# AWQ [[awq]]
이 [노트북](https://colab.research.google.com/drive/1HzZH89yAXJaZgwJDhQj9LqSBux932BvY) 으로 AWQ 양자화를 실습해보세요 !
[Activation-aware Weight Quantization (AWQ)](https://hf.co/papers/2306.00978)은 모델의 모든 가중치를 양자화하지 않고, LLM 성능에 중요한 가중치를 유지합니다. 이로써 4비트 정밀도로 모델을 실행해도 성능 저하 없이 양자화 손실을 크게 줄일 수 있습니다.
AWQ 알고리즘을 사용하여 모델을 양자화할 수 있는 여러 라이브러리가 있습니다. 예를 들어 [llm-awq](https://github.com/mit-han-lab/llm-awq), [autoawq](https://github.com/casper-hansen/AutoAWQ) , [optimum-intel](https://huggingface.co/docs/optimum/main/en/intel/optimization_inc) 등이 있습니다. Transformers는 llm-awq, autoawq 라이브러리를 이용해 양자화된 모델을 가져올 수 있도록 지원합니다. 이 가이드에서는 autoawq로 양자화된 모델을 가져오는 방법을 보여드리나, llm-awq로 양자화된 모델의 경우도 유사한 절차를 따릅니다.
autoawq가 설치되어 있는지 확인하세요:
```bash
pip install autoawq
```
AWQ 양자화된 모델은 해당 모델의 [config.json](https://huggingface.co/TheBloke/zephyr-7B-alpha-AWQ/blob/main/config.json) 파일의 `quantization_config` 속성을 통해 식별할 수 있습니다.:
```json
{
"_name_or_path": "/workspace/process/huggingfaceh4_zephyr-7b-alpha/source",
"architectures": [
"MistralForCausalLM"
],
...
...
...
"quantization_config": {
"quant_method": "awq",
"zero_point": true,
"group_size": 128,
"bits": 4,
"version": "gemm"
}
}
```
양자화된 모델은 [`~PreTrainedModel.from_pretrained`] 메서드를 사용하여 가져옵니다. 모델을 CPU에 가져왔다면, 먼저 모델을 GPU 장치로 옮겨야 합니다. `device_map` 파라미터를 사용하여 모델을 배치할 위치를 지정하세요:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "TheBloke/zephyr-7B-alpha-AWQ"
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0")
```
AWQ 양자화 모델을 가져오면 자동으로 성능상의 이유로 인해 가중치들의 기본값이 fp16으로 설정됩니다. 가중치를 다른 형식으로 가져오려면, `torch_dtype` 파라미터를 사용하세요:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "TheBloke/zephyr-7B-alpha-AWQ"
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float32)
```
추론을 더욱 가속화하기 위해 AWQ 양자화와 [FlashAttention-2](../perf_infer_gpu_one#flashattention-2) 를 결합 할 수 있습니다:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", attn_implementation="flash_attention_2", device_map="cuda:0")
```
## 퓨즈된 모듈 [[fused-modules]]
퓨즈된 모듈은 정확도와 성능을 개선합니다. 퓨즈된 모듈은 [Llama](https://huggingface.co/meta-llama) 아키텍처와 [Mistral](https://huggingface.co/mistralai/Mistral-7B-v0.1) 아키텍처의 AWQ모듈에 기본적으로 지원됩니다. 그러나 지원되지 않는 아키텍처에 대해서도 AWQ 모듈을 퓨즈할 수 있습니다.
퓨즈된 모듈은 FlashAttention-2와 같은 다른 최적화 기술과 결합할 수 없습니다.
지원되는 아키텍처에서 퓨즈된 모듈을 활성화하려면, [`AwqConfig`] 를 생성하고 매개변수 `fuse_max_seq_len` 과 `do_fuse=True`를 설정해야 합니다. `fuse_max_seq_len` 매개변수는 전체 시퀀스 길이로, 컨텍스트 길이와 예상 생성 길이를 포함해야 합니다. 안전하게 사용하기 위해 더 큰 값으로 설정할 수 있습니다.
예를 들어, [TheBloke/Mistral-7B-OpenOrca-AWQ](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ) 모델의 AWQ 모듈을 퓨즈해보겠습니다.
```python
import torch
from transformers import AwqConfig, AutoModelForCausalLM
model_id = "TheBloke/Mistral-7B-OpenOrca-AWQ"
quantization_config = AwqConfig(
bits=4,
fuse_max_seq_len=512,
do_fuse=True,
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config).to(0)
```
[TheBloke/Mistral-7B-OpenOrca-AWQ](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ) 모델은 퓨즈된 모듈이 있는 경우와 없는 경우 모두 `batch_size=1` 로 성능 평가되었습니다.
퓨즈되지 않은 모듈
| 배치 크기 | 프리필 길이 | 디코드 길이 | 프리필 토큰/초 | 디코드 토큰/초 | 메모리 (VRAM) |
|-------------:|-----------------:|----------------:|-------------------:|------------------:|:----------------|
| 1 | 32 | 32 | 60.0984 | 38.4537 | 4.50 GB (5.68%) |
| 1 | 64 | 64 | 1333.67 | 31.6604 | 4.50 GB (5.68%) |
| 1 | 128 | 128 | 2434.06 | 31.6272 | 4.50 GB (5.68%) |
| 1 | 256 | 256 | 3072.26 | 38.1731 | 4.50 GB (5.68%) |
| 1 | 512 | 512 | 3184.74 | 31.6819 | 4.59 GB (5.80%) |
| 1 | 1024 | 1024 | 3148.18 | 36.8031 | 4.81 GB (6.07%) |
| 1 | 2048 | 2048 | 2927.33 | 35.2676 | 5.73 GB (7.23%) |
퓨즈된 모듈
| 배치 크기 | 프리필 길이 | 디코드 길이 | 프리필 토큰/초 | 디코드 토큰/초 | 메모리 (VRAM) |
|-------------:|-----------------:|----------------:|-------------------:|------------------:|:----------------|
| 1 | 32 | 32 | 81.4899 | 80.2569 | 4.00 GB (5.05%) |
| 1 | 64 | 64 | 1756.1 | 106.26 | 4.00 GB (5.05%) |
| 1 | 128 | 128 | 2479.32 | 105.631 | 4.00 GB (5.06%) |
| 1 | 256 | 256 | 1813.6 | 85.7485 | 4.01 GB (5.06%) |
| 1 | 512 | 512 | 2848.9 | 97.701 | 4.11 GB (5.19%) |
| 1 | 1024 | 1024 | 3044.35 | 87.7323 | 4.41 GB (5.57%) |
| 1 | 2048 | 2048 | 2715.11 | 89.4709 | 5.57 GB (7.04%) |
퓨즈된 모듈 및 퓨즈되지 않은 모듈의 속도와 처리량은 [optimum-benchmark](https://github.com/huggingface/optimum-benchmark)라이브러리를 사용하여 테스트 되었습니다.
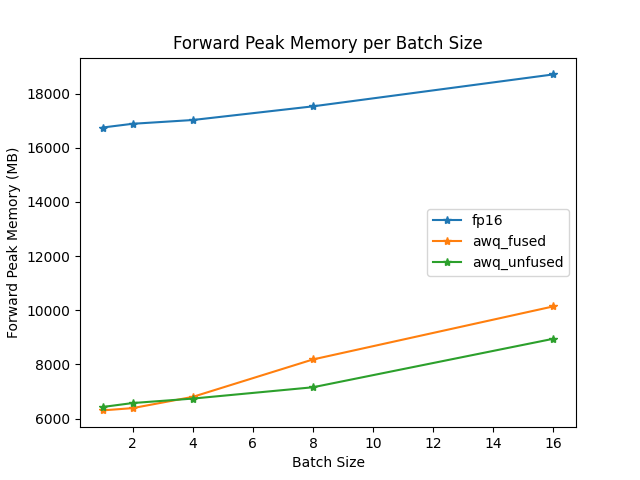 포워드 피크 메모리 (forward peak memory)/배치 크기
포워드 피크 메모리 (forward peak memory)/배치 크기
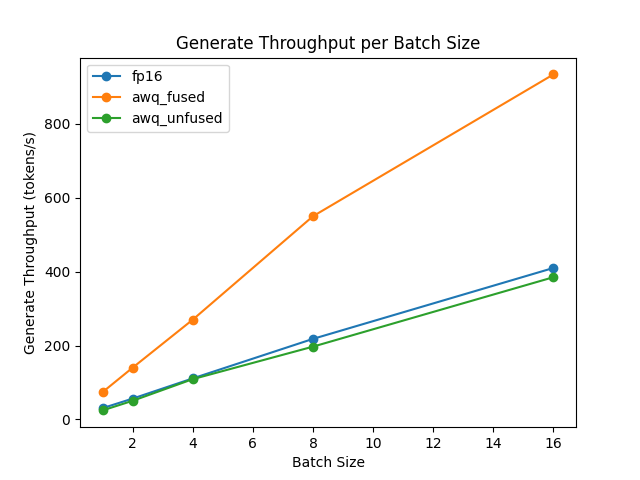 생성 처리량/배치크기
생성 처리량/배치크기
퓨즈된 모듈을 지원하지 않는 아키텍처의 경우, `modules_to_fuse` 매개변수를 사용해 직접 퓨즈 매핑을 만들어 어떤 모듈을 퓨즈할지 정의해야합니다. 예로, [TheBloke/Yi-34B-AWQ](https://huggingface.co/TheBloke/Yi-34B-AWQ) 모델의 AWQ 모듈을 퓨즈하는 방법입니다.
```python
import torch
from transformers import AwqConfig, AutoModelForCausalLM
model_id = "TheBloke/Yi-34B-AWQ"
quantization_config = AwqConfig(
bits=4,
fuse_max_seq_len=512,
modules_to_fuse={
"attention": ["q_proj", "k_proj", "v_proj", "o_proj"],
"layernorm": ["ln1", "ln2", "norm"],
"mlp": ["gate_proj", "up_proj", "down_proj"],
"use_alibi": False,
"num_attention_heads": 56,
"num_key_value_heads": 8,
"hidden_size": 7168
}
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config).to(0)
```
`modules_to_fuse` 매개변수는 다음을 포함해야 합니다:
- `"attention"`: 어텐션 레이어는 다음 순서로 퓨즈하세요 : 쿼리 (query), 키 (key), 값 (value) , 출력 프로젝션 계층 (output projection layer). 해당 레이어를 퓨즈하지 않으려면 빈 리스트를 전달하세요.
- `"layernorm"`: 사용자 정의 퓨즈 레이어 정규화로 교할 레이어 정규화 레이어명. 해당 레이어를 퓨즈하지 않으려면 빈 리스트를 전달하세요.
- `"mlp"`: 단일 MLP 레이어로 퓨즈할 MLP 레이어 순서 : (게이트 (gate) (덴스(dense), 레이어(layer), 포스트 어텐션(post-attention)) / 위 / 아래 레이어).
- `"use_alibi"`: 모델이 ALiBi positional embedding을 사용할 경우 설정합니다.
- `"num_attention_heads"`: 어텐션 헤드 (attention heads)의 수를 설정합니다.
- `"num_key_value_heads"`: 그룹화 쿼리 어텐션 (GQA)을 구현하는데 사용되는 키 값 헤드의 수를 설정합니다. `num_key_value_heads=num_attention_heads`로 설정할 경우, 모델은 다중 헤드 어텐션 (MHA)가 사용되며, `num_key_value_heads=1` 는 다중 쿼리 어텐션 (MQA)가, 나머지는 GQA가 사용됩니다.
- `"hidden_size"`: 숨겨진 표현(hidden representations)의 차원을 설정합니다.
## ExLlama-v2 서포트 [[exllama-v2-support]]
최신 버전 `autoawq`는 빠른 프리필과 디코딩을 위해 ExLlama-v2 커널을 지원합니다. 시작하기 위해 먼저 최신 버전 `autoawq` 를 설치하세요 :
```bash
pip install git+https://github.com/casper-hansen/AutoAWQ.git
```
매개변수를 `version="exllama"`로 설정해 `AwqConfig()`를 생성하고 모델에 넘겨주세요.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, AwqConfig
quantization_config = AwqConfig(version="exllama")
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/Mistral-7B-Instruct-v0.1-AWQ",
quantization_config=quantization_config,
device_map="auto",
)
input_ids = torch.randint(0, 100, (1, 128), dtype=torch.long, device="cuda")
output = model(input_ids)
print(output.logits)
tokenizer = AutoTokenizer.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-AWQ")
input_ids = tokenizer.encode("How to make a cake", return_tensors="pt").to(model.device)
output = model.generate(input_ids, do_sample=True, max_length=50, pad_token_id=50256)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
이 기능은 AMD GPUs에서 지원됩니다.