# OpenAI GPT2
## Overview
OpenAI GPT-2 model was proposed in [Language Models are Unsupervised Multitask Learners](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) by Alec
Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever from [OpenAI](https://huggingface.co/openai). It's a causal (unidirectional)
transformer pretrained using language modeling on a very large corpus of ~40 GB of text data.
The abstract from the paper is the following:
*GPT-2 is a large transformer-based language model with 1.5 billion parameters, trained on a dataset[1] of 8 million
web pages. GPT-2 is trained with a simple objective: predict the next word, given all of the previous words within some
text. The diversity of the dataset causes this simple goal to contain naturally occurring demonstrations of many tasks
across diverse domains. GPT-2 is a direct scale-up of GPT, with more than 10X the parameters and trained on more than
10X the amount of data.*
[Write With Transformer](https://transformer.huggingface.co/doc/gpt2-large) is a webapp created and hosted by
Hugging Face showcasing the generative capabilities of several models. GPT-2 is one of them and is available in five
different sizes: small, medium, large, xl and a distilled version of the small checkpoint: *distilgpt-2*.
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://openai.com/blog/better-language-models/).
## Usage tips
- GPT-2 is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- GPT-2 was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
token in a sequence. Leveraging this feature allows GPT-2 to generate syntactically coherent text as it can be
observed in the *run_generation.py* example script.
- The model can take the *past_key_values* (for PyTorch) or *past* (for TF) as input, which is the previously computed
key/value attention pairs. Using this (*past_key_values* or *past*) value prevents the model from re-computing
pre-computed values in the context of text generation. For PyTorch, see *past_key_values* argument of the
[`GPT2Model.forward`] method, or for TF the *past* argument of the
[`TFGPT2Model.call`] method for more information on its usage.
- Enabling the *scale_attn_by_inverse_layer_idx* and *reorder_and_upcast_attn* flags will apply the training stability
improvements from [Mistral](https://github.com/stanford-crfm/mistral/) (for PyTorch only).
## Usage example
The `generate()` method can be used to generate text using GPT2 model.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("gpt2")
>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
>>> prompt = "GPT2 is a model developed by OpenAI."
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
```
## Using Flash Attention 2
Flash Attention 2 is a faster, optimized version of the attention scores computation which relies on `cuda` kernels.
### Installation
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features). If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered [above](https://huggingface.co/docs/transformers/main/en/model_doc/bark#using-better-transformer).
Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
```bash
pip install -U flash-attn --no-build-isolation
```
### Usage
To load a model using Flash Attention 2, we can pass the argument `attn_implementation="flash_attention_2"` to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). We'll also load the model in half-precision (e.g. `torch.float16`), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("gpt2", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
>>> prompt = "def hello_world():"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
```
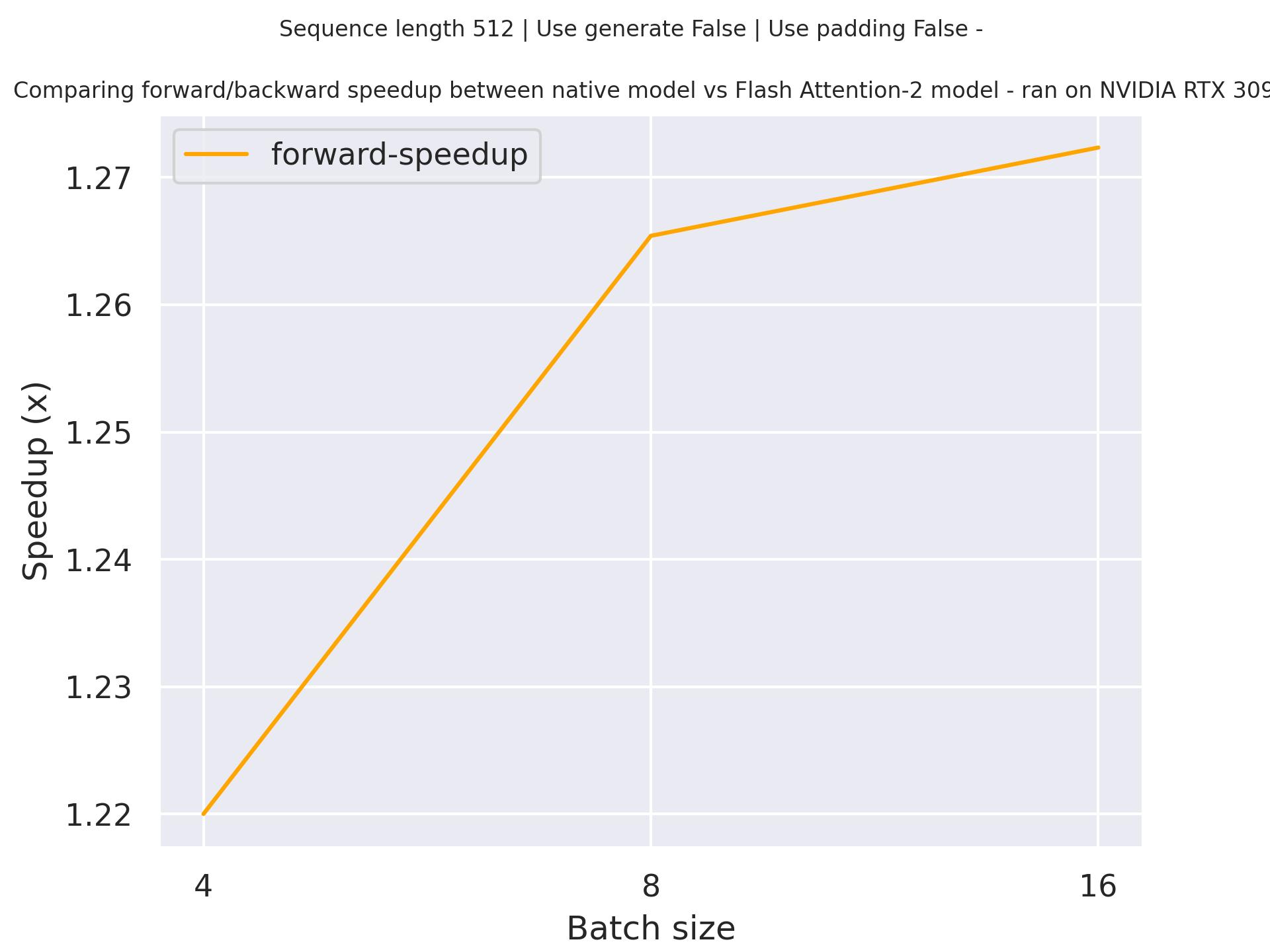
### Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `gpt2` checkpoint and the Flash Attention 2 version of the model using a sequence length of 512.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GPT2. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- A blog on how to [Finetune a non-English GPT-2 Model with Hugging Face](https://www.philschmid.de/fine-tune-a-non-english-gpt-2-model-with-huggingface).
- A blog on [How to generate text: using different decoding methods for language generation with Transformers](https://huggingface.co/blog/how-to-generate) with GPT-2.
- A blog on [Training CodeParrot 🦜 from Scratch](https://huggingface.co/blog/codeparrot), a large GPT-2 model.
- A blog on [Faster Text Generation with TensorFlow and XLA](https://huggingface.co/blog/tf-xla-generate) with GPT-2.
- A blog on [How to train a Language Model with Megatron-LM](https://huggingface.co/blog/megatron-training) with a GPT-2 model.
- A notebook on how to [finetune GPT2 to generate lyrics in the style of your favorite artist](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb). 🌎
- A notebook on how to [finetune GPT2 to generate tweets in the style of your favorite Twitter user](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb). 🌎
- [Causal language modeling](https://huggingface.co/course/en/chapter7/6?fw=pt#training-a-causal-language-model-from-scratch) chapter of the 🤗 Hugging Face Course.
- [`GPT2LMHeadModel`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling), [text generation example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation), and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFGPT2LMHeadModel`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_clmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxGPT2LMHeadModel`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/causal_language_modeling_flax.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
## GPT2Config
[[autodoc]] GPT2Config
## GPT2Tokenizer
[[autodoc]] GPT2Tokenizer
- save_vocabulary
## GPT2TokenizerFast
[[autodoc]] GPT2TokenizerFast
## GPT2 specific outputs
[[autodoc]] models.gpt2.modeling_gpt2.GPT2DoubleHeadsModelOutput
[[autodoc]] models.gpt2.modeling_tf_gpt2.TFGPT2DoubleHeadsModelOutput
## GPT2Model
[[autodoc]] GPT2Model
- forward
## GPT2LMHeadModel
[[autodoc]] GPT2LMHeadModel
- forward
## GPT2DoubleHeadsModel
[[autodoc]] GPT2DoubleHeadsModel
- forward
## GPT2ForQuestionAnswering
[[autodoc]] GPT2ForQuestionAnswering
- forward
## GPT2ForSequenceClassification
[[autodoc]] GPT2ForSequenceClassification
- forward
## GPT2ForTokenClassification
[[autodoc]] GPT2ForTokenClassification
- forward
## TFGPT2Model
[[autodoc]] TFGPT2Model
- call
## TFGPT2LMHeadModel
[[autodoc]] TFGPT2LMHeadModel
- call
## TFGPT2DoubleHeadsModel
[[autodoc]] TFGPT2DoubleHeadsModel
- call
## TFGPT2ForSequenceClassification
[[autodoc]] TFGPT2ForSequenceClassification
- call
## TFSequenceClassifierOutputWithPast
[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutputWithPast
## TFGPT2Tokenizer
[[autodoc]] TFGPT2Tokenizer
## FlaxGPT2Model
[[autodoc]] FlaxGPT2Model
- __call__
## FlaxGPT2LMHeadModel
[[autodoc]] FlaxGPT2LMHeadModel
- __call__