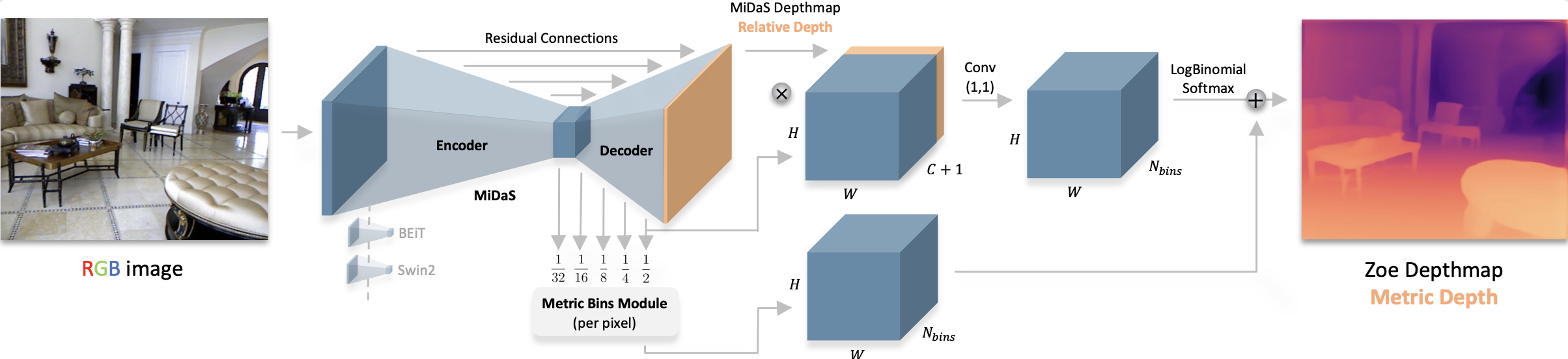
 ZoeDepth architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/isl-org/ZoeDepth).
## Usage tips
- ZoeDepth is an absolute (also called metric) depth estimation model, unlike DPT which is a relative depth estimation model. This means that ZoeDepth is able to estimate depth in metric units like meters.
The easiest to perform inference with ZoeDepth is by leveraging the [pipeline API](../main_classes/pipelines.md):
```python
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> pipe = pipeline(task="depth-estimation", model="Intel/zoedepth-nyu-kitti")
>>> result = pipe(image)
>>> depth = result["depth"]
```
Alternatively, one can also perform inference using the classes:
```python
>>> from transformers import AutoImageProcessor, ZoeDepthForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("Intel/zoedepth-nyu-kitti")
>>> model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu-kitti")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(inputs)
>>> # interpolate to original size and visualize the prediction
>>> ## ZoeDepth dynamically pads the input image. Thus we pass the original image size as argument
>>> ## to `post_process_depth_estimation` to remove the padding and resize to original dimensions.
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... source_sizes=[(image.height, image.width)],
... )
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
>>> depth = depth.detach().cpu().numpy() * 255
>>> depth = Image.fromarray(depth.astype("uint8"))
```
ZoeDepth architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/isl-org/ZoeDepth).
## Usage tips
- ZoeDepth is an absolute (also called metric) depth estimation model, unlike DPT which is a relative depth estimation model. This means that ZoeDepth is able to estimate depth in metric units like meters.
The easiest to perform inference with ZoeDepth is by leveraging the [pipeline API](../main_classes/pipelines.md):
```python
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> pipe = pipeline(task="depth-estimation", model="Intel/zoedepth-nyu-kitti")
>>> result = pipe(image)
>>> depth = result["depth"]
```
Alternatively, one can also perform inference using the classes:
```python
>>> from transformers import AutoImageProcessor, ZoeDepthForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("Intel/zoedepth-nyu-kitti")
>>> model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu-kitti")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(inputs)
>>> # interpolate to original size and visualize the prediction
>>> ## ZoeDepth dynamically pads the input image. Thus we pass the original image size as argument
>>> ## to `post_process_depth_estimation` to remove the padding and resize to original dimensions.
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... source_sizes=[(image.height, image.width)],
... )
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
>>> depth = depth.detach().cpu().numpy() * 255
>>> depth = Image.fromarray(depth.astype("uint8"))
```
In the original implementation ZoeDepth model performs inference on both the original and flipped images and averages out the results. The post_process_depth_estimation function can handle this for us by passing the flipped outputs to the optional outputs_flipped argument:
>>> with torch.no_grad():
... outputs = model(pixel_values)
... outputs_flipped = model(pixel_values=torch.flip(inputs.pixel_values, dims=[3]))
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... source_sizes=[(image.height, image.width)],
... outputs_flipped=outputs_flipped,
... )