
r"""
|
||||
This is the configuration class to store the configuration of a [`FastSpeech2ConformerModel`]. It is used to
|
||||
instantiate a FastSpeech2Conformer model according to the specified arguments, defining the model architecture.
|
||||
Instantiating a configuration with the defaults will yield a similar configuration to that of the
|
||||
FastSpeech2Conformer [espnet/fastspeech2_conformer](https://huggingface.co/espnet/fastspeech2_conformer)
|
||||
architecture.
|
||||
|
||||
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
||||
documentation from [`PretrainedConfig`] for more information.
|
||||
|
||||
Args:
|
||||
hidden_size (`int`, *optional*, defaults to 384):
|
||||
The dimensionality of the hidden layers.
|
||||
vocab_size (`int`, *optional*, defaults to 78):
|
||||
The size of the vocabulary.
|
||||
num_mel_bins (`int`, *optional*, defaults to 80):
|
||||
The number of mel filters used in the filter bank.
|
||||
encoder_num_attention_heads (`int`, *optional*, defaults to 2):
|
||||
The number of attention heads in the encoder.
|
||||
encoder_layers (`int`, *optional*, defaults to 4):
|
||||
The number of layers in the encoder.
|
||||
encoder_linear_units (`int`, *optional*, defaults to 1536):
|
||||
The number of units in the linear layer of the encoder.
|
||||
decoder_layers (`int`, *optional*, defaults to 4):
|
||||
The number of layers in the decoder.
|
||||
decoder_num_attention_heads (`int`, *optional*, defaults to 2):
|
||||
The number of attention heads in the decoder.
|
||||
decoder_linear_units (`int`, *optional*, defaults to 1536):
|
||||
The number of units in the linear layer of the decoder.
|
||||
speech_decoder_postnet_layers (`int`, *optional*, defaults to 5):
|
||||
The number of layers in the post-net of the speech decoder.
|
||||
speech_decoder_postnet_units (`int`, *optional*, defaults to 256):
|
||||
The number of units in the post-net layers of the speech decoder.
|
||||
speech_decoder_postnet_kernel (`int`, *optional*, defaults to 5):
|
||||
The kernel size in the post-net of the speech decoder.
|
||||
positionwise_conv_kernel_size (`int`, *optional*, defaults to 3):
|
||||
The size of the convolution kernel used in the position-wise layer.
|
||||
encoder_normalize_before (`bool`, *optional*, defaults to `False`):
|
||||
Specifies whether to normalize before encoder layers.
|
||||
decoder_normalize_before (`bool`, *optional*, defaults to `False`):
|
||||
Specifies whether to normalize before decoder layers.
|
||||
encoder_concat_after (`bool`, *optional*, defaults to `False`):
|
||||
Specifies whether to concatenate after encoder layers.
|
||||
decoder_concat_after (`bool`, *optional*, defaults to `False`):
|
||||
Specifies whether to concatenate after decoder layers.
|
||||
reduction_factor (`int`, *optional*, defaults to 1):
|
||||
The factor by which the speech frame rate is reduced.
|
||||
speaking_speed (`float`, *optional*, defaults to 1.0):
|
||||
The speed of the speech produced.
|
||||
use_macaron_style_in_conformer (`bool`, *optional*, defaults to `True`):
|
||||
Specifies whether to use macaron style in the conformer.
|
||||
use_cnn_in_conformer (`bool`, *optional*, defaults to `True`):
|
||||
Specifies whether to use convolutional neural networks in the conformer.
|
||||
encoder_kernel_size (`int`, *optional*, defaults to 7):
|
||||
The kernel size used in the encoder.
|
||||
decoder_kernel_size (`int`, *optional*, defaults to 31):
|
||||
The kernel size used in the decoder.
|
||||
duration_predictor_layers (`int`, *optional*, defaults to 2):
|
||||
The number of layers in the duration predictor.
|
||||
duration_predictor_channels (`int`, *optional*, defaults to 256):
|
||||
The number of channels in the duration predictor.
|
||||
duration_predictor_kernel_size (`int`, *optional*, defaults to 3):
|
||||
The kernel size used in the duration predictor.
|
||||
energy_predictor_layers (`int`, *optional*, defaults to 2):
|
||||
The number of layers in the energy predictor.
|
||||
energy_predictor_channels (`int`, *optional*, defaults to 256):
|
||||
The number of channels in the energy predictor.
|
||||
energy_predictor_kernel_size (`int`, *optional*, defaults to 3):
|
||||
The kernel size used in the energy predictor.
|
||||
energy_predictor_dropout (`float`, *optional*, defaults to 0.5):
|
||||
The dropout rate in the energy predictor.
|
||||
energy_embed_kernel_size (`int`, *optional*, defaults to 1):
|
||||
The kernel size used in the energy embed layer.
|
||||
energy_embed_dropout (`float`, *optional*, defaults to 0.0):
|
||||
The dropout rate in the energy embed layer.
|
||||
stop_gradient_from_energy_predictor (`bool`, *optional*, defaults to `False`):
|
||||
Specifies whether to stop gradients from the energy predictor.
|
||||
pitch_predictor_layers (`int`, *optional*, defaults to 5):
|
||||
The number of layers in the pitch predictor.
|
||||
pitch_predictor_channels (`int`, *optional*, defaults to 256):
|
||||
The number of channels in the pitch predictor.
|
||||
pitch_predictor_kernel_size (`int`, *optional*, defaults to 5):
|
||||
The kernel size used in the pitch predictor.
|
||||
pitch_predictor_dropout (`float`, *optional*, defaults to 0.5):
|
||||
The dropout rate in the pitch predictor.
|
||||
pitch_embed_kernel_size (`int`, *optional*, defaults to 1):
|
||||
The kernel size used in the pitch embed layer.
|
||||
pitch_embed_dropout (`float`, *optional*, defaults to 0.0):
|
||||
The dropout rate in the pitch embed layer.
|
||||
stop_gradient_from_pitch_predictor (`bool`, *optional*, defaults to `True`):
|
||||
Specifies whether to stop gradients from the pitch predictor.
|
||||
encoder_dropout_rate (`float`, *optional*, defaults to 0.2):
|
||||
The dropout rate in the encoder.
|
||||
encoder_positional_dropout_rate (`float`, *optional*, defaults to 0.2):
|
||||
The positional dropout rate in the encoder.
|
||||
encoder_attention_dropout_rate (`float`, *optional*, defaults to 0.2):
|
||||
The attention dropout rate in the encoder.
|
||||
decoder_dropout_rate (`float`, *optional*, defaults to 0.2):
|
||||
The dropout rate in the decoder.
|
||||
decoder_positional_dropout_rate (`float`, *optional*, defaults to 0.2):
|
||||
The positional dropout rate in the decoder.
|
||||
decoder_attention_dropout_rate (`float`, *optional*, defaults to 0.2):
|
||||
The attention dropout rate in the decoder.
|
||||
duration_predictor_dropout_rate (`float`, *optional*, defaults to 0.2):
|
||||
The dropout rate in the duration predictor.
|
||||
speech_decoder_postnet_dropout (`float`, *optional*, defaults to 0.5):
|
||||
The dropout rate in the speech decoder postnet.
|
||||
max_source_positions (`int`, *optional*, defaults to 5000):
|
||||
if `"relative"` position embeddings are used, defines the maximum source input positions.
|
||||
use_masking (`bool`, *optional*, defaults to `True`):
|
||||
Specifies whether to use masking in the model.
|
||||
use_weighted_masking (`bool`, *optional*, defaults to `False`):
|
||||
Specifies whether to use weighted masking in the model.
|
||||
num_speakers (`int`, *optional*):
|
||||
Number of speakers. If set to > 1, assume that the speaker ids will be provided as the input and use
|
||||
speaker id embedding layer.
|
||||
num_languages (`int`, *optional*):
|
||||
Number of languages. If set to > 1, assume that the language ids will be provided as the input and use the
|
||||
languge id embedding layer.
|
||||
speaker_embed_dim (`int`, *optional*):
|
||||
Speaker embedding dimension. If set to > 0, assume that speaker_embedding will be provided as the input.
|
||||
is_encoder_decoder (`bool`, *optional*, defaults to `True`):
|
||||
Specifies whether the model is an encoder-decoder.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from transformers import FastSpeech2ConformerModel, FastSpeech2ConformerConfig
|
||||
|
||||
>>> # Initializing a FastSpeech2Conformer style configuration
|
||||
>>> configuration = FastSpeech2ConformerConfig()
|
||||
|
||||
>>> # Initializing a model from the FastSpeech2Conformer style configuration
|
||||
>>> model = FastSpeech2ConformerModel(configuration)
|
||||
|
||||
>>> # Accessing the model configuration
|
||||
>>> configuration = model.config
|
||||
```"""
|
||||
|
||||
model_type = "fastspeech2_conformer"
|
||||
attribute_map = {"num_hidden_layers": "encoder_layers", "num_attention_heads": "encoder_num_attention_heads"}
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size=384,
|
||||
vocab_size=78,
|
||||
num_mel_bins=80,
|
||||
encoder_num_attention_heads=2,
|
||||
encoder_layers=4,
|
||||
encoder_linear_units=1536,
|
||||
decoder_layers=4,
|
||||
decoder_num_attention_heads=2,
|
||||
decoder_linear_units=1536,
|
||||
speech_decoder_postnet_layers=5,
|
||||
speech_decoder_postnet_units=256,
|
||||
speech_decoder_postnet_kernel=5,
|
||||
positionwise_conv_kernel_size=3,
|
||||
encoder_normalize_before=False,
|
||||
decoder_normalize_before=False,
|
||||
encoder_concat_after=False,
|
||||
decoder_concat_after=False,
|
||||
reduction_factor=1,
|
||||
speaking_speed=1.0,
|
||||
use_macaron_style_in_conformer=True,
|
||||
use_cnn_in_conformer=True,
|
||||
encoder_kernel_size=7,
|
||||
decoder_kernel_size=31,
|
||||
duration_predictor_layers=2,
|
||||
duration_predictor_channels=256,
|
||||
duration_predictor_kernel_size=3,
|
||||
energy_predictor_layers=2,
|
||||
energy_predictor_channels=256,
|
||||
energy_predictor_kernel_size=3,
|
||||
energy_predictor_dropout=0.5,
|
||||
energy_embed_kernel_size=1,
|
||||
energy_embed_dropout=0.0,
|
||||
stop_gradient_from_energy_predictor=False,
|
||||
pitch_predictor_layers=5,
|
||||
pitch_predictor_channels=256,
|
||||
pitch_predictor_kernel_size=5,
|
||||
pitch_predictor_dropout=0.5,
|
||||
pitch_embed_kernel_size=1,
|
||||
pitch_embed_dropout=0.0,
|
||||
stop_gradient_from_pitch_predictor=True,
|
||||
encoder_dropout_rate=0.2,
|
||||
encoder_positional_dropout_rate=0.2,
|
||||
encoder_attention_dropout_rate=0.2,
|
||||
decoder_dropout_rate=0.2,
|
||||
decoder_positional_dropout_rate=0.2,
|
||||
decoder_attention_dropout_rate=0.2,
|
||||
duration_predictor_dropout_rate=0.2,
|
||||
speech_decoder_postnet_dropout=0.5,
|
||||
max_source_positions=5000,
|
||||
use_masking=True,
|
||||
use_weighted_masking=False,
|
||||
num_speakers=None,
|
||||
num_languages=None,
|
||||
speaker_embed_dim=None,
|
||||
is_encoder_decoder=True,
|
||||
**kwargs,
|
||||
):
|
||||
if positionwise_conv_kernel_size % 2 == 0:
|
||||
raise ValueError(
|
||||
f"positionwise_conv_kernel_size must be odd, but got {positionwise_conv_kernel_size} instead."
|
||||
)
|
||||
if encoder_kernel_size % 2 == 0:
|
||||
raise ValueError(f"encoder_kernel_size must be odd, but got {encoder_kernel_size} instead.")
|
||||
if decoder_kernel_size % 2 == 0:
|
||||
raise ValueError(f"decoder_kernel_size must be odd, but got {decoder_kernel_size} instead.")
|
||||
if duration_predictor_kernel_size % 2 == 0:
|
||||
raise ValueError(
|
||||
f"duration_predictor_kernel_size must be odd, but got {duration_predictor_kernel_size} instead."
|
||||
)
|
||||
if energy_predictor_kernel_size % 2 == 0:
|
||||
raise ValueError(
|
||||
f"energy_predictor_kernel_size must be odd, but got {energy_predictor_kernel_size} instead."
|
||||
)
|
||||
if energy_embed_kernel_size % 2 == 0:
|
||||
raise ValueError(f"energy_embed_kernel_size must be odd, but got {energy_embed_kernel_size} instead.")
|
||||
if pitch_predictor_kernel_size % 2 == 0:
|
||||
raise ValueError(
|
||||
f"pitch_predictor_kernel_size must be odd, but got {pitch_predictor_kernel_size} instead."
|
||||
)
|
||||
if pitch_embed_kernel_size % 2 == 0:
|
||||
raise ValueError(f"pitch_embed_kernel_size must be odd, but got {pitch_embed_kernel_size} instead.")
|
||||
if hidden_size % encoder_num_attention_heads != 0:
|
||||
raise ValueError("The hidden_size must be evenly divisible by encoder_num_attention_heads.")
|
||||
if hidden_size % decoder_num_attention_heads != 0:
|
||||
raise ValueError("The hidden_size must be evenly divisible by decoder_num_attention_heads.")
|
||||
if use_masking and use_weighted_masking:
|
||||
raise ValueError("Either use_masking or use_weighted_masking can be True, but not both.")
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.vocab_size = vocab_size
|
||||
self.num_mel_bins = num_mel_bins
|
||||
self.encoder_config = {
|
||||
"num_attention_heads": encoder_num_attention_heads,
|
||||
"layers": encoder_layers,
|
||||
"kernel_size": encoder_kernel_size,
|
||||
"attention_dropout_rate": encoder_attention_dropout_rate,
|
||||
"dropout_rate": encoder_dropout_rate,
|
||||
"positional_dropout_rate": encoder_positional_dropout_rate,
|
||||
"linear_units": encoder_linear_units,
|
||||
"normalize_before": encoder_normalize_before,
|
||||
"concat_after": encoder_concat_after,
|
||||
}
|
||||
self.decoder_config = {
|
||||
"num_attention_heads": decoder_num_attention_heads,
|
||||
"layers": decoder_layers,
|
||||
"kernel_size": decoder_kernel_size,
|
||||
"attention_dropout_rate": decoder_attention_dropout_rate,
|
||||
"dropout_rate": decoder_dropout_rate,
|
||||
"positional_dropout_rate": decoder_positional_dropout_rate,
|
||||
"linear_units": decoder_linear_units,
|
||||
"normalize_before": decoder_normalize_before,
|
||||
"concat_after": decoder_concat_after,
|
||||
}
|
||||
self.encoder_num_attention_heads = encoder_num_attention_heads
|
||||
self.encoder_layers = encoder_layers
|
||||
self.duration_predictor_channels = duration_predictor_channels
|
||||
self.duration_predictor_kernel_size = duration_predictor_kernel_size
|
||||
self.duration_predictor_layers = duration_predictor_layers
|
||||
self.energy_embed_dropout = energy_embed_dropout
|
||||
self.energy_embed_kernel_size = energy_embed_kernel_size
|
||||
self.energy_predictor_channels = energy_predictor_channels
|
||||
self.energy_predictor_dropout = energy_predictor_dropout
|
||||
self.energy_predictor_kernel_size = energy_predictor_kernel_size
|
||||
self.energy_predictor_layers = energy_predictor_layers
|
||||
self.pitch_embed_dropout = pitch_embed_dropout
|
||||
self.pitch_embed_kernel_size = pitch_embed_kernel_size
|
||||
self.pitch_predictor_channels = pitch_predictor_channels
|
||||
self.pitch_predictor_dropout = pitch_predictor_dropout
|
||||
self.pitch_predictor_kernel_size = pitch_predictor_kernel_size
|
||||
self.pitch_predictor_layers = pitch_predictor_layers
|
||||
self.positionwise_conv_kernel_size = positionwise_conv_kernel_size
|
||||
self.speech_decoder_postnet_units = speech_decoder_postnet_units
|
||||
self.speech_decoder_postnet_dropout = speech_decoder_postnet_dropout
|
||||
self.speech_decoder_postnet_kernel = speech_decoder_postnet_kernel
|
||||
self.speech_decoder_postnet_layers = speech_decoder_postnet_layers
|
||||
self.reduction_factor = reduction_factor
|
||||
self.speaking_speed = speaking_speed
|
||||
self.stop_gradient_from_energy_predictor = stop_gradient_from_energy_predictor
|
||||
self.stop_gradient_from_pitch_predictor = stop_gradient_from_pitch_predictor
|
||||
self.max_source_positions = max_source_positions
|
||||
self.use_cnn_in_conformer = use_cnn_in_conformer
|
||||
self.use_macaron_style_in_conformer = use_macaron_style_in_conformer
|
||||
self.use_masking = use_masking
|
||||
self.use_weighted_masking = use_weighted_masking
|
||||
self.num_speakers = num_speakers
|
||||
self.num_languages = num_languages
|
||||
self.speaker_embed_dim = speaker_embed_dim
|
||||
self.duration_predictor_dropout_rate = duration_predictor_dropout_rate
|
||||
self.is_encoder_decoder = is_encoder_decoder
|
||||
|
||||
super().__init__(
|
||||
is_encoder_decoder=is_encoder_decoder,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
|
||||
class FastSpeech2ConformerHifiGanConfig(PretrainedConfig):
|
||||
r"""
|
||||
This is the configuration class to store the configuration of a [`FastSpeech2ConformerHifiGanModel`]. It is used to
|
||||
instantiate a FastSpeech2Conformer HiFi-GAN vocoder model according to the specified arguments, defining the model
|
||||
architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the
|
||||
FastSpeech2Conformer
|
||||
[espnet/fastspeech2_conformer_hifigan](https://huggingface.co/espnet/fastspeech2_conformer_hifigan) architecture.
|
||||
|
||||
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
||||
documentation from [`PretrainedConfig`] for more information.
|
||||
|
||||
Args:
|
||||
model_in_dim (`int`, *optional*, defaults to 80):
|
||||
The number of frequency bins in the input log-mel spectrogram.
|
||||
upsample_initial_channel (`int`, *optional*, defaults to 512):
|
||||
The number of input channels into the upsampling network.
|
||||
upsample_rates (`Tuple[int]` or `List[int]`, *optional*, defaults to `[8, 8, 2, 2]`):
|
||||
A tuple of integers defining the stride of each 1D convolutional layer in the upsampling network. The
|
||||
length of *upsample_rates* defines the number of convolutional layers and has to match the length of
|
||||
*upsample_kernel_sizes*.
|
||||
upsample_kernel_sizes (`Tuple[int]` or `List[int]`, *optional*, defaults to `[16, 16, 4, 4]`):
|
||||
A tuple of integers defining the kernel size of each 1D convolutional layer in the upsampling network. The
|
||||
length of *upsample_kernel_sizes* defines the number of convolutional layers and has to match the length of
|
||||
*upsample_rates*.
|
||||
resblock_kernel_sizes (`Tuple[int]` or `List[int]`, *optional*, defaults to `[3, 7, 11]`):
|
||||
A tuple of integers defining the kernel sizes of the 1D convolutional layers in the multi-receptive field
|
||||
fusion (MRF) module.
|
||||
resblock_dilation_sizes (`Tuple[Tuple[int]]` or `List[List[int]]`, *optional*, defaults to `[[1, 3, 5], [1, 3, 5], [1, 3, 5]]`):
|
||||
A nested tuple of integers defining the dilation rates of the dilated 1D convolutional layers in the
|
||||
multi-receptive field fusion (MRF) module.
|
||||
initializer_range (`float`, *optional*, defaults to 0.01):
|
||||
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
||||
leaky_relu_slope (`float`, *optional*, defaults to 0.1):
|
||||
The angle of the negative slope used by the leaky ReLU activation.
|
||||
normalize_before (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to normalize the spectrogram before vocoding using the vocoder's learned mean and variance.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from transformers import FastSpeech2ConformerHifiGan, FastSpeech2ConformerHifiGanConfig
|
||||
|
||||
>>> # Initializing a FastSpeech2ConformerHifiGan configuration
|
||||
>>> configuration = FastSpeech2ConformerHifiGanConfig()
|
||||
|
||||
>>> # Initializing a model (with random weights) from the configuration
|
||||
>>> model = FastSpeech2ConformerHifiGan(configuration)
|
||||
|
||||
>>> # Accessing the model configuration
|
||||
>>> configuration = model.config
|
||||
```"""
|
||||
|
||||
model_type = "hifigan"
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model_in_dim=80,
|
||||
upsample_initial_channel=512,
|
||||
upsample_rates=[8, 8, 2, 2],
|
||||
upsample_kernel_sizes=[16, 16, 4, 4],
|
||||
resblock_kernel_sizes=[3, 7, 11],
|
||||
resblock_dilation_sizes=[[1, 3, 5], [1, 3, 5], [1, 3, 5]],
|
||||
initializer_range=0.01,
|
||||
leaky_relu_slope=0.1,
|
||||
normalize_before=True,
|
||||
**kwargs,
|
||||
):
|
||||
self.model_in_dim = model_in_dim
|
||||
self.upsample_initial_channel = upsample_initial_channel
|
||||
self.upsample_rates = upsample_rates
|
||||
self.upsample_kernel_sizes = upsample_kernel_sizes
|
||||
self.resblock_kernel_sizes = resblock_kernel_sizes
|
||||
self.resblock_dilation_sizes = resblock_dilation_sizes
|
||||
self.initializer_range = initializer_range
|
||||
self.leaky_relu_slope = leaky_relu_slope
|
||||
self.normalize_before = normalize_before
|
||||
super().__init__(**kwargs)
|
||||
|
||||
|
||||
class FastSpeech2ConformerWithHifiGanConfig(PretrainedConfig):
|
||||
"""
|
||||
This is the configuration class to store the configuration of a [`FastSpeech2ConformerWithHifiGan`]. It is used to
|
||||
instantiate a `FastSpeech2ConformerWithHifiGanModel` model according to the specified sub-models configurations,
|
||||
defining the model architecture.
|
||||
|
||||
Instantiating a configuration with the defaults will yield a similar configuration to that of the
|
||||
FastSpeech2ConformerModel [espnet/fastspeech2_conformer](https://huggingface.co/espnet/fastspeech2_conformer) and
|
||||
FastSpeech2ConformerHifiGan
|
||||
[espnet/fastspeech2_conformer_hifigan](https://huggingface.co/espnet/fastspeech2_conformer_hifigan) architectures.
|
||||
|
||||
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
||||
documentation from [`PretrainedConfig`] for more information.
|
||||
|
||||
Args:
|
||||
model_config (`typing.Dict`, *optional*):
|
||||
Configuration of the text-to-speech model.
|
||||
vocoder_config (`typing.Dict`, *optional*):
|
||||
Configuration of the vocoder model.
|
||||
model_config ([`FastSpeech2ConformerConfig`], *optional*):
|
||||
Configuration of the text-to-speech model.
|
||||
vocoder_config ([`FastSpeech2ConformerHiFiGanConfig`], *optional*):
|
||||
Configuration of the vocoder model.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from transformers import (
|
||||
... FastSpeech2ConformerConfig,
|
||||
... FastSpeech2ConformerHifiGanConfig,
|
||||
... FastSpeech2ConformerWithHifiGanConfig,
|
||||
... FastSpeech2ConformerWithHifiGan,
|
||||
... )
|
||||
|
||||
>>> # Initializing FastSpeech2ConformerWithHifiGan sub-modules configurations.
|
||||
>>> model_config = FastSpeech2ConformerConfig()
|
||||
>>> vocoder_config = FastSpeech2ConformerHifiGanConfig()
|
||||
|
||||
>>> # Initializing a FastSpeech2ConformerWithHifiGan module style configuration
|
||||
>>> configuration = FastSpeech2ConformerWithHifiGanConfig(model_config.to_dict(), vocoder_config.to_dict())
|
||||
|
||||
>>> # Initializing a model (with random weights)
|
||||
>>> model = FastSpeech2ConformerWithHifiGan(configuration)
|
||||
|
||||
>>> # Accessing the model configuration
|
||||
>>> configuration = model.config
|
||||
```
|
||||
"""
|
||||
|
||||
model_type = "fastspeech2_conformer_with_hifigan"
|
||||
is_composition = True
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model_config: Dict = None,
|
||||
vocoder_config: Dict = None,
|
||||
**kwargs,
|
||||
):
|
||||
if model_config is None:
|
||||
model_config = {}
|
||||
logger.info("model_config is None. initializing the model with default values.")
|
||||
|
||||
if vocoder_config is None:
|
||||
vocoder_config = {}
|
||||
logger.info("vocoder_config is None. initializing the coarse model with default values.")
|
||||
|
||||
self.model_config = FastSpeech2ConformerConfig(**model_config)
|
||||
self.vocoder_config = FastSpeech2ConformerHifiGanConfig(**vocoder_config)
|
||||
|
||||
super().__init__(**kwargs)
|
||||
@ -0,0 +1,210 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""Convert FastSpeech2Conformer checkpoint."""
|
||||
|
||||
import argparse
|
||||
import json
|
||||
import re
|
||||
from pathlib import Path
|
||||
from tempfile import TemporaryDirectory
|
||||
|
||||
import torch
|
||||
import yaml
|
||||
|
||||
from transformers import (
|
||||
FastSpeech2ConformerConfig,
|
||||
FastSpeech2ConformerModel,
|
||||
FastSpeech2ConformerTokenizer,
|
||||
logging,
|
||||
)
|
||||
|
||||
|
||||
logging.set_verbosity_info()
|
||||
logger = logging.get_logger("transformers.models.FastSpeech2Conformer")
|
||||
|
||||
CONFIG_MAPPING = {
|
||||
"adim": "hidden_size",
|
||||
"aheads": "num_attention_heads",
|
||||
"conformer_dec_kernel_size": "decoder_kernel_size",
|
||||
"conformer_enc_kernel_size": "encoder_kernel_size",
|
||||
"decoder_normalize_before": "decoder_normalize_before",
|
||||
"dlayers": "decoder_layers",
|
||||
"dunits": "decoder_linear_units",
|
||||
"duration_predictor_chans": "duration_predictor_channels",
|
||||
"duration_predictor_kernel_size": "duration_predictor_kernel_size",
|
||||
"duration_predictor_layers": "duration_predictor_layers",
|
||||
"elayers": "encoder_layers",
|
||||
"encoder_normalize_before": "encoder_normalize_before",
|
||||
"energy_embed_dropout": "energy_embed_dropout",
|
||||
"energy_embed_kernel_size": "energy_embed_kernel_size",
|
||||
"energy_predictor_chans": "energy_predictor_channels",
|
||||
"energy_predictor_dropout": "energy_predictor_dropout",
|
||||
"energy_predictor_kernel_size": "energy_predictor_kernel_size",
|
||||
"energy_predictor_layers": "energy_predictor_layers",
|
||||
"eunits": "encoder_linear_units",
|
||||
"pitch_embed_dropout": "pitch_embed_dropout",
|
||||
"pitch_embed_kernel_size": "pitch_embed_kernel_size",
|
||||
"pitch_predictor_chans": "pitch_predictor_channels",
|
||||
"pitch_predictor_dropout": "pitch_predictor_dropout",
|
||||
"pitch_predictor_kernel_size": "pitch_predictor_kernel_size",
|
||||
"pitch_predictor_layers": "pitch_predictor_layers",
|
||||
"positionwise_conv_kernel_size": "positionwise_conv_kernel_size",
|
||||
"postnet_chans": "speech_decoder_postnet_units",
|
||||
"postnet_filts": "speech_decoder_postnet_kernel",
|
||||
"postnet_layers": "speech_decoder_postnet_layers",
|
||||
"reduction_factor": "reduction_factor",
|
||||
"stop_gradient_from_energy_predictor": "stop_gradient_from_energy_predictor",
|
||||
"stop_gradient_from_pitch_predictor": "stop_gradient_from_pitch_predictor",
|
||||
"transformer_dec_attn_dropout_rate": "decoder_attention_dropout_rate",
|
||||
"transformer_dec_dropout_rate": "decoder_dropout_rate",
|
||||
"transformer_dec_positional_dropout_rate": "decoder_positional_dropout_rate",
|
||||
"transformer_enc_attn_dropout_rate": "encoder_attention_dropout_rate",
|
||||
"transformer_enc_dropout_rate": "encoder_dropout_rate",
|
||||
"transformer_enc_positional_dropout_rate": "encoder_positional_dropout_rate",
|
||||
"use_cnn_in_conformer": "use_cnn_in_conformer",
|
||||
"use_macaron_style_in_conformer": "use_macaron_style_in_conformer",
|
||||
"use_masking": "use_masking",
|
||||
"use_weighted_masking": "use_weighted_masking",
|
||||
"idim": "input_dim",
|
||||
"odim": "num_mel_bins",
|
||||
"spk_embed_dim": "speaker_embed_dim",
|
||||
"langs": "num_languages",
|
||||
"spks": "num_speakers",
|
||||
}
|
||||
|
||||
|
||||
def remap_model_yaml_config(yaml_config_path):
|
||||
with Path(yaml_config_path).open("r", encoding="utf-8") as f:
|
||||
args = yaml.safe_load(f)
|
||||
args = argparse.Namespace(**args)
|
||||
|
||||
remapped_config = {}
|
||||
|
||||
model_params = args.tts_conf["text2mel_params"]
|
||||
# espnet_config_key -> hf_config_key, any keys not included are ignored
|
||||
for espnet_config_key, hf_config_key in CONFIG_MAPPING.items():
|
||||
if espnet_config_key in model_params:
|
||||
remapped_config[hf_config_key] = model_params[espnet_config_key]
|
||||
|
||||
return remapped_config, args.g2p, args.token_list
|
||||
|
||||
|
||||
def convert_espnet_state_dict_to_hf(state_dict):
|
||||
new_state_dict = {}
|
||||
for key in state_dict:
|
||||
if "tts.generator.text2mel." in key:
|
||||
new_key = key.replace("tts.generator.text2mel.", "")
|
||||
if "postnet" in key:
|
||||
new_key = new_key.replace("postnet.postnet", "speech_decoder_postnet.layers")
|
||||
new_key = new_key.replace(".0.weight", ".conv.weight")
|
||||
new_key = new_key.replace(".1.weight", ".batch_norm.weight")
|
||||
new_key = new_key.replace(".1.bias", ".batch_norm.bias")
|
||||
new_key = new_key.replace(".1.running_mean", ".batch_norm.running_mean")
|
||||
new_key = new_key.replace(".1.running_var", ".batch_norm.running_var")
|
||||
new_key = new_key.replace(".1.num_batches_tracked", ".batch_norm.num_batches_tracked")
|
||||
if "feat_out" in key:
|
||||
if "weight" in key:
|
||||
new_key = "speech_decoder_postnet.feat_out.weight"
|
||||
if "bias" in key:
|
||||
new_key = "speech_decoder_postnet.feat_out.bias"
|
||||
if "encoder.embed.0.weight" in key:
|
||||
new_key = new_key.replace("0.", "")
|
||||
if "w_1" in key:
|
||||
new_key = new_key.replace("w_1", "conv1")
|
||||
if "w_2" in key:
|
||||
new_key = new_key.replace("w_2", "conv2")
|
||||
if "predictor.conv" in key:
|
||||
new_key = new_key.replace(".conv", ".conv_layers")
|
||||
pattern = r"(\d)\.(\d)"
|
||||
replacement = (
|
||||
r"\1.conv" if ("2.weight" not in new_key) and ("2.bias" not in new_key) else r"\1.layer_norm"
|
||||
)
|
||||
new_key = re.sub(pattern, replacement, new_key)
|
||||
if "pitch_embed" in key or "energy_embed" in key:
|
||||
new_key = new_key.replace("0", "conv")
|
||||
if "encoders" in key:
|
||||
new_key = new_key.replace("encoders", "conformer_layers")
|
||||
new_key = new_key.replace("norm_final", "final_layer_norm")
|
||||
new_key = new_key.replace("norm_mha", "self_attn_layer_norm")
|
||||
new_key = new_key.replace("norm_ff_macaron", "ff_macaron_layer_norm")
|
||||
new_key = new_key.replace("norm_ff", "ff_layer_norm")
|
||||
new_key = new_key.replace("norm_conv", "conv_layer_norm")
|
||||
if "lid_emb" in key:
|
||||
new_key = new_key.replace("lid_emb", "language_id_embedding")
|
||||
if "sid_emb" in key:
|
||||
new_key = new_key.replace("sid_emb", "speaker_id_embedding")
|
||||
|
||||
new_state_dict[new_key] = state_dict[key]
|
||||
|
||||
return new_state_dict
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def convert_FastSpeech2ConformerModel_checkpoint(
|
||||
checkpoint_path,
|
||||
yaml_config_path,
|
||||
pytorch_dump_folder_path,
|
||||
repo_id=None,
|
||||
):
|
||||
model_params, tokenizer_name, vocab = remap_model_yaml_config(yaml_config_path)
|
||||
config = FastSpeech2ConformerConfig(**model_params)
|
||||
|
||||
# Prepare the model
|
||||
model = FastSpeech2ConformerModel(config)
|
||||
|
||||
espnet_checkpoint = torch.load(checkpoint_path)
|
||||
hf_compatible_state_dict = convert_espnet_state_dict_to_hf(espnet_checkpoint)
|
||||
|
||||
model.load_state_dict(hf_compatible_state_dict)
|
||||
|
||||
model.save_pretrained(pytorch_dump_folder_path)
|
||||
|
||||
# Prepare the tokenizer
|
||||
with TemporaryDirectory() as tempdir:
|
||||
vocab = {token: id for id, token in enumerate(vocab)}
|
||||
vocab_file = Path(tempdir) / "vocab.json"
|
||||
with open(vocab_file, "w") as f:
|
||||
json.dump(vocab, f)
|
||||
should_strip_spaces = "no_space" in tokenizer_name
|
||||
tokenizer = FastSpeech2ConformerTokenizer(str(vocab_file), should_strip_spaces=should_strip_spaces)
|
||||
|
||||
tokenizer.save_pretrained(pytorch_dump_folder_path)
|
||||
|
||||
if repo_id:
|
||||
print("Pushing to the hub...")
|
||||
model.push_to_hub(repo_id)
|
||||
tokenizer.push_to_hub(repo_id)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--checkpoint_path", required=True, default=None, type=str, help="Path to original checkpoint")
|
||||
parser.add_argument(
|
||||
"--yaml_config_path", required=True, default=None, type=str, help="Path to config.yaml of model to convert"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--pytorch_dump_folder_path", required=True, default=None, type=str, help="Path to the output PyTorch model."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--push_to_hub", default=None, type=str, help="Where to upload the converted model on the 🤗 hub."
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
convert_FastSpeech2ConformerModel_checkpoint(
|
||||
args.checkpoint_path,
|
||||
args.yaml_config_path,
|
||||
args.pytorch_dump_folder_path,
|
||||
args.push_to_hub,
|
||||
)
|
||||
134
src/transformers/models/fastspeech2_conformer/convert_hifigan.py
Normal file
134
src/transformers/models/fastspeech2_conformer/convert_hifigan.py
Normal file
@ -0,0 +1,134 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""Convert FastSpeech2Conformer HiFi-GAN checkpoint."""
|
||||
|
||||
import argparse
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
import yaml
|
||||
|
||||
from transformers import FastSpeech2ConformerHifiGan, FastSpeech2ConformerHifiGanConfig, logging
|
||||
|
||||
|
||||
logging.set_verbosity_info()
|
||||
logger = logging.get_logger("transformers.models.FastSpeech2Conformer")
|
||||
|
||||
|
||||
def load_weights(checkpoint, hf_model, config):
|
||||
vocoder_key_prefix = "tts.generator.vocoder."
|
||||
checkpoint = {k.replace(vocoder_key_prefix, ""): v for k, v in checkpoint.items() if vocoder_key_prefix in k}
|
||||
|
||||
hf_model.apply_weight_norm()
|
||||
|
||||
hf_model.conv_pre.weight_g.data = checkpoint["input_conv.weight_g"]
|
||||
hf_model.conv_pre.weight_v.data = checkpoint["input_conv.weight_v"]
|
||||
hf_model.conv_pre.bias.data = checkpoint["input_conv.bias"]
|
||||
|
||||
for i in range(len(config.upsample_rates)):
|
||||
hf_model.upsampler[i].weight_g.data = checkpoint[f"upsamples.{i}.1.weight_g"]
|
||||
hf_model.upsampler[i].weight_v.data = checkpoint[f"upsamples.{i}.1.weight_v"]
|
||||
hf_model.upsampler[i].bias.data = checkpoint[f"upsamples.{i}.1.bias"]
|
||||
|
||||
for i in range(len(config.upsample_rates) * len(config.resblock_kernel_sizes)):
|
||||
for j in range(len(config.resblock_dilation_sizes)):
|
||||
hf_model.resblocks[i].convs1[j].weight_g.data = checkpoint[f"blocks.{i}.convs1.{j}.1.weight_g"]
|
||||
hf_model.resblocks[i].convs1[j].weight_v.data = checkpoint[f"blocks.{i}.convs1.{j}.1.weight_v"]
|
||||
hf_model.resblocks[i].convs1[j].bias.data = checkpoint[f"blocks.{i}.convs1.{j}.1.bias"]
|
||||
|
||||
hf_model.resblocks[i].convs2[j].weight_g.data = checkpoint[f"blocks.{i}.convs2.{j}.1.weight_g"]
|
||||
hf_model.resblocks[i].convs2[j].weight_v.data = checkpoint[f"blocks.{i}.convs2.{j}.1.weight_v"]
|
||||
hf_model.resblocks[i].convs2[j].bias.data = checkpoint[f"blocks.{i}.convs2.{j}.1.bias"]
|
||||
|
||||
hf_model.conv_post.weight_g.data = checkpoint["output_conv.1.weight_g"]
|
||||
hf_model.conv_post.weight_v.data = checkpoint["output_conv.1.weight_v"]
|
||||
hf_model.conv_post.bias.data = checkpoint["output_conv.1.bias"]
|
||||
|
||||
hf_model.remove_weight_norm()
|
||||
|
||||
|
||||
def remap_hifigan_yaml_config(yaml_config_path):
|
||||
with Path(yaml_config_path).open("r", encoding="utf-8") as f:
|
||||
args = yaml.safe_load(f)
|
||||
args = argparse.Namespace(**args)
|
||||
|
||||
vocoder_type = args.tts_conf["vocoder_type"]
|
||||
if vocoder_type != "hifigan_generator":
|
||||
raise TypeError(f"Vocoder config must be for `hifigan_generator`, but got {vocoder_type}")
|
||||
|
||||
remapped_dict = {}
|
||||
vocoder_params = args.tts_conf["vocoder_params"]
|
||||
|
||||
# espnet_config_key -> hf_config_key
|
||||
key_mappings = {
|
||||
"channels": "upsample_initial_channel",
|
||||
"in_channels": "model_in_dim",
|
||||
"resblock_dilations": "resblock_dilation_sizes",
|
||||
"resblock_kernel_sizes": "resblock_kernel_sizes",
|
||||
"upsample_kernel_sizes": "upsample_kernel_sizes",
|
||||
"upsample_scales": "upsample_rates",
|
||||
}
|
||||
for espnet_config_key, hf_config_key in key_mappings.items():
|
||||
remapped_dict[hf_config_key] = vocoder_params[espnet_config_key]
|
||||
remapped_dict["sampling_rate"] = args.tts_conf["sampling_rate"]
|
||||
remapped_dict["normalize_before"] = False
|
||||
remapped_dict["leaky_relu_slope"] = vocoder_params["nonlinear_activation_params"]["negative_slope"]
|
||||
|
||||
return remapped_dict
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def convert_hifigan_checkpoint(
|
||||
checkpoint_path,
|
||||
pytorch_dump_folder_path,
|
||||
yaml_config_path=None,
|
||||
repo_id=None,
|
||||
):
|
||||
if yaml_config_path is not None:
|
||||
config_kwargs = remap_hifigan_yaml_config(yaml_config_path)
|
||||
config = FastSpeech2ConformerHifiGanConfig(**config_kwargs)
|
||||
else:
|
||||
config = FastSpeech2ConformerHifiGanConfig()
|
||||
|
||||
model = FastSpeech2ConformerHifiGan(config)
|
||||
|
||||
orig_checkpoint = torch.load(checkpoint_path)
|
||||
load_weights(orig_checkpoint, model, config)
|
||||
|
||||
model.save_pretrained(pytorch_dump_folder_path)
|
||||
|
||||
if repo_id:
|
||||
print("Pushing to the hub...")
|
||||
model.push_to_hub(repo_id)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--checkpoint_path", required=True, default=None, type=str, help="Path to original checkpoint")
|
||||
parser.add_argument("--yaml_config_path", default=None, type=str, help="Path to config.yaml of model to convert")
|
||||
parser.add_argument(
|
||||
"--pytorch_dump_folder_path", required=True, default=None, type=str, help="Path to the output PyTorch model."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--push_to_hub", default=None, type=str, help="Where to upload the converted model on the 🤗 hub."
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
convert_hifigan_checkpoint(
|
||||
args.checkpoint_path,
|
||||
args.pytorch_dump_folder_path,
|
||||
args.yaml_config_path,
|
||||
args.push_to_hub,
|
||||
)
|
||||
@ -0,0 +1,102 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""Convert FastSpeech2Conformer checkpoint."""
|
||||
|
||||
import argparse
|
||||
|
||||
import torch
|
||||
|
||||
from transformers import (
|
||||
FastSpeech2ConformerConfig,
|
||||
FastSpeech2ConformerHifiGan,
|
||||
FastSpeech2ConformerHifiGanConfig,
|
||||
FastSpeech2ConformerModel,
|
||||
FastSpeech2ConformerWithHifiGan,
|
||||
FastSpeech2ConformerWithHifiGanConfig,
|
||||
logging,
|
||||
)
|
||||
|
||||
from .convert_fastspeech2_conformer_original_pytorch_checkpoint_to_pytorch import (
|
||||
convert_espnet_state_dict_to_hf,
|
||||
remap_model_yaml_config,
|
||||
)
|
||||
from .convert_hifigan import load_weights, remap_hifigan_yaml_config
|
||||
|
||||
|
||||
logging.set_verbosity_info()
|
||||
logger = logging.get_logger("transformers.models.FastSpeech2Conformer")
|
||||
|
||||
|
||||
def convert_FastSpeech2ConformerWithHifiGan_checkpoint(
|
||||
checkpoint_path,
|
||||
yaml_config_path,
|
||||
pytorch_dump_folder_path,
|
||||
repo_id=None,
|
||||
):
|
||||
# Prepare the model
|
||||
model_params, *_ = remap_model_yaml_config(yaml_config_path)
|
||||
model_config = FastSpeech2ConformerConfig(**model_params)
|
||||
|
||||
model = FastSpeech2ConformerModel(model_config)
|
||||
|
||||
espnet_checkpoint = torch.load(checkpoint_path)
|
||||
hf_compatible_state_dict = convert_espnet_state_dict_to_hf(espnet_checkpoint)
|
||||
model.load_state_dict(hf_compatible_state_dict)
|
||||
|
||||
# Prepare the vocoder
|
||||
config_kwargs = remap_hifigan_yaml_config(yaml_config_path)
|
||||
vocoder_config = FastSpeech2ConformerHifiGanConfig(**config_kwargs)
|
||||
|
||||
vocoder = FastSpeech2ConformerHifiGan(vocoder_config)
|
||||
load_weights(espnet_checkpoint, vocoder, vocoder_config)
|
||||
|
||||
# Prepare the model + vocoder
|
||||
config = FastSpeech2ConformerWithHifiGanConfig.from_sub_model_configs(model_config, vocoder_config)
|
||||
with_hifigan_model = FastSpeech2ConformerWithHifiGan(config)
|
||||
with_hifigan_model.model = model
|
||||
with_hifigan_model.vocoder = vocoder
|
||||
|
||||
with_hifigan_model.save_pretrained(pytorch_dump_folder_path)
|
||||
|
||||
if repo_id:
|
||||
print("Pushing to the hub...")
|
||||
with_hifigan_model.push_to_hub(repo_id)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--checkpoint_path", required=True, default=None, type=str, help="Path to original checkpoint")
|
||||
parser.add_argument(
|
||||
"--yaml_config_path", required=True, default=None, type=str, help="Path to config.yaml of model to convert"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--pytorch_dump_folder_path",
|
||||
required=True,
|
||||
default=None,
|
||||
type=str,
|
||||
help="Path to the output `FastSpeech2ConformerModel` PyTorch model.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--push_to_hub", default=None, type=str, help="Where to upload the converted model on the 🤗 hub."
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
convert_FastSpeech2ConformerWithHifiGan_checkpoint(
|
||||
args.checkpoint_path,
|
||||
args.yaml_config_path,
|
||||
args.pytorch_dump_folder_path,
|
||||
args.push_to_hub,
|
||||
)
|
||||
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,198 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 The HuggingFace Team and The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""Tokenization classes for FastSpeech2Conformer."""
|
||||
import json
|
||||
import os
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import regex
|
||||
|
||||
from ...tokenization_utils import PreTrainedTokenizer
|
||||
from ...utils import logging, requires_backends
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json"}
|
||||
|
||||
PRETRAINED_VOCAB_FILES_MAP = {
|
||||
"vocab_file": {
|
||||
"espnet/fastspeech2_conformer": "https://huggingface.co/espnet/fastspeech2_conformer/raw/main/vocab.json",
|
||||
},
|
||||
}
|
||||
|
||||
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
|
||||
# Set to somewhat arbitrary large number as the model input
|
||||
# isn't constrained by the relative positional encoding
|
||||
"espnet/fastspeech2_conformer": 4096,
|
||||
}
|
||||
|
||||
|
||||
class FastSpeech2ConformerTokenizer(PreTrainedTokenizer):
|
||||
"""
|
||||
Construct a FastSpeech2Conformer tokenizer.
|
||||
|
||||
Args:
|
||||
vocab_file (`str`):
|
||||
Path to the vocabulary file.
|
||||
bos_token (`str`, *optional*, defaults to `"<sos/eos>"`):
|
||||
The begin of sequence token. Note that for FastSpeech2, it is the same as the `eos_token`.
|
||||
eos_token (`str`, *optional*, defaults to `"<sos/eos>"`):
|
||||
The end of sequence token. Note that for FastSpeech2, it is the same as the `bos_token`.
|
||||
pad_token (`str`, *optional*, defaults to `"<blank>"`):
|
||||
The token used for padding, for example when batching sequences of different lengths.
|
||||
unk_token (`str`, *optional*, defaults to `"<unk>"`):
|
||||
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
|
||||
token instead.
|
||||
should_strip_spaces (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to strip the spaces from the list of tokens.
|
||||
"""
|
||||
|
||||
vocab_files_names = VOCAB_FILES_NAMES
|
||||
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
||||
model_input_names = ["input_ids", "attention_mask"]
|
||||
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_file,
|
||||
bos_token="<sos/eos>",
|
||||
eos_token="<sos/eos>",
|
||||
pad_token="<blank>",
|
||||
unk_token="<unk>",
|
||||
should_strip_spaces=False,
|
||||
**kwargs,
|
||||
):
|
||||
requires_backends(self, "g2p_en")
|
||||
|
||||
with open(vocab_file, encoding="utf-8") as vocab_handle:
|
||||
self.encoder = json.load(vocab_handle)
|
||||
|
||||
import g2p_en
|
||||
|
||||
self.g2p = g2p_en.G2p()
|
||||
|
||||
self.decoder = {v: k for k, v in self.encoder.items()}
|
||||
|
||||
super().__init__(
|
||||
bos_token=bos_token,
|
||||
eos_token=eos_token,
|
||||
unk_token=unk_token,
|
||||
pad_token=pad_token,
|
||||
should_strip_spaces=should_strip_spaces,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
self.should_strip_spaces = should_strip_spaces
|
||||
|
||||
@property
|
||||
def vocab_size(self):
|
||||
return len(self.decoder)
|
||||
|
||||
def get_vocab(self):
|
||||
"Returns vocab as a dict"
|
||||
return dict(self.encoder, **self.added_tokens_encoder)
|
||||
|
||||
def prepare_for_tokenization(self, text, is_split_into_words=False, **kwargs):
|
||||
# expand symbols
|
||||
text = regex.sub(";", ",", text)
|
||||
text = regex.sub(":", ",", text)
|
||||
text = regex.sub("-", " ", text)
|
||||
text = regex.sub("&", "and", text)
|
||||
|
||||
# strip unnecessary symbols
|
||||
text = regex.sub(r"[\(\)\[\]\<\>\"]+", "", text)
|
||||
|
||||
# strip whitespaces
|
||||
text = regex.sub(r"\s+", " ", text)
|
||||
|
||||
text = text.upper()
|
||||
|
||||
return text, kwargs
|
||||
|
||||
def _tokenize(self, text):
|
||||
"""Returns a tokenized string."""
|
||||
# phonemize
|
||||
tokens = self.g2p(text)
|
||||
|
||||
if self.should_strip_spaces:
|
||||
tokens = list(filter(lambda s: s != " ", tokens))
|
||||
|
||||
tokens.append(self.eos_token)
|
||||
|
||||
return tokens
|
||||
|
||||
def _convert_token_to_id(self, token):
|
||||
"""Converts a token (str) in an id using the vocab."""
|
||||
return self.encoder.get(token, self.encoder.get(self.unk_token))
|
||||
|
||||
def _convert_id_to_token(self, index):
|
||||
"""Converts an index (integer) in a token (str) using the vocab."""
|
||||
return self.decoder.get(index, self.unk_token)
|
||||
|
||||
# Override since phonemes cannot be converted back to strings
|
||||
def decode(self, token_ids, **kwargs):
|
||||
logger.warn(
|
||||
"Phonemes cannot be reliably converted to a string due to the one-many mapping, converting to tokens instead."
|
||||
)
|
||||
return self.convert_ids_to_tokens(token_ids)
|
||||
|
||||
# Override since phonemes cannot be converted back to strings
|
||||
def convert_tokens_to_string(self, tokens, **kwargs):
|
||||
logger.warn(
|
||||
"Phonemes cannot be reliably converted to a string due to the one-many mapping, returning the tokens."
|
||||
)
|
||||
return tokens
|
||||
|
||||
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
|
||||
"""
|
||||
Save the vocabulary and special tokens file to a directory.
|
||||
|
||||
Args:
|
||||
save_directory (`str`):
|
||||
The directory in which to save the vocabulary.
|
||||
|
||||
Returns:
|
||||
`Tuple(str)`: Paths to the files saved.
|
||||
"""
|
||||
if not os.path.isdir(save_directory):
|
||||
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
|
||||
return
|
||||
vocab_file = os.path.join(
|
||||
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
|
||||
)
|
||||
|
||||
with open(vocab_file, "w", encoding="utf-8") as f:
|
||||
f.write(json.dumps(self.get_vocab(), ensure_ascii=False))
|
||||
|
||||
return (vocab_file,)
|
||||
|
||||
def __getstate__(self):
|
||||
state = self.__dict__.copy()
|
||||
state["g2p"] = None
|
||||
return state
|
||||
|
||||
def __setstate__(self, d):
|
||||
self.__dict__ = d
|
||||
|
||||
try:
|
||||
import g2p_en
|
||||
|
||||
self.g2p = g2p_en.G2p()
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"You need to install g2p-en to use FastSpeech2ConformerTokenizer. "
|
||||
"See https://pypi.org/project/g2p-en/ for installation."
|
||||
)
|
||||
@ -2655,6 +2655,7 @@ class SpeechT5ForTextToSpeech(SpeechT5PreTrainedModel):
|
||||
return_dict: Optional[bool] = None,
|
||||
speaker_embeddings: Optional[torch.FloatTensor] = None,
|
||||
labels: Optional[torch.FloatTensor] = None,
|
||||
stop_labels: Optional[torch.Tensor] = None,
|
||||
) -> Union[Tuple, Seq2SeqSpectrogramOutput]:
|
||||
r"""
|
||||
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
||||
@ -2973,6 +2974,7 @@ class SpeechT5ForSpeechToSpeech(SpeechT5PreTrainedModel):
|
||||
return_dict: Optional[bool] = None,
|
||||
speaker_embeddings: Optional[torch.FloatTensor] = None,
|
||||
labels: Optional[torch.FloatTensor] = None,
|
||||
stop_labels: Optional[torch.Tensor] = None,
|
||||
) -> Union[Tuple, Seq2SeqSpectrogramOutput]:
|
||||
r"""
|
||||
input_values (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
|
||||
|
||||
@ -67,6 +67,7 @@ from .utils import (
|
||||
is_flax_available,
|
||||
is_fsdp_available,
|
||||
is_ftfy_available,
|
||||
is_g2p_en_available,
|
||||
is_ipex_available,
|
||||
is_jieba_available,
|
||||
is_jinja_available,
|
||||
@ -365,6 +366,13 @@ def require_fsdp(test_case, min_version: str = "1.12.0"):
|
||||
)
|
||||
|
||||
|
||||
def require_g2p_en(test_case):
|
||||
"""
|
||||
Decorator marking a test that requires g2p_en. These tests are skipped when SentencePiece isn't installed.
|
||||
"""
|
||||
return unittest.skipUnless(is_g2p_en_available(), "test requires g2p_en")(test_case)
|
||||
|
||||
|
||||
def require_safetensors(test_case):
|
||||
"""
|
||||
Decorator marking a test that requires safetensors. These tests are skipped when safetensors isn't installed.
|
||||
|
||||
@ -123,6 +123,7 @@ from .import_utils import (
|
||||
is_flax_available,
|
||||
is_fsdp_available,
|
||||
is_ftfy_available,
|
||||
is_g2p_en_available,
|
||||
is_in_notebook,
|
||||
is_ipex_available,
|
||||
is_jieba_available,
|
||||
|
||||
@ -3422,6 +3422,37 @@ class FalconPreTrainedModel(metaclass=DummyObject):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
|
||||
FASTSPEECH2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
|
||||
|
||||
|
||||
class FastSpeech2ConformerHifiGan(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
|
||||
class FastSpeech2ConformerModel(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
|
||||
class FastSpeech2ConformerPreTrainedModel(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
|
||||
class FastSpeech2ConformerWithHifiGan(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
|
||||
FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
|
||||
|
||||
|
||||
|
||||
@ -94,6 +94,7 @@ except importlib.metadata.PackageNotFoundError:
|
||||
except importlib.metadata.PackageNotFoundError:
|
||||
_faiss_available = False
|
||||
_ftfy_available = _is_package_available("ftfy")
|
||||
_g2p_en_available = _is_package_available("g2p_en")
|
||||
_ipex_available, _ipex_version = _is_package_available("intel_extension_for_pytorch", return_version=True)
|
||||
_jieba_available = _is_package_available("jieba")
|
||||
_jinja_available = _is_package_available("jinja2")
|
||||
@ -444,6 +445,10 @@ def is_ftfy_available():
|
||||
return _ftfy_available
|
||||
|
||||
|
||||
def is_g2p_en_available():
|
||||
return _g2p_en_available
|
||||
|
||||
|
||||
@lru_cache()
|
||||
def is_torch_tpu_available(check_device=True):
|
||||
"Checks if `torch_xla` is installed and potentially if a TPU is in the environment"
|
||||
@ -1059,6 +1064,12 @@ LEVENSHTEIN_IMPORT_ERROR = """
|
||||
install python-Levenshtein`. Please note that you may need to restart your runtime after installation.
|
||||
"""
|
||||
|
||||
# docstyle-ignore
|
||||
G2P_EN_IMPORT_ERROR = """
|
||||
{0} requires the g2p-en library but it was not found in your environment. You can install it with pip:
|
||||
`pip install g2p-en`. Please note that you may need to restart your runtime after installation.
|
||||
"""
|
||||
|
||||
# docstyle-ignore
|
||||
PYTORCH_QUANTIZATION_IMPORT_ERROR = """
|
||||
{0} requires the pytorch-quantization library but it was not found in your environment. You can install it with pip:
|
||||
@ -1101,7 +1112,6 @@ SACREMOSES_IMPORT_ERROR = """
|
||||
`pip install sacremoses`. Please note that you may need to restart your runtime after installation.
|
||||
"""
|
||||
|
||||
|
||||
# docstyle-ignore
|
||||
SCIPY_IMPORT_ERROR = """
|
||||
{0} requires the scipy library but it was not found in your environment. You can install it with pip:
|
||||
@ -1225,6 +1235,7 @@ BACKENDS_MAPPING = OrderedDict(
|
||||
("faiss", (is_faiss_available, FAISS_IMPORT_ERROR)),
|
||||
("flax", (is_flax_available, FLAX_IMPORT_ERROR)),
|
||||
("ftfy", (is_ftfy_available, FTFY_IMPORT_ERROR)),
|
||||
("g2p_en", (is_g2p_en_available, G2P_EN_IMPORT_ERROR)),
|
||||
("pandas", (is_pandas_available, PANDAS_IMPORT_ERROR)),
|
||||
("phonemizer", (is_phonemizer_available, PHONEMIZER_IMPORT_ERROR)),
|
||||
("pretty_midi", (is_pretty_midi_available, PRETTY_MIDI_IMPORT_ERROR)),
|
||||
|
||||
0
tests/models/fastspeech2_conformer/__init__.py
Normal file
0
tests/models/fastspeech2_conformer/__init__.py
Normal file
@ -0,0 +1,790 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Testing suite for the PyTorch FastSpeech2Conformer model."""
|
||||
|
||||
import inspect
|
||||
import tempfile
|
||||
import unittest
|
||||
|
||||
from transformers import (
|
||||
FastSpeech2ConformerConfig,
|
||||
FastSpeech2ConformerHifiGanConfig,
|
||||
FastSpeech2ConformerTokenizer,
|
||||
FastSpeech2ConformerWithHifiGanConfig,
|
||||
is_torch_available,
|
||||
)
|
||||
from transformers.testing_utils import require_g2p_en, require_torch, slow, torch_device
|
||||
|
||||
from ...test_configuration_common import ConfigTester
|
||||
from ...test_modeling_common import ModelTesterMixin, _config_zero_init, ids_tensor
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
import torch
|
||||
|
||||
from transformers import FastSpeech2ConformerModel, FastSpeech2ConformerWithHifiGan, set_seed
|
||||
|
||||
|
||||
class FastSpeech2ConformerModelTester:
|
||||
def __init__(
|
||||
self,
|
||||
parent,
|
||||
batch_size=13,
|
||||
num_hidden_layers=1,
|
||||
num_attention_heads=2,
|
||||
hidden_size=24,
|
||||
seq_length=7,
|
||||
encoder_linear_units=384,
|
||||
decoder_linear_units=384,
|
||||
is_training=False,
|
||||
speech_decoder_postnet_units=128,
|
||||
speech_decoder_postnet_layers=2,
|
||||
pitch_predictor_layers=1,
|
||||
energy_predictor_layers=1,
|
||||
duration_predictor_layers=1,
|
||||
num_mel_bins=8,
|
||||
):
|
||||
self.parent = parent
|
||||
self.batch_size = batch_size
|
||||
self.seq_length = seq_length
|
||||
self.is_training = is_training
|
||||
self.vocab_size = hidden_size
|
||||
self.hidden_size = hidden_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_attention_heads = num_attention_heads
|
||||
self.encoder_linear_units = encoder_linear_units
|
||||
self.decoder_linear_units = decoder_linear_units
|
||||
self.speech_decoder_postnet_units = speech_decoder_postnet_units
|
||||
self.speech_decoder_postnet_layers = speech_decoder_postnet_layers
|
||||
self.pitch_predictor_layers = pitch_predictor_layers
|
||||
self.energy_predictor_layers = energy_predictor_layers
|
||||
self.duration_predictor_layers = duration_predictor_layers
|
||||
self.num_mel_bins = num_mel_bins
|
||||
|
||||
def prepare_config_and_inputs(self):
|
||||
config = self.get_config()
|
||||
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
|
||||
return config, input_ids
|
||||
|
||||
def get_config(self):
|
||||
return FastSpeech2ConformerConfig(
|
||||
hidden_size=self.hidden_size,
|
||||
encoder_layers=self.num_hidden_layers,
|
||||
decoder_layers=self.num_hidden_layers,
|
||||
encoder_linear_units=self.encoder_linear_units,
|
||||
decoder_linear_units=self.decoder_linear_units,
|
||||
speech_decoder_postnet_units=self.speech_decoder_postnet_units,
|
||||
speech_decoder_postnet_layers=self.speech_decoder_postnet_layers,
|
||||
num_mel_bins=self.num_mel_bins,
|
||||
pitch_predictor_layers=self.pitch_predictor_layers,
|
||||
energy_predictor_layers=self.energy_predictor_layers,
|
||||
duration_predictor_layers=self.duration_predictor_layers,
|
||||
)
|
||||
|
||||
def create_and_check_model(self, config, input_ids, *args):
|
||||
model = FastSpeech2ConformerModel(config=config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
result = model(input_ids, return_dict=True)
|
||||
|
||||
# total of 5 keys in result
|
||||
self.parent.assertEqual(len(result), 5)
|
||||
# check batch sizes match
|
||||
for value in result.values():
|
||||
self.parent.assertEqual(value.size(0), self.batch_size)
|
||||
# check duration, pitch, and energy have the appopriate shapes
|
||||
# duration: (batch_size, max_text_length), pitch and energy: (batch_size, max_text_length, 1)
|
||||
self.parent.assertEqual(result["duration_outputs"].shape + (1,), result["pitch_outputs"].shape)
|
||||
self.parent.assertEqual(result["pitch_outputs"].shape, result["energy_outputs"].shape)
|
||||
# check predicted mel-spectrogram has correct dimension
|
||||
self.parent.assertEqual(result["spectrogram"].size(2), model.config.num_mel_bins)
|
||||
|
||||
def prepare_config_and_inputs_for_common(self):
|
||||
config, input_ids = self.prepare_config_and_inputs()
|
||||
inputs_dict = {"input_ids": input_ids}
|
||||
return config, inputs_dict
|
||||
|
||||
|
||||
@require_torch
|
||||
class FastSpeech2ConformerModelTest(ModelTesterMixin, unittest.TestCase):
|
||||
all_model_classes = (FastSpeech2ConformerModel,) if is_torch_available() else ()
|
||||
test_pruning = False
|
||||
test_headmasking = False
|
||||
test_torchscript = False
|
||||
test_resize_embeddings = False
|
||||
is_encoder_decoder = True
|
||||
|
||||
def setUp(self):
|
||||
self.model_tester = FastSpeech2ConformerModelTester(self)
|
||||
self.config_tester = ConfigTester(self, config_class=FastSpeech2ConformerConfig)
|
||||
|
||||
def test_config(self):
|
||||
self.config_tester.run_common_tests()
|
||||
|
||||
def test_model(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_model(*config_and_inputs)
|
||||
|
||||
def test_initialization(self):
|
||||
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
configs_no_init = _config_zero_init(config)
|
||||
for model_class in self.all_model_classes:
|
||||
model = model_class(config=configs_no_init)
|
||||
for name, param in model.named_parameters():
|
||||
if param.requires_grad:
|
||||
msg = f"Parameter {name} of model {model_class} seems not properly initialized"
|
||||
if "norm" in name:
|
||||
if "bias" in name:
|
||||
self.assertEqual(param.data.mean().item(), 0.0, msg=msg)
|
||||
if "weight" in name:
|
||||
self.assertEqual(param.data.mean().item(), 1.0, msg=msg)
|
||||
elif "conv" in name or "embed" in name:
|
||||
self.assertTrue(-1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0, msg=msg)
|
||||
|
||||
def test_duration_energy_pitch_output(self):
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
config.return_dict = True
|
||||
|
||||
seq_len = self.model_tester.seq_length
|
||||
for model_class in self.all_model_classes:
|
||||
model = model_class(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
with torch.no_grad():
|
||||
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
|
||||
|
||||
# duration
|
||||
self.assertListEqual(list(outputs.duration_outputs.shape), [self.model_tester.batch_size, seq_len])
|
||||
# energy
|
||||
self.assertListEqual(list(outputs.energy_outputs.shape), [self.model_tester.batch_size, seq_len, 1])
|
||||
# pitch
|
||||
self.assertListEqual(list(outputs.pitch_outputs.shape), [self.model_tester.batch_size, seq_len, 1])
|
||||
|
||||
def test_hidden_states_output(self):
|
||||
def _check_hidden_states_output(inputs_dict, config, model_class):
|
||||
model = model_class(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
|
||||
|
||||
for idx, hidden_states in enumerate([outputs.encoder_hidden_states, outputs.decoder_hidden_states]):
|
||||
expected_num_layers = getattr(
|
||||
self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
|
||||
)
|
||||
|
||||
self.assertEqual(len(hidden_states), expected_num_layers)
|
||||
self.assertIsInstance(hidden_states, (list, tuple))
|
||||
expected_batch_size, expected_seq_length, expected_hidden_size = hidden_states[0].shape
|
||||
self.assertEqual(expected_batch_size, self.model_tester.batch_size)
|
||||
# Only test encoder seq_length since decoder seq_length is variable based on inputs
|
||||
if idx == 0:
|
||||
self.assertEqual(expected_seq_length, self.model_tester.seq_length)
|
||||
self.assertEqual(expected_hidden_size, self.model_tester.hidden_size)
|
||||
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
|
||||
inputs_dict["output_hidden_states"] = True
|
||||
_check_hidden_states_output(inputs_dict, config, FastSpeech2ConformerModel)
|
||||
|
||||
# check that output_hidden_states also work using config
|
||||
del inputs_dict["output_hidden_states"]
|
||||
config.output_hidden_states = True
|
||||
|
||||
_check_hidden_states_output(inputs_dict, config, FastSpeech2ConformerModel)
|
||||
|
||||
def test_save_load_strict(self):
|
||||
config, _ = self.model_tester.prepare_config_and_inputs()
|
||||
model = FastSpeech2ConformerModel(config)
|
||||
|
||||
with tempfile.TemporaryDirectory() as tmpdirname:
|
||||
model.save_pretrained(tmpdirname)
|
||||
_, info = FastSpeech2ConformerModel.from_pretrained(tmpdirname, output_loading_info=True)
|
||||
self.assertEqual(info["missing_keys"], [])
|
||||
|
||||
def test_forward_signature(self):
|
||||
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
model = FastSpeech2ConformerModel(config)
|
||||
signature = inspect.signature(model.forward)
|
||||
# signature.parameters is an OrderedDict => so arg_names order is deterministic
|
||||
arg_names = [*signature.parameters.keys()]
|
||||
|
||||
expected_arg_names = [
|
||||
"input_ids",
|
||||
"attention_mask",
|
||||
"spectrogram_labels",
|
||||
"duration_labels",
|
||||
"pitch_labels",
|
||||
"energy_labels",
|
||||
"speaker_ids",
|
||||
"lang_ids",
|
||||
"speaker_embedding",
|
||||
"return_dict",
|
||||
"output_attentions",
|
||||
"output_hidden_states",
|
||||
]
|
||||
self.assertListEqual(arg_names, expected_arg_names)
|
||||
|
||||
# Override as FastSpeech2Conformer does not output cross attentions
|
||||
def test_retain_grad_hidden_states_attentions(self):
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
config.output_hidden_states = True
|
||||
config.output_attentions = True
|
||||
|
||||
model = FastSpeech2ConformerModel(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
inputs = self._prepare_for_class(inputs_dict, FastSpeech2ConformerModel)
|
||||
|
||||
outputs = model(**inputs)
|
||||
|
||||
output = outputs[0]
|
||||
|
||||
encoder_hidden_states = outputs.encoder_hidden_states[0]
|
||||
encoder_hidden_states.retain_grad()
|
||||
|
||||
decoder_hidden_states = outputs.decoder_hidden_states[0]
|
||||
decoder_hidden_states.retain_grad()
|
||||
|
||||
encoder_attentions = outputs.encoder_attentions[0]
|
||||
encoder_attentions.retain_grad()
|
||||
|
||||
decoder_attentions = outputs.decoder_attentions[0]
|
||||
decoder_attentions.retain_grad()
|
||||
|
||||
output.flatten()[0].backward(retain_graph=True)
|
||||
|
||||
self.assertIsNotNone(encoder_hidden_states.grad)
|
||||
self.assertIsNotNone(decoder_hidden_states.grad)
|
||||
self.assertIsNotNone(encoder_attentions.grad)
|
||||
self.assertIsNotNone(decoder_attentions.grad)
|
||||
|
||||
def test_attention_outputs(self):
|
||||
"""
|
||||
Custom `test_attention_outputs` since FastSpeech2Conformer does not output cross attentions, has variable
|
||||
decoder attention shape, and uniquely outputs energy, pitch, and durations.
|
||||
"""
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
config.return_dict = True
|
||||
|
||||
seq_len = self.model_tester.seq_length
|
||||
|
||||
for model_class in self.all_model_classes:
|
||||
inputs_dict["output_attentions"] = True
|
||||
inputs_dict["output_hidden_states"] = False
|
||||
config.return_dict = True
|
||||
model = model_class(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
with torch.no_grad():
|
||||
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
|
||||
self.assertEqual(len(outputs.encoder_attentions), self.model_tester.num_hidden_layers)
|
||||
|
||||
# check that output_attentions also work using config
|
||||
del inputs_dict["output_attentions"]
|
||||
config.output_attentions = True
|
||||
model = model_class(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
|
||||
encoder_attentions = outputs.encoder_attentions
|
||||
self.assertEqual(len(encoder_attentions), self.model_tester.num_hidden_layers)
|
||||
self.assertListEqual(
|
||||
list(encoder_attentions[0].shape[-3:]),
|
||||
[self.model_tester.num_attention_heads, seq_len, seq_len],
|
||||
)
|
||||
out_len = len(outputs)
|
||||
|
||||
correct_outlen = 7
|
||||
self.assertEqual(out_len, correct_outlen)
|
||||
|
||||
# Check attention is always last and order is fine
|
||||
inputs_dict["output_attentions"] = True
|
||||
inputs_dict["output_hidden_states"] = True
|
||||
model = model_class(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
with torch.no_grad():
|
||||
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
|
||||
|
||||
added_hidden_states = 2
|
||||
self.assertEqual(out_len + added_hidden_states, len(outputs))
|
||||
|
||||
self_attentions = outputs.encoder_attentions
|
||||
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
|
||||
self.assertListEqual(
|
||||
list(self_attentions[0].shape[-3:]),
|
||||
[self.model_tester.num_attention_heads, seq_len, seq_len],
|
||||
)
|
||||
|
||||
@slow
|
||||
def test_model_from_pretrained(self):
|
||||
model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
|
||||
self.assertIsNotNone(model)
|
||||
|
||||
@unittest.skip(reason="FastSpeech2Conformer does not accept inputs_embeds")
|
||||
def test_inputs_embeds(self):
|
||||
pass
|
||||
|
||||
@unittest.skip(reason="FastSpeech2Conformer has no input embeddings")
|
||||
def test_model_common_attributes(self):
|
||||
pass
|
||||
|
||||
|
||||
@require_torch
|
||||
@require_g2p_en
|
||||
@slow
|
||||
class FastSpeech2ConformerModelIntegrationTest(unittest.TestCase):
|
||||
def test_inference_integration(self):
|
||||
model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
|
||||
text = "Test that this generates speech"
|
||||
input_ids = tokenizer(text, return_tensors="pt").to(torch_device)["input_ids"]
|
||||
|
||||
outputs_dict = model(input_ids)
|
||||
spectrogram = outputs_dict["spectrogram"]
|
||||
|
||||
# mel-spectrogram is too large (1, 205, 80), so only check top-left 100 elements
|
||||
# fmt: off
|
||||
expected_mel_spectrogram = torch.tensor(
|
||||
[
|
||||
[-1.2426, -1.7286, -1.6754, -1.7451, -1.6402, -1.5219, -1.4480, -1.3345, -1.4031, -1.4497],
|
||||
[-0.7858, -1.4966, -1.3602, -1.4876, -1.2949, -1.0723, -1.0021, -0.7553, -0.6521, -0.6929],
|
||||
[-0.7298, -1.3908, -1.0369, -1.2656, -1.0342, -0.7883, -0.7420, -0.5249, -0.3734, -0.3977],
|
||||
[-0.4784, -1.3508, -1.1558, -1.4678, -1.2820, -1.0252, -1.0868, -0.9006, -0.8947, -0.8448],
|
||||
[-0.3963, -1.2895, -1.2813, -1.6147, -1.4658, -1.2560, -1.4134, -1.2650, -1.3255, -1.1715],
|
||||
[-1.4914, -1.3097, -0.3821, -0.3898, -0.5748, -0.9040, -1.0755, -1.0575, -1.2205, -1.0572],
|
||||
[0.0197, -0.0582, 0.9147, 1.1512, 1.1651, 0.6628, -0.1010, -0.3085, -0.2285, 0.2650],
|
||||
[1.1780, 0.1803, 0.7251, 1.5728, 1.6678, 0.4542, -0.1572, -0.1787, 0.0744, 0.8168],
|
||||
[-0.2078, -0.3211, 1.1096, 1.5085, 1.4632, 0.6299, -0.0515, 0.0589, 0.8609, 1.4429],
|
||||
[0.7831, -0.2663, 1.0352, 1.4489, 0.9088, 0.0247, -0.3995, 0.0078, 1.2446, 1.6998],
|
||||
],
|
||||
device=torch_device,
|
||||
)
|
||||
# fmt: on
|
||||
|
||||
self.assertTrue(torch.allclose(spectrogram[0, :10, :10], expected_mel_spectrogram, atol=1e-4))
|
||||
self.assertEqual(spectrogram.shape, (1, 205, model.config.num_mel_bins))
|
||||
|
||||
def test_training_integration(self):
|
||||
model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
|
||||
model.to(torch_device)
|
||||
# Set self.training manually to keep deterministic but run the training path
|
||||
model.training = True
|
||||
set_seed(0)
|
||||
|
||||
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
|
||||
text = "Test that this generates speech"
|
||||
input_ids = tokenizer(text, return_tensors="pt").to(torch_device)["input_ids"]
|
||||
|
||||
# NOTE: Dummy numbers since FastSpeech2Conformer does not have a feature extractor due to the package deps required (librosa, MFA)
|
||||
batch_size, max_text_len = input_ids.shape
|
||||
pitch_labels = torch.rand((batch_size, max_text_len, 1), dtype=torch.float, device=torch_device)
|
||||
energy_labels = torch.rand((batch_size, max_text_len, 1), dtype=torch.float, device=torch_device)
|
||||
duration_labels = torch.normal(10, 2, size=(batch_size, max_text_len)).clamp(1, 20).int()
|
||||
max_target_len, _ = duration_labels.sum(dim=1).max(dim=0)
|
||||
max_target_len = max_target_len.item()
|
||||
spectrogram_labels = torch.rand(
|
||||
(batch_size, max_target_len, model.num_mel_bins), dtype=torch.float, device=torch_device
|
||||
)
|
||||
|
||||
outputs_dict = model(
|
||||
input_ids,
|
||||
spectrogram_labels=spectrogram_labels,
|
||||
duration_labels=duration_labels,
|
||||
pitch_labels=pitch_labels,
|
||||
energy_labels=energy_labels,
|
||||
return_dict=True,
|
||||
)
|
||||
spectrogram = outputs_dict["spectrogram"]
|
||||
loss = outputs_dict["loss"]
|
||||
|
||||
# # mel-spectrogram is too large (1, 224, 80), so only check top-left 100 elements
|
||||
# fmt: off
|
||||
expected_mel_spectrogram = torch.tensor(
|
||||
[
|
||||
[-1.0643e+00, -6.8058e-01, -1.0901e+00, -8.2724e-01, -7.7241e-01, -1.1905e+00, -8.5725e-01, -8.2930e-01, -1.1313e+00, -1.2449e+00],
|
||||
[-5.5067e-01, -2.7045e-01, -6.3483e-01, -1.9320e-01, 1.0234e-01, -3.3253e-01, -2.4423e-01, -3.5045e-01, -5.2070e-01, -4.3710e-01],
|
||||
[ 2.2181e-01, 3.1433e-01, -1.2849e-01, 6.0253e-01, 1.0033e+00, 1.3952e-01, 1.2851e-01, -2.3063e-02, -1.5092e-01, 2.4903e-01],
|
||||
[ 4.6343e-01, 4.1820e-01, 1.6468e-01, 1.1297e+00, 1.4588e+00, 1.3737e-01, 6.6355e-02, -6.0973e-02, -5.4225e-02, 5.9208e-01],
|
||||
[ 5.2762e-01, 4.8725e-01, 4.2735e-01, 1.4392e+00, 1.7398e+00, 2.4891e-01, -8.4531e-03, -8.1282e-02, 1.2857e-01, 8.7559e-01],
|
||||
[ 5.2548e-01, 5.1653e-01, 5.2034e-01, 1.3782e+00, 1.5972e+00, 1.6380e-01, -5.1807e-02, 1.5474e-03, 2.2824e-01, 8.5288e-01],
|
||||
[ 3.6356e-01, 4.4109e-01, 4.4257e-01, 9.4273e-01, 1.1201e+00, -9.0551e-03, -1.1627e-01, -2.0821e-02, 1.0793e-01, 5.0336e-01],
|
||||
[ 3.6598e-01, 3.2708e-01, 1.3297e-01, 4.5162e-01, 6.4168e-01, -2.6923e-01, -2.3101e-01, -1.4943e-01, -1.4732e-01, 7.3057e-02],
|
||||
[ 2.7639e-01, 2.2588e-01, -1.5310e-01, 1.0957e-01, 3.3048e-01, -5.3431e-01, -3.3822e-01, -2.8007e-01, -3.3823e-01, -1.5775e-01],
|
||||
[ 2.9323e-01, 1.6723e-01, -3.4153e-01, -1.1209e-01, 1.7355e-01, -6.1724e-01, -5.4201e-01, -4.9944e-01, -5.2212e-01, -2.7596e-01]
|
||||
],
|
||||
device=torch_device,
|
||||
)
|
||||
# fmt: on
|
||||
|
||||
expected_loss = torch.tensor(74.4595, device=torch_device)
|
||||
|
||||
self.assertTrue(torch.allclose(spectrogram[0, :10, :10], expected_mel_spectrogram, atol=1e-3))
|
||||
self.assertTrue(torch.allclose(loss, expected_loss, atol=1e-4))
|
||||
self.assertEqual(spectrogram.shape, (1, 224, model.config.num_mel_bins))
|
||||
|
||||
|
||||
class FastSpeech2ConformerWithHifiGanTester:
|
||||
def __init__(
|
||||
self,
|
||||
parent,
|
||||
batch_size=13,
|
||||
num_hidden_layers=1,
|
||||
num_attention_heads=2,
|
||||
hidden_size=24,
|
||||
seq_length=7,
|
||||
encoder_linear_units=384,
|
||||
decoder_linear_units=384,
|
||||
is_training=False,
|
||||
speech_decoder_postnet_units=128,
|
||||
speech_decoder_postnet_layers=2,
|
||||
pitch_predictor_layers=1,
|
||||
energy_predictor_layers=1,
|
||||
duration_predictor_layers=1,
|
||||
num_mel_bins=8,
|
||||
upsample_initial_channel=64,
|
||||
):
|
||||
self.parent = parent
|
||||
self.batch_size = batch_size
|
||||
self.seq_length = seq_length
|
||||
self.is_training = is_training
|
||||
self.vocab_size = hidden_size
|
||||
self.hidden_size = hidden_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_attention_heads = num_attention_heads
|
||||
self.encoder_linear_units = encoder_linear_units
|
||||
self.decoder_linear_units = decoder_linear_units
|
||||
self.speech_decoder_postnet_units = speech_decoder_postnet_units
|
||||
self.speech_decoder_postnet_layers = speech_decoder_postnet_layers
|
||||
self.pitch_predictor_layers = pitch_predictor_layers
|
||||
self.energy_predictor_layers = energy_predictor_layers
|
||||
self.duration_predictor_layers = duration_predictor_layers
|
||||
self.num_mel_bins = num_mel_bins
|
||||
self.upsample_initial_channel = upsample_initial_channel
|
||||
|
||||
def prepare_config_and_inputs(self):
|
||||
config = self.get_config()
|
||||
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
|
||||
return config, input_ids
|
||||
|
||||
def get_config(self):
|
||||
self.model_config = FastSpeech2ConformerConfig(
|
||||
hidden_size=self.hidden_size,
|
||||
encoder_layers=self.num_hidden_layers,
|
||||
decoder_layers=self.num_hidden_layers,
|
||||
encoder_linear_units=self.encoder_linear_units,
|
||||
decoder_linear_units=self.decoder_linear_units,
|
||||
speech_decoder_postnet_units=self.speech_decoder_postnet_units,
|
||||
speech_decoder_postnet_layers=self.speech_decoder_postnet_layers,
|
||||
num_mel_bins=self.num_mel_bins,
|
||||
pitch_predictor_layers=self.pitch_predictor_layers,
|
||||
energy_predictor_layers=self.energy_predictor_layers,
|
||||
duration_predictor_layers=self.duration_predictor_layers,
|
||||
)
|
||||
self.vocoder_config = FastSpeech2ConformerHifiGanConfig(
|
||||
model_in_dim=self.num_mel_bins, upsample_initial_channel=self.upsample_initial_channel
|
||||
)
|
||||
return FastSpeech2ConformerWithHifiGanConfig(
|
||||
model_config=self.model_config.to_dict(), vocoder_config=self.vocoder_config.to_dict()
|
||||
)
|
||||
|
||||
def create_and_check_model(self, config, input_ids, *args):
|
||||
model = FastSpeech2ConformerWithHifiGan(config=config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
result = model(input_ids, return_dict=True)
|
||||
|
||||
# total of 5 keys in result
|
||||
self.parent.assertEqual(len(result), 6)
|
||||
# check batch sizes match
|
||||
for value in result.values():
|
||||
self.parent.assertEqual(value.size(0), self.batch_size)
|
||||
# check duration, pitch, and energy have the appopriate shapes
|
||||
# duration: (batch_size, max_text_length), pitch and energy: (batch_size, max_text_length, 1)
|
||||
self.parent.assertEqual(result["duration_outputs"].shape + (1,), result["pitch_outputs"].shape)
|
||||
self.parent.assertEqual(result["pitch_outputs"].shape, result["energy_outputs"].shape)
|
||||
# check predicted mel-spectrogram has correct dimension
|
||||
self.parent.assertEqual(result["spectrogram"].size(2), model.config.model_config.num_mel_bins)
|
||||
|
||||
def prepare_config_and_inputs_for_common(self):
|
||||
config, input_ids = self.prepare_config_and_inputs()
|
||||
inputs_dict = {"input_ids": input_ids}
|
||||
return config, inputs_dict
|
||||
|
||||
|
||||
class FastSpeech2ConformerWithHifiGanTest(ModelTesterMixin, unittest.TestCase):
|
||||
all_model_classes = (FastSpeech2ConformerWithHifiGan,) if is_torch_available() else ()
|
||||
test_pruning = False
|
||||
test_headmasking = False
|
||||
test_torchscript = False
|
||||
test_resize_embeddings = False
|
||||
is_encoder_decoder = True
|
||||
|
||||
def setUp(self):
|
||||
self.model_tester = FastSpeech2ConformerWithHifiGanTester(self)
|
||||
|
||||
def test_model(self):
|
||||
config_and_inputs = self.model_tester.prepare_config_and_inputs()
|
||||
self.model_tester.create_and_check_model(*config_and_inputs)
|
||||
|
||||
def test_initialization(self):
|
||||
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
configs_no_init = _config_zero_init(config)
|
||||
for model_class in self.all_model_classes:
|
||||
model = model_class(config=configs_no_init)
|
||||
for name, param in model.named_parameters():
|
||||
if param.requires_grad:
|
||||
msg = f"Parameter {name} of model {model_class} seems not properly initialized"
|
||||
if "norm" in name:
|
||||
if "bias" in name:
|
||||
self.assertEqual(param.data.mean().item(), 0.0, msg=msg)
|
||||
if "weight" in name:
|
||||
self.assertEqual(param.data.mean().item(), 1.0, msg=msg)
|
||||
elif "conv" in name or "embed" in name:
|
||||
self.assertTrue(-1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0, msg=msg)
|
||||
|
||||
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
|
||||
return inputs_dict
|
||||
|
||||
def test_duration_energy_pitch_output(self):
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
config.model_config.return_dict = True
|
||||
|
||||
seq_len = self.model_tester.seq_length
|
||||
for model_class in self.all_model_classes:
|
||||
model = model_class(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
with torch.no_grad():
|
||||
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
|
||||
|
||||
# duration
|
||||
self.assertListEqual(list(outputs.duration_outputs.shape), [self.model_tester.batch_size, seq_len])
|
||||
# energy
|
||||
self.assertListEqual(list(outputs.energy_outputs.shape), [self.model_tester.batch_size, seq_len, 1])
|
||||
# pitch
|
||||
self.assertListEqual(list(outputs.pitch_outputs.shape), [self.model_tester.batch_size, seq_len, 1])
|
||||
|
||||
def test_hidden_states_output(self):
|
||||
def _check_hidden_states_output(inputs_dict, config, model_class):
|
||||
model = model_class(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
|
||||
|
||||
for idx, hidden_states in enumerate([outputs.encoder_hidden_states, outputs.decoder_hidden_states]):
|
||||
expected_num_layers = getattr(
|
||||
self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
|
||||
)
|
||||
|
||||
self.assertEqual(len(hidden_states), expected_num_layers)
|
||||
self.assertIsInstance(hidden_states, (list, tuple))
|
||||
expected_batch_size, expected_seq_length, expected_hidden_size = hidden_states[0].shape
|
||||
self.assertEqual(expected_batch_size, self.model_tester.batch_size)
|
||||
# Only test encoder seq_length since decoder seq_length is variable based on inputs
|
||||
if idx == 0:
|
||||
self.assertEqual(expected_seq_length, self.model_tester.seq_length)
|
||||
self.assertEqual(expected_hidden_size, self.model_tester.hidden_size)
|
||||
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
|
||||
inputs_dict["output_hidden_states"] = True
|
||||
_check_hidden_states_output(inputs_dict, config, FastSpeech2ConformerWithHifiGan)
|
||||
|
||||
# check that output_hidden_states also work using config
|
||||
del inputs_dict["output_hidden_states"]
|
||||
config.model_config.output_hidden_states = True
|
||||
|
||||
_check_hidden_states_output(inputs_dict, config, FastSpeech2ConformerWithHifiGan)
|
||||
|
||||
def test_save_load_strict(self):
|
||||
config, _ = self.model_tester.prepare_config_and_inputs()
|
||||
model = FastSpeech2ConformerWithHifiGan(config)
|
||||
|
||||
with tempfile.TemporaryDirectory() as tmpdirname:
|
||||
model.save_pretrained(tmpdirname)
|
||||
_, info = FastSpeech2ConformerWithHifiGan.from_pretrained(tmpdirname, output_loading_info=True)
|
||||
self.assertEqual(info["missing_keys"], [])
|
||||
|
||||
def test_forward_signature(self):
|
||||
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
model = FastSpeech2ConformerWithHifiGan(config)
|
||||
signature = inspect.signature(model.forward)
|
||||
# signature.parameters is an OrderedDict => so arg_names order is deterministic
|
||||
arg_names = [*signature.parameters.keys()]
|
||||
|
||||
expected_arg_names = [
|
||||
"input_ids",
|
||||
"attention_mask",
|
||||
"spectrogram_labels",
|
||||
"duration_labels",
|
||||
"pitch_labels",
|
||||
"energy_labels",
|
||||
"speaker_ids",
|
||||
"lang_ids",
|
||||
"speaker_embedding",
|
||||
"return_dict",
|
||||
"output_attentions",
|
||||
"output_hidden_states",
|
||||
]
|
||||
self.assertListEqual(arg_names, expected_arg_names)
|
||||
|
||||
# Override as FastSpeech2Conformer does not output cross attentions
|
||||
def test_retain_grad_hidden_states_attentions(self):
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
config.model_config.output_hidden_states = True
|
||||
config.model_config.output_attentions = True
|
||||
|
||||
model = FastSpeech2ConformerWithHifiGan(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
inputs = self._prepare_for_class(inputs_dict, FastSpeech2ConformerModel)
|
||||
|
||||
outputs = model(**inputs)
|
||||
|
||||
output = outputs[0]
|
||||
|
||||
encoder_hidden_states = outputs.encoder_hidden_states[0]
|
||||
encoder_hidden_states.retain_grad()
|
||||
|
||||
decoder_hidden_states = outputs.decoder_hidden_states[0]
|
||||
decoder_hidden_states.retain_grad()
|
||||
|
||||
encoder_attentions = outputs.encoder_attentions[0]
|
||||
encoder_attentions.retain_grad()
|
||||
|
||||
decoder_attentions = outputs.decoder_attentions[0]
|
||||
decoder_attentions.retain_grad()
|
||||
|
||||
output.flatten()[0].backward(retain_graph=True)
|
||||
|
||||
self.assertIsNotNone(encoder_hidden_states.grad)
|
||||
self.assertIsNotNone(decoder_hidden_states.grad)
|
||||
self.assertIsNotNone(encoder_attentions.grad)
|
||||
self.assertIsNotNone(decoder_attentions.grad)
|
||||
|
||||
def test_attention_outputs(self):
|
||||
"""
|
||||
Custom `test_attention_outputs` since FastSpeech2Conformer does not output cross attentions, has variable
|
||||
decoder attention shape, and uniquely outputs energy, pitch, and durations.
|
||||
"""
|
||||
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
|
||||
config.model_config.return_dict = True
|
||||
|
||||
seq_len = self.model_tester.seq_length
|
||||
|
||||
for model_class in self.all_model_classes:
|
||||
inputs_dict["output_attentions"] = True
|
||||
inputs_dict["output_hidden_states"] = False
|
||||
config.model_config.return_dict = True
|
||||
model = model_class(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
with torch.no_grad():
|
||||
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
|
||||
self.assertEqual(len(outputs.encoder_attentions), self.model_tester.num_hidden_layers)
|
||||
|
||||
# check that output_attentions also work using config
|
||||
del inputs_dict["output_attentions"]
|
||||
config.model_config.output_attentions = True
|
||||
model = model_class(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
|
||||
encoder_attentions = outputs.encoder_attentions
|
||||
self.assertEqual(len(encoder_attentions), self.model_tester.num_hidden_layers)
|
||||
self.assertListEqual(
|
||||
list(encoder_attentions[0].shape[-3:]),
|
||||
[self.model_tester.num_attention_heads, seq_len, seq_len],
|
||||
)
|
||||
out_len = len(outputs)
|
||||
|
||||
correct_outlen = 8
|
||||
self.assertEqual(out_len, correct_outlen)
|
||||
|
||||
# Check attention is always last and order is fine
|
||||
inputs_dict["output_attentions"] = True
|
||||
inputs_dict["output_hidden_states"] = True
|
||||
model = model_class(config)
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
with torch.no_grad():
|
||||
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
|
||||
|
||||
added_hidden_states = 2
|
||||
self.assertEqual(out_len + added_hidden_states, len(outputs))
|
||||
|
||||
self_attentions = outputs.encoder_attentions
|
||||
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
|
||||
self.assertListEqual(
|
||||
list(self_attentions[0].shape[-3:]),
|
||||
[self.model_tester.num_attention_heads, seq_len, seq_len],
|
||||
)
|
||||
|
||||
@slow
|
||||
def test_model_from_pretrained(self):
|
||||
model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
|
||||
self.assertIsNotNone(model)
|
||||
|
||||
@unittest.skip(reason="FastSpeech2Conformer does not accept inputs_embeds")
|
||||
def test_inputs_embeds(self):
|
||||
pass
|
||||
|
||||
@unittest.skip(reason="FastSpeech2Conformer has no input embeddings")
|
||||
def test_model_common_attributes(self):
|
||||
pass
|
||||
|
||||
|
||||
@require_torch
|
||||
@require_g2p_en
|
||||
@slow
|
||||
class FastSpeech2ConformerWithHifiGanIntegrationTest(unittest.TestCase):
|
||||
def test_inference_integration(self):
|
||||
model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
|
||||
model.to(torch_device)
|
||||
model.eval()
|
||||
|
||||
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
|
||||
text = "Test that this generates speech"
|
||||
input_ids = tokenizer(text, return_tensors="pt").to(torch_device)["input_ids"]
|
||||
|
||||
output = model(input_ids)
|
||||
waveform = output.waveform
|
||||
|
||||
# waveform is too large (1, 52480), so only check first 100 elements
|
||||
# fmt: off
|
||||
expected_waveform = torch.tensor(
|
||||
[
|
||||
[-9.6345e-04, 1.3557e-03, 5.7559e-04, 2.4706e-04, 2.2675e-04, 1.2258e-04, 4.7784e-04, 1.0109e-03, -1.9718e-04, 6.3495e-04, 3.2106e-04, 6.3620e-05, 9.1713e-04, -2.5664e-05, 1.9596e-04, 6.0418e-04, 8.1112e-04, 3.6342e-04, -6.3396e-04, -2.0146e-04, -1.1768e-04, 4.3155e-04, 7.5599e-04, -2.2972e-04, -9.5665e-05, 3.3078e-04, 1.3793e-04, -1.4932e-04, -3.9645e-04, 3.6473e-05, -1.7224e-04, -4.5370e-05, -4.8950e-04, -4.3059e-04, 1.0451e-04, -1.0485e-03, -6.0410e-04, 1.6990e-04, -2.1997e-04, -3.8769e-04, -7.6898e-04, -3.2372e-04, -1.9783e-04, 5.2896e-05, -1.0586e-03, -7.8516e-04, 7.6867e-04, -8.5331e-05, -4.8158e-04, -4.5362e-05, -1.0770e-04, 6.6823e-04, 3.0765e-04, 3.3669e-04, 9.5677e-04, 1.0458e-03, 5.8129e-04, 3.3737e-04, 1.0816e-03, 7.0346e-04, 4.2378e-04, 4.3131e-04, 2.8095e-04, 1.2201e-03, 5.6121e-04, -1.1086e-04, 4.9908e-04, 1.5586e-04, 4.2046e-04, -2.8088e-04, -2.2462e-04, -1.5539e-04, -7.0126e-04, -2.8577e-04, -3.3693e-04, -1.2471e-04, -6.9104e-04, -1.2867e-03, -6.2651e-04, -2.5586e-04, -1.3201e-04, -9.4537e-04, -4.8438e-04, 4.1458e-04, 6.4109e-04, 1.0891e-04, -6.3764e-04, 4.5573e-04, 8.2974e-04, 3.2973e-06, -3.8274e-04, -2.0400e-04, 4.9922e-04, 2.1508e-04, -1.1009e-04, -3.9763e-05, 3.0576e-04, 3.1485e-05, -2.7574e-05, 3.3856e-04],
|
||||
],
|
||||
device=torch_device,
|
||||
)
|
||||
# fmt: on
|
||||
|
||||
self.assertTrue(torch.allclose(waveform[0, :100], expected_waveform, atol=1e-4))
|
||||
self.assertEqual(waveform.shape, (1, 52480))
|
||||
@ -0,0 +1,190 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""Tests for the FastSpeech2Conformer tokenizer."""
|
||||
|
||||
import unittest
|
||||
|
||||
from transformers.models.fastspeech2_conformer import FastSpeech2ConformerTokenizer
|
||||
from transformers.testing_utils import require_g2p_en, slow
|
||||
|
||||
from ...test_tokenization_common import TokenizerTesterMixin
|
||||
|
||||
|
||||
@require_g2p_en
|
||||
class FastSpeech2ConformerTokenizerTest(TokenizerTesterMixin, unittest.TestCase):
|
||||
tokenizer_class = FastSpeech2ConformerTokenizer
|
||||
test_rust_tokenizer = False
|
||||
|
||||
def setUp(self):
|
||||
super().setUp()
|
||||
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
|
||||
tokenizer.save_pretrained(self.tmpdirname)
|
||||
|
||||
def get_input_output_texts(self, tokenizer):
|
||||
input_text = "this is a test"
|
||||
output_text = "this is a test"
|
||||
return input_text, output_text
|
||||
|
||||
# Custom `get_clean_sequence` since FastSpeech2ConformerTokenizer can't decode id -> string
|
||||
def get_clean_sequence(self, tokenizer, with_prefix_space=False, **kwargs): # max_length=20, min_length=5
|
||||
input_text, output_text = self.get_input_output_texts(tokenizer)
|
||||
ids = tokenizer.encode(output_text, add_special_tokens=False)
|
||||
return output_text, ids
|
||||
|
||||
def test_convert_token_and_id(self):
|
||||
"""Test ``_convert_token_to_id`` and ``_convert_id_to_token``."""
|
||||
token = "<unk>"
|
||||
token_id = 1
|
||||
|
||||
self.assertEqual(self.get_tokenizer()._convert_token_to_id(token), token_id)
|
||||
self.assertEqual(self.get_tokenizer()._convert_id_to_token(token_id), token)
|
||||
|
||||
def test_get_vocab(self):
|
||||
vocab_keys = list(self.get_tokenizer().get_vocab().keys())
|
||||
|
||||
self.assertEqual(vocab_keys[0], "<blank>")
|
||||
self.assertEqual(vocab_keys[1], "<unk>")
|
||||
self.assertEqual(vocab_keys[-4], "UH0")
|
||||
self.assertEqual(vocab_keys[-2], "..")
|
||||
self.assertEqual(vocab_keys[-1], "<sos/eos>")
|
||||
self.assertEqual(len(vocab_keys), 78)
|
||||
|
||||
def test_vocab_size(self):
|
||||
self.assertEqual(self.get_tokenizer().vocab_size, 78)
|
||||
|
||||
@unittest.skip(
|
||||
"FastSpeech2Conformer tokenizer does not support adding tokens as they can't be added to the g2p_en backend"
|
||||
)
|
||||
def test_added_token_are_matched_longest_first(self):
|
||||
pass
|
||||
|
||||
@unittest.skip(
|
||||
"FastSpeech2Conformer tokenizer does not support adding tokens as they can't be added to the g2p_en backend"
|
||||
)
|
||||
def test_added_tokens_do_lower_case(self):
|
||||
pass
|
||||
|
||||
@unittest.skip(
|
||||
"FastSpeech2Conformer tokenizer does not support adding tokens as they can't be added to the g2p_en backend"
|
||||
)
|
||||
def test_tokenize_special_tokens(self):
|
||||
pass
|
||||
|
||||
def test_full_tokenizer(self):
|
||||
tokenizer = self.get_tokenizer()
|
||||
|
||||
tokens = tokenizer.tokenize("This is a test")
|
||||
ids = [9, 12, 6, 12, 11, 2, 4, 15, 6, 4, 77]
|
||||
self.assertListEqual(tokens, ["DH", "IH1", "S", "IH1", "Z", "AH0", "T", "EH1", "S", "T", "<sos/eos>"])
|
||||
self.assertListEqual(tokenizer.convert_tokens_to_ids(tokens), ids)
|
||||
self.assertListEqual(tokenizer.convert_ids_to_tokens(ids), tokens)
|
||||
|
||||
@slow
|
||||
def test_tokenizer_integration(self):
|
||||
# Custom test since:
|
||||
# 1) This tokenizer only decodes to tokens (phonemes cannot be converted to text with complete accuracy)
|
||||
# 2) Uses a sequence without numbers since espnet has different, custom number conversion.
|
||||
# This tokenizer can phonemize numbers, but where in espnet "32" is phonemized as "thirty two",
|
||||
# here "32" is phonemized as "thirty-two" because we haven't implemented the custom number handling.
|
||||
|
||||
sequences = [
|
||||
"Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides "
|
||||
"general-purpose architectures (BERT, GPT, RoBERTa, XLM, DistilBert, XLNet...) for Natural "
|
||||
"Language Understanding (NLU) and Natural Language Generation (NLG) with over thirty-two pretrained "
|
||||
"models in one hundred plus languages and deep interoperability between Jax, PyTorch and TensorFlow.",
|
||||
"BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly "
|
||||
"conditioning on both left and right context in all layers.",
|
||||
"The quick brown fox jumps over the lazy dog.",
|
||||
]
|
||||
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained(
|
||||
"espnet/fastspeech2_conformer", revision="07f9c4a2d6bbc69b277d87d2202ad1e35b05e113"
|
||||
)
|
||||
actual_encoding = tokenizer(sequences)
|
||||
|
||||
# fmt: off
|
||||
expected_encoding = {
|
||||
'input_ids': [
|
||||
[4, 7, 60, 3, 6, 22, 30, 7, 14, 21, 11, 22, 30, 7, 14, 21, 8, 29, 3, 34, 3, 18, 11, 17, 12, 4, 21, 10, 4, 7, 60, 3, 6, 22, 30, 7, 14, 21, 11, 2, 3, 5, 17, 12, 4, 21, 10, 17, 7, 29, 4, 7, 31, 3, 5, 25, 38, 4, 17, 7, 2, 20, 32, 5, 11, 40, 15, 3, 21, 2, 8, 17, 38, 17, 2, 6, 24, 7, 10, 2, 4, 45, 10, 39, 21, 11, 25, 38, 4, 23, 37, 15, 4, 6, 23, 7, 2, 25, 38, 4, 2, 23, 11, 8, 15, 14, 11, 23, 5, 13, 6, 4, 12, 8, 4, 21, 25, 23, 11, 8, 15, 3, 39, 2, 8, 1, 22, 30, 7, 3, 18, 39, 21, 2, 8, 8, 18, 36, 37, 16, 2, 40, 62, 3, 5, 21, 6, 4, 18, 3, 5, 13, 36, 3, 8, 28, 2, 3, 5, 3, 18, 39, 21, 2, 8, 8, 18, 36, 37, 16, 2, 40, 40, 45, 3, 21, 31, 35, 2, 3, 15, 8, 36, 16, 12, 9, 34, 20, 21, 43, 38, 5, 29, 4, 28, 17, 7, 29, 4, 7, 31, 3, 5, 14, 24, 5, 2, 8, 11, 13, 3, 16, 19, 3, 26, 19, 3, 5, 7, 2, 5, 17, 8, 19, 6, 8, 18, 36, 37, 16, 2, 40, 2, 11, 2, 3, 5, 5, 27, 17, 49, 3, 4, 21, 2, 17, 21, 25, 12, 8, 2, 4, 29, 25, 13, 4, 16, 27, 3, 40, 18, 10, 6, 23, 17, 12, 4, 21, 10, 2, 3, 5, 4, 15, 3, 6, 21, 8, 46, 22, 33, 77],
|
||||
[25, 38, 4, 12, 11, 5, 13, 11, 32, 3, 5, 4, 28, 17, 7, 27, 4, 7, 31, 3, 5, 27, 17, 25, 51, 5, 13, 7, 15, 10, 35, 2, 3, 2, 8, 7, 45, 17, 7, 2, 11, 2, 3, 4, 31, 35, 2, 3, 11, 22, 7, 19, 14, 2, 3, 8, 31, 25, 2, 8, 5, 4, 15, 10, 6, 4, 25, 32, 40, 55, 3, 4, 8, 29, 10, 2, 3, 5, 12, 35, 2, 3, 13, 36, 24, 3, 25, 34, 43, 8, 15, 22, 4, 2, 3, 5, 7, 32, 4, 10, 24, 3, 4, 54, 10, 6, 4, 13, 3, 30, 8, 8, 31, 21, 11, 33, 77],
|
||||
[9, 2, 10, 16, 12, 10, 25, 7, 42, 3, 22, 24, 10, 6, 40, 19, 14, 17, 6, 34, 20, 21, 9, 2, 8, 31, 11, 29, 5, 30, 37, 33, 77]
|
||||
],
|
||||
'attention_mask': [
|
||||
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
|
||||
]
|
||||
}
|
||||
# fmt: on
|
||||
|
||||
actual_tokens = [tokenizer.decode(input_ids) for input_ids in expected_encoding["input_ids"]]
|
||||
expected_tokens = [
|
||||
[tokenizer.convert_ids_to_tokens(id) for id in sequence] for sequence in expected_encoding["input_ids"]
|
||||
]
|
||||
|
||||
self.assertListEqual(actual_encoding["input_ids"], expected_encoding["input_ids"])
|
||||
self.assertListEqual(actual_encoding["attention_mask"], expected_encoding["attention_mask"])
|
||||
self.assertTrue(actual_tokens == expected_tokens)
|
||||
|
||||
@unittest.skip(
|
||||
reason="FastSpeech2Conformer tokenizer does not support adding tokens as they can't be added to the g2p_en backend"
|
||||
)
|
||||
def test_add_tokens_tokenizer(self):
|
||||
pass
|
||||
|
||||
@unittest.skip(
|
||||
reason="FastSpeech2Conformer tokenizer does not support adding tokens as they can't be added to the g2p_en backend"
|
||||
)
|
||||
def test_add_special_tokens(self):
|
||||
pass
|
||||
|
||||
@unittest.skip(
|
||||
reason="FastSpeech2Conformer tokenizer does not support adding tokens as they can't be added to the g2p_en backend"
|
||||
)
|
||||
def test_added_token_serializable(self):
|
||||
pass
|
||||
|
||||
@unittest.skip(
|
||||
reason="FastSpeech2Conformer tokenizer does not support adding tokens as they can't be added to the g2p_en backend"
|
||||
)
|
||||
def test_save_and_load_tokenizer(self):
|
||||
pass
|
||||
|
||||
@unittest.skip(reason="Phonemes cannot be reliably converted to string due to one-many mapping")
|
||||
def test_internal_consistency(self):
|
||||
pass
|
||||
|
||||
@unittest.skip(reason="Phonemes cannot be reliably converted to string due to one-many mapping")
|
||||
def test_encode_decode_with_spaces(self):
|
||||
pass
|
||||
|
||||
@unittest.skip(reason="Phonemes cannot be reliably converted to string due to one-many mapping")
|
||||
def test_convert_tokens_to_string_format(self):
|
||||
pass
|
||||
|
||||
@unittest.skip("FastSpeech2Conformer tokenizer does not support pairs.")
|
||||
def test_maximum_encoding_length_pair_input(self):
|
||||
pass
|
||||
|
||||
@unittest.skip(
|
||||
"FastSpeech2Conformer tokenizer appends eos_token to each string it's passed, including `is_split_into_words=True`."
|
||||
)
|
||||
def test_pretokenized_inputs(self):
|
||||
pass
|
||||
|
||||
@unittest.skip(
|
||||
reason="g2p_en is slow is with large inputs and max encoding length is not a concern for FastSpeech2Conformer"
|
||||
)
|
||||
def test_maximum_encoding_length_single_input(self):
|
||||
pass
|
||||
@ -123,6 +123,7 @@ SPECIAL_CASES_TO_ALLOW.update(
|
||||
"DinatConfig": True,
|
||||
"DonutSwinConfig": True,
|
||||
"EfficientFormerConfig": True,
|
||||
"FastSpeech2ConformerConfig": True,
|
||||
"FSMTConfig": True,
|
||||
"JukeboxConfig": True,
|
||||
"LayoutLMv2Config": True,
|
||||
|
||||
@ -90,6 +90,8 @@ IGNORE_NON_TESTED = PRIVATE_MODELS.copy() + [
|
||||
"UMT5EncoderModel", # Building part of bigger (tested) model.
|
||||
"Blip2QFormerModel", # Building part of bigger (tested) model.
|
||||
"ErnieMForInformationExtraction",
|
||||
"FastSpeech2ConformerHifiGan", # Already tested by SpeechT5HifiGan (# Copied from)
|
||||
"FastSpeech2ConformerWithHifiGan", # Built with two smaller (tested) models.
|
||||
"GraphormerDecoderHead", # Building part of bigger (tested) model.
|
||||
"JukeboxVQVAE", # Building part of bigger (tested) model.
|
||||
"JukeboxPrior", # Building part of bigger (tested) model.
|
||||
@ -159,6 +161,8 @@ IGNORE_NON_AUTO_CONFIGURED = PRIVATE_MODELS.copy() + [
|
||||
"Blip2QFormerModel",
|
||||
"Blip2VisionModel",
|
||||
"ErnieMForInformationExtraction",
|
||||
"FastSpeech2ConformerHifiGan",
|
||||
"FastSpeech2ConformerWithHifiGan",
|
||||
"GitVisionModel",
|
||||
"GraphormerModel",
|
||||
"GraphormerForGraphClassification",
|
||||
|
||||
Loading…
Reference in New Issue
Block a user