# Perceiver
## Overview
The Perceiver IO model was proposed in [Perceiver IO: A General Architecture for Structured Inputs &
Outputs](https://huggingface.co/papers/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch,
Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M.
Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
Perceiver IO is a generalization of [Perceiver](https://huggingface.co/papers/2103.03206) to handle arbitrary outputs in
addition to arbitrary inputs. The original Perceiver only produced a single classification label. In addition to
classification labels, Perceiver IO can produce (for example) language, optical flow, and multimodal videos with audio.
This is done using the same building blocks as the original Perceiver. The computational complexity of Perceiver IO is
linear in the input and output size and the bulk of the processing occurs in the latent space, allowing us to process
inputs and outputs that are much larger than can be handled by standard Transformers. This means, for example,
Perceiver IO can do BERT-style masked language modeling directly using bytes instead of tokenized inputs.
The abstract from the paper is the following:
*The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point
clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of
inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without
sacrificing the original's appealing properties by learning to flexibly query the model's latent space to produce
outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales
linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves
strong results on tasks with highly structured output spaces, such as natural language and visual understanding,
StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT
baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art
performance on Sintel optical flow estimation.*
Here's a TLDR explaining how Perceiver works:
The main problem with the self-attention mechanism of the Transformer is that the time and memory requirements scale
quadratically with the sequence length. Hence, models like BERT and RoBERTa are limited to a max sequence length of 512
tokens. Perceiver aims to solve this issue by, instead of performing self-attention on the inputs, perform it on a set
of latent variables, and only use the inputs for cross-attention. In this way, the time and memory requirements don't
depend on the length of the inputs anymore, as one uses a fixed amount of latent variables, like 256 or 512. These are
randomly initialized, after which they are trained end-to-end using backpropagation.
Internally, [`PerceiverModel`] will create the latents, which is a tensor of shape `(batch_size, num_latents,
d_latents)`. One must provide `inputs` (which could be text, images, audio, you name it!) to the model, which it will
use to perform cross-attention with the latents. The output of the Perceiver encoder is a tensor of the same shape. One
can then, similar to BERT, convert the last hidden states of the latents to classification logits by averaging along
the sequence dimension, and placing a linear layer on top of that to project the `d_latents` to `num_labels`.
This was the idea of the original Perceiver paper. However, it could only output classification logits. In a follow-up
work, PerceiverIO, they generalized it to let the model also produce outputs of arbitrary size. How, you might ask? The
idea is actually relatively simple: one defines outputs of an arbitrary size, and then applies cross-attention with the
last hidden states of the latents, using the outputs as queries, and the latents as keys and values.
So let's say one wants to perform masked language modeling (BERT-style) with the Perceiver. As the Perceiver's input
length will not have an impact on the computation time of the self-attention layers, one can provide raw bytes,
providing `inputs` of length 2048 to the model. If one now masks out certain of these 2048 tokens, one can define the
`outputs` as being of shape: `(batch_size, 2048, 768)`. Next, one performs cross-attention with the final hidden states
of the latents to update the `outputs` tensor. After cross-attention, one still has a tensor of shape `(batch_size,
2048, 768)`. One can then place a regular language modeling head on top, to project the last dimension to the
vocabulary size of the model, i.e. creating logits of shape `(batch_size, 2048, 262)` (as Perceiver uses a vocabulary
size of 262 byte IDs).
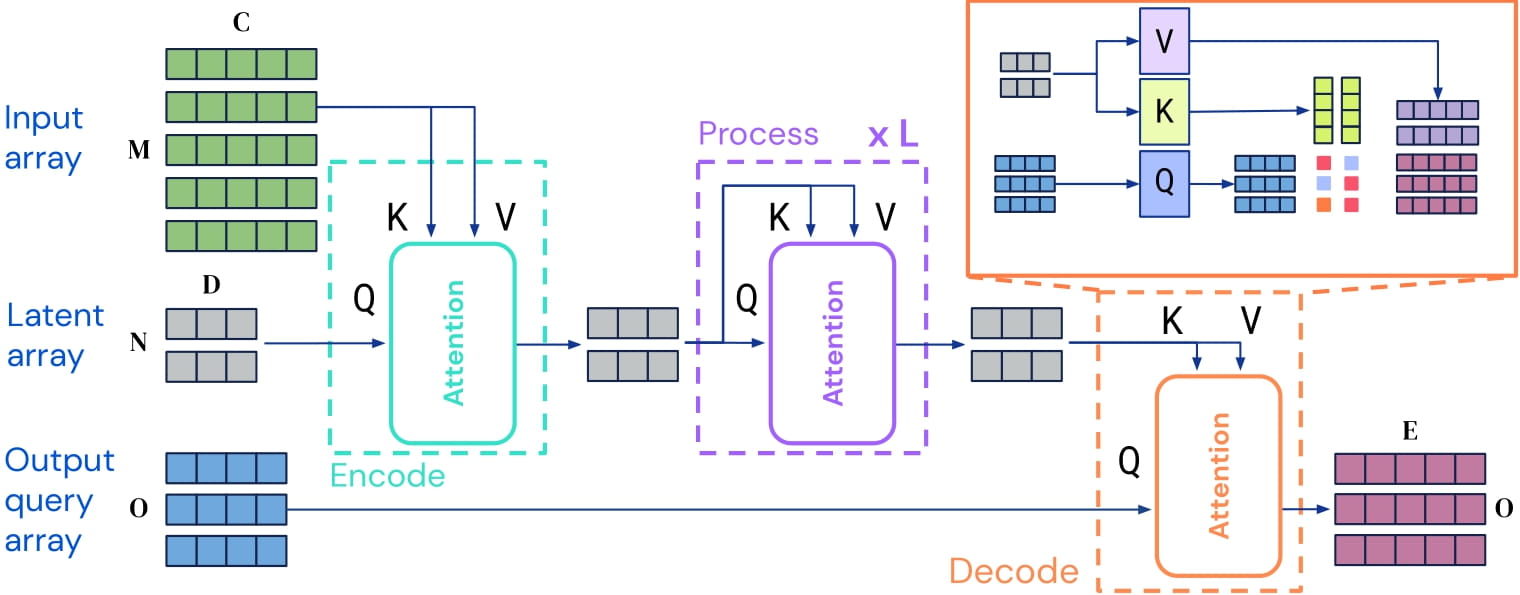 Perceiver IO architecture. Taken from the original paper
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
Perceiver does **not** work with `torch.nn.DataParallel` due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
## Resources
- The quickest way to get started with the Perceiver is by checking the [tutorial
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Perceiver).
- Refer to the [blog post](https://huggingface.co/blog/perceiver) if you want to fully understand how the model works and
is implemented in the library. Note that the models available in the library only showcase some examples of what you can do
with the Perceiver. There are many more use cases, including question answering, named-entity recognition, object detection,
audio classification, video classification, etc.
- [Text classification task guide](../tasks/sequence_classification)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Image classification task guide](../tasks/image_classification)
## Perceiver specific outputs
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverModelOutput
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverDecoderOutput
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassifierOutput
## PerceiverConfig
[[autodoc]] PerceiverConfig
## PerceiverTokenizer
[[autodoc]] PerceiverTokenizer
- __call__
## PerceiverFeatureExtractor
[[autodoc]] PerceiverFeatureExtractor
- __call__
## PerceiverImageProcessor
[[autodoc]] PerceiverImageProcessor
- preprocess
## PerceiverImageProcessorFast
[[autodoc]] PerceiverImageProcessorFast
- preprocess
## PerceiverTextPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverTextPreprocessor
## PerceiverImagePreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverImagePreprocessor
## PerceiverOneHotPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverOneHotPreprocessor
## PerceiverAudioPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverAudioPreprocessor
## PerceiverMultimodalPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalPreprocessor
## PerceiverProjectionDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverProjectionDecoder
## PerceiverBasicDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverBasicDecoder
## PerceiverClassificationDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassificationDecoder
## PerceiverOpticalFlowDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverOpticalFlowDecoder
## PerceiverBasicVideoAutoencodingDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverBasicVideoAutoencodingDecoder
## PerceiverMultimodalDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalDecoder
## PerceiverProjectionPostprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverProjectionPostprocessor
## PerceiverAudioPostprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverAudioPostprocessor
## PerceiverClassificationPostprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassificationPostprocessor
## PerceiverMultimodalPostprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalPostprocessor
## PerceiverModel
[[autodoc]] PerceiverModel
- forward
## PerceiverForMaskedLM
[[autodoc]] PerceiverForMaskedLM
- forward
## PerceiverForSequenceClassification
[[autodoc]] PerceiverForSequenceClassification
- forward
## PerceiverForImageClassificationLearned
[[autodoc]] PerceiverForImageClassificationLearned
- forward
## PerceiverForImageClassificationFourier
[[autodoc]] PerceiverForImageClassificationFourier
- forward
## PerceiverForImageClassificationConvProcessing
[[autodoc]] PerceiverForImageClassificationConvProcessing
- forward
## PerceiverForOpticalFlow
[[autodoc]] PerceiverForOpticalFlow
- forward
## PerceiverForMultimodalAutoencoding
[[autodoc]] PerceiverForMultimodalAutoencoding
- forward
Perceiver IO architecture. Taken from the original paper
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
Perceiver does **not** work with `torch.nn.DataParallel` due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
## Resources
- The quickest way to get started with the Perceiver is by checking the [tutorial
notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Perceiver).
- Refer to the [blog post](https://huggingface.co/blog/perceiver) if you want to fully understand how the model works and
is implemented in the library. Note that the models available in the library only showcase some examples of what you can do
with the Perceiver. There are many more use cases, including question answering, named-entity recognition, object detection,
audio classification, video classification, etc.
- [Text classification task guide](../tasks/sequence_classification)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Image classification task guide](../tasks/image_classification)
## Perceiver specific outputs
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverModelOutput
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverDecoderOutput
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassifierOutput
## PerceiverConfig
[[autodoc]] PerceiverConfig
## PerceiverTokenizer
[[autodoc]] PerceiverTokenizer
- __call__
## PerceiverFeatureExtractor
[[autodoc]] PerceiverFeatureExtractor
- __call__
## PerceiverImageProcessor
[[autodoc]] PerceiverImageProcessor
- preprocess
## PerceiverImageProcessorFast
[[autodoc]] PerceiverImageProcessorFast
- preprocess
## PerceiverTextPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverTextPreprocessor
## PerceiverImagePreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverImagePreprocessor
## PerceiverOneHotPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverOneHotPreprocessor
## PerceiverAudioPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverAudioPreprocessor
## PerceiverMultimodalPreprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalPreprocessor
## PerceiverProjectionDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverProjectionDecoder
## PerceiverBasicDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverBasicDecoder
## PerceiverClassificationDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassificationDecoder
## PerceiverOpticalFlowDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverOpticalFlowDecoder
## PerceiverBasicVideoAutoencodingDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverBasicVideoAutoencodingDecoder
## PerceiverMultimodalDecoder
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalDecoder
## PerceiverProjectionPostprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverProjectionPostprocessor
## PerceiverAudioPostprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverAudioPostprocessor
## PerceiverClassificationPostprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassificationPostprocessor
## PerceiverMultimodalPostprocessor
[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalPostprocessor
## PerceiverModel
[[autodoc]] PerceiverModel
- forward
## PerceiverForMaskedLM
[[autodoc]] PerceiverForMaskedLM
- forward
## PerceiverForSequenceClassification
[[autodoc]] PerceiverForSequenceClassification
- forward
## PerceiverForImageClassificationLearned
[[autodoc]] PerceiverForImageClassificationLearned
- forward
## PerceiverForImageClassificationFourier
[[autodoc]] PerceiverForImageClassificationFourier
- forward
## PerceiverForImageClassificationConvProcessing
[[autodoc]] PerceiverForImageClassificationConvProcessing
- forward
## PerceiverForOpticalFlow
[[autodoc]] PerceiverForOpticalFlow
- forward
## PerceiverForMultimodalAutoencoding
[[autodoc]] PerceiverForMultimodalAutoencoding
- forward