# M2M100
## Overview
The M2M100 model was proposed in [Beyond English-Centric Multilingual Machine Translation](https://huggingface.co/papers/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky,
Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy
Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
The abstract from the paper is the following:
*Existing work in translation demonstrated the potential of massively multilingual machine translation by training a
single model able to translate between any pair of languages. However, much of this work is English-Centric by training
only on data which was translated from or to English. While this is supported by large sources of training data, it
does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation
model that can translate directly between any pair of 100 languages. We build and open source a training dataset that
covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how
to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters
to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly
translating between non-English directions while performing competitively to the best single systems of WMT. We
open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.*
This model was contributed by [valhalla](https://huggingface.co/valhalla).
## Usage tips and examples
M2M100 is a multilingual encoder-decoder (seq-to-seq) model primarily intended for translation tasks. As the model is
multilingual it expects the sequences in a certain format: A special language id token is used as prefix in both the
source and target text. The source text format is `[lang_code] X [eos]`, where `lang_code` is source language
id for source text and target language id for target text, with `X` being the source or target text.
> [!NOTE]
> The `head_mask` argument is ignored when using all attention implementation other than "eager". If you have a `head_mask` and want it to have effect, load the model with `XXXModel.from_pretrained(model_id, attn_implementation="eager")`
The [`M2M100Tokenizer`] depends on `sentencepiece` so be sure to install it before running the
examples. To install `sentencepiece` run `pip install sentencepiece`.
**Supervised Training**
```python
from transformers import M2M100Config, M2M100ForConditionalGeneration, M2M100Tokenizer
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="en", tgt_lang="fr")
src_text = "Life is like a box of chocolates."
tgt_text = "La vie est comme une boîte de chocolat."
model_inputs = tokenizer(src_text, text_target=tgt_text, return_tensors="pt")
loss = model(**model_inputs).loss # forward pass
```
**Generation**
M2M100 uses the `eos_token_id` as the `decoder_start_token_id` for generation with the target language id
being forced as the first generated token. To force the target language id as the first generated token, pass the
*forced_bos_token_id* parameter to the *generate* method. The following example shows how to translate between
Hindi to French and Chinese to English using the *facebook/m2m100_418M* checkpoint.
```python
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
>>> chinese_text = "生活就像一盒巧克力。"
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
>>> # translate Hindi to French
>>> tokenizer.src_lang = "hi"
>>> encoded_hi = tokenizer(hi_text, return_tensors="pt")
>>> generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"La vie est comme une boîte de chocolat."
>>> # translate Chinese to English
>>> tokenizer.src_lang = "zh"
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Life is like a box of chocolate."
```
## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## M2M100Config
[[autodoc]] M2M100Config
## M2M100Tokenizer
[[autodoc]] M2M100Tokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## M2M100Model
[[autodoc]] M2M100Model
- forward
## M2M100ForConditionalGeneration
[[autodoc]] M2M100ForConditionalGeneration
- forward
## Using Flash Attention 2
Flash Attention 2 is a faster, optimized version of the attention scores computation which relies on `cuda` kernels.
### Installation
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features).
Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
```bash
pip install -U flash-attn --no-build-isolation
```
### Usage
To load a model using Flash Attention 2, we can pass the argument `attn_implementation="flash_attention_2"` to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). You can use either `torch.float16` or `torch.bfloat16` precision.
```python
>>> import torch
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda").eval()
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
>>> # translate Hindi to French
>>> hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
>>> tokenizer.src_lang = "hi"
>>> encoded_hi = tokenizer(hi_text, return_tensors="pt").to("cuda")
>>> generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"La vie est comme une boîte de chocolat."
```
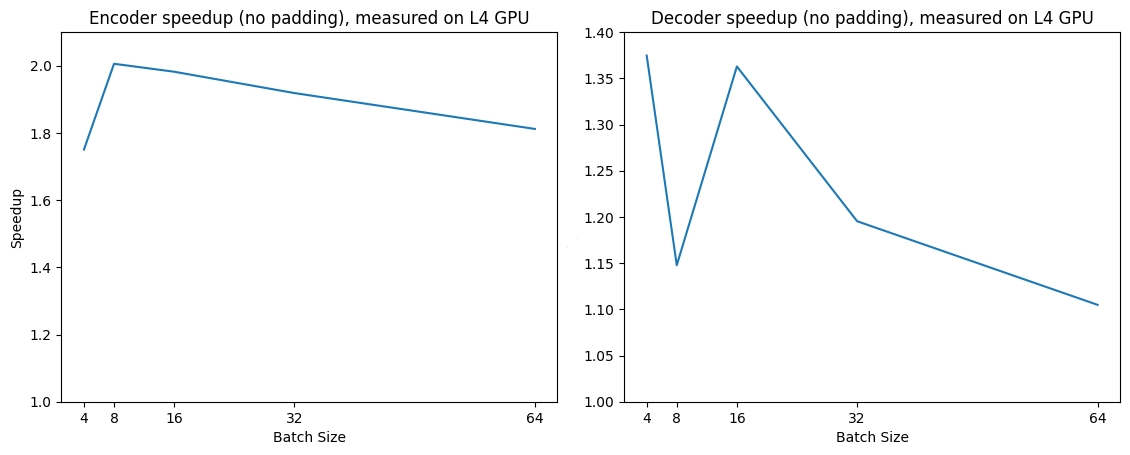
### Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation and the Flash Attention 2.
## Using Scaled Dot Product Attention (SDPA)
PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
page for more information.
SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
```python
from transformers import M2M100ForConditionalGeneration
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M", torch_dtype=torch.float16, attn_implementation="sdpa")
...
```
For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).