# BridgeTower
## Overview
BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) で提案されました。ドゥアン。このモデルの目標は、
各ユニモーダル エンコーダとクロスモーダル エンコーダの間のブリッジにより、クロスモーダル エンコーダの各層での包括的かつ詳細な対話が可能になり、追加のパフォーマンスと計算コストがほとんど無視できる程度で、さまざまな下流タスクで優れたパフォーマンスを実現します。
この論文は [AAAI'23](https://aaai.org/Conferences/AAAI-23/) 会議に採択されました。
論文の要約は次のとおりです。
*TWO-TOWER アーキテクチャを備えたビジョン言語 (VL) モデルは、近年の視覚言語表現学習の主流となっています。
現在の VL モデルは、軽量のユニモーダル エンコーダーを使用して、ディープ クロスモーダル エンコーダーで両方のモダリティを同時に抽出、位置合わせ、融合することを学習するか、事前にトレーニングされたディープ ユニモーダル エンコーダーから最終層のユニモーダル表現を上部のクロスモーダルエンコーダー。
どちらのアプローチも、視覚言語表現の学習を制限し、モデルのパフォーマンスを制限する可能性があります。この論文では、ユニモーダル エンコーダの最上位層とクロスモーダル エンコーダの各層の間の接続を構築する複数のブリッジ層を導入する BRIDGETOWER を提案します。
これにより、効果的なボトムアップのクロスモーダル調整と、クロスモーダル エンコーダー内の事前トレーニング済みユニモーダル エンコーダーのさまざまなセマンティック レベルの視覚表現とテキスト表現の間の融合が可能になります。 BRIDGETOWER は 4M 画像のみで事前トレーニングされており、さまざまな下流の視覚言語タスクで最先端のパフォーマンスを実現します。
特に、VQAv2 テスト標準セットでは、BRIDGETOWER は 78.73% の精度を達成し、同じ事前トレーニング データとほぼ無視できる追加パラメータと計算コストで以前の最先端モデル METER を 1.09% 上回りました。
特に、モデルをさらにスケーリングすると、BRIDGETOWER は 81.15% の精度を達成し、桁違いに大きなデータセットで事前トレーニングされたモデルを上回りました。*
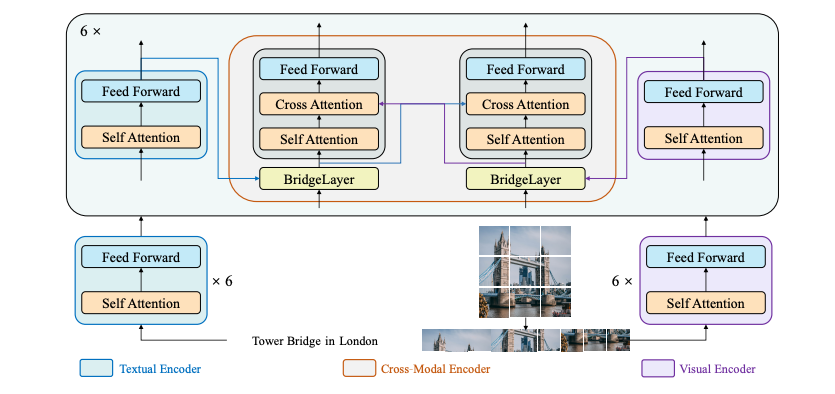 ブリッジタワー アーキテクチャ。 元の論文から抜粋。
このモデルは、[Anahita Bhiwandiwalla](https://huggingface.co/anahita-b)、[Tiep Le](https://huggingface.co/Tile)、[Shaoyen Tseng](https://huggingface.co/shaoyent)。元のコードは [ここ](https://github.com/microsoft/BridgeTower) にあります。
## Usage tips and examples
BridgeTower は、ビジュアル エンコーダー、テキスト エンコーダー、および複数の軽量ブリッジ レイヤーを備えたクロスモーダル エンコーダーで構成されます。
このアプローチの目標は、各ユニモーダル エンコーダーとクロスモーダル エンコーダーの間にブリッジを構築し、クロスモーダル エンコーダーの各層で包括的かつ詳細な対話を可能にすることでした。
原則として、提案されたアーキテクチャでは、任意のビジュアル、テキスト、またはクロスモーダル エンコーダを適用できます。
[`BridgeTowerProcessor`] は、[`RobertaTokenizer`] と [`BridgeTowerImageProcessor`] を単一のインスタンスにラップし、両方の機能を実現します。
テキストをエンコードし、画像をそれぞれ用意します。
次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForContrastiveLearning`] を使用して対照学習を実行する方法を示しています。
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs
```
次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForImageAndTextRetrieval`] を使用して画像テキストの取得を実行する方法を示しています。
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()
```
次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForMaskedLM`] を使用してマスクされた言語モデリングを実行する方法を示しています。
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.
```
チップ:
- BridgeTower のこの実装では、[`RobertaTokenizer`] を使用してテキスト埋め込みを生成し、OpenAI の CLIP/ViT モデルを使用して視覚的埋め込みを計算します。
- 事前トレーニングされた [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) および [bridgetower マスクされた言語モデリングと画像テキスト マッチング](https://huggingface.co/BridgeTower/bridgetower--base-itm-mlm) のチェックポイント がリリースされました。
- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://arxiv.org/pdf/2206.08657.pdf) を参照してください。
- このモデルの PyTorch バージョンは、torch 1.10 以降でのみ使用できます。
## BridgeTowerConfig
[[autodoc]] BridgeTowerConfig
## BridgeTowerTextConfig
[[autodoc]] BridgeTowerTextConfig
## BridgeTowerVisionConfig
[[autodoc]] BridgeTowerVisionConfig
## BridgeTowerImageProcessor
[[autodoc]] BridgeTowerImageProcessor
- preprocess
## BridgeTowerProcessor
[[autodoc]] BridgeTowerProcessor
- __call__
## BridgeTowerModel
[[autodoc]] BridgeTowerModel
- forward
## BridgeTowerForContrastiveLearning
[[autodoc]] BridgeTowerForContrastiveLearning
- forward
## BridgeTowerForMaskedLM
[[autodoc]] BridgeTowerForMaskedLM
- forward
## BridgeTowerForImageAndTextRetrieval
[[autodoc]] BridgeTowerForImageAndTextRetrieval
- forward
ブリッジタワー アーキテクチャ。 元の論文から抜粋。
このモデルは、[Anahita Bhiwandiwalla](https://huggingface.co/anahita-b)、[Tiep Le](https://huggingface.co/Tile)、[Shaoyen Tseng](https://huggingface.co/shaoyent)。元のコードは [ここ](https://github.com/microsoft/BridgeTower) にあります。
## Usage tips and examples
BridgeTower は、ビジュアル エンコーダー、テキスト エンコーダー、および複数の軽量ブリッジ レイヤーを備えたクロスモーダル エンコーダーで構成されます。
このアプローチの目標は、各ユニモーダル エンコーダーとクロスモーダル エンコーダーの間にブリッジを構築し、クロスモーダル エンコーダーの各層で包括的かつ詳細な対話を可能にすることでした。
原則として、提案されたアーキテクチャでは、任意のビジュアル、テキスト、またはクロスモーダル エンコーダを適用できます。
[`BridgeTowerProcessor`] は、[`RobertaTokenizer`] と [`BridgeTowerImageProcessor`] を単一のインスタンスにラップし、両方の機能を実現します。
テキストをエンコードし、画像をそれぞれ用意します。
次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForContrastiveLearning`] を使用して対照学習を実行する方法を示しています。
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs
```
次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForImageAndTextRetrieval`] を使用して画像テキストの取得を実行する方法を示しています。
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()
```
次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForMaskedLM`] を使用してマスクされた言語モデリングを実行する方法を示しています。
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.
```
チップ:
- BridgeTower のこの実装では、[`RobertaTokenizer`] を使用してテキスト埋め込みを生成し、OpenAI の CLIP/ViT モデルを使用して視覚的埋め込みを計算します。
- 事前トレーニングされた [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) および [bridgetower マスクされた言語モデリングと画像テキスト マッチング](https://huggingface.co/BridgeTower/bridgetower--base-itm-mlm) のチェックポイント がリリースされました。
- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://arxiv.org/pdf/2206.08657.pdf) を参照してください。
- このモデルの PyTorch バージョンは、torch 1.10 以降でのみ使用できます。
## BridgeTowerConfig
[[autodoc]] BridgeTowerConfig
## BridgeTowerTextConfig
[[autodoc]] BridgeTowerTextConfig
## BridgeTowerVisionConfig
[[autodoc]] BridgeTowerVisionConfig
## BridgeTowerImageProcessor
[[autodoc]] BridgeTowerImageProcessor
- preprocess
## BridgeTowerProcessor
[[autodoc]] BridgeTowerProcessor
- __call__
## BridgeTowerModel
[[autodoc]] BridgeTowerModel
- forward
## BridgeTowerForContrastiveLearning
[[autodoc]] BridgeTowerForContrastiveLearning
- forward
## BridgeTowerForMaskedLM
[[autodoc]] BridgeTowerForMaskedLM
- forward
## BridgeTowerForImageAndTextRetrieval
[[autodoc]] BridgeTowerForImageAndTextRetrieval
- forward