Removes images to put them in a dataset (#14781)
* First try * Update instructions
@ -277,7 +277,9 @@ Follow these steps to start contributing:
|
||||
example.
|
||||
7. Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
|
||||
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
|
||||
them by URL.
|
||||
them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
|
||||
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
|
||||
to this dataset.
|
||||
|
||||
See more about the checks run on a pull request in our [PR guide](pr_checks)
|
||||
|
||||
|
||||
@ -16,7 +16,7 @@ limitations under the License.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<img src="https://raw.githubusercontent.com/huggingface/transformers/master/docs/source/imgs/transformers_logo_name.png" width="400"/>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers_logo_name.png" width="400"/>
|
||||
<br>
|
||||
<p>
|
||||
<p align="center">
|
||||
@ -52,7 +52,7 @@ limitations under the License.
|
||||
</h3>
|
||||
|
||||
<h3 align="center">
|
||||
<a href="https://hf.co/course"><img src="https://raw.githubusercontent.com/huggingface/transformers/master/docs/source/imgs/course_banner.png"></a>
|
||||
<a href="https://hf.co/course"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/course_banner.png"></a>
|
||||
</h3>
|
||||
|
||||
🤗 Transformers provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio.
|
||||
|
||||
@ -16,7 +16,7 @@ limitations under the License.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<img src="https://raw.githubusercontent.com/huggingface/transformers/master/docs/source/imgs/transformers_logo_name.png" width="400"/>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers_logo_name.png" width="400"/>
|
||||
<br>
|
||||
<p>
|
||||
<p align="center">
|
||||
@ -52,7 +52,7 @@ limitations under the License.
|
||||
</h3>
|
||||
|
||||
<h3 align="center">
|
||||
<a href="https://hf.co/course"><img src="https://raw.githubusercontent.com/huggingface/transformers/master/docs/source/imgs/course_banner.png"></a>
|
||||
<a href="https://hf.co/course"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/course_banner.png"></a>
|
||||
</h3>
|
||||
|
||||
🤗 Transformers는 분류, 정보 추출, 질문 답변, 요약, 번역, 문장 생성 등을 100개 이상의 언어로 수행할 수 있는 수천개의 사전학습된 모델을 제공합니다. 우리의 목표는 모두가 최첨단의 NLP 기술을 쉽게 사용하는 것입니다.
|
||||
|
||||
@ -41,7 +41,7 @@ checkpoint: 检查点
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<img src="https://raw.githubusercontent.com/huggingface/transformers/master/docs/source/imgs/transformers_logo_name.png" width="400"/>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers_logo_name.png" width="400"/>
|
||||
<br>
|
||||
<p>
|
||||
<p align="center">
|
||||
@ -77,7 +77,7 @@ checkpoint: 检查点
|
||||
</h3>
|
||||
|
||||
<h3 align="center">
|
||||
<a href="https://hf.co/course"><img src="https://raw.githubusercontent.com/huggingface/transformers/master/docs/source/imgs/course_banner.png"></a>
|
||||
<a href="https://hf.co/course"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/course_banner.png"></a>
|
||||
</h3>
|
||||
|
||||
🤗 Transformers 提供了数以千计的预训练模型,支持 100 多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成。它的宗旨让最先进的 NLP 技术人人易用。
|
||||
|
||||
@ -53,7 +53,7 @@ user: 使用者
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<img src="https://raw.githubusercontent.com/huggingface/transformers/master/docs/source/imgs/transformers_logo_name.png" width="400"/>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers_logo_name.png" width="400"/>
|
||||
<br>
|
||||
<p>
|
||||
<p align="center">
|
||||
@ -89,7 +89,7 @@ user: 使用者
|
||||
</h3>
|
||||
|
||||
<h3 align="center">
|
||||
<a href="https://hf.co/course"><img src="https://raw.githubusercontent.com/huggingface/transformers/master/docs/source/imgs/course_banner.png"></a>
|
||||
<a href="https://hf.co/course"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/course_banner.png"></a>
|
||||
</h3>
|
||||
|
||||
🤗 Transformers 提供了數以千計的預訓練模型,支援 100 多種語言的文本分類、資訊擷取、問答、摘要、翻譯、文本生成。它的宗旨是讓最先進的 NLP 技術人人易用。
|
||||
|
||||
@ -324,3 +324,11 @@ So using this particular example's output -- if your current section's header us
|
||||
If you needed to add yet another sub-level, then pick a character that is not used already. That is you must pick a character that is not in the output of that script.
|
||||
|
||||
Here is the full list of characters that can be used in this context: `= - ` : ' " ~ ^ _ * + # < >`
|
||||
|
||||
#### Adding an image
|
||||
|
||||
Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
|
||||
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
|
||||
them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
|
||||
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
|
||||
to this dataset.
|
||||
|
||||
@ -72,7 +72,7 @@ call the model to be added to 🤗 Transformers ``BrandNewBert``.
|
||||
|
||||
Let's take a look:
|
||||
|
||||
.. image:: /imgs/transformers_overview.png
|
||||
.. image:: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers_overview.png
|
||||
|
||||
As you can see, we do make use of inheritance in 🤗 Transformers, but we keep the level of abstraction to an absolute
|
||||
minimum. There are never more than two levels of abstraction for any model in the library. :obj:`BrandNewBertModel`
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 78 KiB |
{kind=link}
|
Before Width: | Height: | Size: 27 KiB |
{kind=link}
|
Before Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 342 KiB |
{kind=link}
|
Before Width: | Height: | Size: 47 KiB |
{kind=link}
|
Before Width: | Height: | Size: 20 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 126 KiB |
{kind=link}
|
Before Width: | Height: | Size: 162 KiB |
{kind=link}
|
Before Width: | Height: | Size: 99 KiB |
{kind=link}
|
Before Width: | Height: | Size: 54 KiB |
{kind=link}
|
Before Width: | Height: | Size: 159 KiB |
{kind=link}
|
Before Width: | Height: | Size: 71 KiB |
{kind=link}
|
Before Width: | Height: | Size: 352 KiB |
{kind=link}
|
Before Width: | Height: | Size: 418 KiB |
{kind=link}
|
Before Width: | Height: | Size: 373 KiB |
{kind=link}
|
Before Width: | Height: | Size: 32 KiB |
{kind=link}
|
Before Width: | Height: | Size: 8.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 691 KiB |
{kind=link}
|
Before Width: | Height: | Size: 9.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 17 KiB |
{kind=link}
|
Before Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
@ -52,30 +52,30 @@ Learning Rate Schedules (Pytorch)
|
||||
|
||||
.. autofunction:: transformers.get_constant_schedule_with_warmup
|
||||
|
||||
.. image:: /imgs/warmup_constant_schedule.png
|
||||
:target: /imgs/warmup_constant_schedule.png
|
||||
.. image:: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_constant_schedule.png
|
||||
:target: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_constant_schedule.png
|
||||
:alt:
|
||||
|
||||
|
||||
.. autofunction:: transformers.get_cosine_schedule_with_warmup
|
||||
|
||||
.. image:: /imgs/warmup_cosine_schedule.png
|
||||
:target: /imgs/warmup_cosine_schedule.png
|
||||
.. image:: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_schedule.png
|
||||
:target: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_schedule.png
|
||||
:alt:
|
||||
|
||||
|
||||
.. autofunction:: transformers.get_cosine_with_hard_restarts_schedule_with_warmup
|
||||
|
||||
.. image:: /imgs/warmup_cosine_hard_restarts_schedule.png
|
||||
:target: /imgs/warmup_cosine_hard_restarts_schedule.png
|
||||
.. image:: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_hard_restarts_schedule.png
|
||||
:target: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_hard_restarts_schedule.png
|
||||
:alt:
|
||||
|
||||
|
||||
|
||||
.. autofunction:: transformers.get_linear_schedule_with_warmup
|
||||
|
||||
.. image:: /imgs/warmup_linear_schedule.png
|
||||
:target: /imgs/warmup_linear_schedule.png
|
||||
.. image:: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_linear_schedule.png
|
||||
:target: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_linear_schedule.png
|
||||
:alt:
|
||||
|
||||
|
||||
|
||||
@ -877,7 +877,7 @@ Some preselected input tokens are also given global attention: for those few tok
|
||||
all tokens and this process is symmetric: all other tokens have access to those specific tokens (on top of the ones in
|
||||
their local window). This is shown in Figure 2d of the paper, see below for a sample attention mask:
|
||||
|
||||
.. image:: /imgs/local_attention_mask.png
|
||||
.. image:: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/local_attention_mask.png
|
||||
:scale: 50 %
|
||||
:align: center
|
||||
|
||||
|
||||
@ -46,7 +46,7 @@ Most users with just 2 GPUs already enjoy the increased training speed up thanks
|
||||
## ZeRO Data Parallel
|
||||
|
||||
ZeRO-powered data parallelism (ZeRO-DP) is described on the following diagram from this [blog post](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/)
|
||||

|
||||

|
||||
|
||||
It can be difficult to wrap one's head around it, but in reality the concept is quite simple. This is just the usual DataParallel (DP), except, instead of replicating the full model params, gradients and optimizer states, each GPU stores only a slice of it. And then at run-time when the full layer params are needed just for the given layer, all GPUs synchronize to give each other parts that they miss - this is it.
|
||||
|
||||
@ -150,7 +150,7 @@ Pipeline Parallel (PP) is almost identical to a naive MP, but it solves the GPU
|
||||
|
||||
The following illustration from the [GPipe paper](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html) shows the naive MP on the top, and PP on the bottom:
|
||||
|
||||

|
||||

|
||||
|
||||
It's easy to see from the bottom diagram how PP has less dead zones, where GPUs are idle. The idle parts are referred to as the "bubble".
|
||||
|
||||
@ -203,7 +203,7 @@ Implementations:
|
||||
Other approaches:
|
||||
|
||||
DeepSpeed, Varuna and SageMaker use the concept of an [Interleaved Pipeline](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html)
|
||||

|
||||

|
||||
|
||||
Here the bubble (idle time) is further minimized by prioritizing backward passes.
|
||||
|
||||
@ -221,16 +221,16 @@ The main building block of any transformer is a fully connected `nn.Linear` foll
|
||||
Following the Megatron's paper notation, we can write the dot-product part of it as `Y = GeLU(XA)`, where `X` and `Y` are the input and output vectors, and `A` is the weight matrix.
|
||||
|
||||
If we look at the computation in matrix form, it's easy to see how the matrix multiplication can be split between multiple GPUs:
|
||||

|
||||

|
||||
|
||||
If we split the weight matrix `A` column-wise across `N` GPUs and perform matrix multiplications `XA_1` through `XA_n` in parallel, then we will end up with `N` output vectors `Y_1, Y_2, ..., Y_n` which can be fed into `GeLU` independently:
|
||||

|
||||

|
||||
|
||||
Using this principle, we can update an MLP of arbitrary depth, without the need for any synchronization between GPUs until the very end, where we need to reconstruct the output vector from shards. The Megatron-LM paper authors provide a helpful illustration for that:
|
||||

|
||||

|
||||
|
||||
Parallelizing the multi-headed attention layers is even simpler, since they are already inherently parallel, due to having multiple independent heads!
|
||||

|
||||

|
||||
|
||||
Special considerations: TP requires very fast network, and therefore it's not advisable to do TP across more than one node. Practically, if a node has 4 GPUs, the highest TP degree is therefore 4. If you need a TP degree of 8, you need to use nodes that have at least 8 GPUs.
|
||||
|
||||
@ -258,7 +258,7 @@ Implementations:
|
||||
|
||||
The following diagram from the DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/) demonstrates how one combines DP with PP.
|
||||
|
||||

|
||||

|
||||
|
||||
Here it's important to see how DP rank 0 doesn't see GPU2 and DP rank 1 doesn't see GPU3. To DP there is just GPUs 0 and 1 where it feeds data as if there were just 2 GPUs. GPU0 "secretly" offloads some of its load to GPU2 using PP. And GPU1 does the same by enlisting GPU3 to its aid.
|
||||
|
||||
@ -277,7 +277,7 @@ Implementations:
|
||||
|
||||
To get an even more efficient training a 3D parallelism is used where PP is combined with TP and DP. This can be seen in the following diagram.
|
||||
|
||||

|
||||

|
||||
|
||||
This diagram is from a blog post [3D parallelism: Scaling to trillion-parameter models](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/), which is a good read as well.
|
||||
|
||||
@ -342,7 +342,7 @@ We have 10 batches of 512 length. If we parallelize them by attribute dimension
|
||||
|
||||
It is similar with tensor model parallelism or naive layer-wise model parallelism.
|
||||
|
||||

|
||||

|
||||
|
||||
The significance of this framework is that it takes resources like (1) GPU/TPU/CPU vs. (2) RAM/DRAM vs. (3) fast-intra-connect/slow-inter-connect and it automatically optimizes all these algorithmically deciding which parallelisation to use where.
|
||||
|
||||
|
||||
@ -248,7 +248,7 @@ Here are the commonly used floating point data types choice of which impacts bot
|
||||
|
||||
Here is a diagram that shows how these data types correlate to each other.
|
||||
|
||||

|
||||
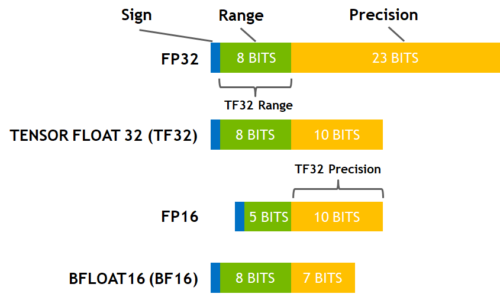
|
||||
|
||||
(source: [NVIDIA Blog](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/))
|
||||
|
||||
@ -524,7 +524,7 @@ Since it has been discovered that more parameters lead to better performance, th
|
||||
|
||||
In this approach every other FFN layer is replaced with a MoE Layer which consists of many experts, with a gated function that trains each expert in a balanced way depending on the input token's position in a sequence.
|
||||
|
||||

|
||||

|
||||
|
||||
(source: [GLAM](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html))
|
||||
|
||||
|
||||
@ -34,7 +34,7 @@ intuition about perplexity and its relationship to Bits Per Character (BPC) and
|
||||
If we weren't limited by a model's context size, we would evaluate the model's perplexity by autoregressively
|
||||
factorizing a sequence and conditioning on the entire preceding subsequence at each step, as shown below.
|
||||
|
||||
<img width="600" alt="Full decomposition of a sequence with unlimited context length" src="/imgs/ppl_full.gif"/>
|
||||
<img width="600" alt="Full decomposition of a sequence with unlimited context length" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/ppl_full.gif"/>
|
||||
|
||||
When working with approximate models, however, we typically have a constraint on the number of tokens the model can
|
||||
process. The largest version of [GPT-2](model_doc/gpt2), for example, has a fixed length of 1024 tokens, so we
|
||||
@ -46,7 +46,7 @@ input size is \\(k\\), we then approximate the likelihood of a token \\(x_t\\) b
|
||||
sequence, a tempting but suboptimal approach is to break the sequence into disjoint chunks and add up the decomposed
|
||||
log-likelihoods of each segment independently.
|
||||
|
||||
<img width="600" alt="Suboptimal PPL not taking advantage of full available context" src="/imgs/ppl_chunked.gif"/>
|
||||
<img width="600" alt="Suboptimal PPL not taking advantage of full available context" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/ppl_chunked.gif"/>
|
||||
|
||||
This is quick to compute since the perplexity of each segment can be computed in one forward pass, but serves as a poor
|
||||
approximation of the fully-factorized perplexity and will typically yield a higher (worse) PPL because the model will
|
||||
@ -55,7 +55,7 @@ have less context at most of the prediction steps.
|
||||
Instead, the PPL of fixed-length models should be evaluated with a sliding-window strategy. This involves repeatedly
|
||||
sliding the context window so that the model has more context when making each prediction.
|
||||
|
||||
<img width="600" alt="Sliding window PPL taking advantage of all available context" src="/imgs/ppl_sliding.gif"/>
|
||||
<img width="600" alt="Sliding window PPL taking advantage of all available context" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/ppl_sliding.gif"/>
|
||||
|
||||
This is a closer approximation to the true decomposition of the sequence probability and will typically yield a more
|
||||
favorable score. The downside is that it requires a separate forward pass for each token in the corpus. A good
|
||||
|
||||
@ -91,7 +91,7 @@ exemplary purposes, we will call the PyTorch model to be added to 🤗 Transform
|
||||
|
||||
Let's take a look:
|
||||
|
||||

|
||||
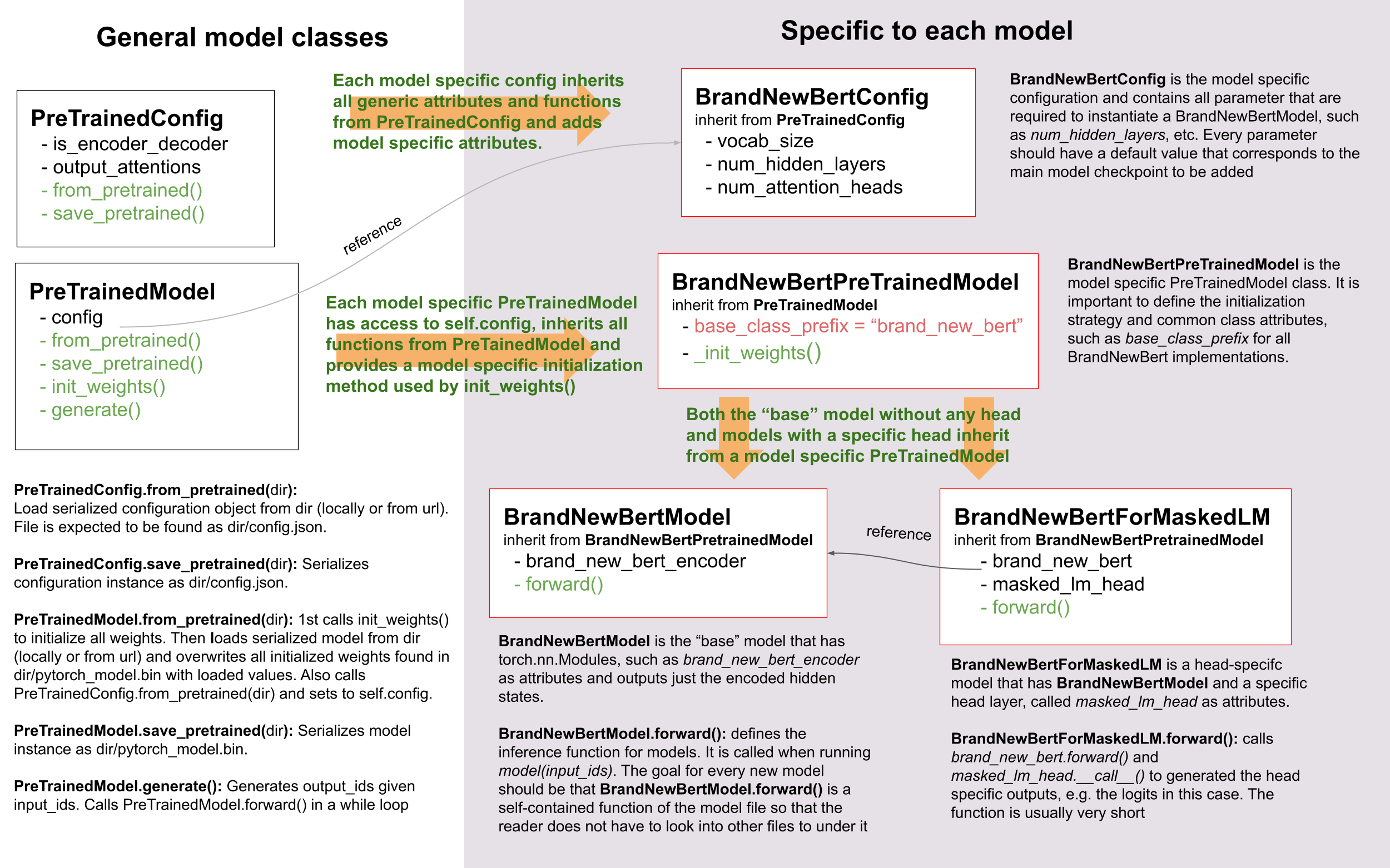
|
||||
|
||||
As you can see, we do make use of inheritance in 🤗 Transformers, but we
|
||||
keep the level of abstraction to an absolute minimum. There are never
|
||||
|
||||
@ -73,7 +73,7 @@ exemplary purposes, we will call the PyTorch model to be added to 🤗 Transform
|
||||
|
||||
Let's take a look:
|
||||
|
||||

|
||||

|
||||
|
||||
As you can see, we do make use of inheritance in 🤗 Transformers, but we
|
||||
keep the level of abstraction to an absolute minimum. There are never
|
||||
|
||||