# Neighborhood Attention Transformer
## Overview
NAT was proposed in [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143)
by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
It is a hierarchical vision transformer based on Neighborhood Attention, a sliding-window self attention pattern.
The abstract from the paper is the following:
*We present Neighborhood Attention (NA), the first efficient and scalable sliding-window attention mechanism for vision.
NA is a pixel-wise operation, localizing self attention (SA) to the nearest neighboring pixels, and therefore enjoys a
linear time and space complexity compared to the quadratic complexity of SA. The sliding-window pattern allows NA's
receptive field to grow without needing extra pixel shifts, and preserves translational equivariance, unlike
Swin Transformer's Window Self Attention (WSA). We develop NATTEN (Neighborhood Attention Extension), a Python package
with efficient C++ and CUDA kernels, which allows NA to run up to 40% faster than Swin's WSA while using up to 25% less
memory. We further present Neighborhood Attention Transformer (NAT), a new hierarchical transformer design based on NA
that boosts image classification and downstream vision performance. Experimental results on NAT are competitive;
NAT-Tiny reaches 83.2% top-1 accuracy on ImageNet, 51.4% mAP on MS-COCO and 48.4% mIoU on ADE20K, which is 1.9%
ImageNet accuracy, 1.0% COCO mAP, and 2.6% ADE20K mIoU improvement over a Swin model with similar size. *
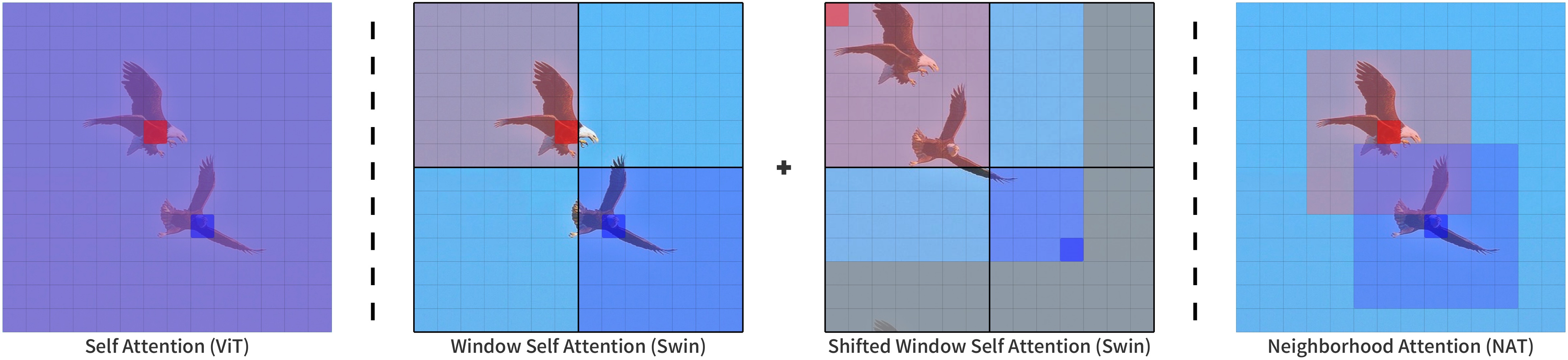 Neighborhood Attention compared to other attention patterns.
Taken from the original paper.
This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Usage tips
- One can use the [`AutoImageProcessor`] API to prepare images for the model.
- NAT can be used as a *backbone*. When `output_hidden_states = True`,
it will output both `hidden_states` and `reshaped_hidden_states`.
The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than
`(batch_size, height, width, num_channels)`.
Notes:
- NAT depends on [NATTEN](https://github.com/SHI-Labs/NATTEN/)'s implementation of Neighborhood Attention.
You can install it with pre-built wheels for Linux by referring to [shi-labs.com/natten](https://shi-labs.com/natten),
or build on your system by running `pip install natten`.
Note that the latter will likely take time to compile. NATTEN does not support Windows devices yet.
- Patch size of 4 is only supported at the moment.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with NAT.
- [`NatForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## NatConfig
[[autodoc]] NatConfig
## NatModel
[[autodoc]] NatModel
- forward
## NatForImageClassification
[[autodoc]] NatForImageClassification
- forward
Neighborhood Attention compared to other attention patterns.
Taken from the original paper.
This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Usage tips
- One can use the [`AutoImageProcessor`] API to prepare images for the model.
- NAT can be used as a *backbone*. When `output_hidden_states = True`,
it will output both `hidden_states` and `reshaped_hidden_states`.
The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than
`(batch_size, height, width, num_channels)`.
Notes:
- NAT depends on [NATTEN](https://github.com/SHI-Labs/NATTEN/)'s implementation of Neighborhood Attention.
You can install it with pre-built wheels for Linux by referring to [shi-labs.com/natten](https://shi-labs.com/natten),
or build on your system by running `pip install natten`.
Note that the latter will likely take time to compile. NATTEN does not support Windows devices yet.
- Patch size of 4 is only supported at the moment.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with NAT.
- [`NatForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## NatConfig
[[autodoc]] NatConfig
## NatModel
[[autodoc]] NatModel
- forward
## NatForImageClassification
[[autodoc]] NatForImageClassification
- forward