# DiT
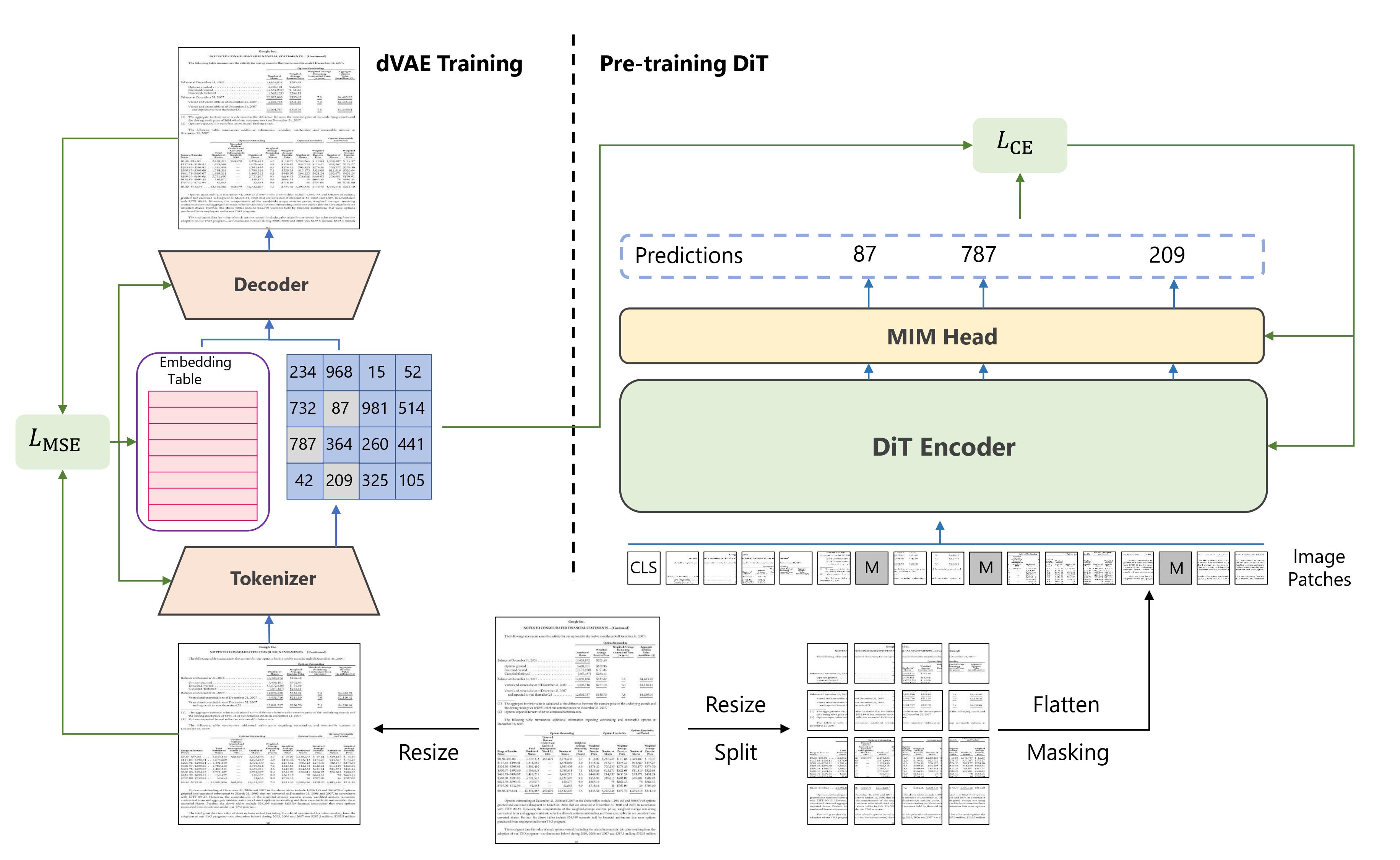
[DiT](https://huggingface.co/papers/2203.02378) is an image transformer pretrained on large-scale unlabeled document images. It learns to predict the missing visual tokens from a corrupted input image. The pretrained DiT model can be used as a backbone in other models for visual document tasks like document image classification and table detection.
 You can find all the original DiT checkpoints under the [Microsoft](https://huggingface.co/microsoft?search_models=dit) organization.
> [!TIP]
> Refer to the [BEiT](./beit) docs for more examples of how to apply DiT to different vision tasks.
The example below demonstrates how to classify an image with [`Pipeline`] or the [`AutoModel`] class.
```py
import torch
from transformers import pipeline
pipeline = pipeline(
task="image-classification",
model="microsoft/dit-base-finetuned-rvlcdip",
torch_dtype=torch.float16,
device=0
)
pipeline(images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/dit-example.jpg")
```
```py
import torch
import requests
from PIL import Image
from transformers import AutoModelForImageClassification, AutoImageProcessor
image_processor = AutoImageProcessor.from_pretrained(
"microsoft/dit-base-finetuned-rvlcdip",
use_fast=True,
)
model = AutoModelForImageClassification.from_pretrained(
"microsoft/dit-base-finetuned-rvlcdip",
device_map="auto",
)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/dit-example.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = image_processor(image, return_tensors="pt").to("cuda")
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax(dim=-1).item()
class_labels = model.config.id2label
predicted_class_label = class_labels[predicted_class_id]
print(f"The predicted class label is: {predicted_class_label}")
```
## Notes
- The pretrained DiT weights can be loaded in a [BEiT] model with a modeling head to predict visual tokens.
```py
from transformers import BeitForMaskedImageModeling
model = BeitForMaskedImageModeling.from_pretraining("microsoft/dit-base")
```
## Resources
- Refer to this [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb) for a document image classification inference example.
You can find all the original DiT checkpoints under the [Microsoft](https://huggingface.co/microsoft?search_models=dit) organization.
> [!TIP]
> Refer to the [BEiT](./beit) docs for more examples of how to apply DiT to different vision tasks.
The example below demonstrates how to classify an image with [`Pipeline`] or the [`AutoModel`] class.
```py
import torch
from transformers import pipeline
pipeline = pipeline(
task="image-classification",
model="microsoft/dit-base-finetuned-rvlcdip",
torch_dtype=torch.float16,
device=0
)
pipeline(images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/dit-example.jpg")
```
```py
import torch
import requests
from PIL import Image
from transformers import AutoModelForImageClassification, AutoImageProcessor
image_processor = AutoImageProcessor.from_pretrained(
"microsoft/dit-base-finetuned-rvlcdip",
use_fast=True,
)
model = AutoModelForImageClassification.from_pretrained(
"microsoft/dit-base-finetuned-rvlcdip",
device_map="auto",
)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/dit-example.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = image_processor(image, return_tensors="pt").to("cuda")
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax(dim=-1).item()
class_labels = model.config.id2label
predicted_class_label = class_labels[predicted_class_id]
print(f"The predicted class label is: {predicted_class_label}")
```
## Notes
- The pretrained DiT weights can be loaded in a [BEiT] model with a modeling head to predict visual tokens.
```py
from transformers import BeitForMaskedImageModeling
model = BeitForMaskedImageModeling.from_pretraining("microsoft/dit-base")
```
## Resources
- Refer to this [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb) for a document image classification inference example.