# GPT Neo
## Overview
The GPTNeo model was released in the [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) repository by Sid
Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy. It is a GPT2 like causal language model trained on the
[Pile](https://pile.eleuther.ai/) dataset.
The architecture is similar to GPT2 except that GPT Neo uses local attention in every other layer with a window size of
256 tokens.
This model was contributed by [valhalla](https://huggingface.co/valhalla).
## Usage example
The `generate()` method can be used to generate text using GPT Neo model.
```python
>>> from transformers import GPTNeoForCausalLM, GPT2Tokenizer
>>> model = GPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> tokenizer = GPT2Tokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> prompt = (
... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
... "researchers was the fact that the unicorns spoke perfect English."
... )
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
```
## Combining GPT-Neo and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature, and make sure your hardware is compatible with Flash-Attention 2. More details are available [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2) concerning the installation.
Make sure as well to load your model in half-precision (e.g. `torch.float16`).
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-2.7B", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-2.7B")
>>> prompt = "def hello_world():"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"def hello_world():\n >>> run_script("hello.py")\n >>> exit(0)\n<|endoftext|>"
```
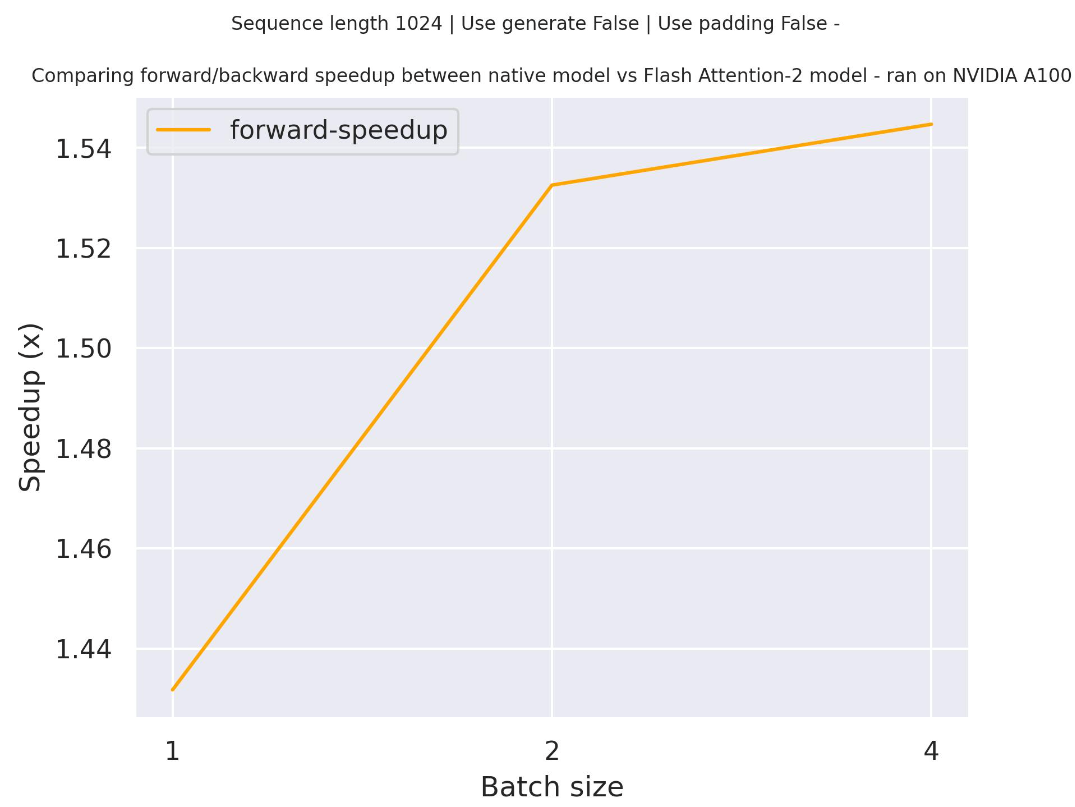
### Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `EleutherAI/gpt-neo-2.7B` checkpoint and the Flash Attention 2 version of the model.
Note that for GPT-Neo it is not possible to train / run on very long context as the max [position embeddings](https://huggingface.co/EleutherAI/gpt-neo-2.7B/blob/main/config.json#L58 ) is limited to 2048 - but this is applicable to all gpt-neo models and not specific to FA-2
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
## GPTNeoConfig
[[autodoc]] GPTNeoConfig
## GPTNeoModel
[[autodoc]] GPTNeoModel
- forward
## GPTNeoForCausalLM
[[autodoc]] GPTNeoForCausalLM
- forward
## GPTNeoForQuestionAnswering
[[autodoc]] GPTNeoForQuestionAnswering
- forward
## GPTNeoForSequenceClassification
[[autodoc]] GPTNeoForSequenceClassification
- forward
## GPTNeoForTokenClassification
[[autodoc]] GPTNeoForTokenClassification
- forward
## FlaxGPTNeoModel
[[autodoc]] FlaxGPTNeoModel
- __call__
## FlaxGPTNeoForCausalLM
[[autodoc]] FlaxGPTNeoForCausalLM
- __call__