# Swin2SR [[swin2sr]]
## 개요 [[overview]]
Swin2SR 모델은 Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte가 제안한 논문 [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345)에서 소개되었습니다.
Swin2SR은 [SwinIR](https://github.com/JingyunLiang/SwinIR/) 모델을 개선하고자 [Swin Transformer v2](swinv2) 레이어를 도입함으로써, 훈련 불안정성, 사전 훈련과 미세 조정 간의 해상도 차이, 그리고 데이터 의존성 문제를 완화시킵니다.
논문의 초록은 다음과 같습니다:
*압축은 스트리밍 서비스, 가상 현실, 비디오 게임과 같은 대역폭이 제한된 시스템을 통해 이미지와 영상을 효율적으로 전송하고 저장하는 데 중요한 역할을 합니다. 하지만 압축은 필연적으로 원본 정보의 손실과 아티팩트를 초래하며, 이는 시각적 품질을 심각하게 저하시킬 수 있습니다. 이러한 이유로, 압축된 이미지의 품질 향상은 활발한 연구 주제가 되고 있습니다. 현재 대부분의 최첨단 이미지 복원 방법은 합성곱 신경망을 기반으로 하지만, SwinIR과 같은 트랜스포머 기반 방법들도 이 작업에서 인상적인 성능을 보여주고 있습니다. 이번 논문에서는 Swin Transformer V2를 사용해 SwinIR을 개선하여 이미지 초해상도 작업, 특히 압축된 입력 시나리오에서 성능을 향상시키고자 합니다. 이 방법을 통해 트랜스포머 비전 모델을 훈련할 때 발생하는 주요 문제들, 예를 들어 훈련 불안정성, 사전 훈련과 미세 조정 간 해상도 차이, 그리고 데이터 의존성을 해결할 수 있습니다. 우리는 JPEG 압축 아티팩트 제거, 이미지 초해상도(클래식 및 경량), 그리고 압축된 이미지 초해상도라는 세 가지 대표적인 작업에서 실험을 수행했습니다. 실험 결과, 우리의 방법인 Swin2SR은 SwinIR의 훈련 수렴성과 성능을 향상시킬 수 있으며, "AIM 2022 Challenge on Super-Resolution of Compressed Image and Video"에서 상위 5위 솔루션으로 선정되었습니다.*
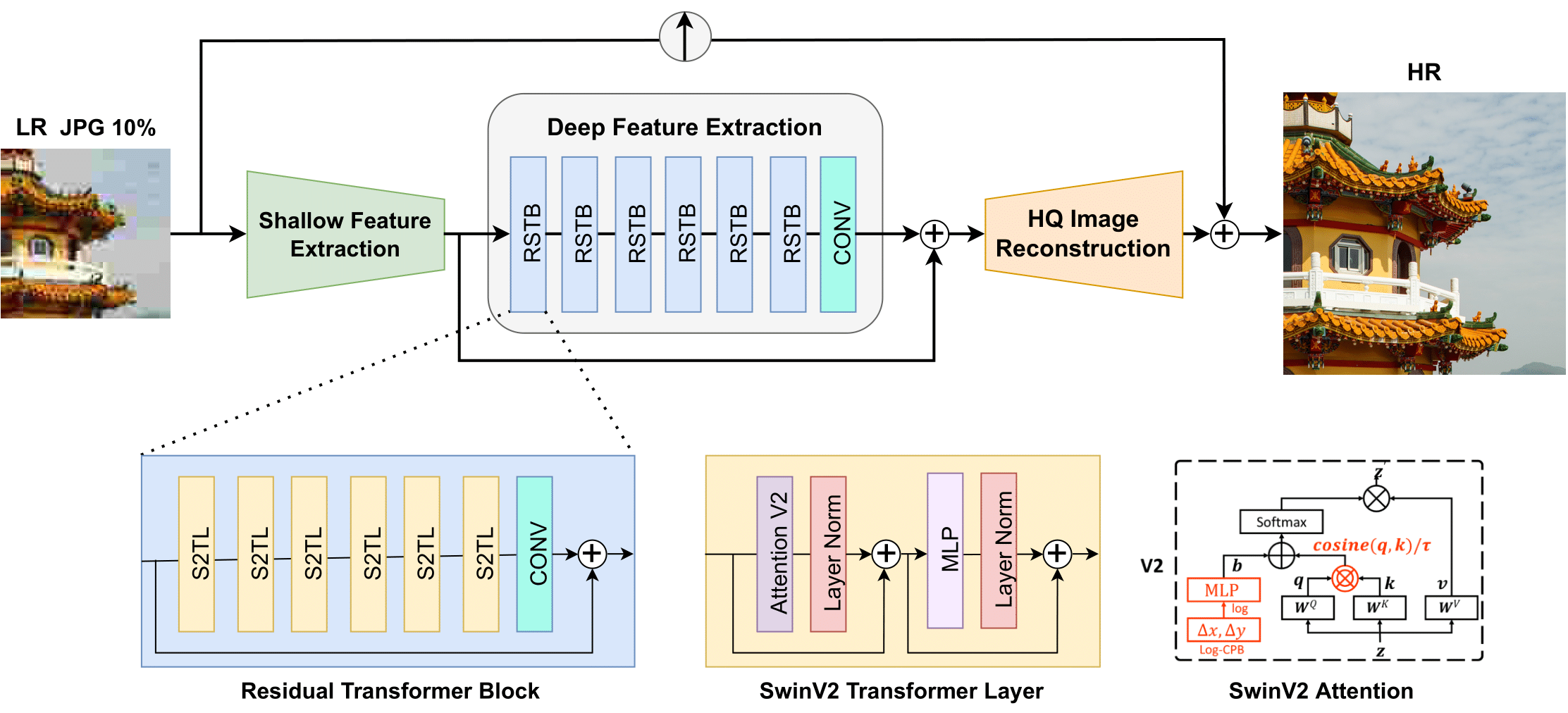 Swin2SR 아키텍처. 원본 논문에서 발췌.
이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여하였습니다.
원본 코드는 [여기](https://github.com/mv-lab/swin2sr)에서 확인할 수 있습니다.
## 리소스 [[resources]]
Swin2SR demo notebook은 [여기](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR)에서 확인할 수 있습니다.
SwinSR을 활용한 image super-resolution demo space는 [여기](https://huggingface.co/spaces/jjourney1125/swin2sr)에서 확인할 수 있습니다.
## Swin2SRImageProcessor [[transformers.Swin2SRImageProcessor]]
[[autodoc]] Swin2SRImageProcessor
- preprocess
## Swin2SRConfig [[transformers.Swin2SRConfig]]
[[autodoc]] Swin2SRConfig
## Swin2SRModel [[transformers.Swin2SRModel]]
[[autodoc]] Swin2SRModel
- forward
## Swin2SRForImageSuperResolution [[transformers.Swin2SRForImageSuperResolution]]
[[autodoc]] Swin2SRForImageSuperResolution
- forward
Swin2SR 아키텍처. 원본 논문에서 발췌.
이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여하였습니다.
원본 코드는 [여기](https://github.com/mv-lab/swin2sr)에서 확인할 수 있습니다.
## 리소스 [[resources]]
Swin2SR demo notebook은 [여기](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR)에서 확인할 수 있습니다.
SwinSR을 활용한 image super-resolution demo space는 [여기](https://huggingface.co/spaces/jjourney1125/swin2sr)에서 확인할 수 있습니다.
## Swin2SRImageProcessor [[transformers.Swin2SRImageProcessor]]
[[autodoc]] Swin2SRImageProcessor
- preprocess
## Swin2SRConfig [[transformers.Swin2SRConfig]]
[[autodoc]] Swin2SRConfig
## Swin2SRModel [[transformers.Swin2SRModel]]
[[autodoc]] Swin2SRModel
- forward
## Swin2SRForImageSuperResolution [[transformers.Swin2SRForImageSuperResolution]]
[[autodoc]] Swin2SRForImageSuperResolution
- forward