# Mistral
## Overview
Mistral was introduced in the [this blogpost](https://mistral.ai/news/announcing-mistral-7b/) by Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
The introduction of the blog post says:
*Mistral AI team is proud to release Mistral 7B, the most powerful language model for its size to date.*
Mistral-7B is the first large language model (LLM) released by [mistral.ai](https://mistral.ai/).
### Architectural details
Mistral-7B is a decoder-only Transformer with the following architectural choices:
- Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
- GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
- Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
For more details refer to the [release blog post](https://mistral.ai/news/announcing-mistral-7b/).
### License
`Mistral-7B` is released under the Apache 2.0 license.
## Usage tips
The Mistral team has released 3 checkpoints:
- a base model, [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1), which has been pre-trained to predict the next token on internet-scale data.
- an instruction tuned model, [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1), which is the base model optimized for chat purposes using supervised fine-tuning (SFT) and direct preference optimization (DPO).
- an improved instruction tuned model, [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2), which improves upon v1.
The base model can be used as follows:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> prompt = "My favourite condiment is"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"My favourite condiment is to ..."
```
The instruction tuned model can be used as follows:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
>>> messages = [
... {"role": "user", "content": "What is your favourite condiment?"},
... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
... {"role": "user", "content": "Do you have mayonnaise recipes?"}
... ]
>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"Mayonnaise can be made as follows: (...)"
```
As can be seen, the instruction-tuned model requires a [chat template](../chat_templating) to be applied to make sure the inputs are prepared in the right format.
## Speeding up Mistral by using Flash Attention
The code snippets above showcase inference without any optimization tricks. However, one can drastically speed up the model by leveraging [Flash Attention](../perf_train_gpu_one.md#flash-attention-2), which is a faster implementation of the attention mechanism used inside the model.
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). Make also sure to load your model in half-precision (e.g. `torch.float16`)
To load and run a model using Flash Attention-2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2", device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> prompt = "My favourite condiment is"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"My favourite condiment is to (...)"
```
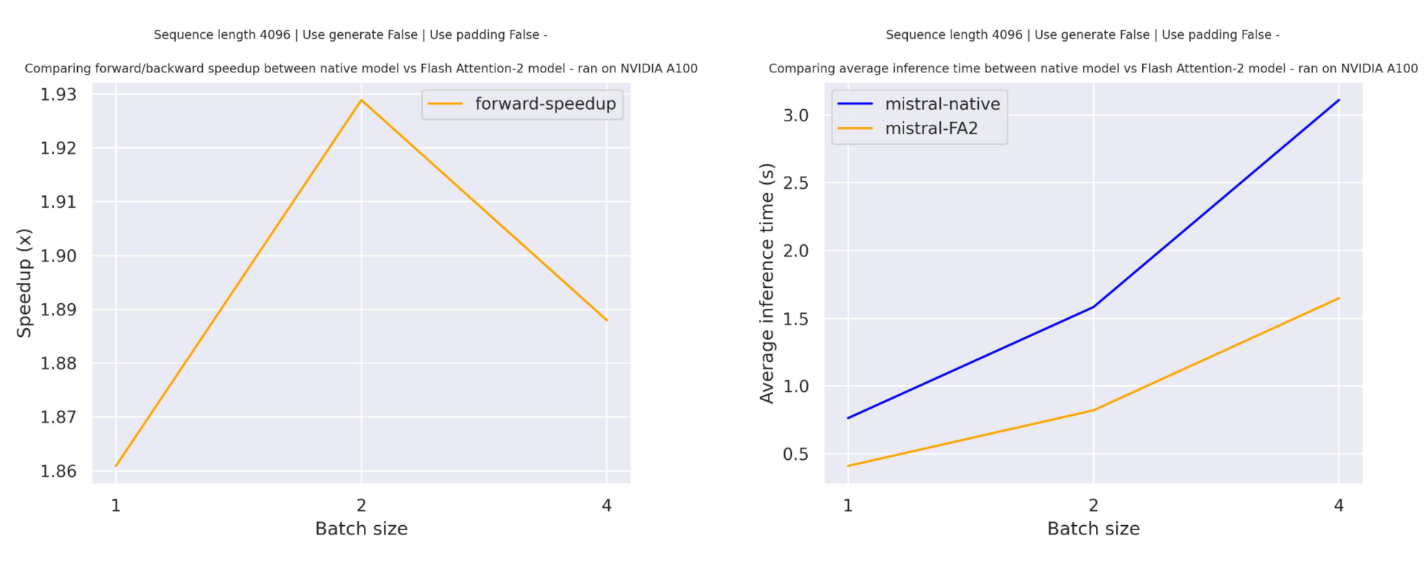
### Expected speedups
Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using `mistralai/Mistral-7B-v0.1` checkpoint and the Flash Attention 2 version of the model.
### Sliding window Attention
The current implementation supports the sliding window attention mechanism and memory efficient cache management.
To enable sliding window attention, just make sure to have a `flash-attn` version that is compatible with sliding window attention (`>=2.3.0`).
The Flash Attention-2 model uses also a more memory efficient cache slicing mechanism - as recommended per the official implementation of Mistral model that use rolling cache mechanism we keep the cache size fixed (`self.config.sliding_window`), support batched generation only for `padding_side="left"` and use the absolute position of the current token to compute the positional embedding.
## Shrinking down Mistral using quantization
As the Mistral model has 7 billion parameters, that would require about 14GB of GPU RAM in half precision (float16), since each parameter is stored in 2 bytes. However, one can shrink down the size of the model using [quantization](../quantization.md). If the model is quantized to 4 bits (or half a byte per parameter),that requires only about 3.5GB of RAM.
Quantizing a model is as simple as passing a `quantization_config` to the model. Below, we'll leverage the BitsAndyBytes quantization (but refer to [this page](../quantization.md) for other quantization methods):
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
>>> # specify how to quantize the model
>>> quantization_config = BitsAndBytesConfig(
... load_in_4bit=True,
... bnb_4bit_quant_type="nf4",
... bnb_4bit_compute_dtype="torch.float16",
... )
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", quantization_config=True, device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
>>> prompt = "My favourite condiment is"
>>> messages = [
... {"role": "user", "content": "What is your favourite condiment?"},
... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
... {"role": "user", "content": "Do you have mayonnaise recipes?"}
... ]
>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"The expected output"
```
This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ) .
The original code can be found [here](https://github.com/mistralai/mistral-src).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mistral. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- A demo notebook to perform supervised fine-tuning (SFT) of Mistral-7B can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Mistral/Supervised_fine_tuning_(SFT)_of_an_LLM_using_Hugging_Face_tooling.ipynb). 🌎
- A [blog post](https://www.philschmid.de/fine-tune-llms-in-2024-with-trl) on how to fine-tune LLMs in 2024 using Hugging Face tooling. 🌎
- The [Alignment Handbook](https://github.com/huggingface/alignment-handbook) by Hugging Face includes scripts and recipes to perform supervised fine-tuning (SFT) and direct preference optimization with Mistral-7B. This includes scripts for full fine-tuning, QLoRa on a single GPU as well as multi-GPU fine-tuning.
- [Causal language modeling task guide](../tasks/language_modeling)
## MistralConfig
[[autodoc]] MistralConfig
## MistralModel
[[autodoc]] MistralModel
- forward
## MistralForCausalLM
[[autodoc]] MistralForCausalLM
- forward
## MistralForSequenceClassification
[[autodoc]] MistralForSequenceClassification
- forward
## MistralForTokenClassification
[[autodoc]] MistralForTokenClassification
- forward
## FlaxMistralModel
[[autodoc]] FlaxMistralModel
- __call__
## FlaxMistralForCausalLM
[[autodoc]] FlaxMistralForCausalLM
- __call__
## TFMistralModel
[[autodoc]] TFMistralModel
- call
## TFMistralForCausalLM
[[autodoc]] TFMistralForCausalLM
- call
## TFMistralForSequenceClassification
[[autodoc]] TFMistralForSequenceClassification
- call