# SegFormer
## Overview
The SegFormer model was proposed in [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping
Luo. The model consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great
results on image segmentation benchmarks such as ADE20K and Cityscapes.
The abstract from the paper is the following:
*We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with
lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel
hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding,
thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution
differs from training. 2) SegFormer avoids complex decoders. The proposed MLP decoder aggregates information from
different layers, and thus combining both local attention and global attention to render powerful representations. We
show that this simple and lightweight design is the key to efficient segmentation on Transformers. We scale our
approach up to obtain a series of models from SegFormer-B0 to SegFormer-B5, reaching significantly better performance
and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50.3% mIoU on ADE20K with 64M parameters,
being 5x smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on
Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C.*
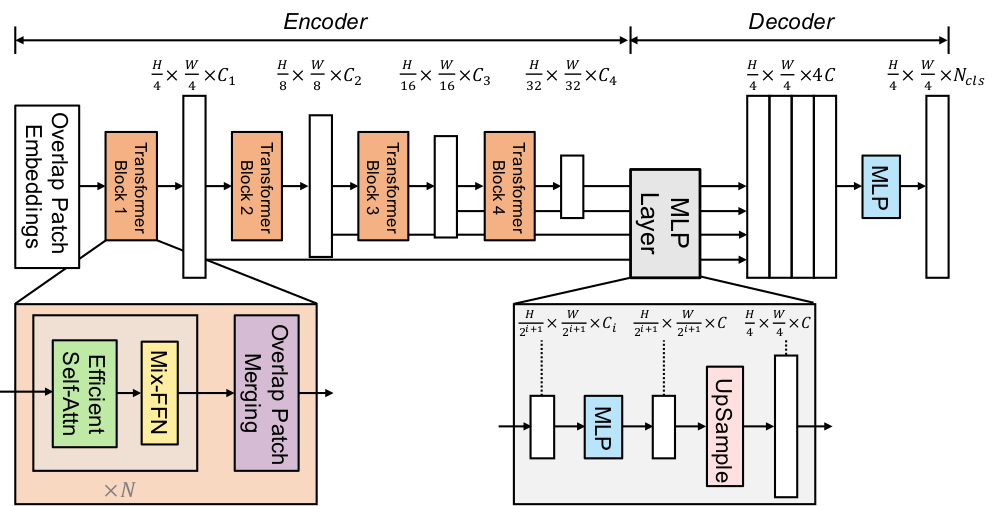
The figure below illustrates the architecture of SegFormer. Taken from the [original paper](https://arxiv.org/abs/2105.15203).
 This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version
of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/NVlabs/SegFormer).
## Usage tips
- SegFormer consists of a hierarchical Transformer encoder, and a lightweight all-MLP decoder head.
[`SegformerModel`] is the hierarchical Transformer encoder (which in the paper is also referred to
as Mix Transformer or MiT). [`SegformerForSemanticSegmentation`] adds the all-MLP decoder head on
top to perform semantic segmentation of images. In addition, there's
[`SegformerForImageClassification`] which can be used to - you guessed it - classify images. The
authors of SegFormer first pre-trained the Transformer encoder on ImageNet-1k to classify images. Next, they throw
away the classification head, and replace it by the all-MLP decode head. Next, they fine-tune the model altogether on
ADE20K, Cityscapes and COCO-stuff, which are important benchmarks for semantic segmentation. All checkpoints can be
found on the [hub](https://huggingface.co/models?other=segformer).
- The quickest way to get started with SegFormer is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer) (which showcase both inference and
fine-tuning on custom data). One can also check out the [blog post](https://huggingface.co/blog/fine-tune-segformer) introducing SegFormer and illustrating how it can be fine-tuned on custom data.
- TensorFlow users should refer to [this repository](https://github.com/deep-diver/segformer-tf-transformers) that shows off-the-shelf inference and fine-tuning.
- One can also check out [this interactive demo on Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers)
to try out a SegFormer model on custom images.
- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
- One can use [`SegformerImageProcessor`] to prepare images and corresponding segmentation maps
for the model. Note that this image processor is fairly basic and does not include all data augmentations used in
the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
important preprocessing step is that images and segmentation maps are randomly cropped and padded to the same size,
such as 512x512 or 640x640, after which they are normalized.
- One additional thing to keep in mind is that one can initialize [`SegformerImageProcessor`] with
`do_reduce_labels` set to `True` or `False`. In some datasets (like ADE20k), the 0 index is used in the annotated
segmentation maps for background. However, ADE20k doesn't include the "background" class in its 150 labels.
Therefore, `do_reduce_labels` is used to reduce all labels by 1, and to make sure no loss is computed for the
background class (i.e. it replaces 0 in the annotated maps by 255, which is the *ignore_index* of the loss function
used by [`SegformerForSemanticSegmentation`]). However, other datasets use the 0 index as
background class and include this class as part of all labels. In that case, `do_reduce_labels` should be set to
`False`, as loss should also be computed for the background class.
- As most models, SegFormer comes in different sizes, the details of which can be found in the table below
(taken from Table 7 of the [original paper](https://arxiv.org/abs/2105.15203)).
| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For
SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://arxiv.org/abs/2105.15203).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SegFormer.
- [`SegformerForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- [Image classification task guide](../tasks/image_classification)
Semantic segmentation:
- [`SegformerForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation).
- A blog on fine-tuning SegFormer on a custom dataset can be found [here](https://huggingface.co/blog/fine-tune-segformer).
- More demo notebooks on SegFormer (both inference + fine-tuning on a custom dataset) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer).
- [`TFSegformerForSemanticSegmentation`] is supported by this [example notebook](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb).
- [Semantic segmentation task guide](../tasks/semantic_segmentation)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## SegformerConfig
[[autodoc]] SegformerConfig
## SegformerFeatureExtractor
[[autodoc]] SegformerFeatureExtractor
- __call__
- post_process_semantic_segmentation
## SegformerImageProcessor
[[autodoc]] SegformerImageProcessor
- preprocess
- post_process_semantic_segmentation
## SegformerModel
[[autodoc]] SegformerModel
- forward
## SegformerDecodeHead
[[autodoc]] SegformerDecodeHead
- forward
## SegformerForImageClassification
[[autodoc]] SegformerForImageClassification
- forward
## SegformerForSemanticSegmentation
[[autodoc]] SegformerForSemanticSegmentation
- forward
## TFSegformerDecodeHead
[[autodoc]] TFSegformerDecodeHead
- call
## TFSegformerModel
[[autodoc]] TFSegformerModel
- call
## TFSegformerForImageClassification
[[autodoc]] TFSegformerForImageClassification
- call
## TFSegformerForSemanticSegmentation
[[autodoc]] TFSegformerForSemanticSegmentation
- call
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version
of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/NVlabs/SegFormer).
## Usage tips
- SegFormer consists of a hierarchical Transformer encoder, and a lightweight all-MLP decoder head.
[`SegformerModel`] is the hierarchical Transformer encoder (which in the paper is also referred to
as Mix Transformer or MiT). [`SegformerForSemanticSegmentation`] adds the all-MLP decoder head on
top to perform semantic segmentation of images. In addition, there's
[`SegformerForImageClassification`] which can be used to - you guessed it - classify images. The
authors of SegFormer first pre-trained the Transformer encoder on ImageNet-1k to classify images. Next, they throw
away the classification head, and replace it by the all-MLP decode head. Next, they fine-tune the model altogether on
ADE20K, Cityscapes and COCO-stuff, which are important benchmarks for semantic segmentation. All checkpoints can be
found on the [hub](https://huggingface.co/models?other=segformer).
- The quickest way to get started with SegFormer is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer) (which showcase both inference and
fine-tuning on custom data). One can also check out the [blog post](https://huggingface.co/blog/fine-tune-segformer) introducing SegFormer and illustrating how it can be fine-tuned on custom data.
- TensorFlow users should refer to [this repository](https://github.com/deep-diver/segformer-tf-transformers) that shows off-the-shelf inference and fine-tuning.
- One can also check out [this interactive demo on Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers)
to try out a SegFormer model on custom images.
- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
- One can use [`SegformerImageProcessor`] to prepare images and corresponding segmentation maps
for the model. Note that this image processor is fairly basic and does not include all data augmentations used in
the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
important preprocessing step is that images and segmentation maps are randomly cropped and padded to the same size,
such as 512x512 or 640x640, after which they are normalized.
- One additional thing to keep in mind is that one can initialize [`SegformerImageProcessor`] with
`do_reduce_labels` set to `True` or `False`. In some datasets (like ADE20k), the 0 index is used in the annotated
segmentation maps for background. However, ADE20k doesn't include the "background" class in its 150 labels.
Therefore, `do_reduce_labels` is used to reduce all labels by 1, and to make sure no loss is computed for the
background class (i.e. it replaces 0 in the annotated maps by 255, which is the *ignore_index* of the loss function
used by [`SegformerForSemanticSegmentation`]). However, other datasets use the 0 index as
background class and include this class as part of all labels. In that case, `do_reduce_labels` should be set to
`False`, as loss should also be computed for the background class.
- As most models, SegFormer comes in different sizes, the details of which can be found in the table below
(taken from Table 7 of the [original paper](https://arxiv.org/abs/2105.15203)).
| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For
SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://arxiv.org/abs/2105.15203).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SegFormer.
- [`SegformerForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- [Image classification task guide](../tasks/image_classification)
Semantic segmentation:
- [`SegformerForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation).
- A blog on fine-tuning SegFormer on a custom dataset can be found [here](https://huggingface.co/blog/fine-tune-segformer).
- More demo notebooks on SegFormer (both inference + fine-tuning on a custom dataset) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer).
- [`TFSegformerForSemanticSegmentation`] is supported by this [example notebook](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb).
- [Semantic segmentation task guide](../tasks/semantic_segmentation)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## SegformerConfig
[[autodoc]] SegformerConfig
## SegformerFeatureExtractor
[[autodoc]] SegformerFeatureExtractor
- __call__
- post_process_semantic_segmentation
## SegformerImageProcessor
[[autodoc]] SegformerImageProcessor
- preprocess
- post_process_semantic_segmentation
## SegformerModel
[[autodoc]] SegformerModel
- forward
## SegformerDecodeHead
[[autodoc]] SegformerDecodeHead
- forward
## SegformerForImageClassification
[[autodoc]] SegformerForImageClassification
- forward
## SegformerForSemanticSegmentation
[[autodoc]] SegformerForSemanticSegmentation
- forward
## TFSegformerDecodeHead
[[autodoc]] TFSegformerDecodeHead
- call
## TFSegformerModel
[[autodoc]] TFSegformerModel
- call
## TFSegformerForImageClassification
[[autodoc]] TFSegformerForImageClassification
- call
## TFSegformerForSemanticSegmentation
[[autodoc]] TFSegformerForSemanticSegmentation
- call