# Phi
## Overview
The Phi-1 model was proposed in [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li.
The Phi-1.5 model was proposed in [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
### Summary
In Phi-1 and Phi-1.5 papers, the authors showed how important the quality of the data is in training relative to the model size.
They selected high quality "textbook" data alongside with synthetically generated data for training their small sized Transformer
based model Phi-1 with 1.3B parameters. Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP.
They follow the same strategy for Phi-1.5 and created another 1.3B parameter model with performance on natural language tasks comparable
to models 5x larger, and surpassing most non-frontier LLMs. Phi-1.5 exhibits many of the traits of much larger LLMs such as the ability
to “think step by step” or perform some rudimentary in-context learning.
With these two experiments the authors successfully showed the huge impact of quality of training data when training machine learning models.
The abstract from the Phi-1 paper is the following:
*We introduce phi-1, a new large language model for code, with significantly smaller size than
competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on
8 A100s, using a selection of “textbook quality” data from the web (6B tokens) and synthetically
generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains
pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent
properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding
exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as
phi-1 that still achieves 45% on HumanEval.*
The abstract from the Phi-1.5 paper is the following:
*We continue the investigation into the power of smaller Transformer-based language models as
initiated by TinyStories – a 10 million parameter model that can produce coherent English – and
the follow-up work on phi-1, a 1.3 billion parameter model with Python coding performance close
to the state-of-the-art. The latter work proposed to use existing Large Language Models (LLMs) to
generate “textbook quality” data as a way to enhance the learning process compared to traditional
web data. We follow the “Textbooks Are All You Need” approach, focusing this time on common
sense reasoning in natural language, and create a new 1.3 billion parameter model named phi-1.5,
with performance on natural language tasks comparable to models 5x larger, and surpassing most
non-frontier LLMs on more complex reasoning tasks such as grade-school mathematics and basic
coding. More generally, phi-1.5 exhibits many of the traits of much larger LLMs, both good –such
as the ability to “think step by step” or perform some rudimentary in-context learning– and bad,
including hallucinations and the potential for toxic and biased generations –encouragingly though, we
are seeing improvement on that front thanks to the absence of web data. We open-source phi-1.5 to
promote further research on these urgent topics.*
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
The original code for Phi-1 and Phi-1.5 can be found [here](https://huggingface.co/microsoft/phi-1/blob/main/modeling_mixformer_sequential.py) and [here](https://huggingface.co/microsoft/phi-1_5/blob/main/modeling_mixformer_sequential.py) respectively.
The original code for Phi-2 can be found [here](https://huggingface.co/microsoft/phi-2).
## Usage tips
- This model is quite similar to `Llama` with the main difference in [`PhiDecoderLayer`], where they used [`PhiAttention`] and [`PhiMLP`] layers in parallel configuration.
- The tokenizer used for this model is identical to the [`CodeGenTokenizer`].
## How to use Phi-2
The current weights at [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) are not in proper order to be used with the library model. Until that is resolved, please use [susnato/phi-2](https://huggingface.co/susnato/phi-2) to load using the library `phi` model.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("susnato/phi-2")
>>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-2")
>>> inputs = tokenizer('Can you help me write a formal email to a potential business partner proposing a joint venture?', return_tensors="pt", return_attention_mask=False)
>>> outputs = model.generate(**inputs, max_length=30)
>>> text = tokenizer.batch_decode(outputs)[0]
>>> print(text)
'Can you help me write a formal email to a potential business partner proposing a joint venture?\nInput: Company A: ABC Inc.\nCompany B: XYZ Ltd.\nJoint Venture: A new online platform for e-commerce'
```
### Example :
```python
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer.
>>> model = PhiForCausalLM.from_pretrained("susnato/phi-1_5_dev")
>>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-1_5_dev")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'
```
## Combining Phi and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer and push the model and tokens to the GPU.
>>> model = PhiForCausalLM.from_pretrained("susnato/phi-1_5_dev", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda")
>>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-1_5_dev")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt").to("cuda")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'
```
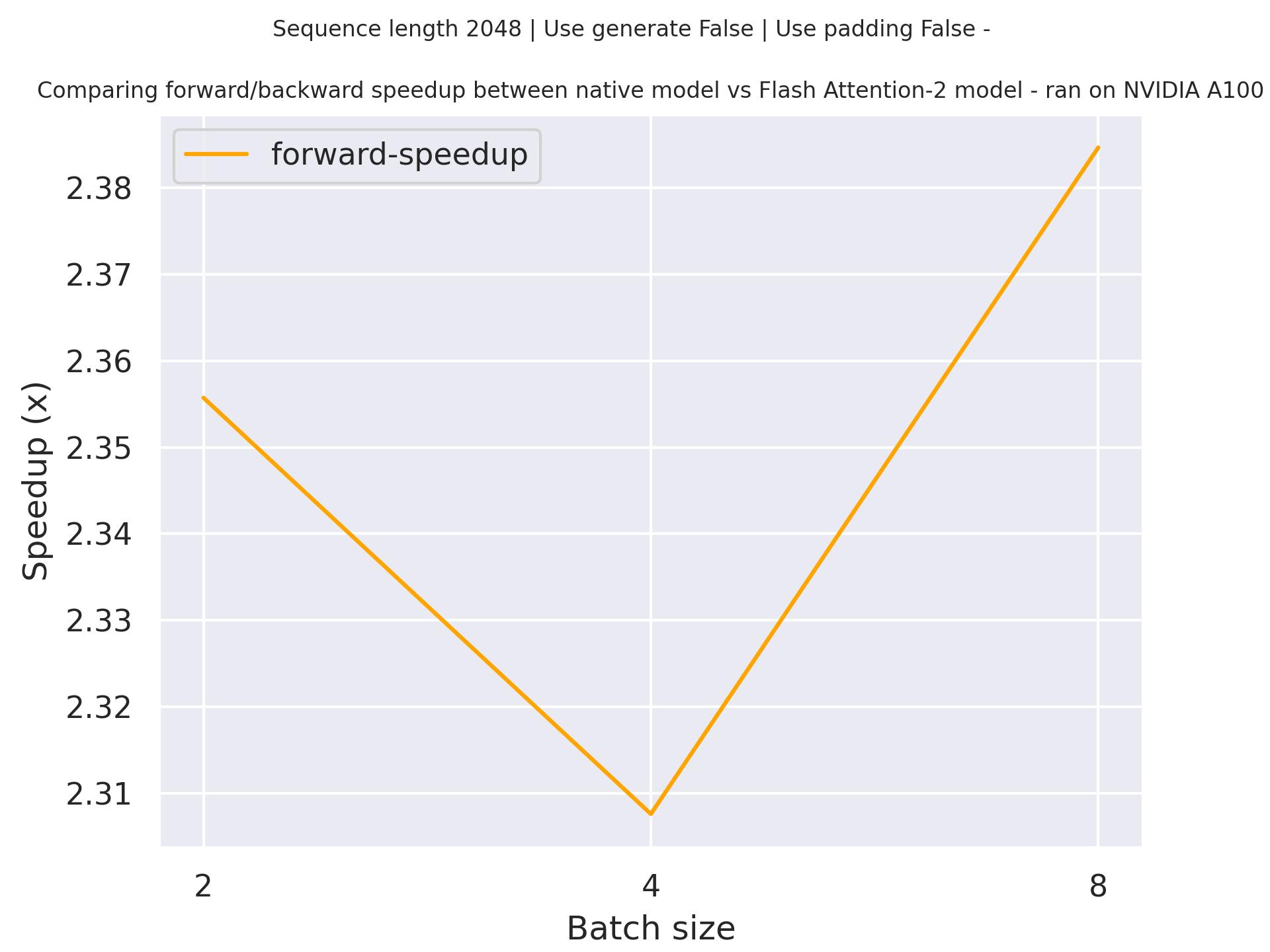
### Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `susnato/phi-1_dev` checkpoint and the Flash Attention 2 version of the model using a sequence length of 2048.
## PhiConfig
[[autodoc]] PhiConfig
## PhiModel
[[autodoc]] PhiModel
- forward
## PhiForCausalLM
[[autodoc]] PhiForCausalLM
- forward
- generate
## PhiForSequenceClassification
[[autodoc]] PhiForSequenceClassification
- forward
## PhiForTokenClassification
[[autodoc]] PhiForTokenClassification
- forward