# Nougat
## Overview
The Nougat model was proposed in [Nougat: Neural Optical Understanding for Academic Documents](https://huggingface.co/papers/2308.13418) by
Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic. Nougat uses the same architecture as [Donut](donut), meaning an image Transformer
encoder and an autoregressive text Transformer decoder to translate scientific PDFs to markdown, enabling easier access to them.
The abstract from the paper is the following:
*Scientific knowledge is predominantly stored in books and scientific journals, often in the form of PDFs. However, the PDF format leads to a loss of semantic information, particularly for mathematical expressions. We propose Nougat (Neural Optical Understanding for Academic Documents), a Visual Transformer model that performs an Optical Character Recognition (OCR) task for processing scientific documents into a markup language, and demonstrate the effectiveness of our model on a new dataset of scientific documents. The proposed approach offers a promising solution to enhance the accessibility of scientific knowledge in the digital age, by bridging the gap between human-readable documents and machine-readable text. We release the models and code to accelerate future work on scientific text recognition.*
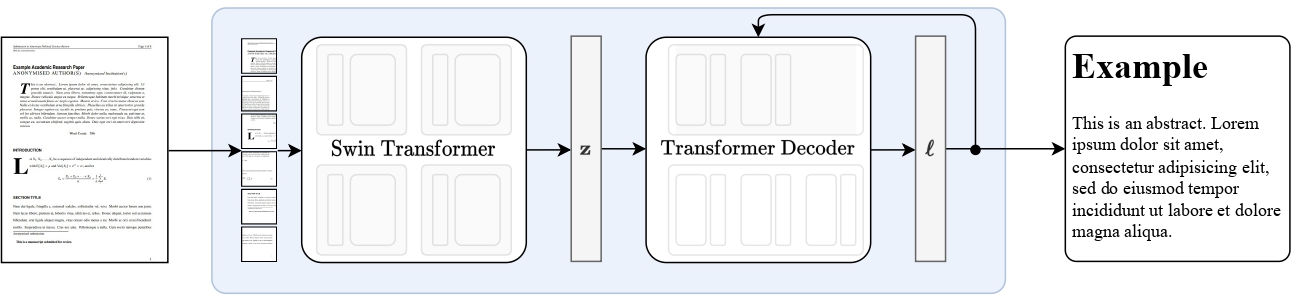 Nougat high-level overview. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/facebookresearch/nougat).
## Usage tips
- The quickest way to get started with Nougat is by checking the [tutorial
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Nougat), which show how to use the model
at inference time as well as fine-tuning on custom data.
- Nougat is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework. The model is identical to [Donut](donut) in terms of architecture.
## Inference
Nougat's [`VisionEncoderDecoder`] model accepts images as input and makes use of
[`~generation.GenerationMixin.generate`] to autoregressively generate text given the input image.
The [`NougatImageProcessor`] class is responsible for preprocessing the input image and
[`NougatTokenizerFast`] decodes the generated target tokens to the target string. The
[`NougatProcessor`] wraps [`NougatImageProcessor`] and [`NougatTokenizerFast`] classes
into a single instance to both extract the input features and decode the predicted token ids.
- Step-by-step PDF transcription
```py
>>> from huggingface_hub import hf_hub_download
>>> import re
>>> from PIL import Image
>>> from transformers import NougatProcessor, VisionEncoderDecoderModel
>>> from datasets import load_dataset
>>> import torch
>>> processor = NougatProcessor.from_pretrained("facebook/nougat-base")
>>> model = VisionEncoderDecoderModel.from_pretrained("facebook/nougat-base")
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> model.to(device) # doctest: +IGNORE_RESULT
>>> # prepare PDF image for the model
>>> filepath = hf_hub_download(repo_id="hf-internal-testing/fixtures_docvqa", filename="nougat_paper.png", repo_type="dataset")
>>> image = Image.open(filepath)
>>> pixel_values = processor(image, return_tensors="pt").pixel_values
>>> # generate transcription (here we only generate 30 tokens)
>>> outputs = model.generate(
... pixel_values.to(device),
... min_length=1,
... max_new_tokens=30,
... bad_words_ids=[[processor.tokenizer.unk_token_id]],
... )
>>> sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
>>> sequence = processor.post_process_generation(sequence, fix_markdown=False)
>>> # note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequence
>>> print(repr(sequence))
'\n\n# Nougat: Neural Optical Understanding for Academic Documents\n\n Lukas Blecher\n\nCorrespondence to: lblecher@'
```
See the [model hub](https://huggingface.co/models?filter=nougat) to look for Nougat checkpoints.
The model is identical to [Donut](donut) in terms of architecture.
## NougatImageProcessor
[[autodoc]] NougatImageProcessor
- preprocess
## NougatTokenizerFast
[[autodoc]] NougatTokenizerFast
## NougatProcessor
[[autodoc]] NougatProcessor
- __call__
- from_pretrained
- save_pretrained
- batch_decode
- decode
- post_process_generation
Nougat high-level overview. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/facebookresearch/nougat).
## Usage tips
- The quickest way to get started with Nougat is by checking the [tutorial
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Nougat), which show how to use the model
at inference time as well as fine-tuning on custom data.
- Nougat is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework. The model is identical to [Donut](donut) in terms of architecture.
## Inference
Nougat's [`VisionEncoderDecoder`] model accepts images as input and makes use of
[`~generation.GenerationMixin.generate`] to autoregressively generate text given the input image.
The [`NougatImageProcessor`] class is responsible for preprocessing the input image and
[`NougatTokenizerFast`] decodes the generated target tokens to the target string. The
[`NougatProcessor`] wraps [`NougatImageProcessor`] and [`NougatTokenizerFast`] classes
into a single instance to both extract the input features and decode the predicted token ids.
- Step-by-step PDF transcription
```py
>>> from huggingface_hub import hf_hub_download
>>> import re
>>> from PIL import Image
>>> from transformers import NougatProcessor, VisionEncoderDecoderModel
>>> from datasets import load_dataset
>>> import torch
>>> processor = NougatProcessor.from_pretrained("facebook/nougat-base")
>>> model = VisionEncoderDecoderModel.from_pretrained("facebook/nougat-base")
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> model.to(device) # doctest: +IGNORE_RESULT
>>> # prepare PDF image for the model
>>> filepath = hf_hub_download(repo_id="hf-internal-testing/fixtures_docvqa", filename="nougat_paper.png", repo_type="dataset")
>>> image = Image.open(filepath)
>>> pixel_values = processor(image, return_tensors="pt").pixel_values
>>> # generate transcription (here we only generate 30 tokens)
>>> outputs = model.generate(
... pixel_values.to(device),
... min_length=1,
... max_new_tokens=30,
... bad_words_ids=[[processor.tokenizer.unk_token_id]],
... )
>>> sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
>>> sequence = processor.post_process_generation(sequence, fix_markdown=False)
>>> # note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequence
>>> print(repr(sequence))
'\n\n# Nougat: Neural Optical Understanding for Academic Documents\n\n Lukas Blecher\n\nCorrespondence to: lblecher@'
```
See the [model hub](https://huggingface.co/models?filter=nougat) to look for Nougat checkpoints.
The model is identical to [Donut](donut) in terms of architecture.
## NougatImageProcessor
[[autodoc]] NougatImageProcessor
- preprocess
## NougatTokenizerFast
[[autodoc]] NougatTokenizerFast
## NougatProcessor
[[autodoc]] NougatProcessor
- __call__
- from_pretrained
- save_pretrained
- batch_decode
- decode
- post_process_generation