mirror of
https://github.com/huggingface/transformers.git
synced 2025-07-31 02:02:21 +06:00
Adding Docker images for transformers + notebooks (#3051)
* Added transformers-pytorch-cpu and gpu Docker images Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Added automatic jupyter launch for Docker image. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Move image from alpine to Ubuntu to align with NVidia container images. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Added TRANSFORMERS_VERSION argument to Dockerfile. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Added Pytorch-GPU based Docker image Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Added Tensorflow images. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Use python 3.7 as Tensorflow doesnt provide 3.8 compatible wheel. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Remove double FROM instructions on transformers-pytorch-cpu image. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Added transformers-tensorflow-gpu Docker image. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * use the correct ubuntu version for tensorflow-gpu Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Added pipelines example notebook Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Added transformers-cpu and transformers-gpu (including both PyTorch and TensorFlow) images. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Docker images doesnt start jupyter notebook by default. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Tokenizers notebook Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Update images links Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Update Docker images to python 3.7.6 and transformers 2.5.1 Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Added 02-transformers notebook. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Trying to realign 02-transformers notebook ? Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Added Transformer image schema * Some tweaks on tokenizers notebook * Removed old notebooks. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Attempt to provide table of content for each notebooks Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Second attempt. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Reintroduce transformer image. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Keep trying Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * It's going to fly ! Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Remaining of the Table of Content Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Fix inlined elements for the table of content Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Removed anaconda dependencies for Docker images. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Removing notebooks ToC Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Added LABEL to each docker image. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Removed old Dockerfile Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Directly use the context and include transformers from here. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Reduce overall size of compiled Docker images. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Install jupyter by default and use CMD for easier launching of the images. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Reduce number of layers in the images. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Added README.md for notebooks. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Fix notebooks link in README Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Fix some wording issues. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Added blog notebooks too. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> * Addressing spelling errors in review comments. Signed-off-by: Morgan Funtowicz <morgan@huggingface.co> Co-authored-by: MOI Anthony <xn1t0x@gmail.com>
This commit is contained in:
parent
34de670dbe
commit
71c8711970
@ -1,7 +0,0 @@
|
||||
FROM pytorch/pytorch:latest
|
||||
|
||||
RUN git clone https://github.com/NVIDIA/apex.git && cd apex && python setup.py install --cuda_ext --cpp_ext
|
||||
|
||||
RUN pip install transformers
|
||||
|
||||
WORKDIR /workspace
|
||||
26
docker/transformers-cpu/Dockerfile
Normal file
26
docker/transformers-cpu/Dockerfile
Normal file
@ -0,0 +1,26 @@
|
||||
FROM ubuntu:18.04
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="transformers"
|
||||
|
||||
RUN apt update && \
|
||||
apt install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
curl \
|
||||
ca-certificates \
|
||||
python3 \
|
||||
python3-pip && \
|
||||
rm -rf /var/lib/apt/lists
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir --upgrade pip && \
|
||||
python3 -m pip install --no-cache-dir \
|
||||
jupyter \
|
||||
tensorflow-cpu \
|
||||
torch
|
||||
|
||||
WORKDIR /workspace
|
||||
COPY . transformers/
|
||||
RUN cd transformers/ && \
|
||||
python3 -m pip install --no-cache-dir .
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
26
docker/transformers-gpu/Dockerfile
Normal file
26
docker/transformers-gpu/Dockerfile
Normal file
@ -0,0 +1,26 @@
|
||||
FROM nvidia/cuda:10.1-cudnn7-runtime-ubuntu18.04
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="transformers"
|
||||
|
||||
RUN apt update && \
|
||||
apt install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
curl \
|
||||
ca-certificates \
|
||||
python3 \
|
||||
python3-pip && \
|
||||
rm -rf /var/lib/apt/lists
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir --upgrade pip && \
|
||||
python3 -m pip install --no-cache-dir \
|
||||
jupyter \
|
||||
tensorflow \
|
||||
torch
|
||||
|
||||
WORKDIR /workspace
|
||||
COPY . transformers/
|
||||
RUN cd transformers/ && \
|
||||
python3 -m pip install --no-cache-dir .
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
25
docker/transformers-pytorch-cpu/Dockerfile
Normal file
25
docker/transformers-pytorch-cpu/Dockerfile
Normal file
@ -0,0 +1,25 @@
|
||||
FROM ubuntu:18.04
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="transformers"
|
||||
|
||||
RUN apt update && \
|
||||
apt install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
curl \
|
||||
ca-certificates \
|
||||
python3 \
|
||||
python3-pip && \
|
||||
rm -rf /var/lib/apt/lists
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir --upgrade pip && \
|
||||
python3 -m pip install --no-cache-dir \
|
||||
jupyter \
|
||||
torch
|
||||
|
||||
WORKDIR /workspace
|
||||
COPY . transformers/
|
||||
RUN cd transformers/ && \
|
||||
python3 -m pip install --no-cache-dir .
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
25
docker/transformers-pytorch-gpu/Dockerfile
Normal file
25
docker/transformers-pytorch-gpu/Dockerfile
Normal file
@ -0,0 +1,25 @@
|
||||
FROM nvidia/cuda:10.1-cudnn7-runtime-ubuntu18.04
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="transformers"
|
||||
|
||||
RUN apt update && \
|
||||
apt install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
curl \
|
||||
ca-certificates \
|
||||
python3 \
|
||||
python3-pip && \
|
||||
rm -rf /var/lib/apt/lists
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir --upgrade pip && \
|
||||
python3 -m pip install --no-cache-dir \
|
||||
mkl \
|
||||
torch
|
||||
|
||||
WORKDIR /workspace
|
||||
COPY . transformers/
|
||||
RUN cd transformers/ && \
|
||||
python3 -m pip install --no-cache-dir .
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
25
docker/transformers-tensorflow-cpu/Dockerfile
Normal file
25
docker/transformers-tensorflow-cpu/Dockerfile
Normal file
@ -0,0 +1,25 @@
|
||||
FROM ubuntu:18.04
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="transformers"
|
||||
|
||||
RUN apt update && \
|
||||
apt install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
curl \
|
||||
ca-certificates \
|
||||
python3 \
|
||||
python3-pip && \
|
||||
rm -rf /var/lib/apt/lists
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir --upgrade pip && \
|
||||
python3 -m pip install --no-cache-dir \
|
||||
mkl \
|
||||
tensorflow-cpu
|
||||
|
||||
WORKDIR /workspace
|
||||
COPY . transformers/
|
||||
RUN cd transformers/ && \
|
||||
python3 -m pip install --no-cache-dir .
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
25
docker/transformers-tensorflow-gpu/Dockerfile
Normal file
25
docker/transformers-tensorflow-gpu/Dockerfile
Normal file
@ -0,0 +1,25 @@
|
||||
FROM nvidia/cuda:10.1-cudnn7-runtime-ubuntu18.04
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="transformers"
|
||||
|
||||
RUN apt update && \
|
||||
apt install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
curl \
|
||||
ca-certificates \
|
||||
python3 \
|
||||
python3-pip && \
|
||||
rm -rf /var/lib/apt/lists
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir --upgrade pip && \
|
||||
python3 -m pip install --no-cache-dir \
|
||||
mkl \
|
||||
tensorflow
|
||||
|
||||
WORKDIR /workspace
|
||||
COPY . transformers/
|
||||
RUN cd transformers/ && \
|
||||
python3 -m pip install --no-cache-dir .
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
366
notebooks/01-training-tokenizers.ipynb
Normal file
366
notebooks/01-training-tokenizers.ipynb
Normal file
@ -0,0 +1,366 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"## Tokenization doesn't have to be slow !\n",
|
||||
"\n",
|
||||
"### Introduction\n",
|
||||
"\n",
|
||||
"Before going deep into any Machine Learning or Deep Learning Natural Language Processing models, every practitioner\n",
|
||||
"should find a way to map raw input strings to a representation understandable by a trainable model.\n",
|
||||
"\n",
|
||||
"One very simple approach would be to split inputs over every space and assign an identifier to each word. This approach\n",
|
||||
"would look similar to the code below in python\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"s = \"very long corpus...\"\n",
|
||||
"words = s.split(\" \") # Split over space\n",
|
||||
"vocabulary = dict(enumerate(set(words))) # Map storing the word to it's corresponding id\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"This approach might work well if your vocabulary remains small as it would store every word (or **token**) present in your original\n",
|
||||
"input. Moreover, word variations like \"cat\" and \"cats\" would not share the same identifiers even if their meaning is \n",
|
||||
"quite close.\n",
|
||||
"\n",
|
||||
"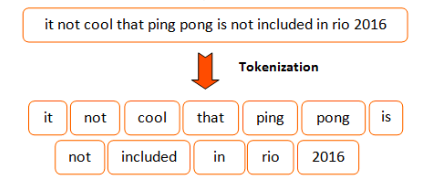\n",
|
||||
"\n",
|
||||
"### Subtoken Tokenization\n",
|
||||
"\n",
|
||||
"To overcome the issues described above, recent works have been done on tokenization, leveraging \"subtoken\" tokenization.\n",
|
||||
"**Subtokens** extends the previous splitting strategy to furthermore explode a word into grammatically logicial sub-components learned\n",
|
||||
"from the data.\n",
|
||||
"\n",
|
||||
"Taking our previous example of the words __cat__ and __cats__, a sub-tokenization of the word __cats__ would be [cat, ##s]. Where the prefix _\"##\"_ indicates a subtoken of the initial input. \n",
|
||||
"Such training algorithms might extract sub-tokens such as _\"##ing\"_, _\"##ed\"_ over English corpus.\n",
|
||||
"\n",
|
||||
"As you might think of, this kind of sub-tokens construction leveraging compositions of _\"pieces\"_ overall reduces the size\n",
|
||||
"of the vocabulary you have to carry to train a Machine Learning model. On the other side, as one token might be exploded\n",
|
||||
"into multiple subtokens, the input of your model might increase and become an issue on model with non-linear complexity over the input sequence's length. \n",
|
||||
" \n",
|
||||
"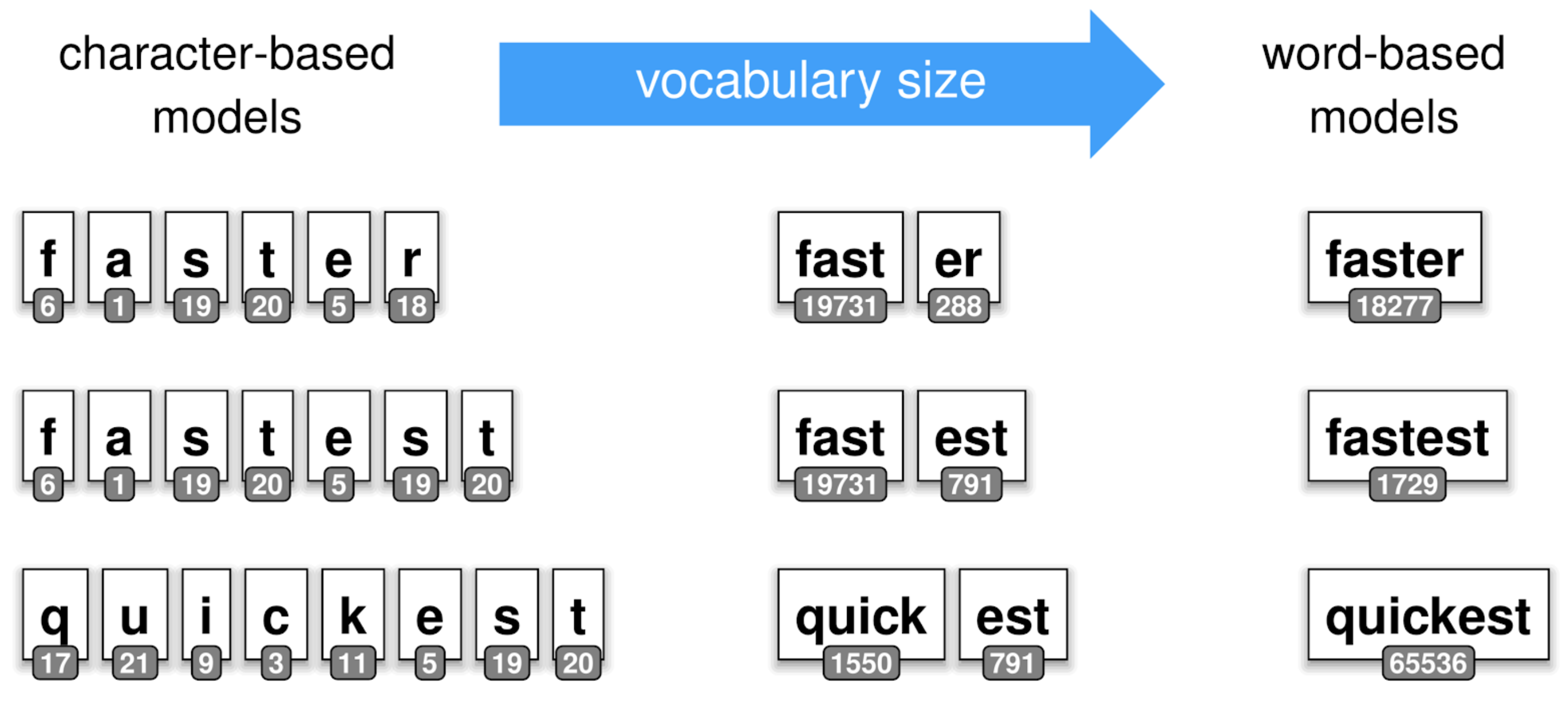\n",
|
||||
" \n",
|
||||
"Among all the tokenization algorithms, we can highlight a few subtokens algorithms used in Transformers-based SoTA models : \n",
|
||||
"\n",
|
||||
"- [Byte Pair Encoding (BPE) - Neural Machine Translation of Rare Words with Subword Units (Sennrich et al., 2015)](https://arxiv.org/abs/1508.07909)\n",
|
||||
"- [Word Piece - Japanese and Korean voice search (Schuster, M., and Nakajima, K., 2015)](https://research.google/pubs/pub37842/)\n",
|
||||
"- [Unigram Language Model - Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo, T., 2018)](https://arxiv.org/abs/1804.10959)\n",
|
||||
"- [Sentence Piece - A simple and language independent subword tokenizer and detokenizer for Neural Text Processing (Taku Kudo and John Richardson, 2018)](https://arxiv.org/abs/1808.06226)\n",
|
||||
"\n",
|
||||
"Going through all of them is out of the scope of this notebook, so we will just highlight how you can use them.\n",
|
||||
"\n",
|
||||
"### @huggingface/tokenizers library \n",
|
||||
"Along with the transformers library, we @huggingface provide a blazing fast tokenization library\n",
|
||||
"able to train, tokenize and decode dozens of Gb/s of text on a common multi-core machine.\n",
|
||||
"\n",
|
||||
"The library is written in Rust allowing us to take full advantage of multi-core parallel computations in a native and memory-aware way, on-top of which \n",
|
||||
"we provide bindings for Python and NodeJS (more bindings may be added in the future). \n",
|
||||
"\n",
|
||||
"We designed the library so that it provides all the required blocks to create end-to-end tokenizers in an interchangeable way. In that sense, we provide\n",
|
||||
"these various components: \n",
|
||||
"\n",
|
||||
"- **Normalizer**: Executes all the initial transformations over the initial input string. For example when you need to\n",
|
||||
"lowercase some text, maybe strip it, or even apply one of the common unicode normalization process, you will add a Normalizer. \n",
|
||||
"- **PreTokenizer**: In charge of splitting the initial input string. That's the component that decides where and how to\n",
|
||||
"pre-segment the origin string. The simplest example would be like we saw before, to simply split on spaces.\n",
|
||||
"- **Model**: Handles all the sub-token discovery and generation, this part is trainable and really dependant\n",
|
||||
" of your input data.\n",
|
||||
"- **Post-Processor**: Provides advanced construction features to be compatible with some of the Transformers-based SoTA\n",
|
||||
"models. For instance, for BERT it would wrap the tokenized sentence around [CLS] and [SEP] tokens.\n",
|
||||
"- **Decoder**: In charge of mapping back a tokenized input to the original string. The decoder is usually chosen according\n",
|
||||
"to the `PreTokenizer` we used previously.\n",
|
||||
"- **Trainer**: Provides training capabilities to each model.\n",
|
||||
"\n",
|
||||
"For each of the components above we provide multiple implementations:\n",
|
||||
"\n",
|
||||
"- **Normalizer**: Lowercase, Unicode (NFD, NFKD, NFC, NFKC), Bert, Strip, ...\n",
|
||||
"- **PreTokenizer**: ByteLevel, WhitespaceSplit, CharDelimiterSplit, Metaspace, ...\n",
|
||||
"- **Model**: WordLevel, BPE, WordPiece\n",
|
||||
"- **Post-Processor**: BertProcessor, ...\n",
|
||||
"- **Decoder**: WordLevel, BPE, WordPiece, ...\n",
|
||||
"\n",
|
||||
"All of these building blocks can be combined to create working tokenization pipelines. \n",
|
||||
"In the next section we will go over our first pipeline."
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% md\n",
|
||||
"is_executing": false
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"Alright, now we are ready to implement our first tokenization pipeline through `tokenizers`. \n",
|
||||
"\n",
|
||||
"For this, we will train a Byte-Pair Encoding (BPE) tokenizer on a quite small input for the purpose of this notebook.\n",
|
||||
"We will work with [the file from peter Norving](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=2ahUKEwjYp9Ppru_nAhUBzIUKHfbUAG8QFjAAegQIBhAB&url=https%3A%2F%2Fnorvig.com%2Fbig.txt&usg=AOvVaw2ed9iwhcP1RKUiEROs15Dz).\n",
|
||||
"This file contains around 130.000 lines of raw text that will be processed by the library to generate a working tokenizer."
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"BIG_FILE_URL = 'https://raw.githubusercontent.com/dscape/spell/master/test/resources/big.txt'\n",
|
||||
"\n",
|
||||
"# Let's download the file and save it somewhere\n",
|
||||
"from requests import get\n",
|
||||
"with open('big.txt', 'wb') as big_f:\n",
|
||||
" response = get(BIG_FILE_URL, )\n",
|
||||
" \n",
|
||||
" if response.status_code == 200:\n",
|
||||
" big_f.write(response.content)\n",
|
||||
" else:\n",
|
||||
" print(\"Unable to get the file: {}\".format(response.reason))\n"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% code\n",
|
||||
"is_executing": false
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
" \n",
|
||||
"Now that we have our training data we need to create the overall pipeline for the tokenizer\n",
|
||||
" "
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% md\n",
|
||||
"is_executing": false
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# For the user's convenience `tokenizers` provides some very high-level classes encapsulating\n",
|
||||
"# the overall pipeline for various well-known tokenization algorithm. \n",
|
||||
"# Everything described below can be replaced by the ByteLevelBPETokenizer class. \n",
|
||||
"\n",
|
||||
"from tokenizers import Tokenizer\n",
|
||||
"from tokenizers.decoders import ByteLevel as ByteLevelDecoder\n",
|
||||
"from tokenizers.models import BPE\n",
|
||||
"from tokenizers.normalizers import Lowercase, NFKC, Sequence\n",
|
||||
"from tokenizers.pre_tokenizers import ByteLevel\n",
|
||||
"\n",
|
||||
"# First we create an empty Byte-Pair Encoding model (i.e. not trained model)\n",
|
||||
"tokenizer = Tokenizer(BPE.empty())\n",
|
||||
"\n",
|
||||
"# Then we enable lower-casing and unicode-normalization\n",
|
||||
"# The Sequence normalizer allows us to combine multiple Normalizer, that will be\n",
|
||||
"# executed in sequence.\n",
|
||||
"tokenizer.normalizer = Sequence([\n",
|
||||
" NFKC(),\n",
|
||||
" Lowercase()\n",
|
||||
"])\n",
|
||||
"\n",
|
||||
"# Out tokenizer also needs a pre-tokenizer responsible for converting the input to a ByteLevel representation.\n",
|
||||
"tokenizer.pre_tokenizer = ByteLevel()\n",
|
||||
"\n",
|
||||
"# And finally, let's plug a decoder so we can recover from a tokenized input to the original one\n",
|
||||
"tokenizer.decoder = ByteLevelDecoder()"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% code\n",
|
||||
"is_executing": false
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"The overall pipeline is now ready to be trained on the corpus we downloaded earlier in this notebook."
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"text": [
|
||||
"Trained vocab size: 25000\n"
|
||||
],
|
||||
"output_type": "stream"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from tokenizers.trainers import BpeTrainer\n",
|
||||
"\n",
|
||||
"# We initialize our trainer, giving him the details about the vocabulary we want to generate\n",
|
||||
"trainer = BpeTrainer(vocab_size=25000, show_progress=True, initial_alphabet=ByteLevel.alphabet())\n",
|
||||
"tokenizer.train(trainer, [\"big.txt\"])\n",
|
||||
"\n",
|
||||
"print(\"Trained vocab size: {}\".format(tokenizer.get_vocab_size()))"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% code\n",
|
||||
"is_executing": false
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"Et voilà ! You trained your very first tokenizer from scratch using `tokenizers`. Of course, this \n",
|
||||
"covers only the basics, and you may want to have a look at the `add_special_tokens` or `special_tokens` parameters\n",
|
||||
"on the `Trainer` class, but the overall process should be very similar.\n",
|
||||
"\n",
|
||||
"We can save the content of the model to reuse it later."
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": "['./vocab.json', './merges.txt']"
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "execute_result",
|
||||
"execution_count": 12
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# You will see the generated files in the output.\n",
|
||||
"tokenizer.model.save('.')"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% code\n",
|
||||
"is_executing": false
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"Now, let load the trained model and start using out newly trained tokenizer"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"text": [
|
||||
"Encoded string: ['Ġthis', 'Ġis', 'Ġa', 'Ġsimple', 'Ġin', 'put', 'Ġto', 'Ġbe', 'Ġtoken', 'ized']\n",
|
||||
"Decoded string: this is a simple input to be tokenized\n"
|
||||
],
|
||||
"output_type": "stream"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Let's tokenizer a simple input\n",
|
||||
"tokenizer.model = BPE.from_files('vocab.json', 'merges.txt')\n",
|
||||
"encoding = tokenizer.encode(\"This is a simple input to be tokenized\")\n",
|
||||
"\n",
|
||||
"print(\"Encoded string: {}\".format(encoding.tokens))\n",
|
||||
"\n",
|
||||
"decoded = tokenizer.decode(encoding.ids)\n",
|
||||
"print(\"Decoded string: {}\".format(decoded))"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% code\n",
|
||||
"is_executing": false
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"The Encoding structure exposes multiple properties which are useful when working with transformers models\n",
|
||||
"\n",
|
||||
"- normalized_str: The input string after normalization (lower-casing, unicode, stripping, etc.)\n",
|
||||
"- original_str: The input string as it was provided\n",
|
||||
"- tokens: The generated tokens with their string representation\n",
|
||||
"- input_ids: The generated tokens with their integer representation\n",
|
||||
"- attention_mask: If your input has been padded by the tokenizer, then this would be a vector of 1 for any non padded token and 0 for padded ones.\n",
|
||||
"- special_token_mask: If your input contains special tokens such as [CLS], [SEP], [MASK], [PAD], then this would be a vector with 1 in places where a special token has been added.\n",
|
||||
"- type_ids: If your was made of multiple \"parts\" such as (question, context), then this would be a vector with for each token the segment it belongs to.\n",
|
||||
"- overflowing: If your has been truncated into multiple subparts because of a length limit (for BERT for example the sequence length is limited to 512), this will contain all the remaining overflowing parts."
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
}
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 2
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython2",
|
||||
"version": "2.7.6"
|
||||
},
|
||||
"pycharm": {
|
||||
"stem_cell": {
|
||||
"cell_type": "raw",
|
||||
"source": [],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 0
|
||||
}
|
||||
502
notebooks/02-transformers.ipynb
Normal file
502
notebooks/02-transformers.ipynb
Normal file
@ -0,0 +1,502 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"## Introduction\n",
|
||||
"The transformers library is an open-source, community-based repository to train, use and share models based on \n",
|
||||
"the Transformer architecture [(Vaswani & al., 2017)](https://arxiv.org/abs/1706.03762) such as Bert [(Devlin & al., 2018)](https://arxiv.org/abs/1810.04805),\n",
|
||||
"Roberta [(Liu & al., 2019)](https://arxiv.org/abs/1907.11692), GPT2 [(Radford & al., 2019)](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf),\n",
|
||||
"XLNet [(Yang & al., 2019)](https://arxiv.org/abs/1906.08237), etc. \n",
|
||||
"\n",
|
||||
"Along with the models, the library contains multiple variations of each of them for a large variety of \n",
|
||||
"downstream-tasks like **Named Entity Recognition (NER)**, **Sentiment Analysis**, \n",
|
||||
"**Language Modeling**, **Question Answering** and so on.\n",
|
||||
"\n",
|
||||
"## Before Transformer\n",
|
||||
"\n",
|
||||
"Back to 2017, most of the people using Neural Networks when working on Natural Language Processing were relying on \n",
|
||||
"sequential processing of the input through [Recurrent Neural Network (RNN)](https://en.wikipedia.org/wiki/Recurrent_neural_network).\n",
|
||||
"\n",
|
||||
"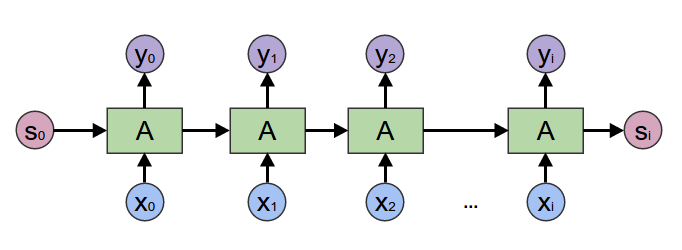 \n",
|
||||
"\n",
|
||||
"RNNs were performing well on large variety of tasks involving sequential dependency over the input sequence. \n",
|
||||
"However, this sequentially-dependent process had issues modeling very long range dependencies and \n",
|
||||
"was not well suited for the kind of hardware we're currently leveraging due to bad parallelization capabilities. \n",
|
||||
"\n",
|
||||
"Some extensions were provided by the academic community, such as Bidirectional RNN ([Schuster & Paliwal., 1997](https://www.researchgate.net/publication/3316656_Bidirectional_recurrent_neural_networks), [Graves & al., 2005](https://mediatum.ub.tum.de/doc/1290195/file.pdf)), \n",
|
||||
"which can be seen as a concatenation of two sequential process, on going forward, the other one going backward over the sequence input.\n",
|
||||
"\n",
|
||||
"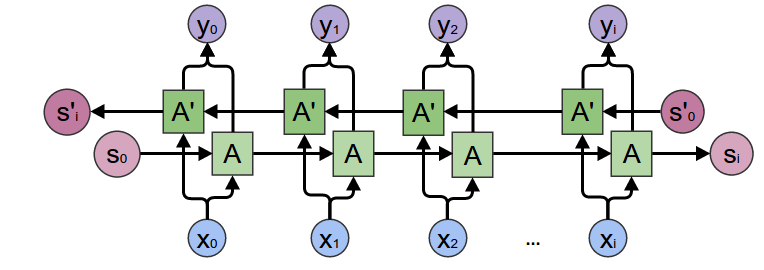\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"And also, the Attention mechanism, which introduced a good improvement over \"raw\" RNNs by giving \n",
|
||||
"a learned, weighted-importance to each element in the sequence, allowing the model to focus on important elements.\n",
|
||||
"\n",
|
||||
" \n",
|
||||
"\n",
|
||||
"## Then comes the Transformer \n",
|
||||
"\n",
|
||||
"The Transformers era originally started from the work of [(Vaswani & al., 2017)](https://arxiv.org/abs/1706.03762) who\n",
|
||||
"demonstrated its superiority over [Recurrent Neural Network (RNN)](https://en.wikipedia.org/wiki/Recurrent_neural_network)\n",
|
||||
"on translation tasks but it quickly extended to almost all the tasks RNNs were State-of-the-Art at that time.\n",
|
||||
"\n",
|
||||
"One advantage of Transformer over its RNN counterpart was its non sequential attention model. Remember, the RNNs had to\n",
|
||||
"iterate over each element of the input sequence one-by-one and carry an \"updatable-state\" between each hop. With Transformer\n",
|
||||
"the, the model is able to look at every position in the sequence, at the same time, in one operation.\n",
|
||||
"\n",
|
||||
"For a deep-dive into the Transformer architecture, [The Annotated Transformer](https://nlp.seas.harvard.edu/2018/04/03/attention.html#encoder-and-decoder-stacks) \n",
|
||||
"will drive you along all the details of the paper.\n",
|
||||
"\n",
|
||||
"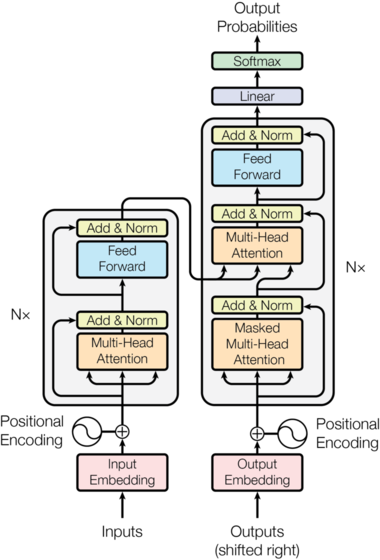"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"## Getting started with transformers\n",
|
||||
"\n",
|
||||
"For the rest of this notebook, we will use a BERT model, as it's the most simple and there are plenty of content about it\n",
|
||||
"over the internet, it will be easy to dig more over this architecture if you want to.\n",
|
||||
"\n",
|
||||
"The transformers library allows you to benefits from large, pretrained language models without requiring a huge and costly computational\n",
|
||||
"infrastructure. Most of the State-of-the-Art models are provided directly by their author and made available in the library \n",
|
||||
"in PyTorch and TensorFlow in a transparent and interchangeable way. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 74,
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% code\n"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"<torch.autograd.grad_mode.set_grad_enabled at 0x1af62fd450>"
|
||||
]
|
||||
},
|
||||
"execution_count": 74,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"from transformers import AutoModel, AutoTokenizer, BertTokenizer\n",
|
||||
"\n",
|
||||
"torch.set_grad_enabled(False)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 75,
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% code\n"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Store the model we want to use\n",
|
||||
"MODEL_NAME = \"bert-base-cased\"\n",
|
||||
"\n",
|
||||
"# We need to create the model and tokenizer\n",
|
||||
"model = AutoModel.from_pretrained(MODEL_NAME)\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"With only the above two lines of code, you're ready to use a BERT pre-trained model. \n",
|
||||
"The tokenizers will allow us to map a raw textual input to a sequence of integers representing our textual input\n",
|
||||
"in a way the model can manipulate."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 76,
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% code\n"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Tokens: ['[CLS]', 'This', 'is', 'an', 'input', 'example', '[SEP]']\n",
|
||||
"Tokens id: [101, 1188, 1110, 1126, 7758, 1859, 102]\n",
|
||||
"Tokens PyTorch: tensor([[ 101, 1188, 1110, 1126, 7758, 1859, 102]])\n",
|
||||
"Tokenwise output: torch.Size([1, 7, 768]), Pooled output: torch.Size([1, 768])\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Tokens comes from a process that splits the input into sub-entities with interesting linguistic properties. \n",
|
||||
"tokens = tokenizer.tokenize(\"This is an input example\")\n",
|
||||
"print(\"Tokens: {}\".format(tokens))\n",
|
||||
"\n",
|
||||
"# This is not sufficient for the model, as it requires integers as input, \n",
|
||||
"# not a problem, let's convert tokens to ids.\n",
|
||||
"tokens_ids = tokenizer.convert_tokens_to_ids(tokens)\n",
|
||||
"print(\"Tokens id: {}\".format(tokens_ids))\n",
|
||||
"\n",
|
||||
"# We need to convert to a Deep Learning framework specific format, let's use PyTorch for now.\n",
|
||||
"tokens_pt = torch.tensor([tokens_ids])\n",
|
||||
"print(\"Tokens PyTorch: {}\".format(tokens_pt))\n",
|
||||
"\n",
|
||||
"# Now we're ready to go through BERT with out input\n",
|
||||
"outputs, pooled = model(tokens_pt)\n",
|
||||
"print(\"Tokenwise output: {}, Pooled output: {}\".format(outputs.shape, pooled.shape))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"As you can see, BERT outputs two tensors:\n",
|
||||
" - One with the generated representation for every token in the input `(1, NB_TOKENS, REPRESENTATION_SIZE)`\n",
|
||||
" - One with an aggregated representation for the whole input `(1, REPRESENTATION_SIZE)`\n",
|
||||
" \n",
|
||||
"The first, token-based, representation can be leveraged if your task requires to keep the sequence representation and you\n",
|
||||
"want to operate at a token-level. This is particularly useful for Named Entity Recognition and Question-Answering.\n",
|
||||
"\n",
|
||||
"The second, aggregated, representation is especially useful if you need to extract the overall context of the sequence and don't\n",
|
||||
"require a fine-grained token-leven. This is the case for Sentiment-Analysis of the sequence or Information Retrieval."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"The code you saw in the previous section introduced all the steps required to do simple model invocation.\n",
|
||||
"For more day-to-day usage, transformers provides you higher-level methods which will makes your NLP journey easier\n",
|
||||
"Let's improve our previous example"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 77,
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% code\n"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"input_ids:\n",
|
||||
"\ttensor([[ 101, 1188, 1110, 1126, 7758, 1859, 102]])\n",
|
||||
"token_type_ids:\n",
|
||||
"\ttensor([[0, 0, 0, 0, 0, 0, 0]])\n",
|
||||
"attention_mask:\n",
|
||||
"\ttensor([[1, 1, 1, 1, 1, 1, 1]])\n",
|
||||
"Difference with previous code: (0.0, 0.0)\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# tokens = tokenizer.tokenize(\"This is an input example\")\n",
|
||||
"# tokens_ids = tokenizer.convert_tokens_to_ids(tokens)\n",
|
||||
"# tokens_pt = torch.tensor([tokens_ids])\n",
|
||||
"\n",
|
||||
"# This code can be factored into one-line as follow\n",
|
||||
"tokens_pt2 = tokenizer.encode_plus(\"This is an input example\", return_tensors=\"pt\")\n",
|
||||
"\n",
|
||||
"for key, value in tokens_pt2.items():\n",
|
||||
" print(\"{}:\\n\\t{}\".format(key, value))\n",
|
||||
"\n",
|
||||
"outputs2, pooled2 = model(**tokens_pt2)\n",
|
||||
"print(\"Difference with previous code: ({}, {})\".format((outputs2 - outputs).sum(), (pooled2 - pooled).sum()))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"As you can see above, the methode `encode_plus` provides a convenient way to generate all the required parameters\n",
|
||||
"that will go through the model. \n",
|
||||
"\n",
|
||||
"Moreover, you might have noticed it generated some additional tensors: \n",
|
||||
"\n",
|
||||
"- token_type_ids: This tensor will map every tokens to their corresponding segment (see below).\n",
|
||||
"- attention_mask: This tensor is used to \"mask\" padded values in a batch of sequence with different lengths (see below)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 78,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Single segment token (str): ['[CLS]', 'This', 'is', 'a', 'sample', 'input', '[SEP]']\n",
|
||||
"Single segment token (int): [101, 1188, 1110, 170, 6876, 7758, 102]\n",
|
||||
"Single segment type : [0, 0, 0, 0, 0, 0, 0]\n",
|
||||
"\n",
|
||||
"Multi segment token (str): ['[CLS]', 'This', 'is', 'segment', 'A', '[SEP]', 'This', 'is', 'segment', 'B', '[SEP]']\n",
|
||||
"Multi segment token (int): [101, 1188, 1110, 6441, 138, 102, 1188, 1110, 6441, 139, 102]\n",
|
||||
"Multi segment type : [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Single segment input\n",
|
||||
"single_seg_input = tokenizer.encode_plus(\"This is a sample input\")\n",
|
||||
"\n",
|
||||
"# Multiple segment input\n",
|
||||
"multi_seg_input = tokenizer.encode_plus(\"This is segment A\", \"This is segment B\")\n",
|
||||
"\n",
|
||||
"print(\"Single segment token (str): {}\".format(tokenizer.convert_ids_to_tokens(single_seg_input['input_ids'])))\n",
|
||||
"print(\"Single segment token (int): {}\".format(single_seg_input['input_ids']))\n",
|
||||
"print(\"Single segment type : {}\".format(single_seg_input['token_type_ids']))\n",
|
||||
"\n",
|
||||
"# Segments are concatened in the input to the model, with \n",
|
||||
"print()\n",
|
||||
"print(\"Multi segment token (str): {}\".format(tokenizer.convert_ids_to_tokens(multi_seg_input['input_ids'])))\n",
|
||||
"print(\"Multi segment token (int): {}\".format(multi_seg_input['input_ids']))\n",
|
||||
"print(\"Multi segment type : {}\".format(multi_seg_input['token_type_ids']))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 79,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Tokens (int) : [101, 1188, 1110, 170, 6876, 102, 0, 0]\n",
|
||||
"Tokens (str) : ['[CLS]', 'This', 'is', 'a', 'sample', '[SEP]', '[PAD]', '[PAD]']\n",
|
||||
"Tokens (attn_mask): [1, 1, 1, 1, 1, 1, 0, 0]\n",
|
||||
"\n",
|
||||
"Tokens (int) : [101, 1188, 1110, 1330, 2039, 6876, 3087, 102]\n",
|
||||
"Tokens (str) : ['[CLS]', 'This', 'is', 'another', 'longer', 'sample', 'text', '[SEP]']\n",
|
||||
"Tokens (attn_mask): [1, 1, 1, 1, 1, 1, 1, 1]\n",
|
||||
"\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Padding highlight\n",
|
||||
"tokens = tokenizer.batch_encode_plus(\n",
|
||||
" [\"This is a sample\", \"This is another longer sample text\"], \n",
|
||||
" pad_to_max_length=True # First sentence will have some PADDED tokens to match second sequence length\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"for i in range(2):\n",
|
||||
" print(\"Tokens (int) : {}\".format(tokens['input_ids'][i]))\n",
|
||||
" print(\"Tokens (str) : {}\".format([tokenizer.convert_ids_to_tokens(s) for s in tokens['input_ids'][i]]))\n",
|
||||
" print(\"Tokens (attn_mask): {}\".format(tokens['attention_mask'][i]))\n",
|
||||
" print()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Frameworks interoperability\n",
|
||||
"\n",
|
||||
"One of the most powerfull feature of transformers is its ability to seamlessly move from PyTorch to Tensorflow\n",
|
||||
"without pain for the user.\n",
|
||||
"\n",
|
||||
"We provide some convenient methods to load TensorFlow pretrained weight insinde a PyTorch model and opposite."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 80,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from transformers import TFBertModel, BertModel\n",
|
||||
"\n",
|
||||
"# Let's load a BERT model for TensorFlow and PyTorch\n",
|
||||
"model_tf = TFBertModel.from_pretrained('bert-base-cased')\n",
|
||||
"model_pt = BertModel.from_pretrained('bert-base-cased')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 81,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"output differences: 2.971128560602665e-05\n",
|
||||
"pooled differences: -8.576549589633942e-06\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# transformers generates a ready to use dictionary with all the required parameters for the specific framework.\n",
|
||||
"input_tf = tokenizer.encode_plus(\"This is a sample input\", return_tensors=\"tf\")\n",
|
||||
"input_pt = tokenizer.encode_plus(\"This is a sample input\", return_tensors=\"pt\")\n",
|
||||
"\n",
|
||||
"# Let's compare the outputs\n",
|
||||
"output_tf, output_pt = model_tf(input_tf), model_pt(**input_pt)\n",
|
||||
"\n",
|
||||
"# Models outputs 2 values (The value for each tokens, the pooled representation of the input sentence)\n",
|
||||
"# Here we compare the output differences between PyTorch and TensorFlow.\n",
|
||||
"for name, o_tf, o_pt in zip([\"output\", \"pooled\"], output_tf, output_pt):\n",
|
||||
" print(\"{} differences: {}\".format(name, (o_tf.numpy() - o_pt.numpy()).sum()))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"## Want it lighter? Faster? Let's talk distillation! \n",
|
||||
"\n",
|
||||
"One of the main concerns when using these Transformer based models is the computational power they require. All over this notebook we are using BERT model as it can be run on common machines but that's not the case for all of the models.\n",
|
||||
"\n",
|
||||
"For example, Google released a few months ago **T5** an Encoder/Decoder architecture based on Transformer and available in `transformers` with no more than 11 billions parameters. Microsoft also recently entered the game with **Turing-NLG** using 17 billions parameters. This kind of model requires tens of gigabytes to store the weights and a tremendous compute infrastructure to run such models which makes it impracticable for the common man !\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"With the goal of making Transformer-based NLP accessible to everyone we @huggingface developed models that take advantage of a training process called **Distillation** which allows us to drastically reduce the resources needed to run such models with almost zero drop in performances.\n",
|
||||
"\n",
|
||||
"Going over the whole Distillation process is out of the scope of this notebook, but if you want more information on the subject you may refer to [this Medium article written by my colleague Victor SANH, author of DistilBERT paper](https://medium.com/huggingface/distilbert-8cf3380435b5), you might also want to directly have a look at the paper [(Sanh & al., 2019)](https://arxiv.org/abs/1910.01108)\n",
|
||||
"\n",
|
||||
"Of course, in `transformers` we have distilled some models and made them available directly in the library ! "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 82,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"CPU times: user 57.1 ms, sys: 2.44 ms, total: 59.5 ms\n",
|
||||
"Wall time: 35.5 ms\n",
|
||||
"CPU times: user 98.8 ms, sys: 725 µs, total: 99.5 ms\n",
|
||||
"Wall time: 50 ms\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from transformers import DistilBertModel\n",
|
||||
"\n",
|
||||
"bert_distil = DistilBertModel.from_pretrained('distilbert-base-cased')\n",
|
||||
"input_pt = tokenizer.encode_plus(\n",
|
||||
" 'This is a sample input to demonstrate performance of distiled models especially inference time', \n",
|
||||
" return_tensors=\"pt\"\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"%time _ = bert_distil(input_pt['input_ids'])\n",
|
||||
"%time _ = model_pt(input_pt['input_ids'])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Community provided models\n",
|
||||
"\n",
|
||||
"Last but not least, earlier in this notebook we introduced Hugging Face `transformers` as a repository for the NLP community to exchange pretrained models. We wanted to highlight this features and all the possibilities it offers for the end-user.\n",
|
||||
"\n",
|
||||
"To leverage community pretrained models, just provide the organisation name and name of the model to `from_pretrained` and it will do all the magic for you ! \n",
|
||||
"\n",
|
||||
"\n",
|
||||
"We currently have more 50 models provided by the community and more are added every day, don't hesitate to give it a try !"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 83,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Let's load German BERT from the Bavarian State Library\n",
|
||||
"de_bert = BertModel.from_pretrained(\"dbmdz/bert-base-german-cased\")\n",
|
||||
"de_tokenizer = BertTokenizer.from_pretrained(\"dbmdz/bert-base-german-cased\")\n",
|
||||
"\n",
|
||||
"de_input = de_tokenizer.encode_plus(\n",
|
||||
" \"Hugging Face ist einen französische Firma Mitarbeitern in New-York.\",\n",
|
||||
" return_tensors=\"pt\"\n",
|
||||
")\n",
|
||||
"output_de, pooled_de = de_bert(**de_input)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.7.6"
|
||||
},
|
||||
"pycharm": {
|
||||
"stem_cell": {
|
||||
"cell_type": "raw",
|
||||
"source": [],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 1
|
||||
}
|
||||
594
notebooks/03-pipelines.ipynb
Normal file
594
notebooks/03-pipelines.ipynb
Normal file
@ -0,0 +1,594 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"## How can I leverage State-of-the-Art Natural Language Models with only one line of code ?"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"Newly introduced in transformers v2.3.0, **pipelines** provides a high-level, easy to use,\n",
|
||||
"API for doing inference over a variety of downstream-tasks, including: \n",
|
||||
"\n",
|
||||
"- Sentence Classification (Sentiment Analysis): Indicate if the overall sentence is either positive or negative. _(Binary Classification task or Logitic Regression task)_\n",
|
||||
"- Token Classification (Named Entity Recognition, Part-of-Speech tagging): For each sub-entities _(**tokens**)_ in the input, assign them a label _(Classification task)_.\n",
|
||||
"- Question-Answering: Provided a tuple (question, context) the model should find the span of text in **content** answering the **question**.\n",
|
||||
"- Mask-Filling: Suggests possible word(s) to fill the masked input with respect to the provided **context**.\n",
|
||||
"- Feature Extraction: Maps the input to a higher, multi-dimensional space learned from the data.\n",
|
||||
"\n",
|
||||
"Pipelines encapsulate the overall process of every NLP process:\n",
|
||||
" \n",
|
||||
" 1. Tokenization: Split the initial input into multiple sub-entities with ... properties (i.e. tokens).\n",
|
||||
" 2. Inference: Maps every tokens into a more meaningful representation. \n",
|
||||
" 3. Decoding: Use the above representation to generate and/or extract the final output for the underlying task.\n",
|
||||
"\n",
|
||||
"The overall API is exposed to the end-user through the `pipeline()` method with the following \n",
|
||||
"structure:\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"from transformers import pipeline\n",
|
||||
"\n",
|
||||
"# Using default model and tokenizer for the task\n",
|
||||
"pipeline(\"<task-name>\")\n",
|
||||
"\n",
|
||||
"# Using a user-specified model\n",
|
||||
"pipeline(\"<task-name>\", model=\"<model_name>\")\n",
|
||||
"\n",
|
||||
"# Using custom model/tokenizer as str\n",
|
||||
"pipeline('<task-name>', model='<model name>', tokenizer='<tokenizer_name>')\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 29,
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% code \n"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"ename": "SyntaxError",
|
||||
"evalue": "from __future__ imports must occur at the beginning of the file (<ipython-input-29-c3a037bd4c55>, line 5)",
|
||||
"output_type": "error",
|
||||
"traceback": [
|
||||
"\u001b[0;36m File \u001b[0;32m\"<ipython-input-29-c3a037bd4c55>\"\u001b[0;36m, line \u001b[0;32m5\u001b[0m\n\u001b[0;31m from transformers import pipeline\u001b[0m\n\u001b[0m ^\u001b[0m\n\u001b[0;31mSyntaxError\u001b[0m\u001b[0;31m:\u001b[0m from __future__ imports must occur at the beginning of the file\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import numpy as np\n",
|
||||
"from __future__ import print_function\n",
|
||||
"from ipywidgets import interact, interactive, fixed, interact_manual\n",
|
||||
"import ipywidgets as widgets\n",
|
||||
"from transformers import pipeline"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"## 1. Sentence Classification - Sentiment Analysis"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% code\n"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "6aeccfdf51994149bdd1f3d3533e380f",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
"HBox(children=(FloatProgress(value=0.0, description='Downloading', max=230.0, style=ProgressStyle(description_…"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[{'label': 'POSITIVE', 'score': 0.800251},\n",
|
||||
" {'label': 'NEGATIVE', 'score': 1.2489903}]"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"nlp_sentence_classif = pipeline('sentiment-analysis')\n",
|
||||
"nlp_sentence_classif(['Such a nice weather outside !', 'This movie was kind of boring.'])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"## 2. Token Classification - Named Entity Recognition"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% code\n"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "b5549c53c27346a899af553c977f00bc",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
"HBox(children=(FloatProgress(value=0.0, description='Downloading', max=230.0, style=ProgressStyle(description_…"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[{'word': 'Hu', 'score': 0.9970937967300415, 'entity': 'I-ORG'},\n",
|
||||
" {'word': '##gging', 'score': 0.9345750212669373, 'entity': 'I-ORG'},\n",
|
||||
" {'word': 'Face', 'score': 0.9787060022354126, 'entity': 'I-ORG'},\n",
|
||||
" {'word': 'French', 'score': 0.9981995820999146, 'entity': 'I-MISC'},\n",
|
||||
" {'word': 'New', 'score': 0.9983047246932983, 'entity': 'I-LOC'},\n",
|
||||
" {'word': '-', 'score': 0.8913455009460449, 'entity': 'I-LOC'},\n",
|
||||
" {'word': 'York', 'score': 0.9979523420333862, 'entity': 'I-LOC'}]"
|
||||
]
|
||||
},
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"nlp_token_class = pipeline('ner')\n",
|
||||
"nlp_token_class('Hugging Face is a French company based in New-York.')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 3. Question Answering"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% code\n"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "6e56a8edcef44ec2ae838711ecd22d3a",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
"HBox(children=(FloatProgress(value=0.0, description='Downloading', max=230.0, style=ProgressStyle(description_…"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"convert squad examples to features: 100%|██████████| 1/1 [00:00<00:00, 53.05it/s]\n",
|
||||
"add example index and unique id: 100%|██████████| 1/1 [00:00<00:00, 2673.23it/s]\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.9632966867654424, 'start': 42, 'end': 50, 'answer': 'New-York.'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"nlp_qa = pipeline('question-answering')\n",
|
||||
"nlp_qa(context='Hugging Face is a French company based in New-York.', question='Where is based Hugging Face ?')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 4. Text Generation - Mask Filling"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% code\n"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "1930695ea2d24ca98c6d7c13842d377f",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
"HBox(children=(FloatProgress(value=0.0, description='Downloading', max=230.0, style=ProgressStyle(description_…"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[{'sequence': '<s> Hugging Face is a French company based in Paris</s>',\n",
|
||||
" 'score': 0.25288480520248413,\n",
|
||||
" 'token': 2201},\n",
|
||||
" {'sequence': '<s> Hugging Face is a French company based in Lyon</s>',\n",
|
||||
" 'score': 0.07639515399932861,\n",
|
||||
" 'token': 12790},\n",
|
||||
" {'sequence': '<s> Hugging Face is a French company based in Brussels</s>',\n",
|
||||
" 'score': 0.055500105023384094,\n",
|
||||
" 'token': 6497},\n",
|
||||
" {'sequence': '<s> Hugging Face is a French company based in Geneva</s>',\n",
|
||||
" 'score': 0.04264815151691437,\n",
|
||||
" 'token': 11559},\n",
|
||||
" {'sequence': '<s> Hugging Face is a French company based in France</s>',\n",
|
||||
" 'score': 0.03868963569402695,\n",
|
||||
" 'token': 1470}]"
|
||||
]
|
||||
},
|
||||
"execution_count": 20,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"nlp_fill = pipeline('fill-mask')\n",
|
||||
"nlp_fill('Hugging Face is a French company based in <mask>')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 5. Projection - Features Extraction "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 32,
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% code\n"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "92fa4d67290f49a3943dc0abd7529892",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
"HBox(children=(FloatProgress(value=0.0, description='Downloading', max=230.0, style=ProgressStyle(description_…"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"(1, 12, 768)"
|
||||
]
|
||||
},
|
||||
"execution_count": 32,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import numpy as np\n",
|
||||
"nlp_features = pipeline('feature-extraction')\n",
|
||||
"output = nlp_features('Hugging Face is a French company based in Paris')\n",
|
||||
"np.array(output).shape # (Samples, Tokens, Vector Size)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"name": "#%% md\n"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"Alright ! Now you have a nice picture of what is possible through transformers' pipelines, and there is more\n",
|
||||
"to come in future releases. \n",
|
||||
"\n",
|
||||
"In the meantime, you can try the different pipelines with your own inputs"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 40,
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% code\n"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "261ae9fa30e84d1d84a3b0d9682ac477",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
"Dropdown(description='Task:', index=1, options=('sentiment-analysis', 'ner', 'fill_mask'), value='ner')"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "ddc51b71c6eb40e5ab60998664e6a857",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
"Text(value='', description='Your input:', placeholder='Enter something')"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[{'word': 'Paris', 'score': 0.9991844296455383, 'entity': 'I-LOC'}]\n",
|
||||
"[{'sequence': '<s> I\\'m from Paris.\"</s>', 'score': 0.224044069647789, 'token': 72}, {'sequence': \"<s> I'm from Paris.)</s>\", 'score': 0.16959427297115326, 'token': 1592}, {'sequence': \"<s> I'm from Paris.]</s>\", 'score': 0.10994981974363327, 'token': 21838}, {'sequence': '<s> I\\'m from Paris!\"</s>', 'score': 0.0706234946846962, 'token': 2901}, {'sequence': \"<s> I'm from Paris.</s>\", 'score': 0.0698278620839119, 'token': 4}]\n",
|
||||
"[{'sequence': \"<s> I'm from Paris and London</s>\", 'score': 0.12238534539937973, 'token': 928}, {'sequence': \"<s> I'm from Paris and Brussels</s>\", 'score': 0.07107886672019958, 'token': 6497}, {'sequence': \"<s> I'm from Paris and Belgium</s>\", 'score': 0.040912602096796036, 'token': 7320}, {'sequence': \"<s> I'm from Paris and Berlin</s>\", 'score': 0.039884064346551895, 'token': 5459}, {'sequence': \"<s> I'm from Paris and Melbourne</s>\", 'score': 0.038133684545755386, 'token': 5703}]\n",
|
||||
"[{'sequence': '<s> I like go to sleep</s>', 'score': 0.08942786604166031, 'token': 3581}, {'sequence': '<s> I like go to bed</s>', 'score': 0.07789064943790436, 'token': 3267}, {'sequence': '<s> I like go to concerts</s>', 'score': 0.06356740742921829, 'token': 12858}, {'sequence': '<s> I like go to school</s>', 'score': 0.03660670667886734, 'token': 334}, {'sequence': '<s> I like go to dinner</s>', 'score': 0.032155368477106094, 'token': 3630}]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"task = widgets.Dropdown(\n",
|
||||
" options=['sentiment-analysis', 'ner', 'fill_mask'],\n",
|
||||
" value='ner',\n",
|
||||
" description='Task:',\n",
|
||||
" disabled=False\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"input = widgets.Text(\n",
|
||||
" value='',\n",
|
||||
" placeholder='Enter something',\n",
|
||||
" description='Your input:',\n",
|
||||
" disabled=False\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"def forward(_):\n",
|
||||
" if len(input.value) > 0: \n",
|
||||
" if task.value == 'ner':\n",
|
||||
" output = nlp_token_class(input.value)\n",
|
||||
" elif task.value == 'sentiment-analysis':\n",
|
||||
" output = nlp_sentence_classif(input.value)\n",
|
||||
" else:\n",
|
||||
" if input.value.find('<mask>') == -1:\n",
|
||||
" output = nlp_fill(input.value + ' <mask>')\n",
|
||||
" else:\n",
|
||||
" output = nlp_fill(input.value) \n",
|
||||
" print(output)\n",
|
||||
"\n",
|
||||
"input.on_submit(forward)\n",
|
||||
"display(task, input)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 43,
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"is_executing": false,
|
||||
"name": "#%% Question Answering\n"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "5ae68677bd8a41f990355aa43840d3f8",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
"Textarea(value='Einstein is famous for the general theory of relativity', description='Context:', placeholder=…"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "14bcfd9a2c5a47e6b1383989ab7632c8",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
"Text(value='Why is Einstein famous for ?', description='Question:', placeholder='Enter something')"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"convert squad examples to features: 100%|██████████| 1/1 [00:00<00:00, 168.83it/s]\n",
|
||||
"add example index and unique id: 100%|██████████| 1/1 [00:00<00:00, 1919.59it/s]\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'score': 0.40340670623875496, 'start': 27, 'end': 54, 'answer': 'general theory of relativity'}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"context = widgets.Textarea(\n",
|
||||
" value='Einstein is famous for the general theory of relativity',\n",
|
||||
" placeholder='Enter something',\n",
|
||||
" description='Context:',\n",
|
||||
" disabled=False\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"query = widgets.Text(\n",
|
||||
" value='Why is Einstein famous for ?',\n",
|
||||
" placeholder='Enter something',\n",
|
||||
" description='Question:',\n",
|
||||
" disabled=False\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"def forward(_):\n",
|
||||
" if len(context.value) > 0 and len(query.value) > 0: \n",
|
||||
" output = nlp_qa(question=query.value, context=context.value) \n",
|
||||
" print(output)\n",
|
||||
"\n",
|
||||
"query.on_submit(forward)\n",
|
||||
"display(context, query)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.7.6"
|
||||
},
|
||||
"pycharm": {
|
||||
"stem_cell": {
|
||||
"cell_type": "raw",
|
||||
"source": [],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 1
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
17
notebooks/README.md
Normal file
17
notebooks/README.md
Normal file
@ -0,0 +1,17 @@
|
||||
# Transformers Notebooks
|
||||
|
||||
You can find here a list of the official notebooks provided by Hugging Face.
|
||||
|
||||
Also, we would like to list here interesting content created by the community.
|
||||
If you wrote some notebook(s) leveraging transformers and would like be listed here, please open a
|
||||
Pull Request and we'll review it so it can be included here.
|
||||
|
||||
|
||||
## Hugging Face's notebooks :hugs:
|
||||
|
||||
| Notebook | Description | |
|
||||
|:----------|:-------------:|------:|
|
||||
| [Getting Started Tokenizers](01-training_tokenizers.ipynb) | How to train and use your very own tokenizer |[](https://colab.research.google.com/github/huggingface/transformers/blob/docker-notebooks/notebooks/01-training-tokenizers.ipynb) |
|
||||
| [Getting Started Transformers](02-transformers.ipynb) | How to easily start using transformers | [](https://colab.research.google.com/github/huggingface/transformers/blob/docker-notebooks/notebooks/01-training-tokenizers.ipynb) |
|
||||
| [How to use Pipelines](03-pipelines.ipynb) | Simple and efficient way to use State-of-the-Art models on downstream tasks through transformers | [](https://colab.research.google.com/github/huggingface/transformers/blob/docker-notebooks/notebooks/01-training-tokenizers.ipynb) |
|
||||
| [How to train a language model](https://github.com/huggingface/blog/blob/master/notebooks/01_how_to_train.ipynb)| Highlight all the steps to effectively train Transformer model on custom data | [](https://colab.research.google.com/github/vochicong/blog/blob/fix-notebook-add-tokenizer-config/notebooks/01_how_to_train.ipynb)|
|
||||
Loading…
Reference in New Issue
Block a user