# ZoeDepth
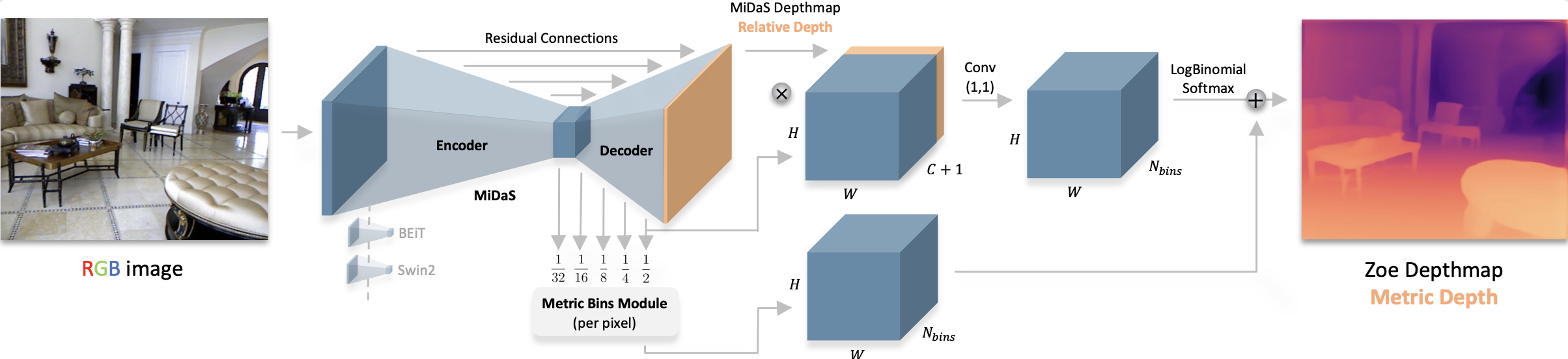
[ZoeDepth](https://huggingface.co/papers/2302.12288) is a depth estimation model that combines the generalization performance of relative depth estimation (how far objects are from each other) and metric depth estimation (precise depth measurement on metric scale) from a single image. It is pre-trained on 12 datasets using relative depth and 2 datasets (NYU Depth v2 and KITTI) for metric accuracy. A lightweight head with a metric bin module for each domain is used, and during inference, it automatically selects the appropriate head for each input image with a latent classifier.
 You can find all the original ZoeDepth checkpoints under the [Intel](https://huggingface.co/Intel?search=zoedepth) organization.
The example below demonstrates how to estimate depth with [`Pipeline`] or the [`AutoModel`] class.
```py
import requests
import torch
from transformers import pipeline
from PIL import Image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
pipeline = pipeline(
task="depth-estimation",
model="Intel/zoedepth-nyu-kitti",
torch_dtype=torch.float16,
device=0
)
results = pipeline(image)
results["depth"]
```
```py
import torch
import requests
from PIL import Image
from transformers import AutoModelForDepthEstimation, AutoImageProcessor
image_processor = AutoImageProcessor.from_pretrained(
"Intel/zoedepth-nyu-kitti"
)
model = AutoModelForDepthEstimation.from_pretrained(
"Intel/zoedepth-nyu-kitti",
device_map="auto"
)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = image_processor(image, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model(inputs)
# interpolate to original size and visualize the prediction
## ZoeDepth dynamically pads the input image, so pass the original image size as argument
## to `post_process_depth_estimation` to remove the padding and resize to original dimensions.
post_processed_output = image_processor.post_process_depth_estimation(
outputs,
source_sizes=[(image.height, image.width)],
)
predicted_depth = post_processed_output[0]["predicted_depth"]
depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
depth = depth.detach().cpu().numpy() * 255
Image.fromarray(depth.astype("uint8"))
```
## Notes
- In the [original implementation](https://github.com/isl-org/ZoeDepth/blob/edb6daf45458569e24f50250ef1ed08c015f17a7/zoedepth/models/depth_model.py#L131) ZoeDepth performs inference on both the original and flipped images and averages the results. The `post_process_depth_estimation` function handles this by passing the flipped outputs to the optional `outputs_flipped` argument as shown below.
```py
with torch.no_grad():
outputs = model(pixel_values)
outputs_flipped = model(pixel_values=torch.flip(inputs.pixel_values, dims=[3]))
post_processed_output = image_processor.post_process_depth_estimation(
outputs,
source_sizes=[(image.height, image.width)],
outputs_flipped=outputs_flipped,
)
```
## Resources
- Refer to this [notebook](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ZoeDepth) for an inference example.
## ZoeDepthConfig
[[autodoc]] ZoeDepthConfig
## ZoeDepthImageProcessor
[[autodoc]] ZoeDepthImageProcessor
- preprocess
## ZoeDepthForDepthEstimation
[[autodoc]] ZoeDepthForDepthEstimation
- forward
You can find all the original ZoeDepth checkpoints under the [Intel](https://huggingface.co/Intel?search=zoedepth) organization.
The example below demonstrates how to estimate depth with [`Pipeline`] or the [`AutoModel`] class.
```py
import requests
import torch
from transformers import pipeline
from PIL import Image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
pipeline = pipeline(
task="depth-estimation",
model="Intel/zoedepth-nyu-kitti",
torch_dtype=torch.float16,
device=0
)
results = pipeline(image)
results["depth"]
```
```py
import torch
import requests
from PIL import Image
from transformers import AutoModelForDepthEstimation, AutoImageProcessor
image_processor = AutoImageProcessor.from_pretrained(
"Intel/zoedepth-nyu-kitti"
)
model = AutoModelForDepthEstimation.from_pretrained(
"Intel/zoedepth-nyu-kitti",
device_map="auto"
)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = image_processor(image, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model(inputs)
# interpolate to original size and visualize the prediction
## ZoeDepth dynamically pads the input image, so pass the original image size as argument
## to `post_process_depth_estimation` to remove the padding and resize to original dimensions.
post_processed_output = image_processor.post_process_depth_estimation(
outputs,
source_sizes=[(image.height, image.width)],
)
predicted_depth = post_processed_output[0]["predicted_depth"]
depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
depth = depth.detach().cpu().numpy() * 255
Image.fromarray(depth.astype("uint8"))
```
## Notes
- In the [original implementation](https://github.com/isl-org/ZoeDepth/blob/edb6daf45458569e24f50250ef1ed08c015f17a7/zoedepth/models/depth_model.py#L131) ZoeDepth performs inference on both the original and flipped images and averages the results. The `post_process_depth_estimation` function handles this by passing the flipped outputs to the optional `outputs_flipped` argument as shown below.
```py
with torch.no_grad():
outputs = model(pixel_values)
outputs_flipped = model(pixel_values=torch.flip(inputs.pixel_values, dims=[3]))
post_processed_output = image_processor.post_process_depth_estimation(
outputs,
source_sizes=[(image.height, image.width)],
outputs_flipped=outputs_flipped,
)
```
## Resources
- Refer to this [notebook](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ZoeDepth) for an inference example.
## ZoeDepthConfig
[[autodoc]] ZoeDepthConfig
## ZoeDepthImageProcessor
[[autodoc]] ZoeDepthImageProcessor
- preprocess
## ZoeDepthForDepthEstimation
[[autodoc]] ZoeDepthForDepthEstimation
- forward