mirror of
https://github.com/huggingface/transformers.git
synced 2025-07-31 10:12:23 +06:00
Add semantic script no trainer, v2 (#16788)
* Add first draft from previous PR * First draft * Improve README and remove num_labels * Make script more aligned with other scripts * Improve README and apply suggestion from code review
This commit is contained in:
parent
494c2a8c4d
commit
7db7aab439
147
examples/pytorch/semantic-segmentation/README.md
Normal file
147
examples/pytorch/semantic-segmentation/README.md
Normal file
@ -0,0 +1,147 @@
|
||||
<!---
|
||||
Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
|
||||
# Semantic segmentation example
|
||||
|
||||
This directory contains a script, `run_semantic_segmentation_no_trainer.py`, that showcases how to fine-tune any model supported by the [`AutoModelForSemanticSegmentation` API](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForSemanticSegmentation) (such as [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer), [BEiT](https://huggingface.co/docs/transformers/main/en/model_doc/beit), [DPT]((https://huggingface.co/docs/transformers/main/en/model_doc/dpt))) for semantic segmentation using PyTorch.
|
||||
|
||||
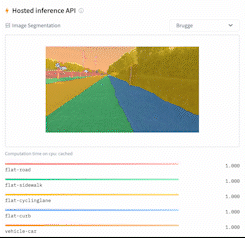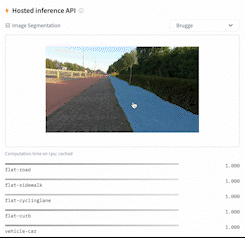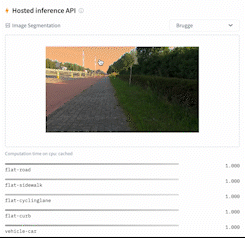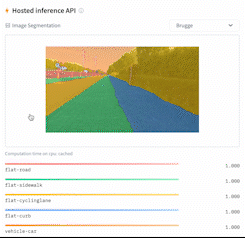
|
||||
|
||||
The script leverages [🤗 `Accelerate`](https://github.com/huggingface/accelerate), which allows to write your own training loop in PyTorch, but have it run instantly on any (distributed) environment, including CPU, multi-CPU, GPU, multi-GPU and TPU. It also supports mixed precision.
|
||||
|
||||
## Note on custom data
|
||||
|
||||
In case you'd like to use the script with custom data, there are 2 things required: 1) creating a DatasetDict 2) creating an id2label mapping. Below, these are explained in more detail.
|
||||
|
||||
### Creating a `DatasetDict`
|
||||
|
||||
The script assumes that you have a `DatasetDict` with 2 columns, "image" and "label", both of type [Image](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Image). This can be created as follows:
|
||||
|
||||
```python
|
||||
from datasets import Dataset, DatasetDict, Image
|
||||
|
||||
image_paths_train = ["path/to/image_1.jpg/png", "path/to/image_2.jpg/png", ..., "path/to/image_n.jpg/png"]
|
||||
label_paths_train = ["path/to/annotation_1.png", "path/to/annotation_2.png", ..., "path/to/annotation_n.png"]
|
||||
|
||||
# same for validation
|
||||
# image_paths_validation = [...]
|
||||
# label_paths_validation = [...]
|
||||
|
||||
def create_dataset(image_paths, label_paths):
|
||||
dataset = Dataset.from_dict({"image": sorted(image_paths),
|
||||
"label": sorted(label_paths)})
|
||||
dataset = dataset.cast_column("image", Image())
|
||||
dataset = dataset.cast_column("label", Image())
|
||||
|
||||
return dataset
|
||||
|
||||
# step 1: create Dataset objects
|
||||
train_dataset = create_dataset(image_paths_train, label_paths_train)
|
||||
validation_dataset = create_dataset(image_paths_validation, label_paths_validation)
|
||||
|
||||
# step 2: create DatasetDict
|
||||
dataset = DatasetDict({
|
||||
"train": train_dataset,
|
||||
"validation": val_dataset,
|
||||
}
|
||||
)
|
||||
|
||||
# step 3: push to hub (assumes you have ran the huggingface-cli login command in a terminal/notebook)
|
||||
dataset.push_to_hub("name of repo on the hub")
|
||||
|
||||
# optionally, you can push to a private repo on the hub
|
||||
# dataset.push_to_hub("name of repo on the hub")
|
||||
```
|
||||
|
||||
An example of such a dataset can be seen at [nielsr/ade20k-demo](https://huggingface.co/datasets/nielsr/ade20k-demo).
|
||||
|
||||
### Creating an id2label mapping
|
||||
|
||||
Besides that, the script also assumes the existence of an `id2label.json` file in the repo, containing a mapping from integers to actual class names.
|
||||
An example of that can be seen [here](https://huggingface.co/datasets/nielsr/ade20k-demo/blob/main/id2label.json). You can easily upload this by clicking on "Add file" in the "Files and versions" tab of your repo on the hub.
|
||||
|
||||
## Running the script
|
||||
|
||||
First, run:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
and reply to the questions asked regarding the environment on which you'd like to train. Then
|
||||
|
||||
```bash
|
||||
accelerate test
|
||||
```
|
||||
|
||||
that will check everything is ready for training. Finally, you can launch training with
|
||||
|
||||
```bash
|
||||
accelerate launch --output_dir segformer-finetuned-sidewalk --with_tracking --push_to_hub
|
||||
```
|
||||
|
||||
and boom, you're training, possibly on multiple GPUs, logging everything to all trackers found in your environment (like Weights and Biases, Tensorboard) and regularly pushing your model to the hub (with the repo name being equal to `args.output_dir` at your HF username) 🤗
|
||||
|
||||
With the default settings, the script fine-tunes a [SegFormer]((https://huggingface.co/docs/transformers/main/en/model_doc/segformer)) model on the [segments/sidewalk-semantic](segments/sidewalk-semantic) dataset.
|
||||
|
||||
The resulting model can be seen here: https://huggingface.co/nielsr/segformer-finetuned-sidewalk.
|
||||
|
||||
## Reload and perform inference
|
||||
|
||||
This means that after training, you can easily load your trained model as follows:
|
||||
|
||||
```python
|
||||
from transformers import AutoFeatureExtractor, AutoModelForSemanticSegmentation
|
||||
|
||||
model_name = "name_of_repo_on_the_hub_or_path_to_local_folder"
|
||||
|
||||
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name)
|
||||
model = AutoModelForSemanticSegmentation.from_pretrained(model_name)
|
||||
```
|
||||
|
||||
and perform inference as follows:
|
||||
|
||||
```python
|
||||
from PIL import Image
|
||||
import requests
|
||||
import torch
|
||||
|
||||
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
||||
image = Image.open(requests.get(url, stream=True).raw)
|
||||
|
||||
# prepare image for the model
|
||||
inputs = feature_extractor(images=image, return_tensors="pt")
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model(**inputs)
|
||||
logits = outputs.logits
|
||||
|
||||
# rescale logits to original image size
|
||||
logits = nn.functional.interpolate(outputs.logits.detach().cpu(),
|
||||
size=image.size[::-1], # (height, width)
|
||||
mode='bilinear',
|
||||
align_corners=False)
|
||||
|
||||
predicted = logits.argmax(1)
|
||||
```
|
||||
|
||||
For visualization of the segmentation maps, we refer to the [example notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SegFormer/Segformer_inference_notebook.ipynb).
|
||||
|
||||
## Important notes
|
||||
|
||||
Some datasets, like [`scene_parse_150`](scene_parse_150), contain a "background" label that is not part of the classes. The Scene Parse 150 dataset for instance contains labels between 0 and 150, with 0 being the background class, and 1 to 150 being actual class names (like "tree", "person", etc.). For these kind of datasets, one replaces the background label (0) by 255, which is the `ignore_index` of the PyTorch model's loss function, and reduces all labels by 1. This way, the `labels` are PyTorch tensors containing values between 0 and 149, and 255 for all background/padding.
|
||||
|
||||
In case you're training on such a dataset, make sure to set the ``reduce_labels`` flag, which will take care of this.
|
||||
3
examples/pytorch/semantic-segmentation/requirements.txt
Normal file
3
examples/pytorch/semantic-segmentation/requirements.txt
Normal file
@ -0,0 +1,3 @@
|
||||
git://github.com/huggingface/accelerate.git
|
||||
datasets >= 2.0.0
|
||||
torch >= 1.3
|
||||
@ -0,0 +1,632 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Finetuning any 🤗 Transformers model supported by AutoModelForSemanticSegmentation for semantic segmentation."""
|
||||
|
||||
import argparse
|
||||
import json
|
||||
import logging
|
||||
import math
|
||||
import os
|
||||
import random
|
||||
from pathlib import Path
|
||||
|
||||
import datasets
|
||||
import numpy as np
|
||||
import torch
|
||||
from datasets import load_dataset, load_metric
|
||||
from PIL import Image
|
||||
from torch.utils.data import DataLoader
|
||||
from torchvision import transforms
|
||||
from torchvision.transforms import functional
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
import transformers
|
||||
from accelerate import Accelerator
|
||||
from accelerate.utils import set_seed
|
||||
from huggingface_hub import Repository, hf_hub_download
|
||||
from transformers import (
|
||||
AutoConfig,
|
||||
AutoFeatureExtractor,
|
||||
AutoModelForSemanticSegmentation,
|
||||
SchedulerType,
|
||||
default_data_collator,
|
||||
get_scheduler,
|
||||
)
|
||||
from transformers.utils import get_full_repo_name
|
||||
from transformers.utils.versions import require_version
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
require_version("datasets>=2.0.0", "To fix: pip install -r examples/pytorch/semantic-segmentation/requirements.txt")
|
||||
|
||||
|
||||
def pad_if_smaller(img, size, fill=0):
|
||||
min_size = min(img.size)
|
||||
if min_size < size:
|
||||
ow, oh = img.size
|
||||
padh = size - oh if oh < size else 0
|
||||
padw = size - ow if ow < size else 0
|
||||
img = functional.pad(img, (0, 0, padw, padh), fill=fill)
|
||||
return img
|
||||
|
||||
|
||||
class Compose:
|
||||
def __init__(self, transforms):
|
||||
self.transforms = transforms
|
||||
|
||||
def __call__(self, image, target):
|
||||
for t in self.transforms:
|
||||
image, target = t(image, target)
|
||||
return image, target
|
||||
|
||||
|
||||
class Identity:
|
||||
def __init__(self):
|
||||
pass
|
||||
|
||||
def __call__(self, image, target):
|
||||
return image, target
|
||||
|
||||
|
||||
class Resize:
|
||||
def __init__(self, size):
|
||||
self.size = size
|
||||
|
||||
def __call__(self, image, target):
|
||||
image = functional.resize(image, self.size)
|
||||
target = functional.resize(target, self.size, interpolation=transforms.InterpolationMode.NEAREST)
|
||||
return image, target
|
||||
|
||||
|
||||
class RandomResize:
|
||||
def __init__(self, min_size, max_size=None):
|
||||
self.min_size = min_size
|
||||
if max_size is None:
|
||||
max_size = min_size
|
||||
self.max_size = max_size
|
||||
|
||||
def __call__(self, image, target):
|
||||
size = random.randint(self.min_size, self.max_size)
|
||||
image = functional.resize(image, size)
|
||||
target = functional.resize(target, size, interpolation=transforms.InterpolationMode.NEAREST)
|
||||
return image, target
|
||||
|
||||
|
||||
class RandomCrop:
|
||||
def __init__(self, size):
|
||||
self.size = size
|
||||
|
||||
def __call__(self, image, target):
|
||||
image = pad_if_smaller(image, self.size)
|
||||
target = pad_if_smaller(target, self.size, fill=255)
|
||||
crop_params = transforms.RandomCrop.get_params(image, (self.size, self.size))
|
||||
image = functional.crop(image, *crop_params)
|
||||
target = functional.crop(target, *crop_params)
|
||||
return image, target
|
||||
|
||||
|
||||
class RandomHorizontalFlip:
|
||||
def __init__(self, flip_prob):
|
||||
self.flip_prob = flip_prob
|
||||
|
||||
def __call__(self, image, target):
|
||||
if random.random() < self.flip_prob:
|
||||
image = functional.hflip(image)
|
||||
target = functional.hflip(target)
|
||||
return image, target
|
||||
|
||||
|
||||
class PILToTensor:
|
||||
def __call__(self, image, target):
|
||||
image = functional.pil_to_tensor(image)
|
||||
target = torch.as_tensor(np.array(target), dtype=torch.int64)
|
||||
return image, target
|
||||
|
||||
|
||||
class ConvertImageDtype:
|
||||
def __init__(self, dtype):
|
||||
self.dtype = dtype
|
||||
|
||||
def __call__(self, image, target):
|
||||
image = functional.convert_image_dtype(image, self.dtype)
|
||||
return image, target
|
||||
|
||||
|
||||
class Normalize:
|
||||
def __init__(self, mean, std):
|
||||
self.mean = mean
|
||||
self.std = std
|
||||
|
||||
def __call__(self, image, target):
|
||||
image = functional.normalize(image, mean=self.mean, std=self.std)
|
||||
return image, target
|
||||
|
||||
|
||||
class ReduceLabels:
|
||||
def __call__(self, image, target):
|
||||
if not isinstance(target, np.ndarray):
|
||||
target = np.array(target).astype(np.uint8)
|
||||
# avoid using underflow conversion
|
||||
target[target == 0] = 255
|
||||
target = target - 1
|
||||
target[target == 254] = 255
|
||||
|
||||
target = Image.fromarray(target)
|
||||
return image, target
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(description="Finetune a transformers model on a text classification task")
|
||||
parser.add_argument(
|
||||
"--model_name_or_path",
|
||||
type=str,
|
||||
help="Path to a pretrained model or model identifier from huggingface.co/models.",
|
||||
default="nvidia/mit-b0",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--dataset_name",
|
||||
type=str,
|
||||
help="Name of the dataset on the hub.",
|
||||
default="segments/sidewalk-semantic",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--reduce_labels",
|
||||
action="store_true",
|
||||
help="Whether or not to reduce all labels by 1 and replace background by 255.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--train_val_split",
|
||||
type=float,
|
||||
default=0.15,
|
||||
help="Fraction of the dataset to be used for validation.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--cache_dir",
|
||||
type=str,
|
||||
help="Path to a folder in which the model and dataset will be cached.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_auth_token",
|
||||
action="store_true",
|
||||
help="Whether to use an authentication token to access the model repository.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--per_device_train_batch_size",
|
||||
type=int,
|
||||
default=8,
|
||||
help="Batch size (per device) for the training dataloader.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--per_device_eval_batch_size",
|
||||
type=int,
|
||||
default=8,
|
||||
help="Batch size (per device) for the evaluation dataloader.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--learning_rate",
|
||||
type=float,
|
||||
default=5e-5,
|
||||
help="Initial learning rate (after the potential warmup period) to use.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--adam_beta1",
|
||||
type=float,
|
||||
default=0.9,
|
||||
help="Beta1 for AdamW optimizer",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--adam_beta2",
|
||||
type=float,
|
||||
default=0.999,
|
||||
help="Beta2 for AdamW optimizer",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--adam_epsilon",
|
||||
type=float,
|
||||
default=1e-8,
|
||||
help="Epsilon for AdamW optimizer",
|
||||
)
|
||||
parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
|
||||
parser.add_argument(
|
||||
"--max_train_steps",
|
||||
type=int,
|
||||
default=None,
|
||||
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--gradient_accumulation_steps",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of updates steps to accumulate before performing a backward/update pass.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--lr_scheduler_type",
|
||||
type=SchedulerType,
|
||||
default="polynomial",
|
||||
help="The scheduler type to use.",
|
||||
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
|
||||
)
|
||||
parser.add_argument(
|
||||
"--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
|
||||
)
|
||||
parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
|
||||
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
|
||||
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
|
||||
parser.add_argument(
|
||||
"--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
|
||||
)
|
||||
parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
|
||||
parser.add_argument(
|
||||
"--checkpointing_steps",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--resume_from_checkpoint",
|
||||
type=str,
|
||||
default=None,
|
||||
help="If the training should continue from a checkpoint folder.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--with_tracking",
|
||||
required=False,
|
||||
action="store_true",
|
||||
help="Whether to load in all available experiment trackers from the environment and use them for logging.",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
# Sanity checks
|
||||
if args.push_to_hub or args.with_tracking:
|
||||
if args.output_dir is None:
|
||||
raise ValueError(
|
||||
"Need an `output_dir` to create a repo when `--push_to_hub` or `with_tracking` is specified."
|
||||
)
|
||||
|
||||
if args.output_dir is not None:
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
|
||||
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
|
||||
# If we're using tracking, we also need to initialize it here and it will pick up all supported trackers in the environment
|
||||
accelerator = Accelerator(log_with="all", logging_dir=args.output_dir) if args.with_tracking else Accelerator()
|
||||
logger.info(accelerator.state)
|
||||
|
||||
# Setup logging, we only want one process per machine to log things on the screen.
|
||||
# accelerator.is_local_main_process is only True for one process per machine.
|
||||
logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
|
||||
if accelerator.is_local_main_process:
|
||||
datasets.utils.logging.set_verbosity_warning()
|
||||
transformers.utils.logging.set_verbosity_info()
|
||||
else:
|
||||
datasets.utils.logging.set_verbosity_error()
|
||||
transformers.utils.logging.set_verbosity_error()
|
||||
|
||||
# If passed along, set the training seed now.
|
||||
# We set device_specific to True as we want different data augmentation per device.
|
||||
if args.seed is not None:
|
||||
set_seed(args.seed, device_specific=True)
|
||||
|
||||
# Handle the repository creation
|
||||
if accelerator.is_main_process:
|
||||
if args.push_to_hub:
|
||||
if args.hub_model_id is None:
|
||||
repo_name = get_full_repo_name(Path(args.output_dir).name, token=args.hub_token)
|
||||
else:
|
||||
repo_name = args.hub_model_id
|
||||
repo = Repository(args.output_dir, clone_from=repo_name)
|
||||
|
||||
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
|
||||
if "step_*" not in gitignore:
|
||||
gitignore.write("step_*\n")
|
||||
if "epoch_*" not in gitignore:
|
||||
gitignore.write("epoch_*\n")
|
||||
elif args.output_dir is not None:
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# Load dataset
|
||||
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
|
||||
# download the dataset.
|
||||
# TODO support datasets from local folders
|
||||
dataset = load_dataset(args.dataset_name, cache_dir=args.cache_dir)
|
||||
|
||||
# Rename column names to standardized names (only "image" and "label" need to be present)
|
||||
if "pixel_values" in dataset["train"].column_names:
|
||||
dataset = dataset.rename_columns({"pixel_values": "image"})
|
||||
if "annotation" in dataset["train"].column_names:
|
||||
dataset = dataset.rename_columns({"annotation": "label"})
|
||||
|
||||
# If we don't have a validation split, split off a percentage of train as validation.
|
||||
args.train_val_split = None if "validation" in dataset.keys() else args.train_val_split
|
||||
if isinstance(args.train_val_split, float) and args.train_val_split > 0.0:
|
||||
split = dataset["train"].train_test_split(args.train_val_split)
|
||||
dataset["train"] = split["train"]
|
||||
dataset["validation"] = split["test"]
|
||||
|
||||
# Prepare label mappings.
|
||||
# We'll include these in the model's config to get human readable labels in the Inference API.
|
||||
if args.dataset_name == "scene_parse_150":
|
||||
repo_id = "datasets/huggingface/label-files"
|
||||
filename = "ade20k-id2label.json"
|
||||
else:
|
||||
repo_id = f"datasets/{args.dataset_name}"
|
||||
filename = "id2label.json"
|
||||
id2label = json.load(open(hf_hub_download(repo_id, filename), "r"))
|
||||
id2label = {int(k): v for k, v in id2label.items()}
|
||||
label2id = {v: k for k, v in id2label.items()}
|
||||
|
||||
# Load pretrained model and feature extractor
|
||||
config = AutoConfig.from_pretrained(args.model_name_or_path, id2label=id2label, label2id=label2id)
|
||||
feature_extractor = AutoFeatureExtractor.from_pretrained(args.model_name_or_path)
|
||||
model = AutoModelForSemanticSegmentation.from_pretrained(args.model_name_or_path, config=config)
|
||||
|
||||
# Preprocessing the datasets
|
||||
# Define torchvision transforms to be applied to each image + target.
|
||||
# Not that straightforward in torchvision: https://github.com/pytorch/vision/issues/9
|
||||
# Currently based on official torchvision references: https://github.com/pytorch/vision/blob/main/references/segmentation/transforms.py
|
||||
train_transforms = Compose(
|
||||
[
|
||||
ReduceLabels() if args.reduce_labels else Identity(),
|
||||
RandomCrop(size=feature_extractor.size),
|
||||
RandomHorizontalFlip(flip_prob=0.5),
|
||||
PILToTensor(),
|
||||
ConvertImageDtype(torch.float),
|
||||
Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std),
|
||||
]
|
||||
)
|
||||
# Define torchvision transform to be applied to each image.
|
||||
# jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
|
||||
val_transforms = Compose(
|
||||
[
|
||||
ReduceLabels() if args.reduce_labels else Identity(),
|
||||
Resize(size=(feature_extractor.size, feature_extractor.size)),
|
||||
PILToTensor(),
|
||||
ConvertImageDtype(torch.float),
|
||||
Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std),
|
||||
]
|
||||
)
|
||||
|
||||
def preprocess_train(example_batch):
|
||||
pixel_values = []
|
||||
labels = []
|
||||
for image, target in zip(example_batch["image"], example_batch["label"]):
|
||||
image, target = train_transforms(image.convert("RGB"), target)
|
||||
pixel_values.append(image)
|
||||
labels.append(target)
|
||||
|
||||
encoding = dict()
|
||||
encoding["pixel_values"] = torch.stack(pixel_values)
|
||||
encoding["labels"] = torch.stack(labels)
|
||||
|
||||
return encoding
|
||||
|
||||
def preprocess_val(example_batch):
|
||||
pixel_values = []
|
||||
labels = []
|
||||
for image, target in zip(example_batch["image"], example_batch["label"]):
|
||||
image, target = val_transforms(image.convert("RGB"), target)
|
||||
pixel_values.append(image)
|
||||
labels.append(target)
|
||||
|
||||
encoding = dict()
|
||||
encoding["pixel_values"] = torch.stack(pixel_values)
|
||||
encoding["labels"] = torch.stack(labels)
|
||||
|
||||
return encoding
|
||||
|
||||
with accelerator.main_process_first():
|
||||
train_dataset = dataset["train"].with_transform(preprocess_train)
|
||||
eval_dataset = dataset["validation"].with_transform(preprocess_val)
|
||||
|
||||
train_dataloader = DataLoader(
|
||||
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=args.per_device_train_batch_size
|
||||
)
|
||||
eval_dataloader = DataLoader(
|
||||
eval_dataset, collate_fn=default_data_collator, batch_size=args.per_device_eval_batch_size
|
||||
)
|
||||
|
||||
# Optimizer
|
||||
optimizer = torch.optim.AdamW(
|
||||
list(model.parameters()),
|
||||
lr=args.learning_rate,
|
||||
betas=[args.adam_beta1, args.adam_beta2],
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
|
||||
# Figure out how many steps we should save the Accelerator states
|
||||
if hasattr(args.checkpointing_steps, "isdigit"):
|
||||
checkpointing_steps = args.checkpointing_steps
|
||||
if args.checkpointing_steps.isdigit():
|
||||
checkpointing_steps = int(args.checkpointing_steps)
|
||||
else:
|
||||
checkpointing_steps = None
|
||||
|
||||
# Scheduler and math around the number of training steps.
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
if args.max_train_steps is None:
|
||||
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
|
||||
else:
|
||||
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
||||
|
||||
lr_scheduler = get_scheduler(
|
||||
name=args.lr_scheduler_type,
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=args.num_warmup_steps,
|
||||
num_training_steps=args.max_train_steps,
|
||||
)
|
||||
|
||||
# Prepare everything with our `accelerator`.
|
||||
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
|
||||
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
|
||||
)
|
||||
|
||||
# Instantiate metric
|
||||
metric = load_metric("mean_iou")
|
||||
|
||||
if args.with_tracking:
|
||||
experiment_config = vars(args)
|
||||
# TensorBoard cannot log Enums, need the raw value
|
||||
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
|
||||
accelerator.init_trackers("semantic_segmentation_no_trainer", experiment_config)
|
||||
|
||||
# Train!
|
||||
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
|
||||
logger.info("***** Running training *****")
|
||||
logger.info(f" Num examples = {len(train_dataset)}")
|
||||
logger.info(f" Num Epochs = {args.num_train_epochs}")
|
||||
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
|
||||
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
|
||||
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
|
||||
logger.info(f" Total optimization steps = {args.max_train_steps}")
|
||||
# Only show the progress bar once on each machine.
|
||||
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
|
||||
completed_steps = 0
|
||||
|
||||
# Potentially load in the weights and states from a previous save
|
||||
if args.resume_from_checkpoint:
|
||||
if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
|
||||
accelerator.print(f"Resumed from checkpoint: {args.resume_from_checkpoint}")
|
||||
accelerator.load_state(args.resume_from_checkpoint)
|
||||
resume_step = None
|
||||
path = args.resume_from_checkpoint
|
||||
else:
|
||||
# Get the most recent checkpoint
|
||||
dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
|
||||
dirs.sort(key=os.path.getctime)
|
||||
path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
|
||||
if "epoch" in path:
|
||||
args.num_train_epochs -= int(path.replace("epoch_", ""))
|
||||
else:
|
||||
resume_step = int(path.replace("step_", ""))
|
||||
args.num_train_epochs -= resume_step // len(train_dataloader)
|
||||
resume_step = (args.num_train_epochs * len(train_dataloader)) - resume_step
|
||||
|
||||
for epoch in range(args.num_train_epochs):
|
||||
if args.with_tracking:
|
||||
total_loss = 0
|
||||
model.train()
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
# We need to skip steps until we reach the resumed step
|
||||
if args.resume_from_checkpoint and epoch == 0 and step < resume_step:
|
||||
continue
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
# We keep track of the loss at each epoch
|
||||
if args.with_tracking:
|
||||
total_loss += loss.detach().float()
|
||||
loss = loss / args.gradient_accumulation_steps
|
||||
accelerator.backward(loss)
|
||||
if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
progress_bar.update(1)
|
||||
completed_steps += 1
|
||||
|
||||
if isinstance(checkpointing_steps, int):
|
||||
if completed_steps % checkpointing_steps == 0:
|
||||
output_dir = f"step_{completed_steps}"
|
||||
if args.output_dir is not None:
|
||||
output_dir = os.path.join(args.output_dir, output_dir)
|
||||
accelerator.save_state(output_dir)
|
||||
|
||||
if args.push_to_hub and epoch < args.num_train_epochs - 1:
|
||||
accelerator.wait_for_everyone()
|
||||
unwrapped_model = accelerator.unwrap_model(model)
|
||||
unwrapped_model.save_pretrained(args.output_dir, save_function=accelerator.save)
|
||||
if accelerator.is_main_process:
|
||||
feature_extractor.save_pretrained(args.output_dir)
|
||||
repo.push_to_hub(
|
||||
commit_message=f"Training in progress {completed_steps} steps",
|
||||
blocking=False,
|
||||
auto_lfs_prune=True,
|
||||
)
|
||||
|
||||
if completed_steps >= args.max_train_steps:
|
||||
break
|
||||
|
||||
logger.info("***** Running evaluation *****")
|
||||
model.eval()
|
||||
for step, batch in enumerate(tqdm(eval_dataloader, disable=not accelerator.is_local_main_process)):
|
||||
outputs = model(**batch)
|
||||
|
||||
upsampled_logits = torch.nn.functional.interpolate(
|
||||
outputs.logits, size=batch["labels"].shape[-2:], mode="bilinear", align_corners=False
|
||||
)
|
||||
predictions = upsampled_logits.argmax(dim=1)
|
||||
|
||||
metric.add_batch(
|
||||
predictions=accelerator.gather(predictions),
|
||||
references=accelerator.gather(batch["labels"]),
|
||||
)
|
||||
|
||||
eval_metrics = metric.compute(
|
||||
num_labels=len(id2label),
|
||||
ignore_index=255,
|
||||
reduce_labels=False, # we've already reduced the labels before
|
||||
)
|
||||
logger.info(f"epoch {epoch}: {eval_metrics}")
|
||||
|
||||
if args.with_tracking:
|
||||
accelerator.log(
|
||||
{
|
||||
"mean_iou": eval_metrics["mean_iou"],
|
||||
"mean_accuracy": eval_metrics["mean_accuracy"],
|
||||
"overall_accuracy": eval_metrics["overall_accuracy"],
|
||||
"train_loss": total_loss,
|
||||
"epoch": epoch,
|
||||
"step": completed_steps,
|
||||
},
|
||||
)
|
||||
|
||||
if args.push_to_hub and epoch < args.num_train_epochs - 1:
|
||||
accelerator.wait_for_everyone()
|
||||
unwrapped_model = accelerator.unwrap_model(model)
|
||||
unwrapped_model.save_pretrained(args.output_dir, save_function=accelerator.save)
|
||||
if accelerator.is_main_process:
|
||||
feature_extractor.save_pretrained(args.output_dir)
|
||||
repo.push_to_hub(
|
||||
commit_message=f"Training in progress epoch {epoch}", blocking=False, auto_lfs_prune=True
|
||||
)
|
||||
|
||||
if args.checkpointing_steps == "epoch":
|
||||
output_dir = f"epoch_{epoch}"
|
||||
if args.output_dir is not None:
|
||||
output_dir = os.path.join(args.output_dir, output_dir)
|
||||
accelerator.save_state(output_dir)
|
||||
|
||||
if args.output_dir is not None:
|
||||
accelerator.wait_for_everyone()
|
||||
unwrapped_model = accelerator.unwrap_model(model)
|
||||
unwrapped_model.save_pretrained(args.output_dir, save_function=accelerator.save)
|
||||
if accelerator.is_main_process:
|
||||
feature_extractor.save_pretrained(args.output_dir)
|
||||
if args.push_to_hub:
|
||||
repo.push_to_hub(commit_message="End of training", auto_lfs_prune=True)
|
||||
|
||||
with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
|
||||
json.dump({"eval_overall_accuracy": eval_metrics["overall_accuracy"]}, f)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@ -43,6 +43,7 @@ SRC_DIRS = [
|
||||
"audio-classification",
|
||||
"speech-pretraining",
|
||||
"image-pretraining",
|
||||
"semantic-segmentation",
|
||||
]
|
||||
]
|
||||
sys.path.extend(SRC_DIRS)
|
||||
@ -54,6 +55,7 @@ if SRC_DIRS is not None:
|
||||
import run_mlm_no_trainer
|
||||
import run_ner_no_trainer
|
||||
import run_qa_no_trainer as run_squad_no_trainer
|
||||
import run_semantic_segmentation_no_trainer
|
||||
import run_summarization_no_trainer
|
||||
import run_swag_no_trainer
|
||||
import run_translation_no_trainer
|
||||
@ -296,3 +298,26 @@ class ExamplesTestsNoTrainer(TestCasePlus):
|
||||
self.assertGreaterEqual(result["eval_bleu"], 30)
|
||||
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
|
||||
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "translation_no_trainer")))
|
||||
|
||||
@slow
|
||||
def test_run_semantic_segmentation_no_trainer(self):
|
||||
stream_handler = logging.StreamHandler(sys.stdout)
|
||||
logger.addHandler(stream_handler)
|
||||
|
||||
tmp_dir = self.get_auto_remove_tmp_dir()
|
||||
testargs = f"""
|
||||
run_semantic_segmentation_no_trainer.py
|
||||
--dataset_name huggingface/semantic-segmentation-test-sample
|
||||
--output_dir {tmp_dir}
|
||||
--max_train_steps=10
|
||||
--num_warmup_steps=2
|
||||
--learning_rate=2e-4
|
||||
--per_device_train_batch_size=2
|
||||
--per_device_eval_batch_size=1
|
||||
--checkpointing_steps epoch
|
||||
""".split()
|
||||
|
||||
with patch.object(sys, "argv", testargs):
|
||||
run_semantic_segmentation_no_trainer.main()
|
||||
result = get_results(tmp_dir)
|
||||
self.assertGreaterEqual(result["eval_overall_accuracy"], 0.10)
|
||||
|
||||
Loading…
Reference in New Issue
Block a user