# How to add a model to 🤗 Transformers?
🤗 Transformersライブラリは、コミュニティの貢献者のおかげで新しいモデルを提供できることがよくあります。
しかし、これは難しいプロジェクトであり、🤗 Transformersライブラリと実装するモデルについての深い知識が必要です。
Hugging Faceでは、コミュニティの多くの人々に積極的にモデルを追加する力を与えようと努力しており、
このガイドをまとめて、PyTorchモデルを追加するプロセスを説明します([PyTorchがインストールされていることを確認してください](https://pytorch.org/get-started/locally/))。
この過程で、以下のことを学びます:
- オープンソースのベストプラクティスに関する洞察
- 最も人気のある深層学習ライブラリの設計原則を理解する
- 大規模なモデルを効率的にテストする方法を学ぶ
- `black`、`ruff`、および`make fix-copies`などのPythonユーティリティを統合して、クリーンで読みやすいコードを確保する方法を学ぶ
Hugging Faceチームのメンバーがサポートを提供するので、一人ぼっちになることはありません。 🤗 ❤️
さあ、始めましょう!🤗 Transformersで見たいモデルについての[New model addition](https://github.com/huggingface/transformers/issues/new?assignees=&labels=New+model&template=new-model-addition.yml)のイシューを開いてください。
特定のモデルを提供することに特にこだわりがない場合、[New model label](https://github.com/huggingface/transformers/labels/New%20model)で未割り当てのモデルリクエストがあるかどうかを確認して、それに取り組むことができます。
新しいモデルリクエストを開いたら、最初のステップは🤗 Transformersをよく理解することです!
## General overview of 🤗 Transformers
まず、🤗 Transformersの一般的な概要を把握する必要があります。🤗 Transformersは非常に意見が分かれるライブラリですので、
ライブラリの哲学や設計選択について同意できない可能性があります。ただし、私たちの経験から、ライブラリの基本的な設計選択と哲学は、
🤗 Transformersを効率的にスケーリングし、適切なレベルで保守コストを抑えるために不可欠です。
ライブラリの理解を深めるための良い出発点は、[哲学のドキュメント](philosophy)を読むことです。
私たちの作業方法の結果、すべてのモデルに適用しようとするいくつかの選択肢があります:
- 一般的に、抽象化よりも構成が優先されます。
- コードの重複は、読みやすさやアクセス可能性を大幅に向上させる場合、必ずしも悪いわけではありません。
- モデルファイルはできるだけ自己完結的であるべきで、特定のモデルのコードを読む際には、理想的には該当する`modeling_....py`ファイルのみを見る必要があります。
私たちの意見では、このライブラリのコードは単なる製品を提供する手段だけでなく、*例えば、推論のためにBERTを使用する能力*などの製品そのもの.
### Overview of models
モデルを正常に追加するためには、モデルとその設定、[`PreTrainedModel`]、および[`PretrainedConfig`]の相互作用を理解することが重要です。
例示的な目的で、🤗 Transformersに追加するモデルを「BrandNewBert」と呼びます。
以下をご覧ください:
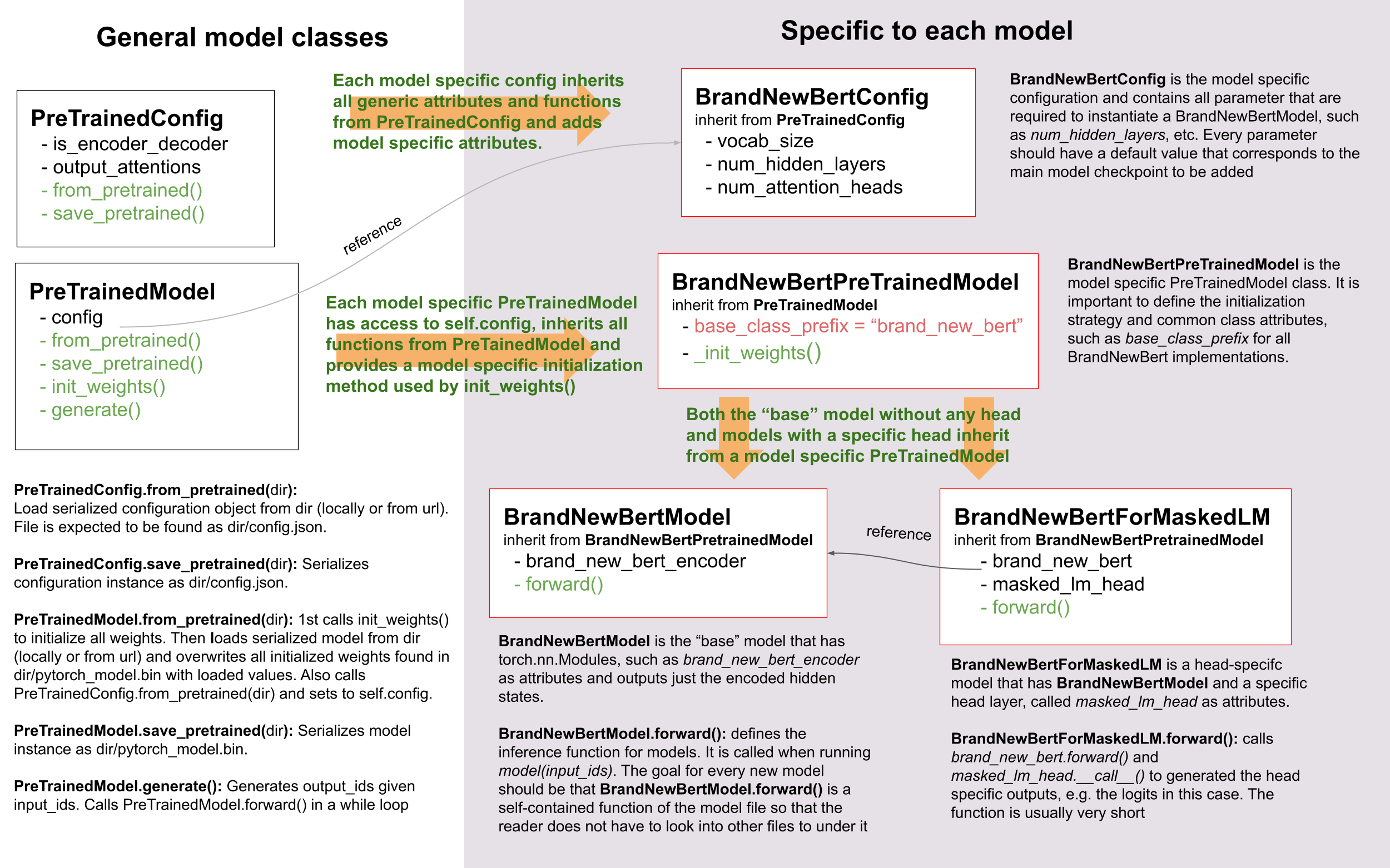 ご覧のように、🤗 Transformersでは継承を使用していますが、抽象化のレベルを最小限に保っています。
ライブラリ内のどのモデルにも、抽象化のレベルが2つを超えることはありません。
`BrandNewBertModel` は `BrandNewBertPreTrainedModel` を継承し、さらに[`PreTrainedModel`]を継承しています。
これだけです。
一般的なルールとして、新しいモデルは[`PreTrainedModel`]にのみ依存するようにしたいと考えています。
すべての新しいモデルに自動的に提供される重要な機能は、[`~PreTrainedModel.from_pretrained`]および
[`~PreTrainedModel.save_pretrained`]です。
これらはシリアライゼーションとデシリアライゼーションに使用されます。
`BrandNewBertModel.forward`などの他の重要な機能は、新しい「modeling_brand_new_bert.py」スクリプトで完全に定義されるべきです。
次に、特定のヘッドレイヤーを持つモデル(たとえば `BrandNewBertForMaskedLM` )が `BrandNewBertModel` を継承するのではなく、
抽象化のレベルを低く保つために、そのフォワードパスで `BrandNewBertModel` を呼び出すコンポーネントとして使用されるようにしたいと考えています。
新しいモデルには常に `BrandNewBertConfig` という設定クラスが必要です。この設定は常に[`PreTrainedModel`]の属性として保存され、
したがって、`BrandNewBertPreTrainedModel`から継承するすべてのクラスで`config`属性を介してアクセスできます。
```python
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
モデルと同様に、設定は[`PretrainedConfig`]から基本的なシリアル化および逆シリアル化の機能を継承しています。注意すべきは、設定とモデルは常に2つの異なる形式にシリアル化されることです - モデルは*pytorch_model.bin*ファイルに、設定は*config.json*ファイルにシリアル化されます。[`~PreTrainedModel.save_pretrained`]を呼び出すと、自動的に[`~PretrainedConfig.save_pretrained`]も呼び出され、モデルと設定の両方が保存されます。
### Code style
新しいモデルをコーディングする際には、Transformersは意見があるライブラリであり、コードの書き方に関していくつかの独自の考え方があります :-)
1. モデルのフォワードパスはモデリングファイルに完全に記述され、ライブラリ内の他のモデルとは完全に独立している必要があります。他のモデルからブロックを再利用したい場合、コードをコピーしてトップに`# Copied from`コメントを付けて貼り付けます(良い例は[こちら](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)、コピーに関する詳細なドキュメンテーションは[ここ](pr_checks#check-copies)を参照してください)。
2. コードは完全に理解可能でなければなりません。これは記述的な変数名を選択し、省略形を避けるべきであることを意味します。例えば、`act`ではなく`activation`が好まれます。1文字の変数名は、forループ内のインデックスでない限り、強く非推奨です。
3. より一般的に、魔法のような短いコードよりも長くて明示的なコードを好みます。
4. PyTorchでは`nn.Sequential`をサブクラス化せずに、`nn.Module`をサブクラス化し、フォワードパスを記述し、コードを使用する他の人が簡単にデバッグできるようにします。プリントステートメントやブレークポイントを追加してデバッグできるようにします。
5. 関数のシグネチャは型アノテーションを付けるべきです。その他の部分に関しては、型アノテーションよりも良い変数名が読みやすく理解しやすいことがあります。
### Overview of tokenizers
まだ完了していません :-( このセクションは近日中に追加されます!
## Step-by-step recipe to add a model to 🤗 Transformers
モデルを追加する方法は人それぞれ異なるため、他のコントリビューターが🤗 Transformersにモデルを追加する際の要約を確認することが非常に役立つ場合があります。以下は、他のコントリビューターが🤗 Transformersにモデルをポートする際のコミュニティブログ投稿のリストです。
1. [GPT2モデルのポーティング](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) by [Thomas](https://huggingface.co/thomwolf)
2. [WMT19 MTモデルのポーティング](https://huggingface.co/blog/porting-fsmt) by [Stas](https://huggingface.co/stas)
経験から言えることは、モデルを追加する際に最も重要なことは次のようになります:
- 車輪の再発明をしないでください!新しい🤗 Transformersモデルのために追加するコードのほとんどはすでに🤗 Transformers内のどこかに存在しています。類似した既存のモデルやトークナイザを見つけるために、いくつかの時間をかけて探すことが重要です。[grep](https://www.gnu.org/software/grep/)と[rg](https://github.com/BurntSushi/ripgrep)はあなたの友達です。モデルのトークナイザは1つのモデル実装に基づいているかもしれませんが、モデルのモデリングコードは別の実装に基づいていることがあることに注意してください。例えば、FSMTのモデリングコードはBARTに基づいており、FSMTのトークナイザコードはXLMに基づいています。
- これは科学的な課題よりもエンジニアリングの課題です。モデルの論文の理論的な側面をすべて理解しようとするよりも、効率的なデバッグ環境を作成するために時間を費やすべきです。
- 行き詰まった場合は助けを求めてください!モデルは🤗 Transformersのコアコンポーネントであり、Hugging Faceではモデルを追加するための各ステップでお手伝いするのを喜んでいます。進行がないことに気付いた場合は、進展していないことを気にしないでください。
以下では、🤗 Transformersにモデルをポートする際に最も役立つと考えられる一般的なレシピを提供しようとしています。
次のリストは、モデルを追加するために行う必要があるすべてのことの要約であり、To-Doリストとして使用できます:
- ☐ (オプション)モデルの理論的な側面を理解しました
- ☐ 🤗 Transformersの開発環境を準備しました
- ☐ オリジナルのリポジトリのデバッグ環境をセットアップしました
- ☐ `forward()` パスをオリジナルのリポジトリとチェックポイントで正常に実行するスクリプトを作成しました
- ☐ モデルの骨格を🤗 Transformersに正常に追加しました
- ☐ オリジナルのチェックポイントを🤗 Transformersのチェックポイントに正常に変換しました
- ☐ 🤗 Transformersで実行される `forward()` パスを正常に実行し、オリジナルのチェックポイントと同一の出力を得ました
- ☐ 🤗 Transformersでのモデルテストを完了しました
- ☐ 🤗 Transformersにトークナイザを正常に追加しました
- ☐ エンドツーエンドの統合テストを実行しました
- ☐ ドキュメントを完成させました
- ☐ モデルのウェイトをHubにアップロードしました
- ☐ プルリクエストを提出しました
- ☐ (オプション)デモノートブックを追加しました
まず、通常、`BrandNewBert`の理論的な理解を深めることをお勧めします。
ただし、もしモデルの理論的な側面を「実務中に理解する」方が好ましい場合、`BrandNewBert`のコードベースに直接アクセスするのも問題ありません。
このオプションは、エンジニアリングのスキルが理論的なスキルよりも優れている場合、
`BrandNewBert`の論文を理解するのに苦労している場合、または科学的な論文を読むよりもプログラミングを楽しんでいる場合に適しています。
### 1. (Optional) Theoretical aspects of BrandNewBert
BrandNewBertの論文がある場合、その説明を読むための時間を取るべきです。論文の中には理解が難しい部分があるかもしれません。
その場合でも心配しないでください。目標は論文の深い理論的理解を得ることではなく、
🤗 Transformersでモデルを効果的に再実装するために必要な情報を抽出することです。
ただし、理論的な側面にあまり多くの時間をかける必要はありません。代わりに、実践的な側面に焦点を当てましょう。具体的には次の点です:
- *brand_new_bert*はどの種類のモデルですか? BERTのようなエンコーダーのみのモデルですか? GPT2のようなデコーダーのみのモデルですか? BARTのようなエンコーダー-デコーダーモデルですか?
[model_summary](model_summary)を参照して、これらの違いについて詳しく知りたい場合があります。
- *brand_new_bert*の応用分野は何ですか? テキスト分類ですか? テキスト生成ですか? Seq2Seqタスク、例えば要約ですか?
- モデルをBERT/GPT-2/BARTとは異なるものにする新しい機能は何ですか?
- 既存の[🤗 Transformersモデル](https://huggingface.co/transformers/#contents)の中で*brand_new_bert*に最も似ているモデルはどれですか?
- 使用されているトークナイザの種類は何ですか? SentencePieceトークナイザですか? WordPieceトークナイザですか? BERTやBARTで使用されているトークナイザと同じですか?
モデルのアーキテクチャの良い概要を得たと感じたら、Hugging Faceチームに質問を送ることができます。
これにはモデルのアーキテクチャ、注意層などに関する質問が含まれるかもしれません。
私たちは喜んでお手伝いします。
### 2. Next prepare your environment
1. リポジトリのページで「Fork」ボタンをクリックして、[リポジトリ](https://github.com/huggingface/transformers)をフォークします。
これにより、コードのコピーがGitHubユーザーアカウントの下に作成されます。
2. ローカルディスクにある`transformers`フォークをクローンし、ベースリポジトリをリモートとして追加します:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
3. 開発環境をセットアップするために、次のコマンドを実行してください:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
お使いのOSに応じて、およびTransformersのオプションの依存関係の数が増えているため、このコマンドでエラーが発生する可能性があります。
その場合は、作業しているDeep Learningフレームワーク(PyTorch、TensorFlow、および/またはFlax)をインストールし、次の手順を実行してください:
```bash
pip install -e ".[quality]"
```
これはほとんどのユースケースには十分であるはずです。その後、親ディレクトリに戻ることができます。
```bash
cd ..
```
4. Transformersに*brand_new_bert*のPyTorchバージョンを追加することをお勧めします。PyTorchをインストールするには、
https://pytorch.org/get-started/locally/ の指示に従ってください。
**注意:** CUDAをインストールする必要はありません。新しいモデルをCPUで動作させることで十分です。
5. *brand_new_bert*を移植するには、元のリポジトリへのアクセスも必要です。
```bash
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
cd brand_new_bert
pip install -e .
```
*brand_new_bert*を🤗 Transformersにポートするための開発環境を設定しました。
### 3.-4. Run a pretrained checkpoint using the original repository
最初に、オリジナルの*brand_new_bert*リポジトリで作業します。通常、オリジナルの実装は非常に「研究的」であり、ドキュメンテーションが不足していたり、コードが理解しにくいことがあります。しかし、これが*brand_new_bert*を再実装する動機となるべきです。Hugging Faceでは、主要な目標の1つが、動作するモデルを取り、それをできるだけ**アクセス可能でユーザーフレンドリーで美しい**ものに書き直すことです。これは、🤗 Transformersにモデルを再実装する最も重要な動機です - 複雑な新しいNLP技術を**誰にでも**アクセス可能にしようとする試みです。
まず、オリジナルのリポジトリに入り込むことから始めるべきです。
公式の事前学習済みモデルをオリジナルのリポジトリで正常に実行することは、通常、**最も困難な**ステップです。
私たちの経験から、オリジナルのコードベースに慣れるのに時間をかけることが非常に重要です。以下のことを理解する必要があります:
- 事前学習済みの重みをどこで見つけるか?
- 対応するモデルに事前学習済みの重みをロードする方法は?
- モデルから独立してトークナイザを実行する方法は?
- 1つのフォワードパスを追跡して、単純なフォワードパスに必要なクラスと関数がわかるようにします。通常、これらの関数だけを再実装する必要があります。
- モデルの重要なコンポーネントを特定できること:モデルのクラスはどこにありますか?モデルのサブクラス、*例* EncoderModel、DecoderModelがありますか?自己注意レイヤーはどこにありますか?複数の異なる注意レイヤー、*例* *自己注意*、*クロスアテンション*などが存在しますか?
- オリジナルのリポジトリの環境でモデルをデバッグする方法は?*print*ステートメントを追加する必要があるか、*ipdb*のような対話型デバッガを使用できるか、PyCharmのような効率的なIDEを使用してモデルをデバッグする必要がありますか?
重要なのは、ポーティングプロセスを開始する前に、オリジナルのリポジトリでコードを**効率的に**デバッグできることです!また、これはオープンソースライブラリで作業していることを覚えておいてください。オリジナルのリポジトリでコードを調べる誰かを歓迎するために、問題をオープンにしたり、プルリクエストを送信したりすることをためらわないでください。このリポジトリのメンテナーは、彼らのコードを調べてくれる人に対して非常に喜んでいる可能性が高いです!
この段階では、オリジナルのモデルのデバッグにどのような環境と戦略を使用するかは、あなた次第です。最初にオリジナルのリポジトリに関するコードをデバッグできることが非常に重要です。また、GPU環境をセットアップすることはお勧めしません。まず、CPU上で作業し、モデルがすでに🤗 Transformersに正常にポートされていることを確認します。最後に、モデルがGPU上でも期待通りに動作するかどうかを検証する必要があります。
一般的に、オリジナルのモデルを実行するための2つのデバッグ環境があります:
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- ローカルなPythonスクリプト。
Jupyterノートブックは、セルごとに実行できるため、論理的なコンポーネントをより分割し、中間結果を保存できるため、デバッグサイクルが速くなるという利点があります。また、ノートブックは他の共同作業者と簡単に共有できることが多く、Hugging Faceチームに助けを求める場合に非常に役立つ場合があります。Jupyterノートブックに精通している場合、それ
```python
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
デバッグ戦略については、通常、いくつかの選択肢があります:
- 元のモデルを多くの小さなテスト可能なコンポーネントに分解し、それぞれに対して前方パスを実行して検証します
- 元のモデルを元のトークナイザと元のモデルにのみ分解し、それらに対して前方パスを実行し、検証のために中間のプリントステートメントまたはブレークポイントを使用します
再度、どの戦略を選択するかはあなた次第です。元のコードベースに依存することが多く、元のコードベースに応じて一方または他方が有利なことがあります。
元のコードベースがモデルを小さなサブコンポーネントに分解できる場合、*例えば*元のコードベースが簡単にイーガーモードで実行できる場合、それを行う価値が通常あります。最初からより難しい方法を選択することにはいくつかの重要な利点があります:
- 後で元のモデルを🤗 Transformersの実装と比較する際に、各コンポーネントが対応する🤗 Transformers実装のコンポーネントと一致することを自動的に検証できるため、視覚的な比較に依存せずに済みます
- 大きな問題を小さな問題に分解する、つまり個々のコンポーネントのみをポーティングする問題に分割するのに役立ち、作業を構造化するのに役立ちます
- モデルを論理的な意味のあるコンポーネントに分割することで、モデルの設計をよりよく理解しやすくし、モデルをよりよく理解するのに役立ちます
- 後で、コンポーネントごとのテストを行うことで、コードを変更し続ける際にリグレッションが発生しないことを確認するのに役立ちます
[Lysandreの](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed) ELECTRAの統合チェックは、これがどのように行われるかの良い例です。
ただし、元のコードベースが非常に複雑で、中間コンポーネントをコンパイルモードで実行することしか許可しない場合、モデルを小さなテスト可能なサブコンポーネントに分解することが時間がかかりすぎるか、不可能であることがあります。
良い例は[T5のMeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow)ライブラリであり、非常に複雑でモデルをサブコンポーネントに分解する簡単な方法を提供しないことがあります。このようなライブラリでは、通常、プリントステートメントを検証することに依存します。
どの戦略を選択しても、推奨される手順は通常同じで、最初のレイヤーからデバッグを開始し、最後のレイヤーからデバッグを行うべきです。
通常、以下の順序で次のレイヤーからの出力を取得することをお勧めします:
1. モデルに渡された入力IDを取得する
2. 単語の埋め込みを取得する
3. 最初のTransformerレイヤーの入力を取得する
4. 最初のTransformerレイヤーの出力を取得する
5. 次のn - 1つのTransformerレイヤーの出力を取得する
6. BrandNewBertモデル全体の出力を取得する
入力IDは整数の配列である必要があり、*例:* `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]` のようになります。
以下のレイヤーの出力は多次元の浮動小数点配列であることが多く、次のようになることがあります:
```
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
🤗 Transformersに追加されるすべてのモデルは、統合テストを数回合格することが期待されており、元のモデルと🤗 Transformersで再実装されたバージョンが、0.001の精度までまったく同じ出力を提供する必要があります。
異なるライブラリフレームワークで同じモデルを書いた場合、わずかに異なる出力を返すことが正常であるため、誤差許容値として1e-3(0.001)を受け入れています。モデルがほぼ同じ出力を返すだけでは不十分で、ほぼ同一である必要があります。そのため、🤗 Transformersバージョンの中間出力を元の*brand_new_bert*の実装の中間出力と複数回にわたって比較することになるでしょう。その際、元のリポジトリの**効率的な**デバッグ環境が非常に重要です。以下は、デバッグ環境をできるだけ効率的にするためのアドバイスです。
- 中間結果をデバッグする最適な方法を見つける。元のリポジトリはPyTorchで書かれていますか?その場合、元のモデルをより小さなサブコンポーネントに分解して中間値を取得する長いスクリプトを書くことがおそらく適切です。元のリポジトリがTensorflow 1で書かれている場合、[tf.print](https://www.tensorflow.org/api_docs/python/tf/print)などのTensorFlowのプリント操作を使用して中間値を出力する必要があるかもしれません。元のリポジトリがJaxで書かれている場合、フォワードパスの実行時にモデルが**jittedされていない**ことを確認してください。例:[このリンク](https://github.com/google/jax/issues/196)をチェック。
- 使用可能な最小の事前学習済みチェックポイントを使用します。チェックポイントが小さいほど、デバッグサイクルが速くなります。事前学習済みモデルがフォワードパスに10秒以上かかる場合、効率的ではありません。非常に大きなチェックポイントしか利用できない場合、新しい環境でランダムに初期化されたウェイトを持つダミーモデルを作成し、それらのウェイトを🤗 Transformersバージョンのモデルと比較する方が良いかもしれません。
- 元のリポジトリでフォワードパスを呼び出す最も簡単な方法を使用していることを確認してください。理想的には、元のリポジトリで**単一のフォワードパス**を呼び出す関数を見つけたいです。これは通常「predict」、「evaluate」、「forward」、「__call__」と呼ばれます。複数回「forward」を呼び出す関数をデバッグしたくありません。例:テキストを生成するために「autoregressive_sample」、「generate」と呼ばれる関数。
- トークナイゼーションとモデルの「フォワード」パスを分離しようとしてください。元のリポジトリが入力文字列を入力する必要がある例を示す場合、フォワードコール内で文字列入力が入力IDに変更される場所を特定し、このポイントから開始します。これは、スクリプトを自分で書くか、入力文字列ではなく入力IDを直接入力できるように元のコードを変更する必要があるかもしれません。
- デバッグセットアップ内のモデルがトレーニングモードではないことを確認してください。トレーニングモードでは、モデル内の複数のドロップアウトレイヤーのためにランダムな出力が生成されることがあります。デバッグ環境のフォワードパスが**決定論的**であることを確認し、ドロップアウトレイヤーが使用されないようにします。または、新しい実装が同じフレームワーク内にある場合、*transformers.utils.set_seed*を使用してください。
以下のセクションでは、*brand_new_bert*についてこれを具体的にどのように行うかについての詳細/ヒントを提供します。
### 5.-14. Port BrandNewBert to 🤗 Transformers
次に、ついに新しいコードを🤗 Transformersに追加できます。🤗 Transformersのフォークのクローンに移動してください:
```bash
cd transformers
```
特別なケースとして、既存のモデルと完全に一致するアーキテクチャのモデルを追加する場合、
[このセクション](#write-a-conversion-script)で説明されているように、変換スクリプトを追加するだけで済みます。
この場合、既存のモデルの完全なモデルアーキテクチャを再利用できます。
それ以外の場合は、新しいモデルの生成を開始しましょう。 次のスクリプトを使用して、以下から始まるモデルを追加することをお勧めします。
既存のモデル:
```bash
transformers add-new-model-like
```
モデルの基本情報を入力するためのアンケートが表示されます。
**主要な huggingface/transformers リポジトリでプルリクエストを開く**
自動生成されたコードを適応し始める前に、🤗 Transformers に「作業中(WIP)」プルリクエストを開くタイミングです。
例:「[WIP] *brand_new_bert* を追加」などです。
これにより、ユーザーと Hugging Face チームが🤗 Transformers にモデルを統合する作業を並行して行うことができます。
以下の手順を実行してください:
1. メインブランチから分かりやすい名前のブランチを作成します。
```bash
git checkout -b add_brand_new_bert
```
2. 自動生成されたコードをコミットしてください:
```bash
git add .
git commit
```
3. 現在の main ブランチにフェッチしてリベース
```bash
git fetch upstream
git rebase upstream/main
```
4. 変更をあなたのアカウントにプッシュするには、次のコマンドを使用します:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
5. 満足したら、GitHub上のフォークのウェブページに移動します。[プルリクエスト]をクリックします。将来の変更に備えて、Hugging Face チームのメンバーのGitHubハンドルをレビュアーとして追加してください。
6. GitHubのプルリクエストウェブページの右側にある「ドラフトに変換」をクリックして、PRをドラフトに変更します。
以下では、進捗があった場合は常に作業をコミットし、プッシュしてプルリクエストに表示されるようにしてください。さらに、定期的にメインからの最新の変更を取り込むために、次のように行うことを忘れないでください:
```bash
git fetch upstream
git merge upstream/main
```
一般的に、モデルや実装に関する質問はPull Request (PR) で行い、PR内で議論し、解決します。
これにより、Hugging Face チームは新しいコードをコミットする際や質問がある場合に常に通知を受けることができます。
質問や問題が解決された際に、問題や質問が理解されやすいように、Hugging Face チームにコードを指摘することが非常に役立ちます。
このためには、「Files changed」タブに移動してすべての変更を表示し、質問したい行に移動して「+」シンボルをクリックしてコメントを追加します。
質問や問題が解決された場合は、作成されたコメントの「Resolve」ボタンをクリックできます。
同様に、Hugging Face チームはコードをレビューする際にコメントを開きます。
PR上でのほとんどの質問はGitHub上で行うことをお勧めします。
一般的な質問に関しては、公にはあまり役立たない質問については、SlackやメールでHugging Face チームに連絡することもできます。
**5. 生成されたモデルコードを"brand_new_bert"に適応させる**
最初に、モデル自体に焦点を当て、トークナイザには気にしないでください。
関連するコードは、生成されたファイル`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`および`src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`で見つかるはずです。
さて、ついにコーディングを始めることができます :smile:。
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`にある生成されたコードは、エンコーダーのみのモデルであればBERTと同じアーキテクチャを持っているか、エンコーダー-デコーダーモデルであればBARTと同じアーキテクチャを持っているはずです。
この段階では、モデルの理論的な側面について学んだことを思い出すべきです。つまり、「このモデルはBERTまたはBARTとどのように異なるのか?」ということです。
これらの変更を実装しますが、これは通常、セルフアテンションレイヤー、正規化レイヤーの順序などを変更することを意味します。
再び、あなたのモデルがどのように実装されるべきかをより良く理解するために、Transformers内に既存のモデルの類似アーキテクチャを見ることが役立つことがあります。
この時点では、コードが完全に正確またはクリーンである必要はありません。
むしろ、まずは必要なコードの最初の*クリーンでない*コピー&ペーストバージョンを
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`に追加し、必要なコードがすべて追加されていると感じるまで改善/修正を反復的に行うことがお勧めです。
私たちの経験から、必要なコードの最初のバージョンを迅速に追加し、次のセクションで説明する変換スクリプトを使用してコードを繰り返し改善/修正する方が効率的であることが多いです。
この時点で動作する必要があるのは、🤗 Transformersの"brand_new_bert"の実装をインスタンス化できることだけです。つまり、以下のコマンドが機能する必要があります:
```python
from transformers import BrandNewBertModel, BrandNewBertConfig
model = BrandNewBertModel(BrandNewBertConfig())
```
上記のコマンドは、`BrandNewBertConfig()` で定義されたデフォルトパラメータに従ってモデルを作成し、
すべてのコンポーネントの `init()` メソッドが正常に動作することを確認します。
すべてのランダムな初期化は、`BrandnewBertPreTrainedModel` クラスの `_init_weights` メソッドで行う必要があります。
このメソッドは、設定変数に依存するすべてのリーフモジュールを初期化する必要があります。以下は、BERT の `_init_weights` メソッドの例です:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
```
特定のモジュールに特別な初期化が必要な場合、カスタムスキームをさらに持つことができます。たとえば、
`Wav2Vec2ForPreTraining`では、最後の2つの線形層には通常のPyTorchの`nn.Linear`の初期化が必要ですが、
他のすべての層は上記のような初期化を使用する必要があります。これは以下のようにコーディングされています:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, Wav2Vec2ForPreTraining):
module.project_hid.reset_parameters()
module.project_q.reset_parameters()
module.project_hid._is_hf_initialized = True
module.project_q._is_hf_initialized = True
elif isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
```
`_is_hf_initialized`フラグは、サブモジュールを一度だけ初期化することを確実にするために内部で使用されます。
`module.project_q`と`module.project_hid`のためにそれを`True`に設定することで、
カスタム初期化が後で上書きされないようにし、`_init_weights`関数がそれらに適用されないようにします。
**6. 変換スクリプトを書く**
次に、*brand_new_bert* の元のリポジトリでデバッグに使用したチェックポイントを、新しく作成した 🤗 Transformers 実装の *brand_new_bert* と互換性のあるチェックポイントに変換できる変換スクリプトを書く必要があります。
変換スクリプトをゼロから書くことはお勧めされませんが、代わりに 🤗 Transformers で既に存在する類似のモデルを同じフレームワークで変換したスクリプトを調べることが良いでしょう。
通常、既存の変換スクリプトをコピーして、自分のユースケースにわずかに適応させることで十分です。
Hugging Face チームに既存のモデルに類似した変換スクリプトを教えてもらうことも躊躇しないでください。
- TensorFlowからPyTorchにモデルを移植している場合、良い出発点はBERTの変換スクリプトかもしれません [here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- PyTorchからPyTorchにモデルを移植している場合、良い出発点はBARTの変換スクリプトかもしれません [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
以下では、PyTorchモデルが層の重みをどのように保存し、層の名前を定義するかについて簡単に説明します。
PyTorchでは、層の名前は層に与えるクラス属性の名前によって定義されます。
PyTorchで `SimpleModel` というダミーモデルを定義しましょう:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
これで、このモデル定義のインスタンスを作成し、`dense`、`intermediate`、`layer_norm`のすべての重みをランダムな重みで埋めたモデルを作成できます。モデルのアーキテクチャを確認するために、モデルを印刷してみましょう。
```python
model = SimpleModel()
print(model)
```
これは以下を出力します:
```
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
層の名前はPyTorchのクラス属性の名前によって定義されています。特定の層の重み値を出力することができます:
```python
print(model.dense.weight.data)
```
ランダムに初期化された重みを確認するために
```
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
スクリプト内の変換スクリプトでは、ランダムに初期化された重みを、対応するチェックポイント内の正確な重みで埋める必要があります。例えば、以下のように翻訳します:
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
PyTorchモデルの各ランダム初期化された重みと対応する事前学習済みチェックポイントの重みが
**形状と名前の両方**で正確に一致することを確認する必要があります。
これを行うために、形状に対するassertステートメントを追加し、チェックポイントの重みの名前を出力することが
**必要不可欠**です。例えば、次のようなステートメントを追加する必要があります:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
また、両方の重みの名前を印刷して、一致していることを確認する必要があります。例えば、次のようにします:
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
もし形状または名前のいずれかが一致しない場合、おそらく誤って🤗 Transformersの実装に初期化されたレイヤーに間違ったチェックポイントの重みを割り当ててしまった可能性があります。
誤った形状は、おそらく`BrandNewBertConfig()`での設定パラメーターが、変換したいチェックポイントで使用されたものと正確に一致しないためです。
ただし、PyTorchのレイヤーの実装によっては、重みを事前に転置する必要がある場合もあります。
最後に、**すべて**の必要な重みが初期化されていることを確認し、初期化に使用されなかったすべてのチェックポイントの重みを表示して、モデルが正しく変換されていることを確認してください。
変換トライアルが誤った形状ステートメントまたは誤った名前割り当てで失敗するのは完全に正常です。
これはおそらく、`BrandNewBertConfig()`で誤ったパラメーターを使用したか、🤗 Transformersの実装に誤ったアーキテクチャがあるか、🤗 Transformersの実装の1つのコンポーネントの`init()`関数にバグがあるか、チェックポイントの重みの1つを転置する必要があるためです。
このステップは、以前のステップと繰り返すべきです。すべてのチェックポイントの重みが正しく🤗 Transformersモデルに読み込まれるまで繰り返すべきです。
🤗 Transformers実装に正しくチェックポイントを読み込んだ後、選択したフォルダーにモデルを保存できます `/path/to/converted/checkpoint/folder`。このフォルダには`pytorch_model.bin`ファイルと`config.json`ファイルの両方が含まれるはずです。
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. 順伝播(forward pass)の実装**
🤗 Transformers実装で事前学習済みの重みを正しく読み込んだ後、順伝播が正しく実装されていることを確認する必要があります。[元のリポジトリを理解する](#3-4-run-a-pretrained-checkpoint-using-the-original-repository)で、元のリポジトリを使用してモデルの順伝播を実行するスクリプトをすでに作成しました。今度は、元のリポジトリの代わりに🤗 Transformers実装を使用して類似のスクリプトを作成する必要があります。以下のようになります:
```python
model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
🤗 Transformersの実装と元のモデルの実装が最初の実行で完全に同じ出力を提供しないか、
フォワードパスでエラーが発生する可能性が非常に高いです。失望しないでください - これは予想されていることです!
まず、フォワードパスがエラーをスローしないことを確認する必要があります。
間違った次元が使用され、*次元の不一致*エラーや、誤ったデータ型オブジェクトが使用されることがよくあります。
例えば、`torch.long`ではなく`torch.float32`が使用されます。特定のエラーを解決できない場合は、
Hugging Faceチームに助けを求めることを躊躇しないでください。
🤗 Transformers実装が正しく機能することを確認する最終的な部分は、出力が`1e-3`の精度で同等であることを確認することです。
まず、出力の形状が同一であること、つまりスクリプトの🤗 Transformers実装と元の実装の両方で`outputs.shape`が同じ値を生成する必要があります。
次に、出力値が同一であることを確認する必要があります。
これは新しいモデルを追加する際の最も難しい部分の1つです。
出力が同一でない理由の一般的な間違いは以下の通りです。
- 一部のレイヤーが追加されていない、つまり*活性化*レイヤーが追加されていないか、リザバル接続が忘れられている
- 単語埋め込み行列が結ばれていない
- オリジナルの実装がオフセットを使用しているため、誤った位置埋め込みが使用されている
- フォワードパス中にドロップアウトが適用されています。これを修正するには、*model.trainingがFalse*であることを確認し、フォワードパス中に誤ってドロップアウトレイヤーがアクティブ化されないようにします。
*つまり* [PyTorchのfunctional dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)に*model.training*を渡します。
問題を修正する最良の方法は、通常、元の実装と🤗 Transformers実装のフォワードパスを並べて表示し、違いがあるかどうかを確認することです。
理想的には、フォワードパスの両方の実装の中間出力をデバッグ/プリントアウトして、🤗 Transformers実装が元の実装と異なる出力を示すネットワーク内の正確な位置を見つけることができます。
最初に、両方のスクリプトのハードコーディングされた`input_ids`が同一であることを確認します。
次に、`input_ids`の最初の変換(通常、単語埋め込み)の出力が同一であることを確認します。
その後、ネットワークの最後のレイヤーまで作業を進めます。
いずれかの時点で、2つの実装間で違いがあることに気付くはずで、それにより🤗 Transformers実装のバグの場所が特定されます。
経験上、元の実装と🤗 Transformers実装のフォワードパスの同じ位置に多くのプリントステートメントを追加し、
中間プレゼンテーションで同じ値を示すプリントステートメントを段階的に削除するのがシンプルかつ効果的な方法です。
両方の実装が同じ出力を生成することに自信を持っている場合、`torch.allclose(original_output, output, atol=1e-3)`を使用して出力を確認すると、最も難しい部分が完了します!
おめでとうございます - 完了する作業は簡単なものになるはずです 😊。
**8. 必要なすべてのモデルテストを追加**
この時点で、新しいモデルが正常に追加されました。
ただし、モデルがまだ必要な設計に完全に準拠していない可能性が非常に高いです。
🤗 Transformersと完全に互換性があることを確認するために、すべての一般的なテストがパスする必要があります。
Cookiecutterはおそらくモデル用のテストファイルを自動的に追加しているはずで、おそらく同じディレクトリに`tests/models/brand_new_bert/test_modeling_brand_new_bert.py`として存在します。
このテストファイルを実行して、すべての一般的なテストがパスすることを確認してください:
```bash
pytest tests/models/brand_new_bert/test_modeling_brand_new_bert.py
```
すべての一般的なテストを修正したら、今度は実行したすべての素晴らしい作業が適切にテストされていることを確認することが非常に重要です。これにより、
- a) コミュニティは*brand_new_bert*の特定のテストを見ることで、あなたの作業を簡単に理解できます。
- b) モデルへの将来の変更がモデルの重要な機能を壊さないようにすることができます。
まず、統合テストを追加する必要があります。これらの統合テストは、基本的にはデバッグスクリプトと同じことを行います。これらのモデルテストのテンプレートはCookiecutterによって既に追加されており、「BrandNewBertModelIntegrationTests」と呼ばれています。このテストを記入するだけです。これらのテストが合格していることを確認するには、次のコマンドを実行します。
```bash
RUN_SLOW=1 pytest -sv tests/models/brand_new_bert/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
```
Windowsを使用している場合、`RUN_SLOW=1`を`SET RUN_SLOW=1`に置き換えてください。
次に、*brand_new_bert*に特有のすべての特徴は、別個のテスト内で追加されるべきです。
`BrandNewBertModelTester`/`BrandNewBertModelTest`の下に。この部分はよく忘れられますが、2つの点で非常に役立ちます:
- モデルの追加中に獲得した知識をコミュニティに伝え、*brand_new_bert*の特別な機能がどのように動作するかを示すことによって、知識の共有を支援します。
- 将来の貢献者は、これらの特別なテストを実行することでモデルへの変更を迅速にテストできます。
**9. トークナイザの実装**
次に、*brand_new_bert*のトークナイザを追加する必要があります。通常、トークナイザは🤗 Transformersの既存のトークナイザと同等か非常に似ています。
トークナイザが正しく動作することを確認するためには、まず、元のリポジトリ内で文字列を入力し、`input_ids`を返すスクリプトを作成することをお勧めします。
このスクリプトは、次のように見えるかもしれません(疑似コードで示します):
```python
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
オリジナルのリポジトリを詳しく調査し、正しいトークナイザの関数を見つける必要があるかもしれません。
または、オリジナルのリポジトリのクローンを変更して、`input_ids`だけを出力するようにする必要があるかもしれません。
オリジナルのリポジトリを使用した機能的なトークナイゼーションスクリプトを作成した後、
🤗 Transformers向けの類似したスクリプトを作成する必要があります。
以下のように見えるべきです:
```python
from transformers import BrandNewBertTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
`input_ids`が同じ値を生成した場合、最終ステップとしてトークナイザのテストファイルも追加するべきです。
*brand_new_bert*のモデルングテストファイルと同様に、*brand_new_bert*のトークナイズテストファイルには、いくつかのハードコードされた統合テストが含まれるべきです。
**10. エンドツーエンド統合テストの実行**
トークナイザを追加した後、`🤗 Transformers`内の`tests/models/brand_new_bert/test_modeling_brand_new_bert.py`に
モデルとトークナイザの両方を使用するいくつかのエンドツーエンド統合テストも追加する必要があります。
このようなテストは、🤗 Transformersの実装が期待どおりに機能することを示すべきです。
意味のあるテキスト対テキストのサンプルが含まれます。有用なテキスト対テキストのサンプルには、ソースからターゲットへの翻訳ペア、記事から要約へのペア、質問から回答へのペアなどが含まれます。
ポートされたチェックポイントがダウンストリームタスクでファインチューニングされていない場合、モデルのテストに依存するだけで十分です。
モデルが完全に機能していることを確認するために、すべてのテストをGPU上で実行することもお勧めします。
モデルの内部テンソルに`.to(self.device)`ステートメントを追加するのを忘れる可能性があるため、そのようなテストではエラーが表示されることがあります。
GPUにアクセスできない場合、Hugging Faceチームが代わりにこれらのテストを実行できます。
**11. ドキュメントの追加**
これで、*brand_new_bert*の必要なすべての機能が追加されました - ほぼ完了です!残りの追加すべきことは、良いドキュメントとドキュメントページです。
Cookiecutterが`docs/source/model_doc/brand_new_bert.md`というテンプレートファイルを追加しているはずで、これを記入する必要があります。
モデルのユーザーは通常、モデルを使用する前にまずこのページを見ます。したがって、ドキュメンテーションは理解しやすく簡潔である必要があります。
モデルの使用方法を示すためにいくつかの*Tips*を追加することはコミュニティにとって非常に役立ちます。ドキュメンテーションに関しては、Hugging Faceチームに問い合わせることをためらわないでください。
次に、`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`に追加されたドキュメンテーション文字列が正しいこと、およびすべての必要な入力および出力を含んでいることを確認してください。
ドキュメンテーションの書き方とドキュメンテーション文字列のフォーマットについて詳細なガイドが[こちら](writing-documentation)にあります。
ドキュメンテーションは通常、コミュニティとモデルの最初の接触点であるため、コードと同じくらい注意深く扱うべきであることを常に念頭に置いてください。
**コードのリファクタリング**
素晴らしい、これで*brand_new_bert*に必要なすべてのコードが追加されました。
この時点で、次のようなポテンシャルなコードスタイルの誤りを訂正するために以下を実行する必要があります:
```bash
make style
```
あなたのコーディングスタイルが品質チェックをパスすることを確認してください:
```bash
make quality
```
🤗 Transformersの非常に厳格なデザインテストには、まだ合格していない可能性があるいくつかの他のテストが存在するかもしれません。
これは、ドキュメント文字列に情報が不足しているか、名前が間違っていることが原因であることが多いです。Hugging Faceチームは、ここで詰まっている場合には必ず助けてくれるでしょう。
最後に、コードが正しく機能することを確認した後、コードをリファクタリングするのは常に良いアイデアです。
すべてのテストがパスした今、追加したコードを再度確認してリファクタリングを行うのは良いタイミングです。
これでコーディングの部分は完了しました、おめでとうございます! 🎉 あなたは素晴らしいです! 😎
**12. モデルをモデルハブにアップロード**
最後のパートでは、すべてのチェックポイントをモデルハブに変換してアップロードし、各アップロードしたモデルチェックポイントにモデルカードを追加する必要があります。
モデルハブの機能について詳しくは、[Model sharing and uploading Page](model_sharing)を読んで理解できます。
ここでは、*brand_new_bert*の著者組織の下にモデルをアップロードできるように必要なアクセス権を取得するために、Hugging Faceチームと協力する必要があります。
`transformers`のすべてのモデルに存在する`push_to_hub`メソッドは、チェックポイントをハブにプッシュする迅速かつ効率的な方法です。
以下に、少しのコードスニペットを示します:
```python
brand_new_bert.push_to_hub("brand_new_bert")
# Uncomment the following line to push to an organization.
# brand_new_bert.push_to_hub("/brand_new_bert")
```
各チェックポイントに適切なモデルカードを作成する価値があります。モデルカードは、この特定のチェックポイントの特性をハイライトするべきです。例えば、このチェックポイントはどのデータセットで事前学習/ファインチューニングされたか、どのような下流タスクでモデルを使用すべきかを示すべきです。また、モデルの正しい使用方法に関するコードも含めるべきです。
**13.(オプション)ノートブックの追加**
*brand_new_bert*を推論または下流タスクのファインチューニングにどのように詳細に使用できるかを示すノートブックを追加することは非常に役立ちます。これはあなたのPRをマージするために必須ではありませんが、コミュニティにとって非常に有用です。
**14. 完成したPRの提出**
プログラミングが完了したら、最後のステップに移動し、PRをメインブランチにマージしましょう。通常、Hugging Faceチームはこの時点で既にあなたをサポートしているはずですが、PRに良い説明を追加し、コードにコメントを追加して、レビュアーに特定の設計の選択肢を指摘したい場合はコメントを追加することも価値があります。
### Share your work!!
さあ、コミュニティからあなたの作業に対する評価を得る時が来ました!モデルの追加を完了することは、TransformersおよびNLPコミュニティにとって重要な貢献です。あなたのコードとポートされた事前学習済みモデルは、何百人、何千人という開発者や研究者によって確実に使用されるでしょう。あなたの仕事に誇りを持ち、コミュニティとあなたの成果を共有しましょう。
**あなたはコミュニティの誰でも簡単にアクセスできる別のモデルを作成しました! 🤯**
ご覧のように、🤗 Transformersでは継承を使用していますが、抽象化のレベルを最小限に保っています。
ライブラリ内のどのモデルにも、抽象化のレベルが2つを超えることはありません。
`BrandNewBertModel` は `BrandNewBertPreTrainedModel` を継承し、さらに[`PreTrainedModel`]を継承しています。
これだけです。
一般的なルールとして、新しいモデルは[`PreTrainedModel`]にのみ依存するようにしたいと考えています。
すべての新しいモデルに自動的に提供される重要な機能は、[`~PreTrainedModel.from_pretrained`]および
[`~PreTrainedModel.save_pretrained`]です。
これらはシリアライゼーションとデシリアライゼーションに使用されます。
`BrandNewBertModel.forward`などの他の重要な機能は、新しい「modeling_brand_new_bert.py」スクリプトで完全に定義されるべきです。
次に、特定のヘッドレイヤーを持つモデル(たとえば `BrandNewBertForMaskedLM` )が `BrandNewBertModel` を継承するのではなく、
抽象化のレベルを低く保つために、そのフォワードパスで `BrandNewBertModel` を呼び出すコンポーネントとして使用されるようにしたいと考えています。
新しいモデルには常に `BrandNewBertConfig` という設定クラスが必要です。この設定は常に[`PreTrainedModel`]の属性として保存され、
したがって、`BrandNewBertPreTrainedModel`から継承するすべてのクラスで`config`属性を介してアクセスできます。
```python
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
モデルと同様に、設定は[`PretrainedConfig`]から基本的なシリアル化および逆シリアル化の機能を継承しています。注意すべきは、設定とモデルは常に2つの異なる形式にシリアル化されることです - モデルは*pytorch_model.bin*ファイルに、設定は*config.json*ファイルにシリアル化されます。[`~PreTrainedModel.save_pretrained`]を呼び出すと、自動的に[`~PretrainedConfig.save_pretrained`]も呼び出され、モデルと設定の両方が保存されます。
### Code style
新しいモデルをコーディングする際には、Transformersは意見があるライブラリであり、コードの書き方に関していくつかの独自の考え方があります :-)
1. モデルのフォワードパスはモデリングファイルに完全に記述され、ライブラリ内の他のモデルとは完全に独立している必要があります。他のモデルからブロックを再利用したい場合、コードをコピーしてトップに`# Copied from`コメントを付けて貼り付けます(良い例は[こちら](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)、コピーに関する詳細なドキュメンテーションは[ここ](pr_checks#check-copies)を参照してください)。
2. コードは完全に理解可能でなければなりません。これは記述的な変数名を選択し、省略形を避けるべきであることを意味します。例えば、`act`ではなく`activation`が好まれます。1文字の変数名は、forループ内のインデックスでない限り、強く非推奨です。
3. より一般的に、魔法のような短いコードよりも長くて明示的なコードを好みます。
4. PyTorchでは`nn.Sequential`をサブクラス化せずに、`nn.Module`をサブクラス化し、フォワードパスを記述し、コードを使用する他の人が簡単にデバッグできるようにします。プリントステートメントやブレークポイントを追加してデバッグできるようにします。
5. 関数のシグネチャは型アノテーションを付けるべきです。その他の部分に関しては、型アノテーションよりも良い変数名が読みやすく理解しやすいことがあります。
### Overview of tokenizers
まだ完了していません :-( このセクションは近日中に追加されます!
## Step-by-step recipe to add a model to 🤗 Transformers
モデルを追加する方法は人それぞれ異なるため、他のコントリビューターが🤗 Transformersにモデルを追加する際の要約を確認することが非常に役立つ場合があります。以下は、他のコントリビューターが🤗 Transformersにモデルをポートする際のコミュニティブログ投稿のリストです。
1. [GPT2モデルのポーティング](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) by [Thomas](https://huggingface.co/thomwolf)
2. [WMT19 MTモデルのポーティング](https://huggingface.co/blog/porting-fsmt) by [Stas](https://huggingface.co/stas)
経験から言えることは、モデルを追加する際に最も重要なことは次のようになります:
- 車輪の再発明をしないでください!新しい🤗 Transformersモデルのために追加するコードのほとんどはすでに🤗 Transformers内のどこかに存在しています。類似した既存のモデルやトークナイザを見つけるために、いくつかの時間をかけて探すことが重要です。[grep](https://www.gnu.org/software/grep/)と[rg](https://github.com/BurntSushi/ripgrep)はあなたの友達です。モデルのトークナイザは1つのモデル実装に基づいているかもしれませんが、モデルのモデリングコードは別の実装に基づいていることがあることに注意してください。例えば、FSMTのモデリングコードはBARTに基づいており、FSMTのトークナイザコードはXLMに基づいています。
- これは科学的な課題よりもエンジニアリングの課題です。モデルの論文の理論的な側面をすべて理解しようとするよりも、効率的なデバッグ環境を作成するために時間を費やすべきです。
- 行き詰まった場合は助けを求めてください!モデルは🤗 Transformersのコアコンポーネントであり、Hugging Faceではモデルを追加するための各ステップでお手伝いするのを喜んでいます。進行がないことに気付いた場合は、進展していないことを気にしないでください。
以下では、🤗 Transformersにモデルをポートする際に最も役立つと考えられる一般的なレシピを提供しようとしています。
次のリストは、モデルを追加するために行う必要があるすべてのことの要約であり、To-Doリストとして使用できます:
- ☐ (オプション)モデルの理論的な側面を理解しました
- ☐ 🤗 Transformersの開発環境を準備しました
- ☐ オリジナルのリポジトリのデバッグ環境をセットアップしました
- ☐ `forward()` パスをオリジナルのリポジトリとチェックポイントで正常に実行するスクリプトを作成しました
- ☐ モデルの骨格を🤗 Transformersに正常に追加しました
- ☐ オリジナルのチェックポイントを🤗 Transformersのチェックポイントに正常に変換しました
- ☐ 🤗 Transformersで実行される `forward()` パスを正常に実行し、オリジナルのチェックポイントと同一の出力を得ました
- ☐ 🤗 Transformersでのモデルテストを完了しました
- ☐ 🤗 Transformersにトークナイザを正常に追加しました
- ☐ エンドツーエンドの統合テストを実行しました
- ☐ ドキュメントを完成させました
- ☐ モデルのウェイトをHubにアップロードしました
- ☐ プルリクエストを提出しました
- ☐ (オプション)デモノートブックを追加しました
まず、通常、`BrandNewBert`の理論的な理解を深めることをお勧めします。
ただし、もしモデルの理論的な側面を「実務中に理解する」方が好ましい場合、`BrandNewBert`のコードベースに直接アクセスするのも問題ありません。
このオプションは、エンジニアリングのスキルが理論的なスキルよりも優れている場合、
`BrandNewBert`の論文を理解するのに苦労している場合、または科学的な論文を読むよりもプログラミングを楽しんでいる場合に適しています。
### 1. (Optional) Theoretical aspects of BrandNewBert
BrandNewBertの論文がある場合、その説明を読むための時間を取るべきです。論文の中には理解が難しい部分があるかもしれません。
その場合でも心配しないでください。目標は論文の深い理論的理解を得ることではなく、
🤗 Transformersでモデルを効果的に再実装するために必要な情報を抽出することです。
ただし、理論的な側面にあまり多くの時間をかける必要はありません。代わりに、実践的な側面に焦点を当てましょう。具体的には次の点です:
- *brand_new_bert*はどの種類のモデルですか? BERTのようなエンコーダーのみのモデルですか? GPT2のようなデコーダーのみのモデルですか? BARTのようなエンコーダー-デコーダーモデルですか?
[model_summary](model_summary)を参照して、これらの違いについて詳しく知りたい場合があります。
- *brand_new_bert*の応用分野は何ですか? テキスト分類ですか? テキスト生成ですか? Seq2Seqタスク、例えば要約ですか?
- モデルをBERT/GPT-2/BARTとは異なるものにする新しい機能は何ですか?
- 既存の[🤗 Transformersモデル](https://huggingface.co/transformers/#contents)の中で*brand_new_bert*に最も似ているモデルはどれですか?
- 使用されているトークナイザの種類は何ですか? SentencePieceトークナイザですか? WordPieceトークナイザですか? BERTやBARTで使用されているトークナイザと同じですか?
モデルのアーキテクチャの良い概要を得たと感じたら、Hugging Faceチームに質問を送ることができます。
これにはモデルのアーキテクチャ、注意層などに関する質問が含まれるかもしれません。
私たちは喜んでお手伝いします。
### 2. Next prepare your environment
1. リポジトリのページで「Fork」ボタンをクリックして、[リポジトリ](https://github.com/huggingface/transformers)をフォークします。
これにより、コードのコピーがGitHubユーザーアカウントの下に作成されます。
2. ローカルディスクにある`transformers`フォークをクローンし、ベースリポジトリをリモートとして追加します:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
3. 開発環境をセットアップするために、次のコマンドを実行してください:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
お使いのOSに応じて、およびTransformersのオプションの依存関係の数が増えているため、このコマンドでエラーが発生する可能性があります。
その場合は、作業しているDeep Learningフレームワーク(PyTorch、TensorFlow、および/またはFlax)をインストールし、次の手順を実行してください:
```bash
pip install -e ".[quality]"
```
これはほとんどのユースケースには十分であるはずです。その後、親ディレクトリに戻ることができます。
```bash
cd ..
```
4. Transformersに*brand_new_bert*のPyTorchバージョンを追加することをお勧めします。PyTorchをインストールするには、
https://pytorch.org/get-started/locally/ の指示に従ってください。
**注意:** CUDAをインストールする必要はありません。新しいモデルをCPUで動作させることで十分です。
5. *brand_new_bert*を移植するには、元のリポジトリへのアクセスも必要です。
```bash
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
cd brand_new_bert
pip install -e .
```
*brand_new_bert*を🤗 Transformersにポートするための開発環境を設定しました。
### 3.-4. Run a pretrained checkpoint using the original repository
最初に、オリジナルの*brand_new_bert*リポジトリで作業します。通常、オリジナルの実装は非常に「研究的」であり、ドキュメンテーションが不足していたり、コードが理解しにくいことがあります。しかし、これが*brand_new_bert*を再実装する動機となるべきです。Hugging Faceでは、主要な目標の1つが、動作するモデルを取り、それをできるだけ**アクセス可能でユーザーフレンドリーで美しい**ものに書き直すことです。これは、🤗 Transformersにモデルを再実装する最も重要な動機です - 複雑な新しいNLP技術を**誰にでも**アクセス可能にしようとする試みです。
まず、オリジナルのリポジトリに入り込むことから始めるべきです。
公式の事前学習済みモデルをオリジナルのリポジトリで正常に実行することは、通常、**最も困難な**ステップです。
私たちの経験から、オリジナルのコードベースに慣れるのに時間をかけることが非常に重要です。以下のことを理解する必要があります:
- 事前学習済みの重みをどこで見つけるか?
- 対応するモデルに事前学習済みの重みをロードする方法は?
- モデルから独立してトークナイザを実行する方法は?
- 1つのフォワードパスを追跡して、単純なフォワードパスに必要なクラスと関数がわかるようにします。通常、これらの関数だけを再実装する必要があります。
- モデルの重要なコンポーネントを特定できること:モデルのクラスはどこにありますか?モデルのサブクラス、*例* EncoderModel、DecoderModelがありますか?自己注意レイヤーはどこにありますか?複数の異なる注意レイヤー、*例* *自己注意*、*クロスアテンション*などが存在しますか?
- オリジナルのリポジトリの環境でモデルをデバッグする方法は?*print*ステートメントを追加する必要があるか、*ipdb*のような対話型デバッガを使用できるか、PyCharmのような効率的なIDEを使用してモデルをデバッグする必要がありますか?
重要なのは、ポーティングプロセスを開始する前に、オリジナルのリポジトリでコードを**効率的に**デバッグできることです!また、これはオープンソースライブラリで作業していることを覚えておいてください。オリジナルのリポジトリでコードを調べる誰かを歓迎するために、問題をオープンにしたり、プルリクエストを送信したりすることをためらわないでください。このリポジトリのメンテナーは、彼らのコードを調べてくれる人に対して非常に喜んでいる可能性が高いです!
この段階では、オリジナルのモデルのデバッグにどのような環境と戦略を使用するかは、あなた次第です。最初にオリジナルのリポジトリに関するコードをデバッグできることが非常に重要です。また、GPU環境をセットアップすることはお勧めしません。まず、CPU上で作業し、モデルがすでに🤗 Transformersに正常にポートされていることを確認します。最後に、モデルがGPU上でも期待通りに動作するかどうかを検証する必要があります。
一般的に、オリジナルのモデルを実行するための2つのデバッグ環境があります:
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- ローカルなPythonスクリプト。
Jupyterノートブックは、セルごとに実行できるため、論理的なコンポーネントをより分割し、中間結果を保存できるため、デバッグサイクルが速くなるという利点があります。また、ノートブックは他の共同作業者と簡単に共有できることが多く、Hugging Faceチームに助けを求める場合に非常に役立つ場合があります。Jupyterノートブックに精通している場合、それ
```python
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
デバッグ戦略については、通常、いくつかの選択肢があります:
- 元のモデルを多くの小さなテスト可能なコンポーネントに分解し、それぞれに対して前方パスを実行して検証します
- 元のモデルを元のトークナイザと元のモデルにのみ分解し、それらに対して前方パスを実行し、検証のために中間のプリントステートメントまたはブレークポイントを使用します
再度、どの戦略を選択するかはあなた次第です。元のコードベースに依存することが多く、元のコードベースに応じて一方または他方が有利なことがあります。
元のコードベースがモデルを小さなサブコンポーネントに分解できる場合、*例えば*元のコードベースが簡単にイーガーモードで実行できる場合、それを行う価値が通常あります。最初からより難しい方法を選択することにはいくつかの重要な利点があります:
- 後で元のモデルを🤗 Transformersの実装と比較する際に、各コンポーネントが対応する🤗 Transformers実装のコンポーネントと一致することを自動的に検証できるため、視覚的な比較に依存せずに済みます
- 大きな問題を小さな問題に分解する、つまり個々のコンポーネントのみをポーティングする問題に分割するのに役立ち、作業を構造化するのに役立ちます
- モデルを論理的な意味のあるコンポーネントに分割することで、モデルの設計をよりよく理解しやすくし、モデルをよりよく理解するのに役立ちます
- 後で、コンポーネントごとのテストを行うことで、コードを変更し続ける際にリグレッションが発生しないことを確認するのに役立ちます
[Lysandreの](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed) ELECTRAの統合チェックは、これがどのように行われるかの良い例です。
ただし、元のコードベースが非常に複雑で、中間コンポーネントをコンパイルモードで実行することしか許可しない場合、モデルを小さなテスト可能なサブコンポーネントに分解することが時間がかかりすぎるか、不可能であることがあります。
良い例は[T5のMeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow)ライブラリであり、非常に複雑でモデルをサブコンポーネントに分解する簡単な方法を提供しないことがあります。このようなライブラリでは、通常、プリントステートメントを検証することに依存します。
どの戦略を選択しても、推奨される手順は通常同じで、最初のレイヤーからデバッグを開始し、最後のレイヤーからデバッグを行うべきです。
通常、以下の順序で次のレイヤーからの出力を取得することをお勧めします:
1. モデルに渡された入力IDを取得する
2. 単語の埋め込みを取得する
3. 最初のTransformerレイヤーの入力を取得する
4. 最初のTransformerレイヤーの出力を取得する
5. 次のn - 1つのTransformerレイヤーの出力を取得する
6. BrandNewBertモデル全体の出力を取得する
入力IDは整数の配列である必要があり、*例:* `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]` のようになります。
以下のレイヤーの出力は多次元の浮動小数点配列であることが多く、次のようになることがあります:
```
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
🤗 Transformersに追加されるすべてのモデルは、統合テストを数回合格することが期待されており、元のモデルと🤗 Transformersで再実装されたバージョンが、0.001の精度までまったく同じ出力を提供する必要があります。
異なるライブラリフレームワークで同じモデルを書いた場合、わずかに異なる出力を返すことが正常であるため、誤差許容値として1e-3(0.001)を受け入れています。モデルがほぼ同じ出力を返すだけでは不十分で、ほぼ同一である必要があります。そのため、🤗 Transformersバージョンの中間出力を元の*brand_new_bert*の実装の中間出力と複数回にわたって比較することになるでしょう。その際、元のリポジトリの**効率的な**デバッグ環境が非常に重要です。以下は、デバッグ環境をできるだけ効率的にするためのアドバイスです。
- 中間結果をデバッグする最適な方法を見つける。元のリポジトリはPyTorchで書かれていますか?その場合、元のモデルをより小さなサブコンポーネントに分解して中間値を取得する長いスクリプトを書くことがおそらく適切です。元のリポジトリがTensorflow 1で書かれている場合、[tf.print](https://www.tensorflow.org/api_docs/python/tf/print)などのTensorFlowのプリント操作を使用して中間値を出力する必要があるかもしれません。元のリポジトリがJaxで書かれている場合、フォワードパスの実行時にモデルが**jittedされていない**ことを確認してください。例:[このリンク](https://github.com/google/jax/issues/196)をチェック。
- 使用可能な最小の事前学習済みチェックポイントを使用します。チェックポイントが小さいほど、デバッグサイクルが速くなります。事前学習済みモデルがフォワードパスに10秒以上かかる場合、効率的ではありません。非常に大きなチェックポイントしか利用できない場合、新しい環境でランダムに初期化されたウェイトを持つダミーモデルを作成し、それらのウェイトを🤗 Transformersバージョンのモデルと比較する方が良いかもしれません。
- 元のリポジトリでフォワードパスを呼び出す最も簡単な方法を使用していることを確認してください。理想的には、元のリポジトリで**単一のフォワードパス**を呼び出す関数を見つけたいです。これは通常「predict」、「evaluate」、「forward」、「__call__」と呼ばれます。複数回「forward」を呼び出す関数をデバッグしたくありません。例:テキストを生成するために「autoregressive_sample」、「generate」と呼ばれる関数。
- トークナイゼーションとモデルの「フォワード」パスを分離しようとしてください。元のリポジトリが入力文字列を入力する必要がある例を示す場合、フォワードコール内で文字列入力が入力IDに変更される場所を特定し、このポイントから開始します。これは、スクリプトを自分で書くか、入力文字列ではなく入力IDを直接入力できるように元のコードを変更する必要があるかもしれません。
- デバッグセットアップ内のモデルがトレーニングモードではないことを確認してください。トレーニングモードでは、モデル内の複数のドロップアウトレイヤーのためにランダムな出力が生成されることがあります。デバッグ環境のフォワードパスが**決定論的**であることを確認し、ドロップアウトレイヤーが使用されないようにします。または、新しい実装が同じフレームワーク内にある場合、*transformers.utils.set_seed*を使用してください。
以下のセクションでは、*brand_new_bert*についてこれを具体的にどのように行うかについての詳細/ヒントを提供します。
### 5.-14. Port BrandNewBert to 🤗 Transformers
次に、ついに新しいコードを🤗 Transformersに追加できます。🤗 Transformersのフォークのクローンに移動してください:
```bash
cd transformers
```
特別なケースとして、既存のモデルと完全に一致するアーキテクチャのモデルを追加する場合、
[このセクション](#write-a-conversion-script)で説明されているように、変換スクリプトを追加するだけで済みます。
この場合、既存のモデルの完全なモデルアーキテクチャを再利用できます。
それ以外の場合は、新しいモデルの生成を開始しましょう。 次のスクリプトを使用して、以下から始まるモデルを追加することをお勧めします。
既存のモデル:
```bash
transformers add-new-model-like
```
モデルの基本情報を入力するためのアンケートが表示されます。
**主要な huggingface/transformers リポジトリでプルリクエストを開く**
自動生成されたコードを適応し始める前に、🤗 Transformers に「作業中(WIP)」プルリクエストを開くタイミングです。
例:「[WIP] *brand_new_bert* を追加」などです。
これにより、ユーザーと Hugging Face チームが🤗 Transformers にモデルを統合する作業を並行して行うことができます。
以下の手順を実行してください:
1. メインブランチから分かりやすい名前のブランチを作成します。
```bash
git checkout -b add_brand_new_bert
```
2. 自動生成されたコードをコミットしてください:
```bash
git add .
git commit
```
3. 現在の main ブランチにフェッチしてリベース
```bash
git fetch upstream
git rebase upstream/main
```
4. 変更をあなたのアカウントにプッシュするには、次のコマンドを使用します:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
5. 満足したら、GitHub上のフォークのウェブページに移動します。[プルリクエスト]をクリックします。将来の変更に備えて、Hugging Face チームのメンバーのGitHubハンドルをレビュアーとして追加してください。
6. GitHubのプルリクエストウェブページの右側にある「ドラフトに変換」をクリックして、PRをドラフトに変更します。
以下では、進捗があった場合は常に作業をコミットし、プッシュしてプルリクエストに表示されるようにしてください。さらに、定期的にメインからの最新の変更を取り込むために、次のように行うことを忘れないでください:
```bash
git fetch upstream
git merge upstream/main
```
一般的に、モデルや実装に関する質問はPull Request (PR) で行い、PR内で議論し、解決します。
これにより、Hugging Face チームは新しいコードをコミットする際や質問がある場合に常に通知を受けることができます。
質問や問題が解決された際に、問題や質問が理解されやすいように、Hugging Face チームにコードを指摘することが非常に役立ちます。
このためには、「Files changed」タブに移動してすべての変更を表示し、質問したい行に移動して「+」シンボルをクリックしてコメントを追加します。
質問や問題が解決された場合は、作成されたコメントの「Resolve」ボタンをクリックできます。
同様に、Hugging Face チームはコードをレビューする際にコメントを開きます。
PR上でのほとんどの質問はGitHub上で行うことをお勧めします。
一般的な質問に関しては、公にはあまり役立たない質問については、SlackやメールでHugging Face チームに連絡することもできます。
**5. 生成されたモデルコードを"brand_new_bert"に適応させる**
最初に、モデル自体に焦点を当て、トークナイザには気にしないでください。
関連するコードは、生成されたファイル`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`および`src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`で見つかるはずです。
さて、ついにコーディングを始めることができます :smile:。
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`にある生成されたコードは、エンコーダーのみのモデルであればBERTと同じアーキテクチャを持っているか、エンコーダー-デコーダーモデルであればBARTと同じアーキテクチャを持っているはずです。
この段階では、モデルの理論的な側面について学んだことを思い出すべきです。つまり、「このモデルはBERTまたはBARTとどのように異なるのか?」ということです。
これらの変更を実装しますが、これは通常、セルフアテンションレイヤー、正規化レイヤーの順序などを変更することを意味します。
再び、あなたのモデルがどのように実装されるべきかをより良く理解するために、Transformers内に既存のモデルの類似アーキテクチャを見ることが役立つことがあります。
この時点では、コードが完全に正確またはクリーンである必要はありません。
むしろ、まずは必要なコードの最初の*クリーンでない*コピー&ペーストバージョンを
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`に追加し、必要なコードがすべて追加されていると感じるまで改善/修正を反復的に行うことがお勧めです。
私たちの経験から、必要なコードの最初のバージョンを迅速に追加し、次のセクションで説明する変換スクリプトを使用してコードを繰り返し改善/修正する方が効率的であることが多いです。
この時点で動作する必要があるのは、🤗 Transformersの"brand_new_bert"の実装をインスタンス化できることだけです。つまり、以下のコマンドが機能する必要があります:
```python
from transformers import BrandNewBertModel, BrandNewBertConfig
model = BrandNewBertModel(BrandNewBertConfig())
```
上記のコマンドは、`BrandNewBertConfig()` で定義されたデフォルトパラメータに従ってモデルを作成し、
すべてのコンポーネントの `init()` メソッドが正常に動作することを確認します。
すべてのランダムな初期化は、`BrandnewBertPreTrainedModel` クラスの `_init_weights` メソッドで行う必要があります。
このメソッドは、設定変数に依存するすべてのリーフモジュールを初期化する必要があります。以下は、BERT の `_init_weights` メソッドの例です:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
```
特定のモジュールに特別な初期化が必要な場合、カスタムスキームをさらに持つことができます。たとえば、
`Wav2Vec2ForPreTraining`では、最後の2つの線形層には通常のPyTorchの`nn.Linear`の初期化が必要ですが、
他のすべての層は上記のような初期化を使用する必要があります。これは以下のようにコーディングされています:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, Wav2Vec2ForPreTraining):
module.project_hid.reset_parameters()
module.project_q.reset_parameters()
module.project_hid._is_hf_initialized = True
module.project_q._is_hf_initialized = True
elif isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
```
`_is_hf_initialized`フラグは、サブモジュールを一度だけ初期化することを確実にするために内部で使用されます。
`module.project_q`と`module.project_hid`のためにそれを`True`に設定することで、
カスタム初期化が後で上書きされないようにし、`_init_weights`関数がそれらに適用されないようにします。
**6. 変換スクリプトを書く**
次に、*brand_new_bert* の元のリポジトリでデバッグに使用したチェックポイントを、新しく作成した 🤗 Transformers 実装の *brand_new_bert* と互換性のあるチェックポイントに変換できる変換スクリプトを書く必要があります。
変換スクリプトをゼロから書くことはお勧めされませんが、代わりに 🤗 Transformers で既に存在する類似のモデルを同じフレームワークで変換したスクリプトを調べることが良いでしょう。
通常、既存の変換スクリプトをコピーして、自分のユースケースにわずかに適応させることで十分です。
Hugging Face チームに既存のモデルに類似した変換スクリプトを教えてもらうことも躊躇しないでください。
- TensorFlowからPyTorchにモデルを移植している場合、良い出発点はBERTの変換スクリプトかもしれません [here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- PyTorchからPyTorchにモデルを移植している場合、良い出発点はBARTの変換スクリプトかもしれません [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
以下では、PyTorchモデルが層の重みをどのように保存し、層の名前を定義するかについて簡単に説明します。
PyTorchでは、層の名前は層に与えるクラス属性の名前によって定義されます。
PyTorchで `SimpleModel` というダミーモデルを定義しましょう:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
これで、このモデル定義のインスタンスを作成し、`dense`、`intermediate`、`layer_norm`のすべての重みをランダムな重みで埋めたモデルを作成できます。モデルのアーキテクチャを確認するために、モデルを印刷してみましょう。
```python
model = SimpleModel()
print(model)
```
これは以下を出力します:
```
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
層の名前はPyTorchのクラス属性の名前によって定義されています。特定の層の重み値を出力することができます:
```python
print(model.dense.weight.data)
```
ランダムに初期化された重みを確認するために
```
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
スクリプト内の変換スクリプトでは、ランダムに初期化された重みを、対応するチェックポイント内の正確な重みで埋める必要があります。例えば、以下のように翻訳します:
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
PyTorchモデルの各ランダム初期化された重みと対応する事前学習済みチェックポイントの重みが
**形状と名前の両方**で正確に一致することを確認する必要があります。
これを行うために、形状に対するassertステートメントを追加し、チェックポイントの重みの名前を出力することが
**必要不可欠**です。例えば、次のようなステートメントを追加する必要があります:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
また、両方の重みの名前を印刷して、一致していることを確認する必要があります。例えば、次のようにします:
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
もし形状または名前のいずれかが一致しない場合、おそらく誤って🤗 Transformersの実装に初期化されたレイヤーに間違ったチェックポイントの重みを割り当ててしまった可能性があります。
誤った形状は、おそらく`BrandNewBertConfig()`での設定パラメーターが、変換したいチェックポイントで使用されたものと正確に一致しないためです。
ただし、PyTorchのレイヤーの実装によっては、重みを事前に転置する必要がある場合もあります。
最後に、**すべて**の必要な重みが初期化されていることを確認し、初期化に使用されなかったすべてのチェックポイントの重みを表示して、モデルが正しく変換されていることを確認してください。
変換トライアルが誤った形状ステートメントまたは誤った名前割り当てで失敗するのは完全に正常です。
これはおそらく、`BrandNewBertConfig()`で誤ったパラメーターを使用したか、🤗 Transformersの実装に誤ったアーキテクチャがあるか、🤗 Transformersの実装の1つのコンポーネントの`init()`関数にバグがあるか、チェックポイントの重みの1つを転置する必要があるためです。
このステップは、以前のステップと繰り返すべきです。すべてのチェックポイントの重みが正しく🤗 Transformersモデルに読み込まれるまで繰り返すべきです。
🤗 Transformers実装に正しくチェックポイントを読み込んだ後、選択したフォルダーにモデルを保存できます `/path/to/converted/checkpoint/folder`。このフォルダには`pytorch_model.bin`ファイルと`config.json`ファイルの両方が含まれるはずです。
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. 順伝播(forward pass)の実装**
🤗 Transformers実装で事前学習済みの重みを正しく読み込んだ後、順伝播が正しく実装されていることを確認する必要があります。[元のリポジトリを理解する](#3-4-run-a-pretrained-checkpoint-using-the-original-repository)で、元のリポジトリを使用してモデルの順伝播を実行するスクリプトをすでに作成しました。今度は、元のリポジトリの代わりに🤗 Transformers実装を使用して類似のスクリプトを作成する必要があります。以下のようになります:
```python
model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
🤗 Transformersの実装と元のモデルの実装が最初の実行で完全に同じ出力を提供しないか、
フォワードパスでエラーが発生する可能性が非常に高いです。失望しないでください - これは予想されていることです!
まず、フォワードパスがエラーをスローしないことを確認する必要があります。
間違った次元が使用され、*次元の不一致*エラーや、誤ったデータ型オブジェクトが使用されることがよくあります。
例えば、`torch.long`ではなく`torch.float32`が使用されます。特定のエラーを解決できない場合は、
Hugging Faceチームに助けを求めることを躊躇しないでください。
🤗 Transformers実装が正しく機能することを確認する最終的な部分は、出力が`1e-3`の精度で同等であることを確認することです。
まず、出力の形状が同一であること、つまりスクリプトの🤗 Transformers実装と元の実装の両方で`outputs.shape`が同じ値を生成する必要があります。
次に、出力値が同一であることを確認する必要があります。
これは新しいモデルを追加する際の最も難しい部分の1つです。
出力が同一でない理由の一般的な間違いは以下の通りです。
- 一部のレイヤーが追加されていない、つまり*活性化*レイヤーが追加されていないか、リザバル接続が忘れられている
- 単語埋め込み行列が結ばれていない
- オリジナルの実装がオフセットを使用しているため、誤った位置埋め込みが使用されている
- フォワードパス中にドロップアウトが適用されています。これを修正するには、*model.trainingがFalse*であることを確認し、フォワードパス中に誤ってドロップアウトレイヤーがアクティブ化されないようにします。
*つまり* [PyTorchのfunctional dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)に*model.training*を渡します。
問題を修正する最良の方法は、通常、元の実装と🤗 Transformers実装のフォワードパスを並べて表示し、違いがあるかどうかを確認することです。
理想的には、フォワードパスの両方の実装の中間出力をデバッグ/プリントアウトして、🤗 Transformers実装が元の実装と異なる出力を示すネットワーク内の正確な位置を見つけることができます。
最初に、両方のスクリプトのハードコーディングされた`input_ids`が同一であることを確認します。
次に、`input_ids`の最初の変換(通常、単語埋め込み)の出力が同一であることを確認します。
その後、ネットワークの最後のレイヤーまで作業を進めます。
いずれかの時点で、2つの実装間で違いがあることに気付くはずで、それにより🤗 Transformers実装のバグの場所が特定されます。
経験上、元の実装と🤗 Transformers実装のフォワードパスの同じ位置に多くのプリントステートメントを追加し、
中間プレゼンテーションで同じ値を示すプリントステートメントを段階的に削除するのがシンプルかつ効果的な方法です。
両方の実装が同じ出力を生成することに自信を持っている場合、`torch.allclose(original_output, output, atol=1e-3)`を使用して出力を確認すると、最も難しい部分が完了します!
おめでとうございます - 完了する作業は簡単なものになるはずです 😊。
**8. 必要なすべてのモデルテストを追加**
この時点で、新しいモデルが正常に追加されました。
ただし、モデルがまだ必要な設計に完全に準拠していない可能性が非常に高いです。
🤗 Transformersと完全に互換性があることを確認するために、すべての一般的なテストがパスする必要があります。
Cookiecutterはおそらくモデル用のテストファイルを自動的に追加しているはずで、おそらく同じディレクトリに`tests/models/brand_new_bert/test_modeling_brand_new_bert.py`として存在します。
このテストファイルを実行して、すべての一般的なテストがパスすることを確認してください:
```bash
pytest tests/models/brand_new_bert/test_modeling_brand_new_bert.py
```
すべての一般的なテストを修正したら、今度は実行したすべての素晴らしい作業が適切にテストされていることを確認することが非常に重要です。これにより、
- a) コミュニティは*brand_new_bert*の特定のテストを見ることで、あなたの作業を簡単に理解できます。
- b) モデルへの将来の変更がモデルの重要な機能を壊さないようにすることができます。
まず、統合テストを追加する必要があります。これらの統合テストは、基本的にはデバッグスクリプトと同じことを行います。これらのモデルテストのテンプレートはCookiecutterによって既に追加されており、「BrandNewBertModelIntegrationTests」と呼ばれています。このテストを記入するだけです。これらのテストが合格していることを確認するには、次のコマンドを実行します。
```bash
RUN_SLOW=1 pytest -sv tests/models/brand_new_bert/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
```
Windowsを使用している場合、`RUN_SLOW=1`を`SET RUN_SLOW=1`に置き換えてください。
次に、*brand_new_bert*に特有のすべての特徴は、別個のテスト内で追加されるべきです。
`BrandNewBertModelTester`/`BrandNewBertModelTest`の下に。この部分はよく忘れられますが、2つの点で非常に役立ちます:
- モデルの追加中に獲得した知識をコミュニティに伝え、*brand_new_bert*の特別な機能がどのように動作するかを示すことによって、知識の共有を支援します。
- 将来の貢献者は、これらの特別なテストを実行することでモデルへの変更を迅速にテストできます。
**9. トークナイザの実装**
次に、*brand_new_bert*のトークナイザを追加する必要があります。通常、トークナイザは🤗 Transformersの既存のトークナイザと同等か非常に似ています。
トークナイザが正しく動作することを確認するためには、まず、元のリポジトリ内で文字列を入力し、`input_ids`を返すスクリプトを作成することをお勧めします。
このスクリプトは、次のように見えるかもしれません(疑似コードで示します):
```python
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
オリジナルのリポジトリを詳しく調査し、正しいトークナイザの関数を見つける必要があるかもしれません。
または、オリジナルのリポジトリのクローンを変更して、`input_ids`だけを出力するようにする必要があるかもしれません。
オリジナルのリポジトリを使用した機能的なトークナイゼーションスクリプトを作成した後、
🤗 Transformers向けの類似したスクリプトを作成する必要があります。
以下のように見えるべきです:
```python
from transformers import BrandNewBertTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
`input_ids`が同じ値を生成した場合、最終ステップとしてトークナイザのテストファイルも追加するべきです。
*brand_new_bert*のモデルングテストファイルと同様に、*brand_new_bert*のトークナイズテストファイルには、いくつかのハードコードされた統合テストが含まれるべきです。
**10. エンドツーエンド統合テストの実行**
トークナイザを追加した後、`🤗 Transformers`内の`tests/models/brand_new_bert/test_modeling_brand_new_bert.py`に
モデルとトークナイザの両方を使用するいくつかのエンドツーエンド統合テストも追加する必要があります。
このようなテストは、🤗 Transformersの実装が期待どおりに機能することを示すべきです。
意味のあるテキスト対テキストのサンプルが含まれます。有用なテキスト対テキストのサンプルには、ソースからターゲットへの翻訳ペア、記事から要約へのペア、質問から回答へのペアなどが含まれます。
ポートされたチェックポイントがダウンストリームタスクでファインチューニングされていない場合、モデルのテストに依存するだけで十分です。
モデルが完全に機能していることを確認するために、すべてのテストをGPU上で実行することもお勧めします。
モデルの内部テンソルに`.to(self.device)`ステートメントを追加するのを忘れる可能性があるため、そのようなテストではエラーが表示されることがあります。
GPUにアクセスできない場合、Hugging Faceチームが代わりにこれらのテストを実行できます。
**11. ドキュメントの追加**
これで、*brand_new_bert*の必要なすべての機能が追加されました - ほぼ完了です!残りの追加すべきことは、良いドキュメントとドキュメントページです。
Cookiecutterが`docs/source/model_doc/brand_new_bert.md`というテンプレートファイルを追加しているはずで、これを記入する必要があります。
モデルのユーザーは通常、モデルを使用する前にまずこのページを見ます。したがって、ドキュメンテーションは理解しやすく簡潔である必要があります。
モデルの使用方法を示すためにいくつかの*Tips*を追加することはコミュニティにとって非常に役立ちます。ドキュメンテーションに関しては、Hugging Faceチームに問い合わせることをためらわないでください。
次に、`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`に追加されたドキュメンテーション文字列が正しいこと、およびすべての必要な入力および出力を含んでいることを確認してください。
ドキュメンテーションの書き方とドキュメンテーション文字列のフォーマットについて詳細なガイドが[こちら](writing-documentation)にあります。
ドキュメンテーションは通常、コミュニティとモデルの最初の接触点であるため、コードと同じくらい注意深く扱うべきであることを常に念頭に置いてください。
**コードのリファクタリング**
素晴らしい、これで*brand_new_bert*に必要なすべてのコードが追加されました。
この時点で、次のようなポテンシャルなコードスタイルの誤りを訂正するために以下を実行する必要があります:
```bash
make style
```
あなたのコーディングスタイルが品質チェックをパスすることを確認してください:
```bash
make quality
```
🤗 Transformersの非常に厳格なデザインテストには、まだ合格していない可能性があるいくつかの他のテストが存在するかもしれません。
これは、ドキュメント文字列に情報が不足しているか、名前が間違っていることが原因であることが多いです。Hugging Faceチームは、ここで詰まっている場合には必ず助けてくれるでしょう。
最後に、コードが正しく機能することを確認した後、コードをリファクタリングするのは常に良いアイデアです。
すべてのテストがパスした今、追加したコードを再度確認してリファクタリングを行うのは良いタイミングです。
これでコーディングの部分は完了しました、おめでとうございます! 🎉 あなたは素晴らしいです! 😎
**12. モデルをモデルハブにアップロード**
最後のパートでは、すべてのチェックポイントをモデルハブに変換してアップロードし、各アップロードしたモデルチェックポイントにモデルカードを追加する必要があります。
モデルハブの機能について詳しくは、[Model sharing and uploading Page](model_sharing)を読んで理解できます。
ここでは、*brand_new_bert*の著者組織の下にモデルをアップロードできるように必要なアクセス権を取得するために、Hugging Faceチームと協力する必要があります。
`transformers`のすべてのモデルに存在する`push_to_hub`メソッドは、チェックポイントをハブにプッシュする迅速かつ効率的な方法です。
以下に、少しのコードスニペットを示します:
```python
brand_new_bert.push_to_hub("brand_new_bert")
# Uncomment the following line to push to an organization.
# brand_new_bert.push_to_hub("/brand_new_bert")
```
各チェックポイントに適切なモデルカードを作成する価値があります。モデルカードは、この特定のチェックポイントの特性をハイライトするべきです。例えば、このチェックポイントはどのデータセットで事前学習/ファインチューニングされたか、どのような下流タスクでモデルを使用すべきかを示すべきです。また、モデルの正しい使用方法に関するコードも含めるべきです。
**13.(オプション)ノートブックの追加**
*brand_new_bert*を推論または下流タスクのファインチューニングにどのように詳細に使用できるかを示すノートブックを追加することは非常に役立ちます。これはあなたのPRをマージするために必須ではありませんが、コミュニティにとって非常に有用です。
**14. 完成したPRの提出**
プログラミングが完了したら、最後のステップに移動し、PRをメインブランチにマージしましょう。通常、Hugging Faceチームはこの時点で既にあなたをサポートしているはずですが、PRに良い説明を追加し、コードにコメントを追加して、レビュアーに特定の設計の選択肢を指摘したい場合はコメントを追加することも価値があります。
### Share your work!!
さあ、コミュニティからあなたの作業に対する評価を得る時が来ました!モデルの追加を完了することは、TransformersおよびNLPコミュニティにとって重要な貢献です。あなたのコードとポートされた事前学習済みモデルは、何百人、何千人という開発者や研究者によって確実に使用されるでしょう。あなたの仕事に誇りを持ち、コミュニティとあなたの成果を共有しましょう。
**あなたはコミュニティの誰でも簡単にアクセスできる別のモデルを作成しました! 🤯**