# LLaVa
## Overview
LLaVa is an open-source chatbot trained by fine-tuning LlamA/Vicuna on GPT-generated multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. In other words, it is an multi-modal version of LLMs fine-tuned for chat / instructions.
The LLaVa model was proposed in [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) and improved in [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
The abstract from the paper is the following:
*Large multimodal models (LMM) have recently shown encouraging progress with visual instruction tuning. In this note, we show that the fully-connected vision-language cross-modal connector in LLaVA is surprisingly powerful and data-efficient. With simple modifications to LLaVA, namely, using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts, we establish stronger baselines that achieve state-of-the-art across 11 benchmarks. Our final 13B checkpoint uses merely 1.2M publicly available data, and finishes full training in ∼1 day on a single 8-A100 node. We hope this can make state-of-the-art LMM research more accessible. Code and model will be publicly available*
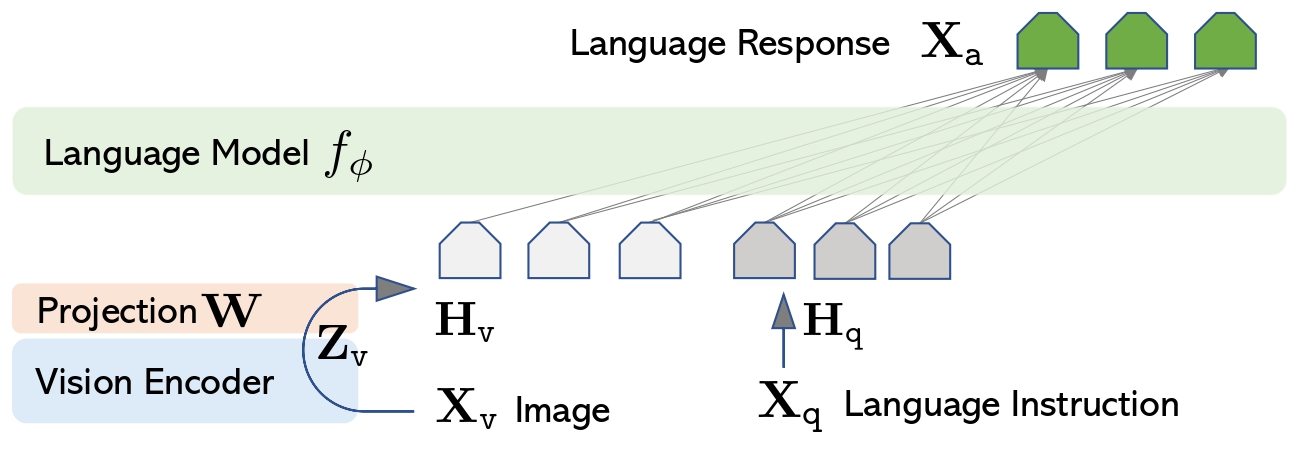 LLaVa architecture. Taken from the original paper.
This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
## Usage tips
- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
- Note the model has not been explicitly trained to process multiple images in the same prompt, although this is technically possible, you may experience inaccurate results.
- For better results, we recommend users to use the processor's `apply_chat_template()` method to format your prompt correctly. For that you need to construct a conversation history, passing in a plain string will not format your prompt. Each message in the conversation history for chat templates is a dictionary with keys "role" and "content". The "content" should be a list of dictionaries, for "text" and "image" modalities, as follows:
```python
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
conversation = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What’s shown in this image?"},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": "This image shows a red stop sign."},]
},
{
"role": "user",
"content": [
{"type": "text", "text": "Describe the image in more details."},
],
},
]
text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
# Note that the template simply formats your prompt, you still have to tokenize it and obtain pixel values for your images
print(text_prompt)
>>> "USER: \nUSER: Describe the image in more details. ASSISTANT:"
```
- If you want to construct a chat prompt yourself, below is a list of prompt formats accepted by each llava checkpoint:
[llava-interleave models](https://huggingface.co/collections/llava-hf/llava-interleave-668e19a97da0036aad4a2f19) requires the following format:
```bash
"<|im_start|>user \nWhat is shown in this image?<|im_end|><|im_start|>assistant"
```
For multiple turns conversation:
```bash
"<|im_start|>user \n<|im_end|><|im_start|>assistant <|im_end|><|im_start|>user \n<|im_end|><|im_start|>assistant "
```
[llava-1.5 models](https://huggingface.co/collections/llava-hf/llava-15-65f762d5b6941db5c2ba07e0) requires the following format:
```bash
"USER: \n ASSISTANT:"
```
For multiple turns conversation:
```bash
"USER: \n ASSISTANT: USER: ASSISTANT: USER: ASSISTANT:"
```
### Using Flash Attention 2
Flash Attention 2 is an even faster, optimized version of the previous optimization, please refer to the [Flash Attention 2 section of performance docs](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
- A [Google Colab demo](https://colab.research.google.com/drive/1qsl6cd2c8gGtEW1xV5io7S8NHh-Cp1TV?usp=sharing) on how to run Llava on a free-tier Google colab instance leveraging 4-bit inference.
- A [similar notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LLaVa/Inference_with_LLaVa_for_multimodal_generation.ipynb) showcasing batched inference. 🌎
## LlavaConfig
[[autodoc]] LlavaConfig
## LlavaProcessor
[[autodoc]] LlavaProcessor
## LlavaForConditionalGeneration
[[autodoc]] LlavaForConditionalGeneration
- forward
LLaVa architecture. Taken from the original paper.
This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
## Usage tips
- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
- Note the model has not been explicitly trained to process multiple images in the same prompt, although this is technically possible, you may experience inaccurate results.
- For better results, we recommend users to use the processor's `apply_chat_template()` method to format your prompt correctly. For that you need to construct a conversation history, passing in a plain string will not format your prompt. Each message in the conversation history for chat templates is a dictionary with keys "role" and "content". The "content" should be a list of dictionaries, for "text" and "image" modalities, as follows:
```python
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
conversation = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What’s shown in this image?"},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": "This image shows a red stop sign."},]
},
{
"role": "user",
"content": [
{"type": "text", "text": "Describe the image in more details."},
],
},
]
text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
# Note that the template simply formats your prompt, you still have to tokenize it and obtain pixel values for your images
print(text_prompt)
>>> "USER: \nUSER: Describe the image in more details. ASSISTANT:"
```
- If you want to construct a chat prompt yourself, below is a list of prompt formats accepted by each llava checkpoint:
[llava-interleave models](https://huggingface.co/collections/llava-hf/llava-interleave-668e19a97da0036aad4a2f19) requires the following format:
```bash
"<|im_start|>user \nWhat is shown in this image?<|im_end|><|im_start|>assistant"
```
For multiple turns conversation:
```bash
"<|im_start|>user \n<|im_end|><|im_start|>assistant <|im_end|><|im_start|>user \n<|im_end|><|im_start|>assistant "
```
[llava-1.5 models](https://huggingface.co/collections/llava-hf/llava-15-65f762d5b6941db5c2ba07e0) requires the following format:
```bash
"USER: \n ASSISTANT:"
```
For multiple turns conversation:
```bash
"USER: \n ASSISTANT: USER: ASSISTANT: USER: ASSISTANT:"
```
### Using Flash Attention 2
Flash Attention 2 is an even faster, optimized version of the previous optimization, please refer to the [Flash Attention 2 section of performance docs](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
- A [Google Colab demo](https://colab.research.google.com/drive/1qsl6cd2c8gGtEW1xV5io7S8NHh-Cp1TV?usp=sharing) on how to run Llava on a free-tier Google colab instance leveraging 4-bit inference.
- A [similar notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LLaVa/Inference_with_LLaVa_for_multimodal_generation.ipynb) showcasing batched inference. 🌎
## LlavaConfig
[[autodoc]] LlavaConfig
## LlavaProcessor
[[autodoc]] LlavaProcessor
## LlavaForConditionalGeneration
[[autodoc]] LlavaForConditionalGeneration
- forward