diff --git a/README.md b/README.md
index 5e17e33b204..ea026159803 100644
--- a/README.md
+++ b/README.md
@@ -328,6 +328,7 @@ Current number of checkpoints: ** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[MarkupLM](https://huggingface.co/docs/transformers/main/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
diff --git a/README_ko.md b/README_ko.md
index f53075ff5fe..e7a0d9d2960 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -278,6 +278,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[MarkupLM](https://huggingface.co/docs/transformers/main/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 2843a8eb29a..f3f1a5474c8 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -302,7 +302,8 @@ conda install -c huggingface transformers
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (来自 Facebook) 伴随论文 [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) 由 Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert 发布。
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (来自 Facebook) 伴随论文 [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) 由 Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin 发布。
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** 用 [OPUS](http://opus.nlpl.eu/) 数据训练的机器翻译模型由 Jörg Tiedemann 发布。[Marian Framework](https://marian-nmt.github.io/) 由微软翻译团队开发。
-1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov
+1. **[MarkupLM](https://huggingface.co/docs/transformers/main/model_doc/markuplm)** (来自 Microsoft Research Asia) 伴随论文 [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) 由 Junlong Li, Yiheng Xu, Lei Cui, Furu Wei 发布。
+1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov >>>>>>> Fix rebase
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (来自 Facebook) 伴随论文 [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) 由 Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer 发布。
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (来自 Facebook) 伴随论文 [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) 由 Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan 发布。
1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (来自 NVIDIA) 伴随论文 [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) 由 Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index 8f74b97e985..43e8a05372c 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -314,6 +314,7 @@ conda install -c huggingface transformers
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[MarkupLM](https://huggingface.co/docs/transformers/main/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 5e2d25ee3c4..644778e155c 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -279,6 +279,8 @@
title: M2M100
- local: model_doc/marian
title: MarianMT
+ - local: model_doc/markuplm
+ title: MarkupLM
- local: model_doc/mbart
title: MBart and MBart-50
- local: model_doc/megatron-bert
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
index 98a458e11ff..652c5bc77b8 100644
--- a/docs/source/en/index.mdx
+++ b/docs/source/en/index.mdx
@@ -118,6 +118,7 @@ The documentation is organized into five sections:
1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
@@ -264,6 +265,7 @@ Flax), PyTorch, and/or TensorFlow.
| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
+| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
diff --git a/docs/source/en/model_doc/markuplm.mdx b/docs/source/en/model_doc/markuplm.mdx
new file mode 100644
index 00000000000..66ba7a8180d
--- /dev/null
+++ b/docs/source/en/model_doc/markuplm.mdx
@@ -0,0 +1,246 @@
+
+
+# MarkupLM
+
+## Overview
+
+The MarkupLM model was proposed in [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document
+Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei. MarkupLM is BERT, but
+applied to HTML pages instead of raw text documents. The model incorporates additional embedding layers to improve
+performance, similar to [LayoutLM](layoutlm).
+
+The model can be used for tasks like question answering on web pages or information extraction from web pages. It obtains
+state-of-the-art results on 2 important benchmarks:
+- [WebSRC](https://x-lance.github.io/WebSRC/), a dataset for Web-Based Structual Reading Comprehension (a bit like SQuAD but for web pages)
+- [SWDE](https://www.researchgate.net/publication/221299838_From_one_tree_to_a_forest_a_unified_solution_for_structured_web_data_extraction), a dataset
+for information extraction from web pages (basically named-entity recogntion on web pages)
+
+The abstract from the paper is the following:
+
+*Multimodal pre-training with text, layout, and image has made significant progress for Visually-rich Document
+Understanding (VrDU), especially the fixed-layout documents such as scanned document images. While, there are still a
+large number of digital documents where the layout information is not fixed and needs to be interactively and
+dynamically rendered for visualization, making existing layout-based pre-training approaches not easy to apply. In this
+paper, we propose MarkupLM for document understanding tasks with markup languages as the backbone such as
+HTML/XML-based documents, where text and markup information is jointly pre-trained. Experiment results show that the
+pre-trained MarkupLM significantly outperforms the existing strong baseline models on several document understanding
+tasks. The pre-trained model and code will be publicly available.*
+
+Tips:
+- In addition to `input_ids`, [`~MarkupLMModel.forward`] expects 2 additional inputs, namely `xpath_tags_seq` and `xpath_subs_seq`.
+These are the XPATH tags and subscripts respectively for each token in the input sequence.
+- One can use [`MarkupLMProcessor`] to prepare all data for the model. Refer to the [usage guide](#usage-markuplmprocessor) for more info.
+- Demo notebooks can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MarkupLM).
+
+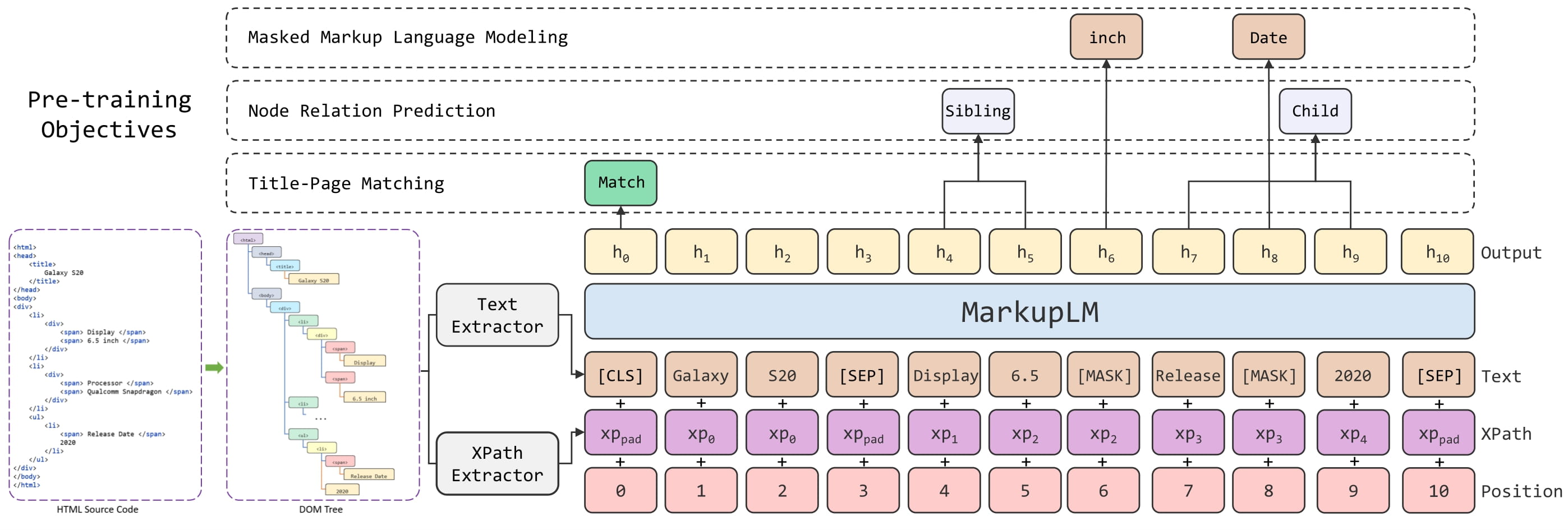 +
+ MarkupLM architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/markuplm).
+
+## Usage: MarkupLMProcessor
+
+The easiest way to prepare data for the model is to use [`MarkupLMProcessor`], which internally combines a feature extractor
+([`MarkupLMFeatureExtractor`]) and a tokenizer ([`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`]). The feature extractor is
+used to extract all nodes and xpaths from the HTML strings, which are then provided to the tokenizer, which turns them into the
+token-level inputs of the model (`input_ids` etc.). Note that you can still use the feature extractor and tokenizer separately,
+if you only want to handle one of the two tasks.
+
+```python
+from transformers import MarkupLMFeatureExtractor, MarkupLMTokenizerFast, MarkupLMProcessor
+
+feature_extractor = MarkupLMFeatureExtractor()
+tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
+processor = MarkupLMProcessor(feature_extractor, tokenizer)
+```
+
+In short, one can provide HTML strings (and possibly additional data) to [`MarkupLMProcessor`],
+and it will create the inputs expected by the model. Internally, the processor first uses
+[`MarkupLMFeatureExtractor`] to get a list of nodes and corresponding xpaths. The nodes and
+xpaths are then provided to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`], which converts them
+to token-level `input_ids`, `attention_mask`, `token_type_ids`, `xpath_subs_seq`, `xpath_tags_seq`.
+Optionally, one can provide node labels to the processor, which are turned into token-level `labels`.
+
+[`MarkupLMFeatureExtractor`] uses [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/), a Python library for
+pulling data out of HTML and XML files, under the hood. Note that you can still use your own parsing solution of
+choice, and provide the nodes and xpaths yourself to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`].
+
+In total, there are 5 use cases that are supported by the processor. Below, we list them all. Note that each of these
+use cases work for both batched and non-batched inputs (we illustrate them for non-batched inputs).
+
+**Use case 1: web page classification (training, inference) + token classification (inference), parse_html = True**
+
+This is the simplest case, in which the processor will use the feature extractor to get all nodes and xpaths from the HTML.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+
+>>> html_string = """
+...
+...
+...
+... Hello world
+...
+...
+
+...
+
+ MarkupLM architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/markuplm).
+
+## Usage: MarkupLMProcessor
+
+The easiest way to prepare data for the model is to use [`MarkupLMProcessor`], which internally combines a feature extractor
+([`MarkupLMFeatureExtractor`]) and a tokenizer ([`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`]). The feature extractor is
+used to extract all nodes and xpaths from the HTML strings, which are then provided to the tokenizer, which turns them into the
+token-level inputs of the model (`input_ids` etc.). Note that you can still use the feature extractor and tokenizer separately,
+if you only want to handle one of the two tasks.
+
+```python
+from transformers import MarkupLMFeatureExtractor, MarkupLMTokenizerFast, MarkupLMProcessor
+
+feature_extractor = MarkupLMFeatureExtractor()
+tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
+processor = MarkupLMProcessor(feature_extractor, tokenizer)
+```
+
+In short, one can provide HTML strings (and possibly additional data) to [`MarkupLMProcessor`],
+and it will create the inputs expected by the model. Internally, the processor first uses
+[`MarkupLMFeatureExtractor`] to get a list of nodes and corresponding xpaths. The nodes and
+xpaths are then provided to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`], which converts them
+to token-level `input_ids`, `attention_mask`, `token_type_ids`, `xpath_subs_seq`, `xpath_tags_seq`.
+Optionally, one can provide node labels to the processor, which are turned into token-level `labels`.
+
+[`MarkupLMFeatureExtractor`] uses [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/), a Python library for
+pulling data out of HTML and XML files, under the hood. Note that you can still use your own parsing solution of
+choice, and provide the nodes and xpaths yourself to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`].
+
+In total, there are 5 use cases that are supported by the processor. Below, we list them all. Note that each of these
+use cases work for both batched and non-batched inputs (we illustrate them for non-batched inputs).
+
+**Use case 1: web page classification (training, inference) + token classification (inference), parse_html = True**
+
+This is the simplest case, in which the processor will use the feature extractor to get all nodes and xpaths from the HTML.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+
+>>> html_string = """
+...
+...
+...
+... Hello world
+...
+...
+
+... Welcome
+... Here is my website.
+
+...
+... """
+
+>>> # note that you can also add provide all tokenizer parameters here such as padding, truncation
+>>> encoding = processor(html_string, return_tensors="pt")
+>>> print(encoding.keys())
+dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
+```
+
+**Use case 2: web page classification (training, inference) + token classification (inference), parse_html=False**
+
+In case one already has obtained all nodes and xpaths, one doesn't need the feature extractor. In that case, one should
+provide the nodes and corresponding xpaths themselves to the processor, and make sure to set `parse_html` to `False`.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+>>> processor.parse_html = False
+
+>>> nodes = ["hello", "world", "how", "are"]
+>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
+>>> encoding = processor(nodes=nodes, xpaths=xpaths, return_tensors="pt")
+>>> print(encoding.keys())
+dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
+```
+
+**Use case 3: token classification (training), parse_html=False**
+
+For token classification tasks (such as [SWDE](https://paperswithcode.com/dataset/swde)), one can also provide the
+corresponding node labels in order to train a model. The processor will then convert these into token-level `labels`.
+By default, it will only label the first wordpiece of a word, and label the remaining wordpieces with -100, which is the
+`ignore_index` of PyTorch's CrossEntropyLoss. In case you want all wordpieces of a word to be labeled, you can
+initialize the tokenizer with `only_label_first_subword` set to `False`.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+>>> processor.parse_html = False
+
+>>> nodes = ["hello", "world", "how", "are"]
+>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
+>>> node_labels = [1, 2, 2, 1]
+>>> encoding = processor(nodes=nodes, xpaths=xpaths, node_labels=node_labels, return_tensors="pt")
+>>> print(encoding.keys())
+dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq', 'labels'])
+```
+
+**Use case 4: web page question answering (inference), parse_html=True**
+
+For question answering tasks on web pages, you can provide a question to the processor. By default, the
+processor will use the feature extractor to get all nodes and xpaths, and create [CLS] question tokens [SEP] word tokens [SEP].
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+
+>>> html_string = """
+...
+...
+...
+... Hello world
+...
+...
+
+... Welcome
+... My name is Niels.
+
+...
+... """
+
+>>> question = "What's his name?"
+>>> encoding = processor(html_string, questions=question, return_tensors="pt")
+>>> print(encoding.keys())
+dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
+```
+
+**Use case 5: web page question answering (inference), apply_ocr=False**
+
+For question answering tasks (such as WebSRC), you can provide a question to the processor. If you have extracted
+all nodes and xpaths yourself, you can provide them directly to the processor. Make sure to set `parse_html` to `False`.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+>>> processor.parse_html = False
+
+>>> nodes = ["hello", "world", "how", "are"]
+>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
+>>> question = "What's his name?"
+>>> encoding = processor(nodes=nodes, xpaths=xpaths, questions=question, return_tensors="pt")
+>>> print(encoding.keys())
+dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
+```
+
+## MarkupLMConfig
+
+[[autodoc]] MarkupLMConfig
+ - all
+
+## MarkupLMFeatureExtractor
+
+[[autodoc]] MarkupLMFeatureExtractor
+ - __call__
+
+## MarkupLMTokenizer
+
+[[autodoc]] MarkupLMTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## MarkupLMTokenizerFast
+
+[[autodoc]] MarkupLMTokenizerFast
+ - all
+
+## MarkupLMProcessor
+
+[[autodoc]] MarkupLMProcessor
+ - __call__
+
+## MarkupLMModel
+
+[[autodoc]] MarkupLMModel
+ - forward
+
+## MarkupLMForSequenceClassification
+
+[[autodoc]] MarkupLMForSequenceClassification
+ - forward
+
+## MarkupLMForTokenClassification
+
+[[autodoc]] MarkupLMForTokenClassification
+ - forward
+
+## MarkupLMForQuestionAnswering
+
+[[autodoc]] MarkupLMForQuestionAnswering
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index fb09d0af9f2..6478bcd7e5b 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -262,6 +262,13 @@ _import_structure = {
"models.lxmert": ["LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LxmertConfig", "LxmertTokenizer"],
"models.m2m_100": ["M2M_100_PRETRAINED_CONFIG_ARCHIVE_MAP", "M2M100Config"],
"models.marian": ["MarianConfig"],
+ "models.markuplm": [
+ "MARKUPLM_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "MarkupLMConfig",
+ "MarkupLMFeatureExtractor",
+ "MarkupLMProcessor",
+ "MarkupLMTokenizer",
+ ],
"models.maskformer": ["MASKFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "MaskFormerConfig"],
"models.mbart": ["MBartConfig"],
"models.mbart50": [],
@@ -570,6 +577,7 @@ else:
_import_structure["models.led"].append("LEDTokenizerFast")
_import_structure["models.longformer"].append("LongformerTokenizerFast")
_import_structure["models.lxmert"].append("LxmertTokenizerFast")
+ _import_structure["models.markuplm"].append("MarkupLMTokenizerFast")
_import_structure["models.mbart"].append("MBartTokenizerFast")
_import_structure["models.mbart50"].append("MBart50TokenizerFast")
_import_structure["models.mobilebert"].append("MobileBertTokenizerFast")
@@ -1488,6 +1496,16 @@ else:
"MaskFormerPreTrainedModel",
]
)
+ _import_structure["models.markuplm"].extend(
+ [
+ "MARKUPLM_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "MarkupLMForQuestionAnswering",
+ "MarkupLMForSequenceClassification",
+ "MarkupLMForTokenClassification",
+ "MarkupLMModel",
+ "MarkupLMPreTrainedModel",
+ ]
+ )
_import_structure["models.mbart"].extend(
[
"MBartForCausalLM",
@@ -3192,6 +3210,13 @@ if TYPE_CHECKING:
from .models.lxmert import LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP, LxmertConfig, LxmertTokenizer
from .models.m2m_100 import M2M_100_PRETRAINED_CONFIG_ARCHIVE_MAP, M2M100Config
from .models.marian import MarianConfig
+ from .models.markuplm import (
+ MARKUPLM_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ MarkupLMConfig,
+ MarkupLMFeatureExtractor,
+ MarkupLMProcessor,
+ MarkupLMTokenizer,
+ )
from .models.maskformer import MASKFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP, MaskFormerConfig
from .models.mbart import MBartConfig
from .models.mctct import MCTCT_PRETRAINED_CONFIG_ARCHIVE_MAP, MCTCTConfig, MCTCTProcessor
@@ -3465,6 +3490,7 @@ if TYPE_CHECKING:
from .models.led import LEDTokenizerFast
from .models.longformer import LongformerTokenizerFast
from .models.lxmert import LxmertTokenizerFast
+ from .models.markuplm import MarkupLMTokenizerFast
from .models.mbart import MBartTokenizerFast
from .models.mbart50 import MBart50TokenizerFast
from .models.mobilebert import MobileBertTokenizerFast
@@ -4196,6 +4222,14 @@ if TYPE_CHECKING:
M2M100PreTrainedModel,
)
from .models.marian import MarianForCausalLM, MarianModel, MarianMTModel
+ from .models.markuplm import (
+ MARKUPLM_PRETRAINED_MODEL_ARCHIVE_LIST,
+ MarkupLMForQuestionAnswering,
+ MarkupLMForSequenceClassification,
+ MarkupLMForTokenClassification,
+ MarkupLMModel,
+ MarkupLMPreTrainedModel,
+ )
from .models.maskformer import (
MASKFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
MaskFormerForInstanceSegmentation,
diff --git a/src/transformers/convert_slow_tokenizer.py b/src/transformers/convert_slow_tokenizer.py
index 6fbd7b49b06..ce52ba3b3be 100644
--- a/src/transformers/convert_slow_tokenizer.py
+++ b/src/transformers/convert_slow_tokenizer.py
@@ -1043,6 +1043,44 @@ class XGLMConverter(SpmConverter):
)
+class MarkupLMConverter(Converter):
+ def converted(self) -> Tokenizer:
+ ot = self.original_tokenizer
+ vocab = ot.encoder
+ merges = list(ot.bpe_ranks.keys())
+
+ tokenizer = Tokenizer(
+ BPE(
+ vocab=vocab,
+ merges=merges,
+ dropout=None,
+ continuing_subword_prefix="",
+ end_of_word_suffix="",
+ fuse_unk=False,
+ unk_token=self.original_tokenizer.unk_token,
+ )
+ )
+
+ tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=ot.add_prefix_space)
+ tokenizer.decoder = decoders.ByteLevel()
+
+ cls = str(self.original_tokenizer.cls_token)
+ sep = str(self.original_tokenizer.sep_token)
+ cls_token_id = self.original_tokenizer.cls_token_id
+ sep_token_id = self.original_tokenizer.sep_token_id
+
+ tokenizer.post_processor = processors.TemplateProcessing(
+ single=f"{cls} $A {sep}",
+ pair=f"{cls} $A {sep} $B {sep}",
+ special_tokens=[
+ (cls, cls_token_id),
+ (sep, sep_token_id),
+ ],
+ )
+
+ return tokenizer
+
+
SLOW_TO_FAST_CONVERTERS = {
"AlbertTokenizer": AlbertConverter,
"BartTokenizer": RobertaConverter,
@@ -1072,6 +1110,7 @@ SLOW_TO_FAST_CONVERTERS = {
"LongformerTokenizer": RobertaConverter,
"LEDTokenizer": RobertaConverter,
"LxmertTokenizer": BertConverter,
+ "MarkupLMTokenizer": MarkupLMConverter,
"MBartTokenizer": MBartConverter,
"MBart50Tokenizer": MBart50Converter,
"MPNetTokenizer": MPNetConverter,
diff --git a/src/transformers/file_utils.py b/src/transformers/file_utils.py
index aa3681e057b..87cd9a46918 100644
--- a/src/transformers/file_utils.py
+++ b/src/transformers/file_utils.py
@@ -79,6 +79,7 @@ from .utils import (
has_file,
http_user_agent,
is_apex_available,
+ is_bs4_available,
is_coloredlogs_available,
is_datasets_available,
is_detectron2_available,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 18c21cdf186..261d4c03e23 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -88,6 +88,7 @@ from . import (
lxmert,
m2m_100,
marian,
+ markuplm,
maskformer,
mbart,
mbart50,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 39c48b217ff..781641b74ed 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -90,6 +90,7 @@ CONFIG_MAPPING_NAMES = OrderedDict(
("lxmert", "LxmertConfig"),
("m2m_100", "M2M100Config"),
("marian", "MarianConfig"),
+ ("markuplm", "MarkupLMConfig"),
("maskformer", "MaskFormerConfig"),
("mbart", "MBartConfig"),
("mctct", "MCTCTConfig"),
@@ -221,6 +222,7 @@ CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
("luke", "LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("lxmert", "LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("m2m_100", "M2M_100_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("markuplm", "MARKUPLM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("maskformer", "MASKFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("mbart", "MBART_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("mctct", "MCTCT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -357,6 +359,7 @@ MODEL_NAMES_MAPPING = OrderedDict(
("lxmert", "LXMERT"),
("m2m_100", "M2M100"),
("marian", "Marian"),
+ ("markuplm", "MarkupLM"),
("maskformer", "MaskFormer"),
("mbart", "mBART"),
("mbart50", "mBART-50"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 936e9c8bdc4..d703c5b22a6 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -89,6 +89,7 @@ MODEL_MAPPING_NAMES = OrderedDict(
("lxmert", "LxmertModel"),
("m2m_100", "M2M100Model"),
("marian", "MarianModel"),
+ ("markuplm", "MarkupLMModel"),
("maskformer", "MaskFormerModel"),
("mbart", "MBartModel"),
("mctct", "MCTCTModel"),
@@ -247,6 +248,7 @@ MODEL_WITH_LM_HEAD_MAPPING_NAMES = OrderedDict(
("luke", "LukeForMaskedLM"),
("m2m_100", "M2M100ForConditionalGeneration"),
("marian", "MarianMTModel"),
+ ("markuplm", "MarkupLMForMaskedLM"),
("megatron-bert", "MegatronBertForCausalLM"),
("mobilebert", "MobileBertForMaskedLM"),
("mpnet", "MPNetForMaskedLM"),
@@ -530,6 +532,7 @@ MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
("led", "LEDForSequenceClassification"),
("longformer", "LongformerForSequenceClassification"),
("luke", "LukeForSequenceClassification"),
+ ("markuplm", "MarkupLMForSequenceClassification"),
("mbart", "MBartForSequenceClassification"),
("megatron-bert", "MegatronBertForSequenceClassification"),
("mobilebert", "MobileBertForSequenceClassification"),
@@ -585,6 +588,7 @@ MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES = OrderedDict(
("longformer", "LongformerForQuestionAnswering"),
("luke", "LukeForQuestionAnswering"),
("lxmert", "LxmertForQuestionAnswering"),
+ ("markuplm", "MarkupLMForQuestionAnswering"),
("mbart", "MBartForQuestionAnswering"),
("megatron-bert", "MegatronBertForQuestionAnswering"),
("mobilebert", "MobileBertForQuestionAnswering"),
@@ -654,6 +658,7 @@ MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
("layoutlmv3", "LayoutLMv3ForTokenClassification"),
("longformer", "LongformerForTokenClassification"),
("luke", "LukeForTokenClassification"),
+ ("markuplm", "MarkupLMForTokenClassification"),
("megatron-bert", "MegatronBertForTokenClassification"),
("mobilebert", "MobileBertForTokenClassification"),
("mpnet", "MPNetForTokenClassification"),
diff --git a/src/transformers/models/auto/processing_auto.py b/src/transformers/models/auto/processing_auto.py
index 07b2811a164..9885cae95e8 100644
--- a/src/transformers/models/auto/processing_auto.py
+++ b/src/transformers/models/auto/processing_auto.py
@@ -46,6 +46,7 @@ PROCESSOR_MAPPING_NAMES = OrderedDict(
("layoutlmv2", "LayoutLMv2Processor"),
("layoutlmv3", "LayoutLMv3Processor"),
("layoutxlm", "LayoutXLMProcessor"),
+ ("markuplm", "MarkupLMProcessor"),
("owlvit", "OwlViTProcessor"),
("sew", "Wav2Vec2Processor"),
("sew-d", "Wav2Vec2Processor"),
diff --git a/src/transformers/models/markuplm/__init__.py b/src/transformers/models/markuplm/__init__.py
new file mode 100644
index 00000000000..9d81b9ad369
--- /dev/null
+++ b/src/transformers/models/markuplm/__init__.py
@@ -0,0 +1,88 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+# rely on isort to merge the imports
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_tokenizers_available, is_torch_available
+
+
+_import_structure = {
+ "configuration_markuplm": ["MARKUPLM_PRETRAINED_CONFIG_ARCHIVE_MAP", "MarkupLMConfig"],
+ "feature_extraction_markuplm": ["MarkupLMFeatureExtractor"],
+ "processing_markuplm": ["MarkupLMProcessor"],
+ "tokenization_markuplm": ["MarkupLMTokenizer"],
+}
+
+try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["tokenization_markuplm_fast"] = ["MarkupLMTokenizerFast"]
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_markuplm"] = [
+ "MARKUPLM_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "MarkupLMForQuestionAnswering",
+ "MarkupLMForSequenceClassification",
+ "MarkupLMForTokenClassification",
+ "MarkupLMModel",
+ "MarkupLMPreTrainedModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_markuplm import MARKUPLM_PRETRAINED_CONFIG_ARCHIVE_MAP, MarkupLMConfig
+ from .feature_extraction_markuplm import MarkupLMFeatureExtractor
+ from .processing_markuplm import MarkupLMProcessor
+ from .tokenization_markuplm import MarkupLMTokenizer
+
+ try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .tokenization_markuplm_fast import MarkupLMTokenizerFast
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_markuplm import (
+ MARKUPLM_PRETRAINED_MODEL_ARCHIVE_LIST,
+ MarkupLMForQuestionAnswering,
+ MarkupLMForSequenceClassification,
+ MarkupLMForTokenClassification,
+ MarkupLMModel,
+ MarkupLMPreTrainedModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure)
diff --git a/src/transformers/models/markuplm/configuration_markuplm.py b/src/transformers/models/markuplm/configuration_markuplm.py
new file mode 100644
index 00000000000..a7676d7db4b
--- /dev/null
+++ b/src/transformers/models/markuplm/configuration_markuplm.py
@@ -0,0 +1,151 @@
+# coding=utf-8
+# Copyright 2021, The Microsoft Research Asia MarkupLM Team authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" MarkupLM model configuration"""
+
+from transformers.models.roberta.configuration_roberta import RobertaConfig
+from transformers.utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+MARKUPLM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "microsoft/markuplm-base": "https://huggingface.co/microsoft/markuplm-base/resolve/main/config.json",
+ "microsoft/markuplm-large": "https://huggingface.co/microsoft/markuplm-large/resolve/main/config.json",
+}
+
+
+class MarkupLMConfig(RobertaConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`MarkupLMModel`]. It is used to instantiate a
+ MarkupLM model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the MarkupLM
+ [microsoft/markuplm-base-uncased](https://huggingface.co/microsoft/markuplm-base-uncased) architecture.
+
+ Configuration objects inherit from [`BertConfig`] and can be used to control the model outputs. Read the
+ documentation from [`BertConfig`] for more information.
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 30522):
+ Vocabulary size of the MarkupLM model. Defines the different tokens that can be represented by the
+ *inputs_ids* passed to the forward method of [`MarkupLMModel`].
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"silu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout ratio for the attention probabilities.
+ max_position_embeddings (`int`, *optional*, defaults to 512):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ type_vocab_size (`int`, *optional*, defaults to 2):
+ The vocabulary size of the `token_type_ids` passed into [`MarkupLMModel`].
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ gradient_checkpointing (`bool`, *optional*, defaults to `False`):
+ If True, use gradient checkpointing to save memory at the expense of slower backward pass.
+ max_tree_id_unit_embeddings (`int`, *optional*, defaults to 1024):
+ The maximum value that the tree id unit embedding might ever use. Typically set this to something large
+ just in case (e.g., 1024).
+ max_xpath_tag_unit_embeddings (`int`, *optional*, defaults to 256):
+ The maximum value that the xpath tag unit embedding might ever use. Typically set this to something large
+ just in case (e.g., 256).
+ max_xpath_subs_unit_embeddings (`int`, *optional*, defaults to 1024):
+ The maximum value that the xpath subscript unit embedding might ever use. Typically set this to something
+ large just in case (e.g., 1024).
+ tag_pad_id (`int`, *optional*, defaults to 216):
+ The id of the padding token in the xpath tags.
+ subs_pad_id (`int`, *optional*, defaults to 1001):
+ The id of the padding token in the xpath subscripts.
+ xpath_tag_unit_hidden_size (`int`, *optional*, defaults to 32):
+ The hidden size of each tree id unit. One complete tree index will have
+ (50*xpath_tag_unit_hidden_size)-dim.
+ max_depth (`int`, *optional*, defaults to 50):
+ The maximum depth in xpath.
+
+ Examples:
+
+ ```python
+ >>> from transformers import MarkupLMModel, MarkupLMConfig
+
+ >>> # Initializing a MarkupLM microsoft/markuplm-base style configuration
+ >>> configuration = MarkupLMConfig()
+
+ >>> # Initializing a model from the microsoft/markuplm-base style configuration
+ >>> model = MarkupLMModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "markuplm"
+
+ def __init__(
+ self,
+ vocab_size=30522,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=2,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ pad_token_id=0,
+ gradient_checkpointing=False,
+ max_xpath_tag_unit_embeddings=256,
+ max_xpath_subs_unit_embeddings=1024,
+ tag_pad_id=216,
+ subs_pad_id=1001,
+ xpath_unit_hidden_size=32,
+ max_depth=50,
+ **kwargs
+ ):
+ super().__init__(
+ vocab_size=vocab_size,
+ hidden_size=hidden_size,
+ num_hidden_layers=num_hidden_layers,
+ num_attention_heads=num_attention_heads,
+ intermediate_size=intermediate_size,
+ hidden_act=hidden_act,
+ hidden_dropout_prob=hidden_dropout_prob,
+ attention_probs_dropout_prob=attention_probs_dropout_prob,
+ max_position_embeddings=max_position_embeddings,
+ type_vocab_size=type_vocab_size,
+ initializer_range=initializer_range,
+ layer_norm_eps=layer_norm_eps,
+ pad_token_id=pad_token_id,
+ gradient_checkpointing=gradient_checkpointing,
+ **kwargs,
+ )
+ # additional properties
+ self.max_depth = max_depth
+ self.max_xpath_tag_unit_embeddings = max_xpath_tag_unit_embeddings
+ self.max_xpath_subs_unit_embeddings = max_xpath_subs_unit_embeddings
+ self.tag_pad_id = tag_pad_id
+ self.subs_pad_id = subs_pad_id
+ self.xpath_unit_hidden_size = xpath_unit_hidden_size
diff --git a/src/transformers/models/markuplm/feature_extraction_markuplm.py b/src/transformers/models/markuplm/feature_extraction_markuplm.py
new file mode 100644
index 00000000000..b20349fafb0
--- /dev/null
+++ b/src/transformers/models/markuplm/feature_extraction_markuplm.py
@@ -0,0 +1,183 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Feature extractor class for MarkupLM.
+"""
+
+import html
+
+from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+from ...utils import is_bs4_available, logging, requires_backends
+
+
+if is_bs4_available():
+ import bs4
+ from bs4 import BeautifulSoup
+
+
+logger = logging.get_logger(__name__)
+
+
+class MarkupLMFeatureExtractor(FeatureExtractionMixin):
+ r"""
+ Constructs a MarkupLM feature extractor. This can be used to get a list of nodes and corresponding xpaths from HTML
+ strings.
+
+ This feature extractor inherits from [`~feature_extraction_utils.PreTrainedFeatureExtractor`] which contains most
+ of the main methods. Users should refer to this superclass for more information regarding those methods.
+
+ """
+
+ def __init__(self, **kwargs):
+ requires_backends(self, ["bs4"])
+ super().__init__(**kwargs)
+
+ def xpath_soup(self, element):
+ xpath_tags = []
+ xpath_subscripts = []
+ child = element if element.name else element.parent
+ for parent in child.parents: # type: bs4.element.Tag
+ siblings = parent.find_all(child.name, recursive=False)
+ xpath_tags.append(child.name)
+ xpath_subscripts.append(
+ 0 if 1 == len(siblings) else next(i for i, s in enumerate(siblings, 1) if s is child)
+ )
+ child = parent
+ xpath_tags.reverse()
+ xpath_subscripts.reverse()
+ return xpath_tags, xpath_subscripts
+
+ def get_three_from_single(self, html_string):
+ html_code = BeautifulSoup(html_string, "html.parser")
+
+ all_doc_strings = []
+ string2xtag_seq = []
+ string2xsubs_seq = []
+
+ for element in html_code.descendants:
+ if type(element) == bs4.element.NavigableString:
+ if type(element.parent) != bs4.element.Tag:
+ continue
+
+ text_in_this_tag = html.unescape(element).strip()
+ if not text_in_this_tag:
+ continue
+
+ all_doc_strings.append(text_in_this_tag)
+
+ xpath_tags, xpath_subscripts = self.xpath_soup(element)
+ string2xtag_seq.append(xpath_tags)
+ string2xsubs_seq.append(xpath_subscripts)
+
+ if len(all_doc_strings) != len(string2xtag_seq):
+ raise ValueError("Number of doc strings and xtags does not correspond")
+ if len(all_doc_strings) != len(string2xsubs_seq):
+ raise ValueError("Number of doc strings and xsubs does not correspond")
+
+ return all_doc_strings, string2xtag_seq, string2xsubs_seq
+
+ def construct_xpath(self, xpath_tags, xpath_subscripts):
+ xpath = ""
+ for tagname, subs in zip(xpath_tags, xpath_subscripts):
+ xpath += f"/{tagname}"
+ if subs != 0:
+ xpath += f"[{subs}]"
+ return xpath
+
+ def __call__(self, html_strings) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several HTML strings.
+
+ Args:
+ html_strings (`str`, `List[str]`):
+ The HTML string or batch of HTML strings from which to extract nodes and corresponding xpaths.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **nodes** -- Nodes.
+ - **xpaths** -- Corresponding xpaths.
+
+ Examples:
+
+ ```python
+ >>> from transformers import MarkupLMFeatureExtractor
+
+ >>> page_name_1 = "page1.html"
+ >>> page_name_2 = "page2.html"
+ >>> page_name_3 = "page3.html"
+
+ >>> with open(page_name_1) as f:
+ ... single_html_string = f.read()
+
+ >>> feature_extractor = MarkupLMFeatureExtractor()
+
+ >>> # single example
+ >>> encoding = feature_extractor(single_html_string)
+ >>> print(encoding.keys())
+ >>> # dict_keys(['nodes', 'xpaths'])
+
+ >>> # batched example
+
+ >>> multi_html_strings = []
+
+ >>> with open(page_name_2) as f:
+ ... multi_html_strings.append(f.read())
+ >>> with open(page_name_3) as f:
+ ... multi_html_strings.append(f.read())
+
+ >>> encoding = feature_extractor(multi_html_strings)
+ >>> print(encoding.keys())
+ >>> # dict_keys(['nodes', 'xpaths'])
+ ```"""
+
+ # Input type checking for clearer error
+ valid_strings = False
+
+ # Check that strings has a valid type
+ if isinstance(html_strings, str):
+ valid_strings = True
+ elif isinstance(html_strings, (list, tuple)):
+ if len(html_strings) == 0 or isinstance(html_strings[0], str):
+ valid_strings = True
+
+ if not valid_strings:
+ raise ValueError(
+ "HTML strings must of type `str`, `List[str]` (batch of examples), "
+ f"but is of type {type(html_strings)}."
+ )
+
+ is_batched = bool(isinstance(html_strings, (list, tuple)) and (isinstance(html_strings[0], str)))
+
+ if not is_batched:
+ html_strings = [html_strings]
+
+ # Get nodes + xpaths
+ nodes = []
+ xpaths = []
+ for html_string in html_strings:
+ all_doc_strings, string2xtag_seq, string2xsubs_seq = self.get_three_from_single(html_string)
+ nodes.append(all_doc_strings)
+ xpath_strings = []
+ for node, tag_list, sub_list in zip(all_doc_strings, string2xtag_seq, string2xsubs_seq):
+ xpath_string = self.construct_xpath(tag_list, sub_list)
+ xpath_strings.append(xpath_string)
+ xpaths.append(xpath_strings)
+
+ # return as Dict
+ data = {"nodes": nodes, "xpaths": xpaths}
+ encoded_inputs = BatchFeature(data=data, tensor_type=None)
+
+ return encoded_inputs
diff --git a/src/transformers/models/markuplm/modeling_markuplm.py b/src/transformers/models/markuplm/modeling_markuplm.py
new file mode 100755
index 00000000000..0a8e9050142
--- /dev/null
+++ b/src/transformers/models/markuplm/modeling_markuplm.py
@@ -0,0 +1,1300 @@
+# coding=utf-8
+# Copyright 2022 Microsoft Research Asia and the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch MarkupLM model."""
+
+import math
+import os
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from transformers.activations import ACT2FN
+from transformers.file_utils import (
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ replace_return_docstrings,
+)
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPastAndCrossAttentions,
+ BaseModelOutputWithPoolingAndCrossAttentions,
+ MaskedLMOutput,
+ QuestionAnsweringModelOutput,
+ SequenceClassifierOutput,
+ TokenClassifierOutput,
+)
+from transformers.modeling_utils import (
+ PreTrainedModel,
+ apply_chunking_to_forward,
+ find_pruneable_heads_and_indices,
+ prune_linear_layer,
+)
+from transformers.utils import logging
+
+from .configuration_markuplm import MarkupLMConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "microsoft/markuplm-base"
+_CONFIG_FOR_DOC = "MarkupLMConfig"
+_TOKENIZER_FOR_DOC = "MarkupLMTokenizer"
+
+MARKUPLM_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "microsoft/markuplm-base",
+ "microsoft/markuplm-large",
+]
+
+
+class XPathEmbeddings(nn.Module):
+ """Construct the embeddings from xpath tags and subscripts.
+
+ We drop tree-id in this version, as its info can be covered by xpath.
+ """
+
+ def __init__(self, config):
+ super(XPathEmbeddings, self).__init__()
+ self.max_depth = config.max_depth
+
+ self.xpath_unitseq2_embeddings = nn.Linear(config.xpath_unit_hidden_size * self.max_depth, config.hidden_size)
+
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ self.activation = nn.ReLU()
+ self.xpath_unitseq2_inner = nn.Linear(config.xpath_unit_hidden_size * self.max_depth, 4 * config.hidden_size)
+ self.inner2emb = nn.Linear(4 * config.hidden_size, config.hidden_size)
+
+ self.xpath_tag_sub_embeddings = nn.ModuleList(
+ [
+ nn.Embedding(config.max_xpath_tag_unit_embeddings, config.xpath_unit_hidden_size)
+ for _ in range(self.max_depth)
+ ]
+ )
+
+ self.xpath_subs_sub_embeddings = nn.ModuleList(
+ [
+ nn.Embedding(config.max_xpath_subs_unit_embeddings, config.xpath_unit_hidden_size)
+ for _ in range(self.max_depth)
+ ]
+ )
+
+ def forward(self, xpath_tags_seq=None, xpath_subs_seq=None):
+ xpath_tags_embeddings = []
+ xpath_subs_embeddings = []
+
+ for i in range(self.max_depth):
+ xpath_tags_embeddings.append(self.xpath_tag_sub_embeddings[i](xpath_tags_seq[:, :, i]))
+ xpath_subs_embeddings.append(self.xpath_subs_sub_embeddings[i](xpath_subs_seq[:, :, i]))
+
+ xpath_tags_embeddings = torch.cat(xpath_tags_embeddings, dim=-1)
+ xpath_subs_embeddings = torch.cat(xpath_subs_embeddings, dim=-1)
+
+ xpath_embeddings = xpath_tags_embeddings + xpath_subs_embeddings
+
+ xpath_embeddings = self.inner2emb(self.dropout(self.activation(self.xpath_unitseq2_inner(xpath_embeddings))))
+
+ return xpath_embeddings
+
+
+# Copied from transformers.models.roberta.modeling_roberta.create_position_ids_from_input_ids
+def create_position_ids_from_input_ids(input_ids, padding_idx, past_key_values_length=0):
+ """
+ Replace non-padding symbols with their position numbers. Position numbers begin at padding_idx+1. Padding symbols
+ are ignored. This is modified from fairseq's `utils.make_positions`.
+
+ Args:
+ x: torch.Tensor x:
+
+ Returns: torch.Tensor
+ """
+ # The series of casts and type-conversions here are carefully balanced to both work with ONNX export and XLA.
+ mask = input_ids.ne(padding_idx).int()
+ incremental_indices = (torch.cumsum(mask, dim=1).type_as(mask) + past_key_values_length) * mask
+ return incremental_indices.long() + padding_idx
+
+
+class MarkupLMEmbeddings(nn.Module):
+ """Construct the embeddings from word, position and token_type embeddings."""
+
+ def __init__(self, config):
+ super(MarkupLMEmbeddings, self).__init__()
+ self.config = config
+ self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
+
+ self.max_depth = config.max_depth
+
+ self.xpath_embeddings = XPathEmbeddings(config)
+
+ self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
+
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
+
+ self.padding_idx = config.pad_token_id
+ self.position_embeddings = nn.Embedding(
+ config.max_position_embeddings, config.hidden_size, padding_idx=self.padding_idx
+ )
+
+ # Copied from transformers.models.roberta.modeling_roberta.RobertaEmbeddings.create_position_ids_from_inputs_embeds
+ def create_position_ids_from_inputs_embeds(self, inputs_embeds):
+ """
+ We are provided embeddings directly. We cannot infer which are padded so just generate sequential position ids.
+
+ Args:
+ inputs_embeds: torch.Tensor
+
+ Returns: torch.Tensor
+ """
+ input_shape = inputs_embeds.size()[:-1]
+ sequence_length = input_shape[1]
+
+ position_ids = torch.arange(
+ self.padding_idx + 1, sequence_length + self.padding_idx + 1, dtype=torch.long, device=inputs_embeds.device
+ )
+ return position_ids.unsqueeze(0).expand(input_shape)
+
+ def forward(
+ self,
+ input_ids=None,
+ xpath_tags_seq=None,
+ xpath_subs_seq=None,
+ token_type_ids=None,
+ position_ids=None,
+ inputs_embeds=None,
+ past_key_values_length=0,
+ ):
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ else:
+ input_shape = inputs_embeds.size()[:-1]
+
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+
+ if position_ids is None:
+ if input_ids is not None:
+ # Create the position ids from the input token ids. Any padded tokens remain padded.
+ position_ids = create_position_ids_from_input_ids(input_ids, self.padding_idx, past_key_values_length)
+ else:
+ position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds)
+
+ if token_type_ids is None:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+
+ # prepare xpath seq
+ if xpath_tags_seq is None:
+ xpath_tags_seq = self.config.tag_pad_id * torch.ones(
+ tuple(list(input_shape) + [self.max_depth]), dtype=torch.long, device=device
+ )
+ if xpath_subs_seq is None:
+ xpath_subs_seq = self.config.subs_pad_id * torch.ones(
+ tuple(list(input_shape) + [self.max_depth]), dtype=torch.long, device=device
+ )
+
+ words_embeddings = inputs_embeds
+ position_embeddings = self.position_embeddings(position_ids)
+
+ token_type_embeddings = self.token_type_embeddings(token_type_ids)
+
+ xpath_embeddings = self.xpath_embeddings(xpath_tags_seq, xpath_subs_seq)
+ embeddings = words_embeddings + position_embeddings + token_type_embeddings + xpath_embeddings
+
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings
+
+
+# Copied from transformers.models.bert.modeling_bert.BertSelfOutput with Bert->MarkupLM
+class MarkupLMSelfOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+# Copied from transformers.models.bert.modeling_bert.BertIntermediate
+class MarkupLMIntermediate(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.bert.modeling_bert.BertOutput with Bert->MarkupLM
+class MarkupLMOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+# Copied from transformers.models.bert.modeling_bert.BertPooler
+class MarkupLMPooler(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+# Copied from transformers.models.bert.modeling_bert.BertPredictionHeadTransform with Bert->MarkupLM
+class MarkupLMPredictionHeadTransform(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ if isinstance(config.hidden_act, str):
+ self.transform_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.transform_act_fn = config.hidden_act
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.transform_act_fn(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.bert.modeling_bert.BertLMPredictionHead with Bert->MarkupLM
+class MarkupLMLMPredictionHead(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.transform = MarkupLMPredictionHeadTransform(config)
+
+ # The output weights are the same as the input embeddings, but there is
+ # an output-only bias for each token.
+ self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ self.bias = nn.Parameter(torch.zeros(config.vocab_size))
+
+ # Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
+ self.decoder.bias = self.bias
+
+ def forward(self, hidden_states):
+ hidden_states = self.transform(hidden_states)
+ hidden_states = self.decoder(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.bert.modeling_bert.BertOnlyMLMHead with Bert->MarkupLM
+class MarkupLMOnlyMLMHead(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.predictions = MarkupLMLMPredictionHead(config)
+
+ def forward(self, sequence_output: torch.Tensor) -> torch.Tensor:
+ prediction_scores = self.predictions(sequence_output)
+ return prediction_scores
+
+
+# Copied from transformers.models.bert.modeling_bert.BertSelfAttention with Bert->MarkupLM
+class MarkupLMSelfAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
+ f"heads ({config.num_attention_heads})"
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+ self.position_embedding_type = position_embedding_type or getattr(
+ config, "position_embedding_type", "absolute"
+ )
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ self.max_position_embeddings = config.max_position_embeddings
+ self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
+
+ self.is_decoder = config.is_decoder
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ mixed_query_layer = self.query(hidden_states)
+
+ # If this is instantiated as a cross-attention module, the keys
+ # and values come from an encoder; the attention mask needs to be
+ # such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ if is_cross_attention and past_key_value is not None:
+ # reuse k,v, cross_attentions
+ key_layer = past_key_value[0]
+ value_layer = past_key_value[1]
+ attention_mask = encoder_attention_mask
+ elif is_cross_attention:
+ key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
+ value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
+ attention_mask = encoder_attention_mask
+ elif past_key_value is not None:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+ else:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_layer, value_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ seq_length = hidden_states.size()[1]
+ position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+ positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == "relative_key":
+ relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores
+ elif self.position_embedding_type == "relative_key_query":
+ relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in MarkupLMModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ if self.is_decoder:
+ outputs = outputs + (past_key_value,)
+ return outputs
+
+
+# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->MarkupLM
+class MarkupLMAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ self.self = MarkupLMSelfAttention(config, position_embedding_type=position_embedding_type)
+ self.output = MarkupLMSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.self.query = prune_linear_layer(self.self.query, index)
+ self.self.key = prune_linear_layer(self.self.key, index)
+ self.self.value = prune_linear_layer(self.self.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
+ self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ self_outputs = self.self(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ attention_output = self.output(self_outputs[0], hidden_states)
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.bert.modeling_bert.BertLayer with Bert->MarkupLM
+class MarkupLMLayer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = MarkupLMAttention(config)
+ self.is_decoder = config.is_decoder
+ self.add_cross_attention = config.add_cross_attention
+ if self.add_cross_attention:
+ if not self.is_decoder:
+ raise ValueError(f"{self} should be used as a decoder model if cross attention is added")
+ self.crossattention = MarkupLMAttention(config, position_embedding_type="absolute")
+ self.intermediate = MarkupLMIntermediate(config)
+ self.output = MarkupLMOutput(config)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
+ self_attention_outputs = self.attention(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ output_attentions=output_attentions,
+ past_key_value=self_attn_past_key_value,
+ )
+ attention_output = self_attention_outputs[0]
+
+ # if decoder, the last output is tuple of self-attn cache
+ if self.is_decoder:
+ outputs = self_attention_outputs[1:-1]
+ present_key_value = self_attention_outputs[-1]
+ else:
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ cross_attn_present_key_value = None
+ if self.is_decoder and encoder_hidden_states is not None:
+ if not hasattr(self, "crossattention"):
+ raise ValueError(
+ f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
+ " by setting `config.add_cross_attention=True`"
+ )
+
+ # cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
+ cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
+ cross_attention_outputs = self.crossattention(
+ attention_output,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ cross_attn_past_key_value,
+ output_attentions,
+ )
+ attention_output = cross_attention_outputs[0]
+ outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
+
+ # add cross-attn cache to positions 3,4 of present_key_value tuple
+ cross_attn_present_key_value = cross_attention_outputs[-1]
+ present_key_value = present_key_value + cross_attn_present_key_value
+
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
+ )
+ outputs = (layer_output,) + outputs
+
+ # if decoder, return the attn key/values as the last output
+ if self.is_decoder:
+ outputs = outputs + (present_key_value,)
+
+ return outputs
+
+ def feed_forward_chunk(self, attention_output):
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ return layer_output
+
+
+# Copied from transformers.models.bert.modeling_bert.BertEncoder with Bert->MarkupLM
+class MarkupLMEncoder(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([MarkupLMLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = True,
+ ) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPastAndCrossAttentions]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
+
+ next_decoder_cache = () if use_cache else None
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+ past_key_value = past_key_values[i] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ if use_cache:
+ logger.warning(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, past_key_value, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+ if use_cache:
+ next_decoder_cache += (layer_outputs[-1],)
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+ if self.config.add_cross_attention:
+ all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ next_decoder_cache,
+ all_hidden_states,
+ all_self_attentions,
+ all_cross_attentions,
+ ]
+ if v is not None
+ )
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+class MarkupLMPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = MarkupLMConfig
+ pretrained_model_archive_map = MARKUPLM_PRETRAINED_MODEL_ARCHIVE_LIST
+ base_model_prefix = "markuplm"
+ _keys_to_ignore_on_load_missing = [r"position_ids"]
+
+ # Copied from transformers.models.bert.modeling_bert.BertPreTrainedModel._init_weights with Bert->MarkupLM
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, nn.Linear):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], *model_args, **kwargs):
+ return super(MarkupLMPreTrainedModel, cls).from_pretrained(
+ pretrained_model_name_or_path, *model_args, **kwargs
+ )
+
+
+MARKUPLM_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
+ it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`MarkupLMConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+MARKUPLM_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `({0})`):
+ Indices of input sequence tokens in the vocabulary.
+
+ Indices can be obtained using [`MarkupLMTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+
+ xpath_tags_seq (`torch.LongTensor` of shape `({0}, config.max_depth)`, *optional*):
+ Tag IDs for each token in the input sequence, padded up to config.max_depth.
+
+ xpath_subs_seq (`torch.LongTensor` of shape `({0}, config.max_depth)`, *optional*):
+ Subscript IDs for each token in the input sequence, padded up to config.max_depth.
+
+ attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`: `1` for
+ tokens that are NOT MASKED, `0` for MASKED tokens.
+
+ [What are attention masks?](../glossary#attention-mask)
+ token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
+ 1]`: `0` corresponds to a *sentence A* token, `1` corresponds to a *sentence B* token
+
+ [What are token type IDs?](../glossary#token-type-ids)
+ position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`: `1`
+ indicates the head is **not masked**, `0` indicates the head is **masked**.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert *input_ids* indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ If set to `True`, the attentions tensors of all attention layers are returned. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ If set to `True`, the hidden states of all layers are returned. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ If set to `True`, the model will return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare MarkupLM Model transformer outputting raw hidden-states without any specific head on top.",
+ MARKUPLM_START_DOCSTRING,
+)
+class MarkupLMModel(MarkupLMPreTrainedModel):
+ # Copied from transformers.models.bert.modeling_bert.BertModel.__init__ with Bert->MarkupLM
+ def __init__(self, config, add_pooling_layer=True):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = MarkupLMEmbeddings(config)
+ self.encoder = MarkupLMEncoder(config)
+
+ self.pooler = MarkupLMPooler(config) if add_pooling_layer else None
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value):
+ self.embeddings.word_embeddings = value
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(MARKUPLM_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=BaseModelOutputWithPoolingAndCrossAttentions, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids=None,
+ xpath_tags_seq=None,
+ xpath_subs_seq=None,
+ attention_mask=None,
+ token_type_ids=None,
+ position_ids=None,
+ head_mask=None,
+ inputs_embeds=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import MarkupLMProcessor, MarkupLMModel
+
+ >>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+ >>> model = MarkupLMModel.from_pretrained("microsoft/markuplm-base")
+
+ >>> html_string = " Page Title "
+
+ >>> encoding = processor(html_string, return_tensors="pt")
+
+ >>> outputs = model(**encoding)
+ >>> last_hidden_states = outputs.last_hidden_state
+ >>> list(last_hidden_states.shape)
+ [1, 4, 768]
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ input_shape = input_ids.size()
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+
+ if attention_mask is None:
+ attention_mask = torch.ones(input_shape, device=device)
+
+ if token_type_ids is None:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
+
+ extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
+ extended_attention_mask = extended_attention_mask.to(dtype=self.dtype)
+ extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
+
+ if head_mask is not None:
+ if head_mask.dim() == 1:
+ head_mask = head_mask.unsqueeze(0).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
+ head_mask = head_mask.expand(self.config.num_hidden_layers, -1, -1, -1, -1)
+ elif head_mask.dim() == 2:
+ head_mask = head_mask.unsqueeze(1).unsqueeze(-1).unsqueeze(-1)
+ head_mask = head_mask.to(dtype=next(self.parameters()).dtype)
+ else:
+ head_mask = [None] * self.config.num_hidden_layers
+
+ embedding_output = self.embeddings(
+ input_ids=input_ids,
+ xpath_tags_seq=xpath_tags_seq,
+ xpath_subs_seq=xpath_subs_seq,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ inputs_embeds=inputs_embeds,
+ )
+ encoder_outputs = self.encoder(
+ embedding_output,
+ extended_attention_mask,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndCrossAttentions(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ cross_attentions=encoder_outputs.cross_attentions,
+ )
+
+ # Copied from transformers.models.bert.modeling_bert.BertModel.prepare_inputs_for_generation
+ def prepare_inputs_for_generation(self, input_ids, past=None, attention_mask=None, **model_kwargs):
+ input_shape = input_ids.shape
+ # if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
+ if attention_mask is None:
+ attention_mask = input_ids.new_ones(input_shape)
+
+ # cut decoder_input_ids if past is used
+ if past is not None:
+ input_ids = input_ids[:, -1:]
+
+ return {"input_ids": input_ids, "attention_mask": attention_mask, "past_key_values": past}
+
+ # Copied from transformers.models.bert.modeling_bert.BertModel._reorder_cache
+ def _reorder_cache(self, past, beam_idx):
+ reordered_past = ()
+ for layer_past in past:
+ reordered_past += (tuple(past_state.index_select(0, beam_idx) for past_state in layer_past),)
+ return reordered_past
+
+
+@add_start_docstrings(
+ """
+ MarkupLM Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
+ layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
+ """,
+ MARKUPLM_START_DOCSTRING,
+)
+class MarkupLMForQuestionAnswering(MarkupLMPreTrainedModel):
+ _keys_to_ignore_on_load_unexpected = [r"pooler"]
+
+ # Copied from transformers.models.bert.modeling_bert.BertForQuestionAnswering.__init__ with bert->markuplm, Bert->MarkupLM
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+
+ self.markuplm = MarkupLMModel(config, add_pooling_layer=False)
+ self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(MARKUPLM_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=QuestionAnsweringModelOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids=None,
+ xpath_tags_seq=None,
+ xpath_subs_seq=None,
+ attention_mask=None,
+ token_type_ids=None,
+ position_ids=None,
+ head_mask=None,
+ inputs_embeds=None,
+ start_positions=None,
+ end_positions=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the start of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+ end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the end of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import MarkupLMProcessor, MarkupLMForQuestionAnswering
+ >>> import torch
+
+ >>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base-finetuned-websrc")
+ >>> model = MarkupLMForQuestionAnswering.from_pretrained("microsoft/markuplm-base-finetuned-websrc")
+
+ >>> html_string = " My name is Niels "
+ >>> question = "What's his name?"
+
+ >>> encoding = processor(html_string, questions=question, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... outputs = model(**encoding)
+
+ >>> answer_start_index = outputs.start_logits.argmax()
+ >>> answer_end_index = outputs.end_logits.argmax()
+
+ >>> predict_answer_tokens = encoding.input_ids[0, answer_start_index : answer_end_index + 1]
+ >>> processor.decode(predict_answer_tokens).strip()
+ 'Niels'
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.markuplm(
+ input_ids,
+ xpath_tags_seq=xpath_tags_seq,
+ xpath_subs_seq=xpath_subs_seq,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ logits = self.qa_outputs(sequence_output)
+ start_logits, end_logits = logits.split(1, dim=-1)
+ start_logits = start_logits.squeeze(-1).contiguous()
+ end_logits = end_logits.squeeze(-1).contiguous()
+
+ total_loss = None
+ if start_positions is not None and end_positions is not None:
+ # If we are on multi-GPU, split add a dimension
+ if len(start_positions.size()) > 1:
+ start_positions = start_positions.squeeze(-1)
+ if len(end_positions.size()) > 1:
+ end_positions = end_positions.squeeze(-1)
+ # sometimes the start/end positions are outside our model inputs, we ignore these terms
+ ignored_index = start_logits.size(1)
+ start_positions.clamp_(0, ignored_index)
+ end_positions.clamp_(0, ignored_index)
+
+ loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
+ start_loss = loss_fct(start_logits, start_positions)
+ end_loss = loss_fct(end_logits, end_positions)
+ total_loss = (start_loss + end_loss) / 2
+
+ if not return_dict:
+ output = (start_logits, end_logits) + outputs[2:]
+ return ((total_loss,) + output) if total_loss is not None else output
+
+ return QuestionAnsweringModelOutput(
+ loss=total_loss,
+ start_logits=start_logits,
+ end_logits=end_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings("""MarkupLM Model with a `token_classification` head on top.""", MARKUPLM_START_DOCSTRING)
+class MarkupLMForTokenClassification(MarkupLMPreTrainedModel):
+ # Copied from transformers.models.bert.modeling_bert.BertForTokenClassification.__init__ with bert->markuplm, Bert->MarkupLM
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+
+ self.markuplm = MarkupLMModel(config, add_pooling_layer=False)
+ classifier_dropout = (
+ config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
+ )
+ self.dropout = nn.Dropout(classifier_dropout)
+ self.classifier = nn.Linear(config.hidden_size, config.num_labels)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(MARKUPLM_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=MaskedLMOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids=None,
+ xpath_tags_seq=None,
+ xpath_subs_seq=None,
+ attention_mask=None,
+ token_type_ids=None,
+ position_ids=None,
+ head_mask=None,
+ inputs_embeds=None,
+ labels=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoProcessor, AutoModelForTokenClassification
+ >>> import torch
+
+ >>> processor = AutoProcessor.from_pretrained("microsoft/markuplm-base")
+ >>> processor.parse_html = False
+ >>> model = AutoModelForTokenClassification.from_pretrained("microsoft/markuplm-base", num_labels=7)
+
+ >>> nodes = ["hello", "world"]
+ >>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span"]
+ >>> node_labels = [1, 2]
+ >>> encoding = processor(nodes=nodes, xpaths=xpaths, node_labels=node_labels, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... outputs = model(**encoding)
+
+ >>> loss = outputs.loss
+ >>> logits = outputs.logits
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.markuplm(
+ input_ids,
+ xpath_tags_seq=xpath_tags_seq,
+ xpath_subs_seq=xpath_subs_seq,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+ prediction_scores = self.classifier(sequence_output) # (batch_size, seq_length, node_type_size)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(
+ prediction_scores.view(-1, self.config.num_labels),
+ labels.view(-1),
+ )
+
+ if not return_dict:
+ output = (prediction_scores,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return TokenClassifierOutput(
+ loss=loss,
+ logits=prediction_scores,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ MarkupLM Model transformer with a sequence classification/regression head on top (a linear layer on top of the
+ pooled output) e.g. for GLUE tasks.
+ """,
+ MARKUPLM_START_DOCSTRING,
+)
+class MarkupLMForSequenceClassification(MarkupLMPreTrainedModel):
+ # Copied from transformers.models.bert.modeling_bert.BertForSequenceClassification.__init__ with bert->markuplm, Bert->MarkupLM
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.config = config
+
+ self.markuplm = MarkupLMModel(config)
+ classifier_dropout = (
+ config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
+ )
+ self.dropout = nn.Dropout(classifier_dropout)
+ self.classifier = nn.Linear(config.hidden_size, config.num_labels)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(MARKUPLM_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=SequenceClassifierOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids=None,
+ xpath_tags_seq=None,
+ xpath_subs_seq=None,
+ attention_mask=None,
+ token_type_ids=None,
+ position_ids=None,
+ head_mask=None,
+ inputs_embeds=None,
+ labels=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoProcessor, AutoModelForSequenceClassification
+ >>> import torch
+
+ >>> processor = AutoProcessor.from_pretrained("microsoft/markuplm-base")
+ >>> model = AutoModelForSequenceClassification.from_pretrained("microsoft/markuplm-base", num_labels=7)
+
+ >>> html_string = " Page Title "
+ >>> encoding = processor(html_string, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... outputs = model(**encoding)
+
+ >>> loss = outputs.loss
+ >>> logits = outputs.logits
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.markuplm(
+ input_ids,
+ xpath_tags_seq=xpath_tags_seq,
+ xpath_subs_seq=xpath_subs_seq,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = outputs[1]
+
+ pooled_output = self.dropout(pooled_output)
+ logits = self.classifier(pooled_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/models/markuplm/processing_markuplm.py b/src/transformers/models/markuplm/processing_markuplm.py
new file mode 100644
index 00000000000..5740fe43abc
--- /dev/null
+++ b/src/transformers/models/markuplm/processing_markuplm.py
@@ -0,0 +1,140 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Processor class for MarkupLM.
+"""
+from typing import Optional, Union
+
+from ...file_utils import TensorType
+from ...processing_utils import ProcessorMixin
+from ...tokenization_utils_base import BatchEncoding, PaddingStrategy, TruncationStrategy
+
+
+class MarkupLMProcessor(ProcessorMixin):
+ r"""
+ Constructs a MarkupLM processor which combines a MarkupLM feature extractor and a MarkupLM tokenizer into a single
+ processor.
+
+ [`MarkupLMProcessor`] offers all the functionalities you need to prepare data for the model.
+
+ It first uses [`MarkupLMFeatureExtractor`] to extract nodes and corresponding xpaths from one or more HTML strings.
+ Next, these are provided to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`], which turns them into token-level
+ `input_ids`, `attention_mask`, `token_type_ids`, `xpath_tags_seq` and `xpath_subs_seq`.
+
+ Args:
+ feature_extractor (`MarkupLMFeatureExtractor`):
+ An instance of [`MarkupLMFeatureExtractor`]. The feature extractor is a required input.
+ tokenizer (`MarkupLMTokenizer` or `MarkupLMTokenizerFast`):
+ An instance of [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`]. The tokenizer is a required input.
+ parse_html (`bool`, *optional*, defaults to `True`):
+ Whether or not to use `MarkupLMFeatureExtractor` to parse HTML strings into nodes and corresponding xpaths.
+ """
+ feature_extractor_class = "MarkupLMFeatureExtractor"
+ tokenizer_class = ("MarkupLMTokenizer", "MarkupLMTokenizerFast")
+ parse_html = True
+
+ def __call__(
+ self,
+ html_strings=None,
+ nodes=None,
+ xpaths=None,
+ node_labels=None,
+ questions=None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = False,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ **kwargs
+ ) -> BatchEncoding:
+ """
+ This method first forwards the `html_strings` argument to [`~MarkupLMFeatureExtractor.__call__`]. Next, it
+ passes the `nodes` and `xpaths` along with the additional arguments to [`~MarkupLMTokenizer.__call__`] and
+ returns the output.
+
+ Optionally, one can also provide a `text` argument which is passed along as first sequence.
+
+ Please refer to the docstring of the above two methods for more information.
+ """
+ # first, create nodes and xpaths
+ if self.parse_html:
+ if html_strings is None:
+ raise ValueError("Make sure to pass HTML strings in case `parse_html` is set to `True`")
+
+ if nodes is not None or xpaths is not None or node_labels is not None:
+ raise ValueError(
+ "Please don't pass nodes, xpaths nor node labels in case `parse_html` is set to `True`"
+ )
+
+ features = self.feature_extractor(html_strings)
+ nodes = features["nodes"]
+ xpaths = features["xpaths"]
+ else:
+ if html_strings is not None:
+ raise ValueError("You have passed HTML strings but `parse_html` is set to `False`.")
+ if nodes is None or xpaths is None:
+ raise ValueError("Make sure to pass nodes and xpaths in case `parse_html` is set to `False`")
+
+ # # second, apply the tokenizer
+ if questions is not None and self.parse_html:
+ if isinstance(questions, str):
+ questions = [questions] # add batch dimension (as the feature extractor always adds a batch dimension)
+
+ encoded_inputs = self.tokenizer(
+ text=questions if questions is not None else nodes,
+ text_pair=nodes if questions is not None else None,
+ xpaths=xpaths,
+ node_labels=node_labels,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ return_tensors=return_tensors,
+ **kwargs,
+ )
+
+ return encoded_inputs
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to TrOCRTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please refer
+ to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to TrOCRTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer to the
+ docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
diff --git a/src/transformers/models/markuplm/tokenization_markuplm.py b/src/transformers/models/markuplm/tokenization_markuplm.py
new file mode 100644
index 00000000000..bf8d4e6dd90
--- /dev/null
+++ b/src/transformers/models/markuplm/tokenization_markuplm.py
@@ -0,0 +1,1461 @@
+# coding=utf-8
+# Copyright Microsoft Research and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tokenization class for MarkupLM."""
+
+import json
+import os
+from functools import lru_cache
+from typing import Dict, List, Optional, Tuple, Union
+
+import regex as re
+
+from ...file_utils import PaddingStrategy, TensorType, add_end_docstrings
+from ...tokenization_utils import AddedToken, PreTrainedTokenizer
+from ...tokenization_utils_base import (
+ ENCODE_KWARGS_DOCSTRING,
+ BatchEncoding,
+ EncodedInput,
+ PreTokenizedInput,
+ TextInput,
+ TextInputPair,
+ TruncationStrategy,
+)
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
+
+PRETRAINED_VOCAB_FILES_MAP = {
+ "vocab_file": {
+ "microsoft/markuplm-base": "https://huggingface.co/microsoft/markuplm-base/resolve/main/vocab.json",
+ "microsoft/markuplm-large": "https://huggingface.co/microsoft/markuplm-large/resolve/main/vocab.json",
+ },
+ "merges_file": {
+ "microsoft/markuplm-base": "https://huggingface.co/microsoft/markuplm-base/resolve/main/merges.txt",
+ "microsoft/markuplm-large": "https://huggingface.co/microsoft/markuplm-large/resolve/main/merges.txt",
+ },
+}
+
+
+PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
+ "microsoft/markuplm-base": 512,
+ "microsoft/markuplm-large": 512,
+}
+
+
+MARKUPLM_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING = r"""
+ add_special_tokens (`bool`, *optional*, defaults to `True`):
+ Whether or not to encode the sequences with the special tokens relative to their model.
+ padding (`bool`, `str` or [`~file_utils.PaddingStrategy`], *optional*, defaults to `False`):
+ Activates and controls padding. Accepts the following values:
+
+ - `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
+ sequence if provided).
+ - `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the maximum
+ acceptable input length for the model if that argument is not provided.
+ - `False` or `'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of different
+ lengths).
+ truncation (`bool`, `str` or [`~tokenization_utils_base.TruncationStrategy`], *optional*, defaults to `False`):
+ Activates and controls truncation. Accepts the following values:
+
+ - `True` or `'longest_first'`: Truncate to a maximum length specified with the argument `max_length` or
+ to the maximum acceptable input length for the model if that argument is not provided. This will
+ truncate token by token, removing a token from the longest sequence in the pair if a pair of
+ sequences (or a batch of pairs) is provided.
+ - `'only_first'`: Truncate to a maximum length specified with the argument `max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided. This will only
+ truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.
+ - `'only_second'`: Truncate to a maximum length specified with the argument `max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided. This will only
+ truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.
+ - `False` or `'do_not_truncate'` (default): No truncation (i.e., can output batch with sequence lengths
+ greater than the model maximum admissible input size).
+ max_length (`int`, *optional*):
+ Controls the maximum length to use by one of the truncation/padding parameters. If left unset or set to
+ `None`, this will use the predefined model maximum length if a maximum length is required by one of the
+ truncation/padding parameters. If the model has no specific maximum input length (like XLNet)
+ truncation/padding to a maximum length will be deactivated.
+ stride (`int`, *optional*, defaults to 0):
+ If set to a number along with `max_length`, the overflowing tokens returned when
+ `return_overflowing_tokens=True` will contain some tokens from the end of the truncated sequence
+ returned to provide some overlap between truncated and overflowing sequences. The value of this
+ argument defines the number of overlapping tokens.
+ pad_to_multiple_of (`int`, *optional*):
+ If set will pad the sequence to a multiple of the provided value. This is especially useful to enable
+ the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
+ return_tensors (`str` or [`~file_utils.TensorType`], *optional*):
+ If set, will return tensors instead of list of python integers. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return Numpy `np.ndarray` objects.
+"""
+
+
+@lru_cache()
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a mapping to unicode strings. We specifically avoids mapping to whitespace/control
+ characters the bpe code barfs on. The reversible bpe codes work on unicode strings. This means you need a large #
+ of unicode characters in your vocab if you want to avoid UNKs. When you're at something like a 10B token dataset
+ you end up needing around 5K for decent coverage. This is a significant percentage of your normal, say, 32K bpe
+ vocab. To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
+ """
+ bs = (
+ list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
+ )
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8 + n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+def get_pairs(word):
+ """
+ Return set of symbol pairs in a word. Word is represented as tuple of symbols (symbols being variable-length
+ strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+class MarkupLMTokenizer(PreTrainedTokenizer):
+ r"""
+ Construct a MarkupLM tokenizer. Based on byte-level Byte-Pair-Encoding (BPE). [`MarkupLMTokenizer`] can be used to
+ turn HTML strings into to token-level `input_ids`, `attention_mask`, `token_type_ids`, `xpath_tags_seq` and
+ `xpath_tags_seq`. This tokenizer inherits from [`PreTrainedTokenizer`] which contains most of the main methods.
+ Users should refer to this superclass for more information regarding those methods.
+
+ Args:
+ vocab_file (`str`):
+ Path to the vocabulary file.
+ merges_file (`str`):
+ Path to the merges file.
+ errors (`str`, *optional*, defaults to `"replace"`):
+ Paradigm to follow when decoding bytes to UTF-8. See
+ [bytes.decode](https://docs.python.org/3/library/stdtypes.html#bytes.decode) for more information.
+ bos_token (`str`, *optional*, defaults to `""`):
+ The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.
+
+
+
+ When building a sequence using special tokens, this is not the token that is used for the beginning of
+ sequence. The token used is the `cls_token`.
+
+
+
+ eos_token (`str`, *optional*, defaults to `""`):
+ The end of sequence token.
+
+
+
+ When building a sequence using special tokens, this is not the token that is used for the end of sequence.
+ The token used is the `sep_token`.
+
+
+
+ sep_token (`str`, *optional*, defaults to `""`):
+ The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
+ sequence classification or for a text and a question for question answering. It is also used as the last
+ token of a sequence built with special tokens.
+ cls_token (`str`, *optional*, defaults to `""`):
+ The classifier token which is used when doing sequence classification (classification of the whole sequence
+ instead of per-token classification). It is the first token of the sequence when built with special tokens.
+ unk_token (`str`, *optional*, defaults to `""`):
+ The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
+ token instead.
+ pad_token (`str`, *optional*, defaults to `""`):
+ The token used for padding, for example when batching sequences of different lengths.
+ mask_token (`str`, *optional*, defaults to `""`):
+ The token used for masking values. This is the token used when training this model with masked language
+ modeling. This is the token which the model will try to predict.
+ add_prefix_space (`bool`, *optional*, defaults to `False`):
+ Whether or not to add an initial space to the input. This allows to treat the leading word just as any
+ other word. (RoBERTa tokenizer detect beginning of words by the preceding space).
+ """
+
+ vocab_files_names = VOCAB_FILES_NAMES
+ pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
+ max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
+
+ def __init__(
+ self,
+ vocab_file,
+ merges_file,
+ tags_dict,
+ errors="replace",
+ bos_token="",
+ eos_token="",
+ sep_token="",
+ cls_token="",
+ unk_token="",
+ pad_token="",
+ mask_token="",
+ add_prefix_space=False,
+ max_depth=50,
+ max_width=1000,
+ pad_width=1001,
+ pad_token_label=-100,
+ only_label_first_subword=True,
+ **kwargs
+ ):
+ bos_token = AddedToken(bos_token, lstrip=False, rstrip=False) if isinstance(bos_token, str) else bos_token
+ eos_token = AddedToken(eos_token, lstrip=False, rstrip=False) if isinstance(eos_token, str) else eos_token
+ sep_token = AddedToken(sep_token, lstrip=False, rstrip=False) if isinstance(sep_token, str) else sep_token
+ cls_token = AddedToken(cls_token, lstrip=False, rstrip=False) if isinstance(cls_token, str) else cls_token
+ unk_token = AddedToken(unk_token, lstrip=False, rstrip=False) if isinstance(unk_token, str) else unk_token
+ pad_token = AddedToken(pad_token, lstrip=False, rstrip=False) if isinstance(pad_token, str) else pad_token
+
+ # Mask token behave like a normal word, i.e. include the space before it
+ mask_token = AddedToken(mask_token, lstrip=True, rstrip=False) if isinstance(mask_token, str) else mask_token
+
+ super().__init__(
+ vocab_file=vocab_file,
+ merges_file=merges_file,
+ tags_dict=tags_dict,
+ errors=errors,
+ bos_token=bos_token,
+ eos_token=eos_token,
+ unk_token=unk_token,
+ sep_token=sep_token,
+ cls_token=cls_token,
+ pad_token=pad_token,
+ mask_token=mask_token,
+ add_prefix_space=add_prefix_space,
+ max_depth=max_depth,
+ max_width=max_width,
+ pad_width=pad_width,
+ pad_token_label=pad_token_label,
+ only_label_first_subword=only_label_first_subword,
+ **kwargs,
+ )
+
+ with open(vocab_file, encoding="utf-8") as vocab_handle:
+ self.encoder = json.load(vocab_handle)
+
+ self.tags_dict = tags_dict
+ self.decoder = {v: k for k, v in self.encoder.items()}
+ self.errors = errors # how to handle errors in decoding
+ self.byte_encoder = bytes_to_unicode()
+ self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
+ with open(merges_file, encoding="utf-8") as merges_handle:
+ bpe_merges = merges_handle.read().split("\n")[1:-1]
+ bpe_merges = [tuple(merge.split()) for merge in bpe_merges]
+ self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges))))
+ self.cache = {}
+ self.add_prefix_space = add_prefix_space
+
+ # Should have added re.IGNORECASE so BPE merges can happen for capitalized versions of contractions
+ self.pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
+
+ # additional properties
+ self.max_depth = max_depth
+ self.max_width = max_width
+ self.pad_width = pad_width
+ self.unk_tag_id = len(self.tags_dict)
+ self.pad_tag_id = self.unk_tag_id + 1
+ self.pad_xpath_tags_seq = [self.pad_tag_id] * self.max_depth
+ self.pad_xpath_subs_seq = [self.pad_width] * self.max_depth
+ self.pad_token_label = pad_token_label
+ self.only_label_first_subword = only_label_first_subword
+
+ def get_xpath_seq(self, xpath):
+ """
+ Given the xpath expression of one particular node (like "/html/body/div/li[1]/div/span[2]"), return a list of
+ tag IDs and corresponding subscripts, taking into account max depth.
+ """
+ xpath_tags_list = []
+ xpath_subs_list = []
+
+ xpath_units = xpath.split("/")
+ for unit in xpath_units:
+ if not unit.strip():
+ continue
+ name_subs = unit.strip().split("[")
+ tag_name = name_subs[0]
+ sub = 0 if len(name_subs) == 1 else int(name_subs[1][:-1])
+ xpath_tags_list.append(self.tags_dict.get(tag_name, self.unk_tag_id))
+ xpath_subs_list.append(min(self.max_width, sub))
+
+ xpath_tags_list = xpath_tags_list[: self.max_depth]
+ xpath_subs_list = xpath_tags_list[: self.max_depth]
+ xpath_tags_list += [self.pad_tag_id] * (self.max_depth - len(xpath_tags_list))
+ xpath_subs_list += [self.pad_width] * (self.max_depth - len(xpath_subs_list))
+
+ return xpath_tags_list, xpath_subs_list
+
+ @property
+ def vocab_size(self):
+ return len(self.encoder)
+
+ def get_vocab(self):
+ return dict(self.encoder, **self.added_tokens_encoder)
+
+ def bpe(self, token):
+ if token in self.cache:
+ return self.cache[token]
+ word = tuple(token)
+ pairs = get_pairs(word)
+
+ if not pairs:
+ return token
+
+ while True:
+ bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))
+ if bigram not in self.bpe_ranks:
+ break
+ first, second = bigram
+ new_word = []
+ i = 0
+ while i < len(word):
+ try:
+ j = word.index(first, i)
+ except ValueError:
+ new_word.extend(word[i:])
+ break
+ else:
+ new_word.extend(word[i:j])
+ i = j
+
+ if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
+ new_word.append(first + second)
+ i += 2
+ else:
+ new_word.append(word[i])
+ i += 1
+ new_word = tuple(new_word)
+ word = new_word
+ if len(word) == 1:
+ break
+ else:
+ pairs = get_pairs(word)
+ word = " ".join(word)
+ self.cache[token] = word
+ return word
+
+ def _tokenize(self, text):
+ """Tokenize a string."""
+ bpe_tokens = []
+ for token in re.findall(self.pat, text):
+ token = "".join(
+ self.byte_encoder[b] for b in token.encode("utf-8")
+ ) # Maps all our bytes to unicode strings, avoiding control tokens of the BPE (spaces in our case)
+ bpe_tokens.extend(bpe_token for bpe_token in self.bpe(token).split(" "))
+ return bpe_tokens
+
+ def _convert_token_to_id(self, token):
+ """Converts a token (str) in an id using the vocab."""
+ return self.encoder.get(token, self.encoder.get(self.unk_token))
+
+ def _convert_id_to_token(self, index):
+ """Converts an index (integer) in a token (str) using the vocab."""
+ return self.decoder.get(index)
+
+ def convert_tokens_to_string(self, tokens):
+ """Converts a sequence of tokens (string) in a single string."""
+ logger.warning(
+ "MarkupLM now does not support generative tasks, decoding is experimental and subject to change."
+ )
+ text = "".join(tokens)
+ text = bytearray([self.byte_decoder[c] for c in text]).decode("utf-8", errors=self.errors)
+ return text
+
+ def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
+ if not os.path.isdir(save_directory):
+ logger.error(f"Vocabulary path ({save_directory}) should be a directory")
+ return
+ vocab_file = os.path.join(
+ save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
+ )
+ merge_file = os.path.join(
+ save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["merges_file"]
+ )
+
+ # save vocab_file
+ with open(vocab_file, "w", encoding="utf-8") as f:
+ f.write(json.dumps(self.encoder, indent=2, sort_keys=True, ensure_ascii=False) + "\n")
+
+ # save merge_file
+ index = 0
+ with open(merge_file, "w", encoding="utf-8") as writer:
+ writer.write("#version: 0.2\n")
+ for bpe_tokens, token_index in sorted(self.bpe_ranks.items(), key=lambda kv: kv[1]):
+ if index != token_index:
+ logger.warning(
+ f"Saving vocabulary to {merge_file}: BPE merge indices are not consecutive."
+ " Please check that the tokenizer is not corrupted!"
+ )
+ index = token_index
+ writer.write(" ".join(bpe_tokens) + "\n")
+ index += 1
+
+ return vocab_file, merge_file
+
+ def prepare_for_tokenization(self, text, is_split_into_words=False, **kwargs):
+ add_prefix_space = kwargs.pop("add_prefix_space", self.add_prefix_space)
+ if (is_split_into_words or add_prefix_space) and (len(text) > 0 and not text[0].isspace()):
+ text = " " + text
+ return (text, kwargs)
+
+ def build_inputs_with_special_tokens(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
+ ) -> List[int]:
+ """
+ Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
+ adding special tokens. A RoBERTa sequence has the following format:
+ - single sequence: ` X `
+ - pair of sequences: ` A B `
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs to which the special tokens will be added.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+ Returns:
+ `List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
+ """
+ if token_ids_1 is None:
+ return [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
+ cls = [self.cls_token_id]
+ sep = [self.sep_token_id]
+ return cls + token_ids_0 + sep + token_ids_1 + sep
+
+ def build_xpath_tags_with_special_tokens(
+ self, xpath_tags_0: List[int], xpath_tags_1: Optional[List[int]] = None
+ ) -> List[int]:
+ pad = [self.pad_xpath_tags_seq]
+ if len(xpath_tags_1) == 0:
+ return pad + xpath_tags_0 + pad
+ return pad + xpath_tags_0 + pad + xpath_tags_1 + pad
+
+ def build_xpath_subs_with_special_tokens(
+ self, xpath_subs_0: List[int], xpath_subs_1: Optional[List[int]] = None
+ ) -> List[int]:
+ pad = [self.pad_xpath_subs_seq]
+ if len(xpath_subs_1) == 0:
+ return pad + xpath_subs_0 + pad
+ return pad + xpath_subs_0 + pad + xpath_subs_1 + pad
+
+ def get_special_tokens_mask(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
+ ) -> List[int]:
+ """
+ Args:
+ Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
+ special tokens using the tokenizer `prepare_for_model` method.
+ token_ids_0 (`List[int]`):
+ List of IDs.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+ already_has_special_tokens (`bool`, *optional*, defaults to `False`):
+ Whether or not the token list is already formatted with special tokens for the model.
+ Returns:
+ `List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
+ """
+ if already_has_special_tokens:
+ return super().get_special_tokens_mask(
+ token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
+ )
+
+ if token_ids_1 is None:
+ return [1] + ([0] * len(token_ids_0)) + [1]
+ return [1] + ([0] * len(token_ids_0)) + [1, 1] + ([0] * len(token_ids_1)) + [1]
+
+ def create_token_type_ids_from_sequences(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
+ ) -> List[int]:
+ """
+ Create a mask from the two sequences passed to be used in a sequence-pair classification task. RoBERTa does not
+ make use of token type ids, therefore a list of zeros is returned.
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+ Returns:
+ `List[int]`: List of zeros.
+ """
+ sep = [self.sep_token_id]
+ cls = [self.cls_token_id]
+
+ if token_ids_1 is None:
+ return len(cls + token_ids_0 + sep) * [0]
+ return len(cls + token_ids_0 + sep + token_ids_1 + sep) * [0]
+
+ @add_end_docstrings(ENCODE_KWARGS_DOCSTRING, MARKUPLM_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
+ def __call__(
+ self,
+ text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]],
+ text_pair: Optional[Union[PreTokenizedInput, List[PreTokenizedInput]]] = None,
+ xpaths: Union[List[List[int]], List[List[List[int]]]] = None,
+ node_labels: Optional[Union[List[int], List[List[int]]]] = None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = False,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ **kwargs
+ ) -> BatchEncoding:
+ """
+ Main method to tokenize and prepare for the model one or several sequence(s) or one or several pair(s) of
+ sequences with node-level xpaths and optional labels.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string, a list of strings
+ (nodes of a single example or questions of a batch of examples) or a list of list of strings (batch of
+ nodes).
+ text_pair (`List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence should be a list of strings
+ (pretokenized string).
+ xpaths (`List[List[int]]`, `List[List[List[int]]]`):
+ Node-level xpaths.
+ node_labels (`List[int]`, `List[List[int]]`, *optional*):
+ Node-level integer labels (for token classification tasks).
+ """
+
+ # Input type checking for clearer error
+ def _is_valid_text_input(t):
+ if isinstance(t, str):
+ # Strings are fine
+ return True
+ elif isinstance(t, (list, tuple)):
+ # List are fine as long as they are...
+ if len(t) == 0:
+ # ... empty
+ return True
+ elif isinstance(t[0], str):
+ # ... list of strings
+ return True
+ elif isinstance(t[0], (list, tuple)):
+ # ... list with an empty list or with a list of strings
+ return len(t[0]) == 0 or isinstance(t[0][0], str)
+ else:
+ return False
+ else:
+ return False
+
+ if text_pair is not None:
+ # in case text + text_pair are provided, text = questions, text_pair = nodes
+ if not _is_valid_text_input(text):
+ raise ValueError("text input must of type `str` (single example) or `List[str]` (batch of examples). ")
+ if not isinstance(text_pair, (list, tuple)):
+ raise ValueError(
+ "Nodes must be of type `List[str]` (single pretokenized example), "
+ "or `List[List[str]]` (batch of pretokenized examples)."
+ )
+ else:
+ # in case only text is provided => must be nodes
+ if not isinstance(text, (list, tuple)):
+ raise ValueError(
+ "Nodes must be of type `List[str]` (single pretokenized example), "
+ "or `List[List[str]]` (batch of pretokenized examples)."
+ )
+
+ if text_pair is not None:
+ is_batched = isinstance(text, (list, tuple))
+ else:
+ is_batched = isinstance(text, (list, tuple)) and text and isinstance(text[0], (list, tuple))
+
+ nodes = text if text_pair is None else text_pair
+ assert xpaths is not None, "You must provide corresponding xpaths"
+ if is_batched:
+ assert len(nodes) == len(xpaths), "You must provide nodes and xpaths for an equal amount of examples"
+ for nodes_example, xpaths_example in zip(nodes, xpaths):
+ assert len(nodes_example) == len(xpaths_example), "You must provide as many nodes as there are xpaths"
+ else:
+ assert len(nodes) == len(xpaths), "You must provide as many nodes as there are xpaths"
+
+ if is_batched:
+ if text_pair is not None and len(text) != len(text_pair):
+ raise ValueError(
+ f"batch length of `text`: {len(text)} does not match batch length of `text_pair`:"
+ f" {len(text_pair)}."
+ )
+ batch_text_or_text_pairs = list(zip(text, text_pair)) if text_pair is not None else text
+ is_pair = bool(text_pair is not None)
+ return self.batch_encode_plus(
+ batch_text_or_text_pairs=batch_text_or_text_pairs,
+ is_pair=is_pair,
+ xpaths=xpaths,
+ node_labels=node_labels,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_tensors=return_tensors,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ **kwargs,
+ )
+ else:
+ return self.encode_plus(
+ text=text,
+ text_pair=text_pair,
+ xpaths=xpaths,
+ node_labels=node_labels,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_tensors=return_tensors,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ @add_end_docstrings(ENCODE_KWARGS_DOCSTRING, MARKUPLM_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
+ def batch_encode_plus(
+ self,
+ batch_text_or_text_pairs: Union[
+ List[TextInput],
+ List[TextInputPair],
+ List[PreTokenizedInput],
+ ],
+ is_pair: bool = None,
+ xpaths: Optional[List[List[List[int]]]] = None,
+ node_labels: Optional[Union[List[int], List[List[int]]]] = None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = False,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ **kwargs
+ ) -> BatchEncoding:
+ # Backward compatibility for 'truncation_strategy', 'pad_to_max_length'
+ padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ pad_to_multiple_of=pad_to_multiple_of,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ return self._batch_encode_plus(
+ batch_text_or_text_pairs=batch_text_or_text_pairs,
+ is_pair=is_pair,
+ xpaths=xpaths,
+ node_labels=node_labels,
+ add_special_tokens=add_special_tokens,
+ padding_strategy=padding_strategy,
+ truncation_strategy=truncation_strategy,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_tensors=return_tensors,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ def _batch_encode_plus(
+ self,
+ batch_text_or_text_pairs: Union[
+ List[TextInput],
+ List[TextInputPair],
+ List[PreTokenizedInput],
+ ],
+ is_pair: bool = None,
+ xpaths: Optional[List[List[List[int]]]] = None,
+ node_labels: Optional[List[List[int]]] = None,
+ add_special_tokens: bool = True,
+ padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
+ truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ **kwargs
+ ) -> BatchEncoding:
+ if return_offsets_mapping:
+ raise NotImplementedError(
+ "return_offset_mapping is not available when using Python tokenizers. "
+ "To use this feature, change your tokenizer to one deriving from "
+ "transformers.PreTrainedTokenizerFast."
+ )
+
+ batch_outputs = self._batch_prepare_for_model(
+ batch_text_or_text_pairs=batch_text_or_text_pairs,
+ is_pair=is_pair,
+ xpaths=xpaths,
+ node_labels=node_labels,
+ add_special_tokens=add_special_tokens,
+ padding_strategy=padding_strategy,
+ truncation_strategy=truncation_strategy,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_attention_mask=return_attention_mask,
+ return_token_type_ids=return_token_type_ids,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_length=return_length,
+ return_tensors=return_tensors,
+ verbose=verbose,
+ )
+
+ return BatchEncoding(batch_outputs)
+
+ @add_end_docstrings(ENCODE_KWARGS_DOCSTRING, MARKUPLM_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
+ def _batch_prepare_for_model(
+ self,
+ batch_text_or_text_pairs,
+ is_pair: bool = None,
+ xpaths: Optional[List[List[int]]] = None,
+ node_labels: Optional[List[List[int]]] = None,
+ add_special_tokens: bool = True,
+ padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
+ truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[str] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ ) -> BatchEncoding:
+ """
+ Prepares a sequence of input id, or a pair of sequences of inputs ids so that it can be used by the model. It
+ adds special tokens, truncates sequences if overflowing while taking into account the special tokens and
+ manages a moving window (with user defined stride) for overflowing tokens.
+
+ Args:
+ batch_ids_pairs: list of tokenized input ids or input ids pairs
+ """
+
+ batch_outputs = {}
+ for idx, example in enumerate(zip(batch_text_or_text_pairs, xpaths)):
+ batch_text_or_text_pair, xpaths_example = example
+ outputs = self.prepare_for_model(
+ batch_text_or_text_pair[0] if is_pair else batch_text_or_text_pair,
+ batch_text_or_text_pair[1] if is_pair else None,
+ xpaths_example,
+ node_labels=node_labels[idx] if node_labels is not None else None,
+ add_special_tokens=add_special_tokens,
+ padding=PaddingStrategy.DO_NOT_PAD.value, # we pad in batch afterward
+ truncation=truncation_strategy.value,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=None, # we pad in batch afterward
+ return_attention_mask=False, # we pad in batch afterward
+ return_token_type_ids=return_token_type_ids,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_length=return_length,
+ return_tensors=None, # We convert the whole batch to tensors at the end
+ prepend_batch_axis=False,
+ verbose=verbose,
+ )
+
+ for key, value in outputs.items():
+ if key not in batch_outputs:
+ batch_outputs[key] = []
+ batch_outputs[key].append(value)
+
+ batch_outputs = self.pad(
+ batch_outputs,
+ padding=padding_strategy.value,
+ max_length=max_length,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_attention_mask=return_attention_mask,
+ )
+
+ batch_outputs = BatchEncoding(batch_outputs, tensor_type=return_tensors)
+
+ return batch_outputs
+
+ @add_end_docstrings(ENCODE_KWARGS_DOCSTRING)
+ def encode(
+ self,
+ text: Union[TextInput, PreTokenizedInput],
+ text_pair: Optional[PreTokenizedInput] = None,
+ xpaths: Optional[List[List[int]]] = None,
+ node_labels: Optional[List[int]] = None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = False,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ **kwargs
+ ) -> List[int]:
+ encoded_inputs = self.encode_plus(
+ text=text,
+ text_pair=text_pair,
+ xpaths=xpaths,
+ node_labels=node_labels,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_tensors=return_tensors,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ return encoded_inputs["input_ids"]
+
+ @add_end_docstrings(ENCODE_KWARGS_DOCSTRING, MARKUPLM_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
+ def encode_plus(
+ self,
+ text: Union[TextInput, PreTokenizedInput],
+ text_pair: Optional[PreTokenizedInput] = None,
+ xpaths: Optional[List[List[int]]] = None,
+ node_labels: Optional[List[int]] = None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = False,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ **kwargs
+ ) -> BatchEncoding:
+ """
+ Tokenize and prepare for the model a sequence or a pair of sequences. .. warning:: This method is deprecated,
+ `__call__` should be used instead.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The first sequence to be encoded. This can be a string, a list of strings or a list of list of strings.
+ text_pair (`List[str]` or `List[int]`, *optional*):
+ Optional second sequence to be encoded. This can be a list of strings (nodes of a single example) or a
+ list of list of strings (nodes of a batch of examples).
+ """
+
+ # Backward compatibility for 'truncation_strategy', 'pad_to_max_length'
+ padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ pad_to_multiple_of=pad_to_multiple_of,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ return self._encode_plus(
+ text=text,
+ xpaths=xpaths,
+ text_pair=text_pair,
+ node_labels=node_labels,
+ add_special_tokens=add_special_tokens,
+ padding_strategy=padding_strategy,
+ truncation_strategy=truncation_strategy,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_tensors=return_tensors,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ def _encode_plus(
+ self,
+ text: Union[TextInput, PreTokenizedInput],
+ text_pair: Optional[PreTokenizedInput] = None,
+ xpaths: Optional[List[List[int]]] = None,
+ node_labels: Optional[List[int]] = None,
+ add_special_tokens: bool = True,
+ padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
+ truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ **kwargs
+ ) -> BatchEncoding:
+ if return_offsets_mapping:
+ raise NotImplementedError(
+ "return_offset_mapping is not available when using Python tokenizers. "
+ "To use this feature, change your tokenizer to one deriving from "
+ "transformers.PreTrainedTokenizerFast. "
+ "More information on available tokenizers at "
+ "https://github.com/huggingface/transformers/pull/2674"
+ )
+
+ return self.prepare_for_model(
+ text=text,
+ text_pair=text_pair,
+ xpaths=xpaths,
+ node_labels=node_labels,
+ add_special_tokens=add_special_tokens,
+ padding=padding_strategy.value,
+ truncation=truncation_strategy.value,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_tensors=return_tensors,
+ prepend_batch_axis=True,
+ return_attention_mask=return_attention_mask,
+ return_token_type_ids=return_token_type_ids,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_length=return_length,
+ verbose=verbose,
+ )
+
+ @add_end_docstrings(ENCODE_KWARGS_DOCSTRING, MARKUPLM_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
+ def prepare_for_model(
+ self,
+ text: Union[TextInput, PreTokenizedInput],
+ text_pair: Optional[PreTokenizedInput] = None,
+ xpaths: Optional[List[List[int]]] = None,
+ node_labels: Optional[List[int]] = None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = False,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ prepend_batch_axis: bool = False,
+ **kwargs
+ ) -> BatchEncoding:
+ """
+ Prepares a sequence or a pair of sequences so that it can be used by the model. It adds special tokens,
+ truncates sequences if overflowing while taking into account the special tokens and manages a moving window
+ (with user defined stride) for overflowing tokens. Please Note, for *text_pair* different than `None` and
+ *truncation_strategy = longest_first* or `True`, it is not possible to return overflowing tokens. Such a
+ combination of arguments will raise an error.
+
+ Node-level `xpaths` are turned into token-level `xpath_tags_seq` and `xpath_subs_seq`. If provided, node-level
+ `node_labels` are turned into token-level `labels`. The node label is used for the first token of the node,
+ while remaining tokens are labeled with -100, such that they will be ignored by the loss function.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The first sequence to be encoded. This can be a string, a list of strings or a list of list of strings.
+ text_pair (`List[str]` or `List[int]`, *optional*):
+ Optional second sequence to be encoded. This can be a list of strings (nodes of a single example) or a
+ list of list of strings (nodes of a batch of examples).
+ """
+
+ # Backward compatibility for 'truncation_strategy', 'pad_to_max_length'
+ padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ pad_to_multiple_of=pad_to_multiple_of,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ tokens = []
+ pair_tokens = []
+ xpath_tags_seq = []
+ xpath_subs_seq = []
+ pair_xpath_tags_seq = []
+ pair_xpath_subs_seq = []
+ labels = []
+
+ if text_pair is None:
+ if node_labels is None:
+ # CASE 1: web page classification (training + inference) + CASE 2: token classification (inference)
+ for word, xpath in zip(text, xpaths):
+ if len(word) < 1: # skip empty nodes
+ continue
+ word_tokens = self.tokenize(word)
+ tokens.extend(word_tokens)
+ xpath_tags_list, xpath_subs_list = self.get_xpath_seq(xpath)
+ xpath_tags_seq.extend([xpath_tags_list] * len(word_tokens))
+ xpath_subs_seq.extend([xpath_subs_list] * len(word_tokens))
+ else:
+ # CASE 2: token classification (training)
+ for word, xpath, label in zip(text, xpaths, node_labels):
+ if len(word) < 1: # skip empty nodes
+ continue
+ word_tokens = self.tokenize(word)
+ tokens.extend(word_tokens)
+ xpath_tags_list, xpath_subs_list = self.get_xpath_seq(xpath)
+ xpath_tags_seq.extend([xpath_tags_list] * len(word_tokens))
+ xpath_subs_seq.extend([xpath_subs_list] * len(word_tokens))
+ if self.only_label_first_subword:
+ # Use the real label id for the first token of the word, and padding ids for the remaining tokens
+ labels.extend([label] + [self.pad_token_label] * (len(word_tokens) - 1))
+ else:
+ labels.extend([label] * len(word_tokens))
+ else:
+ # CASE 3: web page question answering (inference)
+ # text = question
+ # text_pair = nodes
+ tokens = self.tokenize(text)
+ xpath_tags_seq = [self.pad_xpath_tags_seq for _ in range(len(tokens))]
+ xpath_subs_seq = [self.pad_xpath_subs_seq for _ in range(len(tokens))]
+
+ for word, xpath in zip(text_pair, xpaths):
+ if len(word) < 1: # skip empty nodes
+ continue
+ word_tokens = self.tokenize(word)
+ pair_tokens.extend(word_tokens)
+ xpath_tags_list, xpath_subs_list = self.get_xpath_seq(xpath)
+ pair_xpath_tags_seq.extend([xpath_tags_list] * len(word_tokens))
+ pair_xpath_subs_seq.extend([xpath_subs_list] * len(word_tokens))
+
+ # Create ids + pair_ids
+ ids = self.convert_tokens_to_ids(tokens)
+ pair_ids = self.convert_tokens_to_ids(pair_tokens) if pair_tokens else None
+
+ if (
+ return_overflowing_tokens
+ and truncation_strategy == TruncationStrategy.LONGEST_FIRST
+ and pair_ids is not None
+ ):
+ raise ValueError(
+ "Not possible to return overflowing tokens for pair of sequences with the "
+ "`longest_first`. Please select another truncation strategy than `longest_first`, "
+ "for instance `only_second` or `only_first`."
+ )
+
+ # Compute the total size of the returned encodings
+ pair = bool(pair_ids is not None)
+ len_ids = len(ids)
+ len_pair_ids = len(pair_ids) if pair else 0
+ total_len = len_ids + len_pair_ids + (self.num_special_tokens_to_add(pair=pair) if add_special_tokens else 0)
+
+ # Truncation: Handle max sequence length
+ overflowing_tokens = []
+ overflowing_xpath_tags_seq = []
+ overflowing_xpath_subs_seq = []
+ overflowing_labels = []
+ if truncation_strategy != TruncationStrategy.DO_NOT_TRUNCATE and max_length and total_len > max_length:
+ (
+ ids,
+ xpath_tags_seq,
+ xpath_subs_seq,
+ pair_ids,
+ pair_xpath_tags_seq,
+ pair_xpath_subs_seq,
+ labels,
+ overflowing_tokens,
+ overflowing_xpath_tags_seq,
+ overflowing_xpath_subs_seq,
+ overflowing_labels,
+ ) = self.truncate_sequences(
+ ids,
+ xpath_tags_seq=xpath_tags_seq,
+ xpath_subs_seq=xpath_subs_seq,
+ pair_ids=pair_ids,
+ pair_xpath_tags_seq=pair_xpath_tags_seq,
+ pair_xpath_subs_seq=pair_xpath_subs_seq,
+ labels=labels,
+ num_tokens_to_remove=total_len - max_length,
+ truncation_strategy=truncation_strategy,
+ stride=stride,
+ )
+
+ if return_token_type_ids and not add_special_tokens:
+ raise ValueError(
+ "Asking to return token_type_ids while setting add_special_tokens to False "
+ "results in an undefined behavior. Please set add_special_tokens to True or "
+ "set return_token_type_ids to None."
+ )
+
+ # Load from model defaults
+ if return_token_type_ids is None:
+ return_token_type_ids = "token_type_ids" in self.model_input_names
+ if return_attention_mask is None:
+ return_attention_mask = "attention_mask" in self.model_input_names
+
+ encoded_inputs = {}
+
+ if return_overflowing_tokens:
+ encoded_inputs["overflowing_tokens"] = overflowing_tokens
+ encoded_inputs["overflowing_xpath_tags_seq"] = overflowing_xpath_tags_seq
+ encoded_inputs["overflowing_xpath_subs_seq"] = overflowing_xpath_subs_seq
+ encoded_inputs["overflowing_labels"] = overflowing_labels
+ encoded_inputs["num_truncated_tokens"] = total_len - max_length
+
+ # Add special tokens
+ if add_special_tokens:
+ sequence = self.build_inputs_with_special_tokens(ids, pair_ids)
+ token_type_ids = self.create_token_type_ids_from_sequences(ids, pair_ids)
+ xpath_tags_ids = self.build_xpath_tags_with_special_tokens(xpath_tags_seq, pair_xpath_tags_seq)
+ xpath_subs_ids = self.build_xpath_subs_with_special_tokens(xpath_subs_seq, pair_xpath_subs_seq)
+ if labels:
+ labels = [self.pad_token_label] + labels + [self.pad_token_label]
+ else:
+ sequence = ids + pair_ids if pair else ids
+ token_type_ids = [0] * len(ids) + ([0] * len(pair_ids) if pair else [])
+ xpath_tags_ids = xpath_tags_seq + pair_xpath_tags_seq if pair else xpath_tags_seq
+ xpath_subs_ids = xpath_subs_seq + pair_xpath_subs_seq if pair else xpath_subs_seq
+
+ # Build output dictionary
+ encoded_inputs["input_ids"] = sequence
+ encoded_inputs["xpath_tags_seq"] = xpath_tags_ids
+ encoded_inputs["xpath_subs_seq"] = xpath_subs_ids
+ if return_token_type_ids:
+ encoded_inputs["token_type_ids"] = token_type_ids
+ if return_special_tokens_mask:
+ if add_special_tokens:
+ encoded_inputs["special_tokens_mask"] = self.get_special_tokens_mask(ids, pair_ids)
+ else:
+ encoded_inputs["special_tokens_mask"] = [0] * len(sequence)
+
+ if labels:
+ encoded_inputs["labels"] = labels
+
+ # Check lengths
+ self._eventual_warn_about_too_long_sequence(encoded_inputs["input_ids"], max_length, verbose)
+
+ # Padding
+ if padding_strategy != PaddingStrategy.DO_NOT_PAD or return_attention_mask:
+ encoded_inputs = self.pad(
+ encoded_inputs,
+ max_length=max_length,
+ padding=padding_strategy.value,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_attention_mask=return_attention_mask,
+ )
+
+ if return_length:
+ encoded_inputs["length"] = len(encoded_inputs["input_ids"])
+
+ batch_outputs = BatchEncoding(
+ encoded_inputs, tensor_type=return_tensors, prepend_batch_axis=prepend_batch_axis
+ )
+
+ return batch_outputs
+
+ def truncate_sequences(
+ self,
+ ids: List[int],
+ xpath_tags_seq: List[List[int]],
+ xpath_subs_seq: List[List[int]],
+ pair_ids: Optional[List[int]] = None,
+ pair_xpath_tags_seq: Optional[List[List[int]]] = None,
+ pair_xpath_subs_seq: Optional[List[List[int]]] = None,
+ labels: Optional[List[int]] = None,
+ num_tokens_to_remove: int = 0,
+ truncation_strategy: Union[str, TruncationStrategy] = "longest_first",
+ stride: int = 0,
+ ) -> Tuple[List[int], List[int], List[int]]:
+ """
+ Args:
+ Truncates a sequence pair in-place following the strategy.
+ ids (`List[int]`):
+ Tokenized input ids of the first sequence. Can be obtained from a string by chaining the `tokenize` and
+ `convert_tokens_to_ids` methods.
+ xpath_tags_seq (`List[List[int]]`):
+ XPath tag IDs of the first sequence.
+ xpath_subs_seq (`List[List[int]]`):
+ XPath sub IDs of the first sequence.
+ pair_ids (`List[int]`, *optional*):
+ Tokenized input ids of the second sequence. Can be obtained from a string by chaining the `tokenize`
+ and `convert_tokens_to_ids` methods.
+ pair_xpath_tags_seq (`List[List[int]]`, *optional*):
+ XPath tag IDs of the second sequence.
+ pair_xpath_subs_seq (`List[List[int]]`, *optional*):
+ XPath sub IDs of the second sequence.
+ num_tokens_to_remove (`int`, *optional*, defaults to 0):
+ Number of tokens to remove using the truncation strategy.
+ truncation_strategy (`str` or [`~tokenization_utils_base.TruncationStrategy`], *optional*, defaults to
+ `False`):
+ The strategy to follow for truncation. Can be:
+ - `'longest_first'`: Truncate to a maximum length specified with the argument `max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided. This will truncate
+ token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a
+ batch of pairs) is provided.
+ - `'only_first'`: Truncate to a maximum length specified with the argument `max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided. This will only
+ truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.
+ - `'only_second'`: Truncate to a maximum length specified with the argument `max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided. This will only
+ truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.
+ - `'do_not_truncate'` (default): No truncation (i.e., can output batch with sequence lengths greater
+ than the model maximum admissible input size).
+ stride (`int`, *optional*, defaults to 0):
+ If set to a positive number, the overflowing tokens returned will contain some tokens from the main
+ sequence returned. The value of this argument defines the number of additional tokens.
+ Returns:
+ `Tuple[List[int], List[int], List[int]]`: The truncated `ids`, the truncated `pair_ids` and the list of
+ overflowing tokens. Note: The *longest_first* strategy returns empty list of overflowing tokens if a pair
+ of sequences (or a batch of pairs) is provided.
+ """
+ if num_tokens_to_remove <= 0:
+ return ids, xpath_tags_seq, xpath_subs_seq, pair_ids, pair_xpath_tags_seq, pair_xpath_subs_seq, [], [], []
+
+ if not isinstance(truncation_strategy, TruncationStrategy):
+ truncation_strategy = TruncationStrategy(truncation_strategy)
+
+ overflowing_tokens = []
+ overflowing_xpath_tags_seq = []
+ overflowing_xpath_subs_seq = []
+ overflowing_labels = []
+ if truncation_strategy == TruncationStrategy.ONLY_FIRST or (
+ truncation_strategy == TruncationStrategy.LONGEST_FIRST and pair_ids is None
+ ):
+ if len(ids) > num_tokens_to_remove:
+ window_len = min(len(ids), stride + num_tokens_to_remove)
+ overflowing_tokens = ids[-window_len:]
+ overflowing_xpath_tags_seq = xpath_tags_seq[-window_len:]
+ overflowing_xpath_subs_seq = xpath_subs_seq[-window_len:]
+ ids = ids[:-num_tokens_to_remove]
+ xpath_tags_seq = xpath_tags_seq[:-num_tokens_to_remove]
+ xpath_subs_seq = xpath_subs_seq[:-num_tokens_to_remove]
+ labels = labels[:-num_tokens_to_remove]
+ else:
+ error_msg = (
+ f"We need to remove {num_tokens_to_remove} to truncate the input "
+ f"but the first sequence has a length {len(ids)}. "
+ )
+ if truncation_strategy == TruncationStrategy.ONLY_FIRST:
+ error_msg = (
+ error_msg
+ + "Please select another truncation strategy than "
+ f"{truncation_strategy}, for instance 'longest_first' or 'only_second'."
+ )
+ logger.error(error_msg)
+ elif truncation_strategy == TruncationStrategy.LONGEST_FIRST:
+ logger.warning(
+ "Be aware, overflowing tokens are not returned for the setting you have chosen,"
+ f" i.e. sequence pairs with the '{TruncationStrategy.LONGEST_FIRST.value}' "
+ "truncation strategy. So the returned list will always be empty even if some "
+ "tokens have been removed."
+ )
+ for _ in range(num_tokens_to_remove):
+ if pair_ids is None or len(ids) > len(pair_ids):
+ ids = ids[:-1]
+ xpath_tags_seq = xpath_tags_seq[:-1]
+ xpath_subs_seq = xpath_subs_seq[:-1]
+ labels = labels[:-1]
+ else:
+ pair_ids = pair_ids[:-1]
+ pair_xpath_tags_seq = pair_xpath_tags_seq[:-1]
+ pair_xpath_subs_seq = pair_xpath_subs_seq[:-1]
+ elif truncation_strategy == TruncationStrategy.ONLY_SECOND and pair_ids is not None:
+ if len(pair_ids) > num_tokens_to_remove:
+ window_len = min(len(pair_ids), stride + num_tokens_to_remove)
+ overflowing_tokens = pair_ids[-window_len:]
+ overflowing_xpath_tags_seq = pair_xpath_tags_seq[-window_len:]
+ overflowing_xpath_subs_seq = pair_xpath_subs_seq[-window_len:]
+ pair_ids = pair_ids[:-num_tokens_to_remove]
+ pair_xpath_tags_seq = pair_xpath_tags_seq[:-num_tokens_to_remove]
+ pair_xpath_subs_seq = pair_xpath_subs_seq[:-num_tokens_to_remove]
+ else:
+ logger.error(
+ f"We need to remove {num_tokens_to_remove} to truncate the input "
+ f"but the second sequence has a length {len(pair_ids)}. "
+ f"Please select another truncation strategy than {truncation_strategy}, "
+ "for instance 'longest_first' or 'only_first'."
+ )
+
+ return (
+ ids,
+ xpath_tags_seq,
+ xpath_subs_seq,
+ pair_ids,
+ pair_xpath_tags_seq,
+ pair_xpath_subs_seq,
+ labels,
+ overflowing_tokens,
+ overflowing_xpath_tags_seq,
+ overflowing_xpath_subs_seq,
+ overflowing_labels,
+ )
+
+ def _pad(
+ self,
+ encoded_inputs: Union[Dict[str, EncodedInput], BatchEncoding],
+ max_length: Optional[int] = None,
+ padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
+ pad_to_multiple_of: Optional[int] = None,
+ return_attention_mask: Optional[bool] = None,
+ ) -> dict:
+ """
+ Args:
+ Pad encoded inputs (on left/right and up to predefined length or max length in the batch)
+ encoded_inputs:
+ Dictionary of tokenized inputs (`List[int]`) or batch of tokenized inputs (`List[List[int]]`).
+ max_length: maximum length of the returned list and optionally padding length (see below).
+ Will truncate by taking into account the special tokens.
+ padding_strategy: PaddingStrategy to use for padding.
+ - PaddingStrategy.LONGEST Pad to the longest sequence in the batch
+ - PaddingStrategy.MAX_LENGTH: Pad to the max length (default)
+ - PaddingStrategy.DO_NOT_PAD: Do not pad
+ The tokenizer padding sides are defined in self.padding_side:
+ - 'left': pads on the left of the sequences
+ - 'right': pads on the right of the sequences
+ pad_to_multiple_of: (optional) Integer if set will pad the sequence to a multiple of the provided value.
+ This is especially useful to enable the use of Tensor Core on NVIDIA hardware with compute capability
+ >= 7.5 (Volta).
+ return_attention_mask:
+ (optional) Set to False to avoid returning attention mask (default: set to model specifics)
+ """
+ # Load from model defaults
+ if return_attention_mask is None:
+ return_attention_mask = "attention_mask" in self.model_input_names
+
+ required_input = encoded_inputs[self.model_input_names[0]]
+
+ if padding_strategy == PaddingStrategy.LONGEST:
+ max_length = len(required_input)
+
+ if max_length is not None and pad_to_multiple_of is not None and (max_length % pad_to_multiple_of != 0):
+ max_length = ((max_length // pad_to_multiple_of) + 1) * pad_to_multiple_of
+
+ needs_to_be_padded = padding_strategy != PaddingStrategy.DO_NOT_PAD and len(required_input) != max_length
+
+ # Initialize attention mask if not present.
+ if return_attention_mask and "attention_mask" not in encoded_inputs:
+ encoded_inputs["attention_mask"] = [1] * len(required_input)
+
+ if needs_to_be_padded:
+ difference = max_length - len(required_input)
+ if self.padding_side == "right":
+ if return_attention_mask:
+ encoded_inputs["attention_mask"] = encoded_inputs["attention_mask"] + [0] * difference
+ if "token_type_ids" in encoded_inputs:
+ encoded_inputs["token_type_ids"] = (
+ encoded_inputs["token_type_ids"] + [self.pad_token_type_id] * difference
+ )
+ if "xpath_tags_seq" in encoded_inputs:
+ encoded_inputs["xpath_tags_seq"] = (
+ encoded_inputs["xpath_tags_seq"] + [self.pad_xpath_tags_seq] * difference
+ )
+ if "xpath_subs_seq" in encoded_inputs:
+ encoded_inputs["xpath_subs_seq"] = (
+ encoded_inputs["xpath_subs_seq"] + [self.pad_xpath_subs_seq] * difference
+ )
+ if "labels" in encoded_inputs:
+ encoded_inputs["labels"] = encoded_inputs["labels"] + [self.pad_token_label] * difference
+ if "special_tokens_mask" in encoded_inputs:
+ encoded_inputs["special_tokens_mask"] = encoded_inputs["special_tokens_mask"] + [1] * difference
+ encoded_inputs[self.model_input_names[0]] = required_input + [self.pad_token_id] * difference
+ elif self.padding_side == "left":
+ if return_attention_mask:
+ encoded_inputs["attention_mask"] = [0] * difference + encoded_inputs["attention_mask"]
+ if "token_type_ids" in encoded_inputs:
+ encoded_inputs["token_type_ids"] = [self.pad_token_type_id] * difference + encoded_inputs[
+ "token_type_ids"
+ ]
+ if "xpath_tags_seq" in encoded_inputs:
+ encoded_inputs["xpath_tags_seq"] = [self.pad_xpath_tags_seq] * difference + encoded_inputs[
+ "xpath_tags_seq"
+ ]
+ if "xpath_subs_seq" in encoded_inputs:
+ encoded_inputs["xpath_subs_seq"] = [self.pad_xpath_subs_seq] * difference + encoded_inputs[
+ "xpath_subs_seq"
+ ]
+ if "labels" in encoded_inputs:
+ encoded_inputs["labels"] = [self.pad_token_label] * difference + encoded_inputs["labels"]
+ if "special_tokens_mask" in encoded_inputs:
+ encoded_inputs["special_tokens_mask"] = [1] * difference + encoded_inputs["special_tokens_mask"]
+ encoded_inputs[self.model_input_names[0]] = [self.pad_token_id] * difference + required_input
+ else:
+ raise ValueError("Invalid padding strategy:" + str(self.padding_side))
+
+ return encoded_inputs
diff --git a/src/transformers/models/markuplm/tokenization_markuplm_fast.py b/src/transformers/models/markuplm/tokenization_markuplm_fast.py
new file mode 100644
index 00000000000..5e76f4d0bc1
--- /dev/null
+++ b/src/transformers/models/markuplm/tokenization_markuplm_fast.py
@@ -0,0 +1,924 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fast tokenization class for MarkupLM. It overwrites 2 methods of the slow tokenizer class, namely _batch_encode_plus
+and _encode_plus, in which the Rust tokenizer is used.
+"""
+
+import json
+from functools import lru_cache
+from typing import Dict, List, Optional, Tuple, Union
+
+from tokenizers import pre_tokenizers, processors
+
+from ...file_utils import PaddingStrategy, TensorType, add_end_docstrings
+from ...tokenization_utils_base import (
+ ENCODE_KWARGS_DOCSTRING,
+ BatchEncoding,
+ EncodedInput,
+ PreTokenizedInput,
+ TextInput,
+ TextInputPair,
+ TruncationStrategy,
+)
+from ...tokenization_utils_fast import PreTrainedTokenizerFast
+from ...utils import logging
+from .tokenization_markuplm import MARKUPLM_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING, MarkupLMTokenizer
+
+
+logger = logging.get_logger(__name__)
+
+VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
+
+PRETRAINED_VOCAB_FILES_MAP = {
+ "vocab_file": {
+ "microsoft/markuplm-base": "https://huggingface.co/microsoft/markuplm-base/resolve/main/vocab.json",
+ "microsoft/markuplm-large": "https://huggingface.co/microsoft/markuplm-large/resolve/main/vocab.json",
+ },
+ "merges_file": {
+ "microsoft/markuplm-base": "https://huggingface.co/microsoft/markuplm-base/resolve/main/merges.txt",
+ "microsoft/markuplm-large": "https://huggingface.co/microsoft/markuplm-large/resolve/main/merges.txt",
+ },
+}
+
+
+PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
+ "microsoft/markuplm-base": 512,
+ "microsoft/markuplm-large": 512,
+}
+
+
+@lru_cache()
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a mapping to unicode strings. We specifically avoids mapping to whitespace/control
+ characters the bpe code barfs on. The reversible bpe codes work on unicode strings. This means you need a large #
+ of unicode characters in your vocab if you want to avoid UNKs. When you're at something like a 10B token dataset
+ you end up needing around 5K for decent coverage. This is a significant percentage of your normal, say, 32K bpe
+ vocab. To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
+ """
+ bs = (
+ list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
+ )
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8 + n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+def get_pairs(word):
+ """
+ Return set of symbol pairs in a word. Word is represented as tuple of symbols (symbols being variable-length
+ strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+class MarkupLMTokenizerFast(PreTrainedTokenizerFast):
+ r"""
+ Construct a MarkupLM tokenizer. Based on byte-level Byte-Pair-Encoding (BPE).
+
+ [`MarkupLMTokenizerFast`] can be used to turn HTML strings into to token-level `input_ids`, `attention_mask`,
+ `token_type_ids`, `xpath_tags_seq` and `xpath_tags_seq`. This tokenizer inherits from [`PreTrainedTokenizer`] which
+ contains most of the main methods.
+
+ Users should refer to this superclass for more information regarding those methods.
+
+ Args:
+ vocab_file (`str`):
+ Path to the vocabulary file.
+ merges_file (`str`):
+ Path to the merges file.
+ errors (`str`, *optional*, defaults to `"replace"`):
+ Paradigm to follow when decoding bytes to UTF-8. See
+ [bytes.decode](https://docs.python.org/3/library/stdtypes.html#bytes.decode) for more information.
+ bos_token (`str`, *optional*, defaults to `""`):
+ The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.
+
+
+
+ When building a sequence using special tokens, this is not the token that is used for the beginning of
+ sequence. The token used is the `cls_token`.
+
+
+
+ eos_token (`str`, *optional*, defaults to `""`):
+ The end of sequence token.
+
+
+
+ When building a sequence using special tokens, this is not the token that is used for the end of sequence.
+ The token used is the `sep_token`.
+
+
+
+ sep_token (`str`, *optional*, defaults to `""`):
+ The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
+ sequence classification or for a text and a question for question answering. It is also used as the last
+ token of a sequence built with special tokens.
+ cls_token (`str`, *optional*, defaults to `""`):
+ The classifier token which is used when doing sequence classification (classification of the whole sequence
+ instead of per-token classification). It is the first token of the sequence when built with special tokens.
+ unk_token (`str`, *optional*, defaults to `""`):
+ The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
+ token instead.
+ pad_token (`str`, *optional*, defaults to `""`):
+ The token used for padding, for example when batching sequences of different lengths.
+ mask_token (`str`, *optional*, defaults to `""`):
+ The token used for masking values. This is the token used when training this model with masked language
+ modeling. This is the token which the model will try to predict.
+ add_prefix_space (`bool`, *optional*, defaults to `False`):
+ Whether or not to add an initial space to the input. This allows to treat the leading word just as any
+ other word. (RoBERTa tokenizer detect beginning of words by the preceding space).
+ """
+
+ vocab_files_names = VOCAB_FILES_NAMES
+ pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
+ max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
+ slow_tokenizer_class = MarkupLMTokenizer
+
+ def __init__(
+ self,
+ vocab_file,
+ merges_file,
+ tags_dict,
+ tokenizer_file=None,
+ errors="replace",
+ bos_token="",
+ eos_token="",
+ sep_token="",
+ cls_token="",
+ unk_token="",
+ pad_token="",
+ mask_token="",
+ add_prefix_space=False,
+ max_depth=50,
+ max_width=1000,
+ pad_width=1001,
+ pad_token_label=-100,
+ only_label_first_subword=True,
+ trim_offsets=False,
+ **kwargs
+ ):
+ super().__init__(
+ vocab_file=vocab_file,
+ merges_file=merges_file,
+ tags_dict=tags_dict,
+ tokenizer_file=tokenizer_file,
+ errors=errors,
+ bos_token=bos_token,
+ eos_token=eos_token,
+ unk_token=unk_token,
+ sep_token=sep_token,
+ cls_token=cls_token,
+ pad_token=pad_token,
+ mask_token=mask_token,
+ add_prefix_space=add_prefix_space,
+ trim_offsets=trim_offsets,
+ max_depth=max_depth,
+ max_width=max_width,
+ pad_width=pad_width,
+ pad_token_label=pad_token_label,
+ only_label_first_subword=only_label_first_subword,
+ **kwargs,
+ )
+ if trim_offsets:
+ # Not implemented yet, because we need to chain two post processors which is not possible yet
+ # We need to wait for https://github.com/huggingface/tokenizers/pull/1005
+ # With `trim_offsets=False` we don't need to do add `processors.ByteLevel(trim_offsets=False)`
+ # because it's not doing anything
+ raise NotImplementedError(
+ "`trim_offsets=True` is not implemented for MarkupLMTokenizerFast. Please set it to False."
+ )
+
+ self.tags_dict = tags_dict
+
+ pre_tok_state = json.loads(self.backend_tokenizer.pre_tokenizer.__getstate__())
+ if pre_tok_state.get("add_prefix_space", add_prefix_space) != add_prefix_space:
+ pre_tok_class = getattr(pre_tokenizers, pre_tok_state.pop("type"))
+ pre_tok_state["add_prefix_space"] = add_prefix_space
+ self.backend_tokenizer.pre_tokenizer = pre_tok_class(**pre_tok_state)
+
+ self.add_prefix_space = add_prefix_space
+
+ tokenizer_component = "post_processor"
+ tokenizer_component_instance = getattr(self.backend_tokenizer, tokenizer_component, None)
+ if tokenizer_component_instance:
+ state = json.loads(tokenizer_component_instance.__getstate__())
+
+ # The lists 'sep' and 'cls' must be cased in tuples for the object `post_processor_class`
+ if "sep" in state:
+ state["sep"] = tuple(state["sep"])
+ if "cls" in state:
+ state["cls"] = tuple(state["cls"])
+
+ changes_to_apply = False
+
+ if state.get("add_prefix_space", add_prefix_space) != add_prefix_space:
+ state["add_prefix_space"] = add_prefix_space
+ changes_to_apply = True
+
+ if changes_to_apply:
+ component_class = getattr(processors, state.pop("type"))
+ new_value = component_class(**state)
+ setattr(self.backend_tokenizer, tokenizer_component, new_value)
+
+ # additional properties
+ self.max_depth = max_depth
+ self.max_width = max_width
+ self.pad_width = pad_width
+ self.unk_tag_id = len(self.tags_dict)
+ self.pad_tag_id = self.unk_tag_id + 1
+ self.pad_xpath_tags_seq = [self.pad_tag_id] * self.max_depth
+ self.pad_xpath_subs_seq = [self.pad_width] * self.max_depth
+ self.pad_token_label = pad_token_label
+ self.only_label_first_subword = only_label_first_subword
+
+ def get_xpath_seq(self, xpath):
+ """
+ Given the xpath expression of one particular node (like "/html/body/div/li[1]/div/span[2]"), return a list of
+ tag IDs and corresponding subscripts, taking into account max depth.
+ """
+ xpath_tags_list = []
+ xpath_subs_list = []
+
+ xpath_units = xpath.split("/")
+ for unit in xpath_units:
+ if not unit.strip():
+ continue
+ name_subs = unit.strip().split("[")
+ tag_name = name_subs[0]
+ sub = 0 if len(name_subs) == 1 else int(name_subs[1][:-1])
+ xpath_tags_list.append(self.tags_dict.get(tag_name, self.unk_tag_id))
+ xpath_subs_list.append(min(self.max_width, sub))
+
+ xpath_tags_list = xpath_tags_list[: self.max_depth]
+ xpath_subs_list = xpath_tags_list[: self.max_depth]
+ xpath_tags_list += [self.pad_tag_id] * (self.max_depth - len(xpath_tags_list))
+ xpath_subs_list += [self.pad_width] * (self.max_depth - len(xpath_subs_list))
+
+ return xpath_tags_list, xpath_subs_list
+
+ @add_end_docstrings(ENCODE_KWARGS_DOCSTRING, MARKUPLM_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
+ def __call__(
+ self,
+ text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]],
+ text_pair: Optional[Union[PreTokenizedInput, List[PreTokenizedInput]]] = None,
+ xpaths: Union[List[List[int]], List[List[List[int]]]] = None,
+ node_labels: Optional[Union[List[int], List[List[int]]]] = None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = False,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ **kwargs
+ ) -> BatchEncoding:
+ """
+ Main method to tokenize and prepare for the model one or several sequence(s) or one or several pair(s) of
+ sequences with nodes, xpaths and optional labels.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string, a list of strings
+ (words of a single example or questions of a batch of examples) or a list of list of strings (batch of
+ words).
+ text_pair (`List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence should be a list of strings
+ (pretokenized string).
+ xpaths (`List[List[int]]`, `List[List[List[int]]]`):
+ Node-level xpaths. Each bounding box should be normalized to be on a 0-1000 scale.
+ node_labels (`List[int]`, `List[List[int]]`, *optional*):
+ Node-level integer labels (for token classification tasks).
+ """
+ # Input type checking for clearer error
+ def _is_valid_text_input(t):
+ if isinstance(t, str):
+ # Strings are fine
+ return True
+ elif isinstance(t, (list, tuple)):
+ # List are fine as long as they are...
+ if len(t) == 0:
+ # ... empty
+ return True
+ elif isinstance(t[0], str):
+ # ... list of strings
+ return True
+ elif isinstance(t[0], (list, tuple)):
+ # ... list with an empty list or with a list of strings
+ return len(t[0]) == 0 or isinstance(t[0][0], str)
+ else:
+ return False
+ else:
+ return False
+
+ if text_pair is not None:
+ # in case text + text_pair are provided, text = questions, text_pair = nodes
+ if not _is_valid_text_input(text):
+ raise ValueError("text input must of type `str` (single example) or `List[str]` (batch of examples). ")
+ if not isinstance(text_pair, (list, tuple)):
+ raise ValueError(
+ "Nodes must be of type `List[str]` (single pretokenized example), "
+ "or `List[List[str]]` (batch of pretokenized examples)."
+ )
+ else:
+ # in case only text is provided => must be nodes
+ if not isinstance(text, (list, tuple)):
+ raise ValueError(
+ "Nodes must be of type `List[str]` (single pretokenized example), "
+ "or `List[List[str]]` (batch of pretokenized examples)."
+ )
+
+ if text_pair is not None:
+ is_batched = isinstance(text, (list, tuple))
+ else:
+ is_batched = isinstance(text, (list, tuple)) and text and isinstance(text[0], (list, tuple))
+
+ nodes = text if text_pair is None else text_pair
+ assert xpaths is not None, "You must provide corresponding xpaths"
+ if is_batched:
+ assert len(nodes) == len(xpaths), "You must provide nodes and xpaths for an equal amount of examples"
+ for nodes_example, xpaths_example in zip(nodes, xpaths):
+ assert len(nodes_example) == len(xpaths_example), "You must provide as many nodes as there are xpaths"
+ else:
+ assert len(nodes) == len(xpaths), "You must provide as many nodes as there are xpaths"
+
+ if is_batched:
+ if text_pair is not None and len(text) != len(text_pair):
+ raise ValueError(
+ f"batch length of `text`: {len(text)} does not match batch length of `text_pair`:"
+ f" {len(text_pair)}."
+ )
+ batch_text_or_text_pairs = list(zip(text, text_pair)) if text_pair is not None else text
+ is_pair = bool(text_pair is not None)
+ return self.batch_encode_plus(
+ batch_text_or_text_pairs=batch_text_or_text_pairs,
+ is_pair=is_pair,
+ xpaths=xpaths,
+ node_labels=node_labels,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_tensors=return_tensors,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ **kwargs,
+ )
+ else:
+ return self.encode_plus(
+ text=text,
+ text_pair=text_pair,
+ xpaths=xpaths,
+ node_labels=node_labels,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_tensors=return_tensors,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ @add_end_docstrings(ENCODE_KWARGS_DOCSTRING, MARKUPLM_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
+ def batch_encode_plus(
+ self,
+ batch_text_or_text_pairs: Union[
+ List[TextInput],
+ List[TextInputPair],
+ List[PreTokenizedInput],
+ ],
+ is_pair: bool = None,
+ xpaths: Optional[List[List[List[int]]]] = None,
+ node_labels: Optional[Union[List[int], List[List[int]]]] = None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = False,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ **kwargs
+ ) -> BatchEncoding:
+ # Backward compatibility for 'truncation_strategy', 'pad_to_max_length'
+ padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ pad_to_multiple_of=pad_to_multiple_of,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ return self._batch_encode_plus(
+ batch_text_or_text_pairs=batch_text_or_text_pairs,
+ is_pair=is_pair,
+ xpaths=xpaths,
+ node_labels=node_labels,
+ add_special_tokens=add_special_tokens,
+ padding_strategy=padding_strategy,
+ truncation_strategy=truncation_strategy,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_tensors=return_tensors,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ def tokenize(self, text: str, pair: Optional[str] = None, add_special_tokens: bool = False, **kwargs) -> List[str]:
+ batched_input = [(text, pair)] if pair else [text]
+ encodings = self._tokenizer.encode_batch(
+ batched_input, add_special_tokens=add_special_tokens, is_pretokenized=False, **kwargs
+ )
+
+ return encodings[0].tokens
+
+ @add_end_docstrings(ENCODE_KWARGS_DOCSTRING, MARKUPLM_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
+ def encode_plus(
+ self,
+ text: Union[TextInput, PreTokenizedInput],
+ text_pair: Optional[PreTokenizedInput] = None,
+ xpaths: Optional[List[List[int]]] = None,
+ node_labels: Optional[List[int]] = None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = False,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ **kwargs
+ ) -> BatchEncoding:
+ """
+ Tokenize and prepare for the model a sequence or a pair of sequences. .. warning:: This method is deprecated,
+ `__call__` should be used instead.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The first sequence to be encoded. This can be a string, a list of strings or a list of list of strings.
+ text_pair (`List[str]` or `List[int]`, *optional*):
+ Optional second sequence to be encoded. This can be a list of strings (words of a single example) or a
+ list of list of strings (words of a batch of examples).
+ """
+
+ # Backward compatibility for 'truncation_strategy', 'pad_to_max_length'
+ padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ pad_to_multiple_of=pad_to_multiple_of,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ return self._encode_plus(
+ text=text,
+ xpaths=xpaths,
+ text_pair=text_pair,
+ node_labels=node_labels,
+ add_special_tokens=add_special_tokens,
+ padding_strategy=padding_strategy,
+ truncation_strategy=truncation_strategy,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_tensors=return_tensors,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ def _batch_encode_plus(
+ self,
+ batch_text_or_text_pairs: Union[
+ List[TextInput],
+ List[TextInputPair],
+ List[PreTokenizedInput],
+ ],
+ is_pair: bool = None,
+ xpaths: Optional[List[List[List[int]]]] = None,
+ node_labels: Optional[List[List[int]]] = None,
+ add_special_tokens: bool = True,
+ padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
+ truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[str] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ ) -> BatchEncoding:
+ if not isinstance(batch_text_or_text_pairs, list):
+ raise TypeError(f"batch_text_or_text_pairs has to be a list (got {type(batch_text_or_text_pairs)})")
+
+ # Set the truncation and padding strategy and restore the initial configuration
+ self.set_truncation_and_padding(
+ padding_strategy=padding_strategy,
+ truncation_strategy=truncation_strategy,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ )
+
+ if is_pair:
+ batch_text_or_text_pairs = [([text], text_pair) for text, text_pair in batch_text_or_text_pairs]
+
+ encodings = self._tokenizer.encode_batch(
+ batch_text_or_text_pairs,
+ add_special_tokens=add_special_tokens,
+ is_pretokenized=True, # we set this to True as MarkupLM always expects pretokenized inputs
+ )
+
+ # Convert encoding to dict
+ # `Tokens` is a tuple of (List[Dict[str, List[List[int]]]] or List[Dict[str, 2D-Tensor]],
+ # List[EncodingFast]) with nested dimensions corresponding to batch, overflows, sequence length
+ tokens_and_encodings = [
+ self._convert_encoding(
+ encoding=encoding,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=True
+ if node_labels is not None
+ else return_offsets_mapping, # we use offsets to create the labels
+ return_length=return_length,
+ verbose=verbose,
+ )
+ for encoding in encodings
+ ]
+
+ # Convert the output to have dict[list] from list[dict] and remove the additional overflows dimension
+ # From (variable) shape (batch, overflows, sequence length) to ~ (batch * overflows, sequence length)
+ # (we say ~ because the number of overflow varies with the example in the batch)
+ #
+ # To match each overflowing sample with the original sample in the batch
+ # we add an overflow_to_sample_mapping array (see below)
+ sanitized_tokens = {}
+ for key in tokens_and_encodings[0][0].keys():
+ stack = [e for item, _ in tokens_and_encodings for e in item[key]]
+ sanitized_tokens[key] = stack
+ sanitized_encodings = [e for _, item in tokens_and_encodings for e in item]
+
+ # If returning overflowing tokens, we need to return a mapping
+ # from the batch idx to the original sample
+ if return_overflowing_tokens:
+ overflow_to_sample_mapping = []
+ for i, (toks, _) in enumerate(tokens_and_encodings):
+ overflow_to_sample_mapping += [i] * len(toks["input_ids"])
+ sanitized_tokens["overflow_to_sample_mapping"] = overflow_to_sample_mapping
+
+ for input_ids in sanitized_tokens["input_ids"]:
+ self._eventual_warn_about_too_long_sequence(input_ids, max_length, verbose)
+
+ # create the token-level xpaths tags and subscripts
+ xpath_tags_seq = []
+ xpath_subs_seq = []
+ for batch_index in range(len(sanitized_tokens["input_ids"])):
+ if return_overflowing_tokens:
+ original_index = sanitized_tokens["overflow_to_sample_mapping"][batch_index]
+ else:
+ original_index = batch_index
+ xpath_tags_seq_example = []
+ xpath_subs_seq_example = []
+ for id, sequence_id, word_id in zip(
+ sanitized_tokens["input_ids"][batch_index],
+ sanitized_encodings[batch_index].sequence_ids,
+ sanitized_encodings[batch_index].word_ids,
+ ):
+ if word_id is not None:
+ if is_pair and sequence_id == 0:
+ xpath_tags_seq_example.append(self.pad_xpath_tags_seq)
+ xpath_subs_seq_example.append(self.pad_xpath_subs_seq)
+ else:
+ xpath_tags_list, xpath_subs_list = self.get_xpath_seq(xpaths[original_index][word_id])
+ xpath_tags_seq_example.extend([xpath_tags_list])
+ xpath_subs_seq_example.extend([xpath_subs_list])
+ else:
+ if id in [self.cls_token_id, self.sep_token_id, self.pad_token_id]:
+ xpath_tags_seq_example.append(self.pad_xpath_tags_seq)
+ xpath_subs_seq_example.append(self.pad_xpath_subs_seq)
+ else:
+ raise ValueError("Id not recognized")
+ xpath_tags_seq.append(xpath_tags_seq_example)
+ xpath_subs_seq.append(xpath_subs_seq_example)
+
+ sanitized_tokens["xpath_tags_seq"] = xpath_tags_seq
+ sanitized_tokens["xpath_subs_seq"] = xpath_subs_seq
+
+ # optionally, create the labels
+ if node_labels is not None:
+ labels = []
+ for batch_index in range(len(sanitized_tokens["input_ids"])):
+ if return_overflowing_tokens:
+ original_index = sanitized_tokens["overflow_to_sample_mapping"][batch_index]
+ else:
+ original_index = batch_index
+ labels_example = []
+ for id, offset, word_id in zip(
+ sanitized_tokens["input_ids"][batch_index],
+ sanitized_tokens["offset_mapping"][batch_index],
+ sanitized_encodings[batch_index].word_ids,
+ ):
+ if word_id is not None:
+ if self.only_label_first_subword:
+ if offset[0] == 0:
+ # Use the real label id for the first token of the word, and padding ids for the remaining tokens
+ labels_example.append(node_labels[original_index][word_id])
+ else:
+ labels_example.append(self.pad_token_label)
+ else:
+ labels_example.append(node_labels[original_index][word_id])
+ else:
+ labels_example.append(self.pad_token_label)
+ labels.append(labels_example)
+
+ sanitized_tokens["labels"] = labels
+ # finally, remove offsets if the user didn't want them
+ if not return_offsets_mapping:
+ del sanitized_tokens["offset_mapping"]
+
+ return BatchEncoding(sanitized_tokens, sanitized_encodings, tensor_type=return_tensors)
+
+ def _encode_plus(
+ self,
+ text: Union[TextInput, PreTokenizedInput],
+ text_pair: Optional[PreTokenizedInput] = None,
+ xpaths: Optional[List[List[int]]] = None,
+ node_labels: Optional[List[int]] = None,
+ add_special_tokens: bool = True,
+ padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
+ truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_tensors: Optional[bool] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ **kwargs
+ ) -> BatchEncoding:
+ # make it a batched input
+ # 2 options:
+ # 1) only text, in case text must be a list of str
+ # 2) text + text_pair, in which case text = str and text_pair a list of str
+ batched_input = [(text, text_pair)] if text_pair else [text]
+ batched_xpaths = [xpaths]
+ batched_node_labels = [node_labels] if node_labels is not None else None
+ batched_output = self._batch_encode_plus(
+ batched_input,
+ is_pair=bool(text_pair is not None),
+ xpaths=batched_xpaths,
+ node_labels=batched_node_labels,
+ add_special_tokens=add_special_tokens,
+ padding_strategy=padding_strategy,
+ truncation_strategy=truncation_strategy,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_tensors=return_tensors,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ **kwargs,
+ )
+
+ # Return tensor is None, then we can remove the leading batch axis
+ # Overflowing tokens are returned as a batch of output so we keep them in this case
+ if return_tensors is None and not return_overflowing_tokens:
+ batched_output = BatchEncoding(
+ {
+ key: value[0] if len(value) > 0 and isinstance(value[0], list) else value
+ for key, value in batched_output.items()
+ },
+ batched_output.encodings,
+ )
+
+ self._eventual_warn_about_too_long_sequence(batched_output["input_ids"], max_length, verbose)
+
+ return batched_output
+
+ def _pad(
+ self,
+ encoded_inputs: Union[Dict[str, EncodedInput], BatchEncoding],
+ max_length: Optional[int] = None,
+ padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
+ pad_to_multiple_of: Optional[int] = None,
+ return_attention_mask: Optional[bool] = None,
+ ) -> dict:
+ """
+ Args:
+ Pad encoded inputs (on left/right and up to predefined length or max length in the batch)
+ encoded_inputs:
+ Dictionary of tokenized inputs (`List[int]`) or batch of tokenized inputs (`List[List[int]]`).
+ max_length: maximum length of the returned list and optionally padding length (see below).
+ Will truncate by taking into account the special tokens.
+ padding_strategy: PaddingStrategy to use for padding.
+ - PaddingStrategy.LONGEST Pad to the longest sequence in the batch
+ - PaddingStrategy.MAX_LENGTH: Pad to the max length (default)
+ - PaddingStrategy.DO_NOT_PAD: Do not pad
+ The tokenizer padding sides are defined in self.padding_side:
+ - 'left': pads on the left of the sequences
+ - 'right': pads on the right of the sequences
+ pad_to_multiple_of: (optional) Integer if set will pad the sequence to a multiple of the provided value.
+ This is especially useful to enable the use of Tensor Core on NVIDIA hardware with compute capability
+ >= 7.5 (Volta).
+ return_attention_mask:
+ (optional) Set to False to avoid returning attention mask (default: set to model specifics)
+ """
+ # Load from model defaults
+ if return_attention_mask is None:
+ return_attention_mask = "attention_mask" in self.model_input_names
+
+ required_input = encoded_inputs[self.model_input_names[0]]
+
+ if padding_strategy == PaddingStrategy.LONGEST:
+ max_length = len(required_input)
+
+ if max_length is not None and pad_to_multiple_of is not None and (max_length % pad_to_multiple_of != 0):
+ max_length = ((max_length // pad_to_multiple_of) + 1) * pad_to_multiple_of
+
+ needs_to_be_padded = padding_strategy != PaddingStrategy.DO_NOT_PAD and len(required_input) != max_length
+
+ # Initialize attention mask if not present.
+ if return_attention_mask and "attention_mask" not in encoded_inputs:
+ encoded_inputs["attention_mask"] = [1] * len(required_input)
+
+ if needs_to_be_padded:
+ difference = max_length - len(required_input)
+ if self.padding_side == "right":
+ if return_attention_mask:
+ encoded_inputs["attention_mask"] = encoded_inputs["attention_mask"] + [0] * difference
+ if "token_type_ids" in encoded_inputs:
+ encoded_inputs["token_type_ids"] = (
+ encoded_inputs["token_type_ids"] + [self.pad_token_type_id] * difference
+ )
+ if "xpath_tags_seq" in encoded_inputs:
+ encoded_inputs["xpath_tags_seq"] = (
+ encoded_inputs["xpath_tags_seq"] + [self.pad_xpath_tags_seq] * difference
+ )
+ if "xpath_subs_seq" in encoded_inputs:
+ encoded_inputs["xpath_subs_seq"] = (
+ encoded_inputs["xpath_subs_seq"] + [self.pad_xpath_subs_seq] * difference
+ )
+ if "labels" in encoded_inputs:
+ encoded_inputs["labels"] = encoded_inputs["labels"] + [self.pad_token_label] * difference
+ if "special_tokens_mask" in encoded_inputs:
+ encoded_inputs["special_tokens_mask"] = encoded_inputs["special_tokens_mask"] + [1] * difference
+ encoded_inputs[self.model_input_names[0]] = required_input + [self.pad_token_id] * difference
+ elif self.padding_side == "left":
+ if return_attention_mask:
+ encoded_inputs["attention_mask"] = [0] * difference + encoded_inputs["attention_mask"]
+ if "token_type_ids" in encoded_inputs:
+ encoded_inputs["token_type_ids"] = [self.pad_token_type_id] * difference + encoded_inputs[
+ "token_type_ids"
+ ]
+ if "xpath_tags_seq" in encoded_inputs:
+ encoded_inputs["xpath_tags_seq"] = [self.pad_xpath_tags_seq] * difference + encoded_inputs[
+ "xpath_tags_seq"
+ ]
+ if "xpath_subs_seq" in encoded_inputs:
+ encoded_inputs["xpath_subs_seq"] = [self.pad_xpath_subs_seq] * difference + encoded_inputs[
+ "xpath_subs_seq"
+ ]
+ if "labels" in encoded_inputs:
+ encoded_inputs["labels"] = [self.pad_token_label] * difference + encoded_inputs["labels"]
+ if "special_tokens_mask" in encoded_inputs:
+ encoded_inputs["special_tokens_mask"] = [1] * difference + encoded_inputs["special_tokens_mask"]
+ encoded_inputs[self.model_input_names[0]] = [self.pad_token_id] * difference + required_input
+ else:
+ raise ValueError("Invalid padding strategy:" + str(self.padding_side))
+
+ return encoded_inputs
+
+ def build_inputs_with_special_tokens(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
+ ) -> List[int]:
+ """
+ Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
+ adding special tokens. A RoBERTa sequence has the following format:
+ - single sequence: ` X `
+ - pair of sequences: ` A B `
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs to which the special tokens will be added.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+ Returns:
+ `List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
+ """
+ if token_ids_1 is None:
+ return [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
+ cls = [self.cls_token_id]
+ sep = [self.sep_token_id]
+ return cls + token_ids_0 + sep + token_ids_1 + sep
+
+ def create_token_type_ids_from_sequences(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
+ ) -> List[int]:
+ """
+ Create a mask from the two sequences passed to be used in a sequence-pair classification task. RoBERTa does not
+ make use of token type ids, therefore a list of zeros is returned.
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+ Returns:
+ `List[int]`: List of zeros.
+ """
+ sep = [self.sep_token_id]
+ cls = [self.cls_token_id]
+
+ if token_ids_1 is None:
+ return len(cls + token_ids_0 + sep) * [0]
+ return len(cls + token_ids_0 + sep + token_ids_1 + sep) * [0]
+
+ def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
+ files = self._tokenizer.model.save(save_directory, name=filename_prefix)
+ return tuple(files)
diff --git a/src/transformers/testing_utils.py b/src/transformers/testing_utils.py
index b14ed5d589c..65c15fbd967 100644
--- a/src/transformers/testing_utils.py
+++ b/src/transformers/testing_utils.py
@@ -46,6 +46,7 @@ from .utils import (
is_accelerate_available,
is_apex_available,
is_bitsandbytes_available,
+ is_bs4_available,
is_detectron2_available,
is_faiss_available,
is_flax_available,
@@ -239,6 +240,13 @@ def custom_tokenizers(test_case):
return unittest.skipUnless(_run_custom_tokenizers, "test of custom tokenizers")(test_case)
+def require_bs4(test_case):
+ """
+ Decorator marking a test that requires BeautifulSoup4. These tests are skipped when BeautifulSoup4 isn't installed.
+ """
+ return unittest.skipUnless(is_bs4_available(), "test requires BeautifulSoup4")(test_case)
+
+
def require_git_lfs(test_case):
"""
Decorator marking a test that requires git-lfs.
diff --git a/src/transformers/utils/__init__.py b/src/transformers/utils/__init__.py
index 9572a673f67..7f3f704ac4a 100644
--- a/src/transformers/utils/__init__.py
+++ b/src/transformers/utils/__init__.py
@@ -89,6 +89,7 @@ from .import_utils import (
is_accelerate_available,
is_apex_available,
is_bitsandbytes_available,
+ is_bs4_available,
is_coloredlogs_available,
is_datasets_available,
is_detectron2_available,
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index e9f1bae358f..d564c08e9fc 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -3020,6 +3020,44 @@ class MarianMTModel(metaclass=DummyObject):
requires_backends(self, ["torch"])
+MARKUPLM_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class MarkupLMForQuestionAnswering(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class MarkupLMForSequenceClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class MarkupLMForTokenClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class MarkupLMModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class MarkupLMPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
MASKFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_tokenizers_objects.py b/src/transformers/utils/dummy_tokenizers_objects.py
index 7a469bdff36..8a24d9bea6b 100644
--- a/src/transformers/utils/dummy_tokenizers_objects.py
+++ b/src/transformers/utils/dummy_tokenizers_objects.py
@@ -234,6 +234,13 @@ class LxmertTokenizerFast(metaclass=DummyObject):
requires_backends(self, ["tokenizers"])
+class MarkupLMTokenizerFast(metaclass=DummyObject):
+ _backends = ["tokenizers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["tokenizers"])
+
+
class MBartTokenizerFast(metaclass=DummyObject):
_backends = ["tokenizers"]
diff --git a/src/transformers/utils/import_utils.py b/src/transformers/utils/import_utils.py
index f2cf5ffd9bf..16616e0772d 100644
--- a/src/transformers/utils/import_utils.py
+++ b/src/transformers/utils/import_utils.py
@@ -386,6 +386,10 @@ def is_torch_fx_available():
return _torch_fx_available
+def is_bs4_available():
+ return importlib.util.find_spec("bs4") is not None
+
+
def is_torch_onnx_dict_inputs_support_available():
return _torch_onnx_dict_inputs_support_available
@@ -748,6 +752,12 @@ If you really do want to use TensorFlow, please follow the instructions on the
installation page https://www.tensorflow.org/install that match your environment.
"""
+# docstyle-ignore
+BS4_IMPORT_ERROR = """
+{0} requires the Beautiful Soup library but it was not found in your environment. You can install it with pip:
+`pip install beautifulsoup4`
+"""
+
# docstyle-ignore
SKLEARN_IMPORT_ERROR = """
@@ -889,6 +899,7 @@ CCL_IMPORT_ERROR = """
BACKENDS_MAPPING = OrderedDict(
[
+ ("bs4", (is_bs4_available, BS4_IMPORT_ERROR)),
("datasets", (is_datasets_available, DATASETS_IMPORT_ERROR)),
("detectron2", (is_detectron2_available, DETECTRON2_IMPORT_ERROR)),
("faiss", (is_faiss_available, FAISS_IMPORT_ERROR)),
diff --git a/tests/models/markuplm/__init__.py b/tests/models/markuplm/__init__.py
new file mode 100644
index 00000000000..e69de29bb2d
diff --git a/tests/models/markuplm/test_feature_extraction_markuplm.py b/tests/models/markuplm/test_feature_extraction_markuplm.py
new file mode 100644
index 00000000000..4541cb9480b
--- /dev/null
+++ b/tests/models/markuplm/test_feature_extraction_markuplm.py
@@ -0,0 +1,114 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers.testing_utils import require_bs4
+from transformers.utils import is_bs4_available
+
+from ...test_feature_extraction_common import FeatureExtractionSavingTestMixin
+
+
+if is_bs4_available():
+ from transformers import MarkupLMFeatureExtractor
+
+
+class MarkupLMFeatureExtractionTester(unittest.TestCase):
+ def __init__(self, parent):
+ self.parent = parent
+
+ def prepare_feat_extract_dict(self):
+ return {}
+
+
+def get_html_strings():
+ html_string_1 = """
+
+
+ sample document
+
+
+
+
+ Goog
+ This is one header
+ This is a another Header
+ Travel from
+
+ SFO to JFK
+
+ on May 2, 2015 at 2:00 pm. For details go to confirm.com
+
+
+
Traveler name is
+
John Doe
+
My First Heading
+ My first paragraph.
+
+
+
+ """
+
+ return [html_string_1, html_string_2]
+
+
+@require_bs4
+class MarkupLMFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+ feature_extraction_class = MarkupLMFeatureExtractor if is_bs4_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = MarkupLMFeatureExtractionTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_call(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class()
+
+ # Test not batched input
+ html_string = get_html_strings()[0]
+ encoding = feature_extractor(html_string)
+
+ # fmt: off
+ expected_nodes = [['sample document', 'Goog', 'This is one header', 'This is a another Header', 'Travel from', 'SFO to JFK', 'on May 2, 2015 at 2:00 pm. For details go to confirm.com', 'Traveler', 'name', 'is', 'John Doe']]
+ expected_xpaths = [['/html/head/title', '/html/body/a', '/html/body/h1', '/html/body/h2', '/html/body/p', '/html/body/p/p/b[1]', '/html/body/p/p/b[2]/i', '/html/body/p/p/div/h3', '/html/body/p/p/div/h3/b', '/html/body/p/p/div/h3', '/html/body/p/p/div/h3/p']]
+ # fmt: on
+
+ self.assertEqual(encoding.nodes, expected_nodes)
+ self.assertEqual(encoding.xpaths, expected_xpaths)
+
+ # Test batched
+ html_strings = get_html_strings()
+ encoding = feature_extractor(html_strings)
+
+ # fmt: off
+ expected_nodes = expected_nodes + [['My First Heading', 'My first paragraph.']]
+ expected_xpaths = expected_xpaths + [['/html/body/h1', '/html/body/p']]
+
+ self.assertEqual(len(encoding.nodes), 2)
+ self.assertEqual(len(encoding.xpaths), 2)
+
+ self.assertEqual(encoding.nodes, expected_nodes)
+ self.assertEqual(encoding.xpaths, expected_xpaths)
diff --git a/tests/models/markuplm/test_modeling_markuplm.py b/tests/models/markuplm/test_modeling_markuplm.py
new file mode 100644
index 00000000000..8fa1bb440a5
--- /dev/null
+++ b/tests/models/markuplm/test_modeling_markuplm.py
@@ -0,0 +1,364 @@
+# coding=utf-8
+# Copyright 2022 The Hugging Face Team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers import MarkupLMConfig, is_torch_available
+from transformers.testing_utils import require_torch, slow, torch_device
+from transformers.utils import cached_property
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ MarkupLMForQuestionAnswering,
+ MarkupLMForSequenceClassification,
+ MarkupLMForTokenClassification,
+ MarkupLMModel,
+ )
+
+# TODO check dependencies
+from transformers import MarkupLMFeatureExtractor, MarkupLMProcessor, MarkupLMTokenizer
+
+
+class MarkupLMModelTester:
+ """You can also import this e.g from .test_modeling_markuplm import MarkupLMModelTester"""
+
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ scope=None,
+ max_xpath_tag_unit_embeddings=20,
+ max_xpath_subs_unit_embeddings=30,
+ tag_pad_id=2,
+ subs_pad_id=2,
+ max_depth=10,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.scope = scope
+ self.max_xpath_tag_unit_embeddings = max_xpath_tag_unit_embeddings
+ self.max_xpath_subs_unit_embeddings = max_xpath_subs_unit_embeddings
+ self.tag_pad_id = tag_pad_id
+ self.subs_pad_id = subs_pad_id
+ self.max_depth = max_depth
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ xpath_tags_seq = ids_tensor(
+ [self.batch_size, self.seq_length, self.max_depth], self.max_xpath_tag_unit_embeddings
+ )
+
+ xpath_subs_seq = ids_tensor(
+ [self.batch_size, self.seq_length, self.max_depth], self.max_xpath_subs_unit_embeddings
+ )
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+
+ config = self.get_config()
+
+ return (
+ config,
+ input_ids,
+ xpath_tags_seq,
+ xpath_subs_seq,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ )
+
+ def get_config(self):
+ return MarkupLMConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ initializer_range=self.initializer_range,
+ max_xpath_tag_unit_embeddings=self.max_xpath_tag_unit_embeddings,
+ max_xpath_subs_unit_embeddings=self.max_xpath_subs_unit_embeddings,
+ tag_pad_id=self.tag_pad_id,
+ subs_pad_id=self.subs_pad_id,
+ max_depth=self.max_depth,
+ )
+
+ def create_and_check_model(
+ self,
+ config,
+ input_ids,
+ xpath_tags_seq,
+ xpath_subs_seq,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ ):
+ model = MarkupLMModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ print("Configs:", model.config.tag_pad_id, model.config.subs_pad_id)
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ result = model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def create_and_check_for_sequence_classification(
+ self,
+ config,
+ input_ids,
+ xpath_tags_seq,
+ xpath_subs_seq,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ ):
+ config.num_labels = self.num_labels
+ model = MarkupLMForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ xpath_tags_seq=xpath_tags_seq,
+ xpath_subs_seq=xpath_subs_seq,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ labels=sequence_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_for_token_classification(
+ self,
+ config,
+ input_ids,
+ xpath_tags_seq,
+ xpath_subs_seq,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ ):
+ config.num_labels = self.num_labels
+ model = MarkupLMForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ xpath_tags_seq=xpath_tags_seq,
+ xpath_subs_seq=xpath_subs_seq,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ labels=token_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_for_question_answering(
+ self,
+ config,
+ input_ids,
+ xpath_tags_seq,
+ xpath_subs_seq,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ ):
+ model = MarkupLMForQuestionAnswering(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ xpath_tags_seq=xpath_tags_seq,
+ xpath_subs_seq=xpath_subs_seq,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ )
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ xpath_tags_seq,
+ xpath_subs_seq,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ ) = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "xpath_tags_seq": xpath_tags_seq,
+ "xpath_subs_seq": xpath_subs_seq,
+ "token_type_ids": token_type_ids,
+ "attention_mask": input_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class MarkupLMModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ MarkupLMModel,
+ MarkupLMForSequenceClassification,
+ MarkupLMForTokenClassification,
+ MarkupLMForQuestionAnswering,
+ )
+ if is_torch_available()
+ else None
+ )
+
+ def setUp(self):
+ self.model_tester = MarkupLMModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=MarkupLMConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_sequence_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
+
+ def test_for_question_answering(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
+
+
+def prepare_html_string():
+ html_string = """
+
+
+
+ Page Title
+
+
+
+ This is a Heading
+ This is a paragraph.
+
+
+
+ """
+
+ return html_string
+
+
+@require_torch
+class MarkupLMModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_processor(self):
+ # TODO use from_pretrained here
+ feature_extractor = MarkupLMFeatureExtractor()
+ tokenizer = MarkupLMTokenizer.from_pretrained("microsoft/markuplm-base")
+
+ return MarkupLMProcessor(feature_extractor, tokenizer)
+
+ @slow
+ def test_forward_pass_no_head(self):
+ model = MarkupLMModel.from_pretrained("microsoft/markuplm-base").to(torch_device)
+
+ processor = self.default_processor
+
+ inputs = processor(prepare_html_string(), return_tensors="pt")
+ inputs = inputs.to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the last hidden states
+ expected_shape = torch.Size([1, 14, 768])
+ self.assertEqual(outputs.last_hidden_state.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[0.0267, -0.1289, 0.4930], [-0.2376, -0.0342, 0.2381], [-0.0329, -0.3785, 0.0263]]
+ ).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.last_hidden_state[0, :3, :3], expected_slice, atol=1e-4))
diff --git a/tests/models/markuplm/test_processor_markuplm.py b/tests/models/markuplm/test_processor_markuplm.py
new file mode 100644
index 00000000000..6870a63336a
--- /dev/null
+++ b/tests/models/markuplm/test_processor_markuplm.py
@@ -0,0 +1,451 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import tempfile
+import unittest
+from typing import List
+
+from transformers import (
+ MarkupLMProcessor,
+ MarkupLMTokenizer,
+ PreTrainedTokenizer,
+ PreTrainedTokenizerBase,
+ PreTrainedTokenizerFast,
+)
+from transformers.models.markuplm.tokenization_markuplm import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_bs4, require_tokenizers, require_torch, slow
+from transformers.utils import FEATURE_EXTRACTOR_NAME, cached_property, is_bs4_available, is_tokenizers_available
+
+
+if is_bs4_available():
+ from transformers import MarkupLMFeatureExtractor
+
+if is_tokenizers_available():
+ from transformers import MarkupLMTokenizerFast
+
+
+@require_bs4
+@require_tokenizers
+class MarkupLMProcessorTest(unittest.TestCase):
+ tokenizer_class = MarkupLMTokenizer
+ rust_tokenizer_class = MarkupLMTokenizerFast
+
+ def setUp(self):
+ # Adapted from Sennrich et al. 2015 and https://github.com/rsennrich/subword-nmt
+ # fmt: off
+ vocab = ["l", "o", "w", "e", "r", "s", "t", "i", "d", "n", "\u0120", "\u0120l", "\u0120n", "\u0120lo", "\u0120low", "er", "\u0120lowest", "\u0120newer", "\u0120wider", "\u0120hello", "\u0120world", "",] # noqa
+ # fmt: on
+ self.tmpdirname = tempfile.mkdtemp()
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["#version: 0.2", "\u0120 l", "\u0120l o", "\u0120lo w", "e r", ""]
+ self.tags_dict = {"a": 0, "abbr": 1, "acronym": 2, "address": 3}
+ self.special_tokens_map = {"unk_token": ""}
+
+ self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ self.merges_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ self.tokenizer_config_file = os.path.join(self.tmpdirname, "tokenizer_config.json")
+
+ with open(self.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(self.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+ with open(self.tokenizer_config_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps({"tags_dict": self.tags_dict}))
+
+ feature_extractor_map = {"feature_extractor_type": "MarkupLMFeatureExtractor"}
+ self.feature_extraction_file = os.path.join(self.tmpdirname, FEATURE_EXTRACTOR_NAME)
+ with open(self.feature_extraction_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(feature_extractor_map) + "\n")
+
+ def get_tokenizer(self, **kwargs) -> PreTrainedTokenizer:
+ return self.tokenizer_class.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_rust_tokenizer(self, **kwargs) -> PreTrainedTokenizerFast:
+ return self.rust_tokenizer_class.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_tokenizers(self, **kwargs) -> List[PreTrainedTokenizerBase]:
+ return [self.get_tokenizer(**kwargs), self.get_rust_tokenizer(**kwargs)]
+
+ def get_feature_extractor(self, **kwargs):
+ return MarkupLMFeatureExtractor.from_pretrained(self.tmpdirname, **kwargs)
+
+ def tearDown(self):
+ shutil.rmtree(self.tmpdirname)
+
+ def test_save_load_pretrained_default(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizers = self.get_tokenizers()
+ for tokenizer in tokenizers:
+ processor = MarkupLMProcessor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+
+ processor.save_pretrained(self.tmpdirname)
+ processor = MarkupLMProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer.get_vocab())
+ self.assertIsInstance(processor.tokenizer, (MarkupLMTokenizer, MarkupLMTokenizerFast))
+
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor.to_json_string())
+ self.assertIsInstance(processor.feature_extractor, MarkupLMFeatureExtractor)
+
+ def test_save_load_pretrained_additional_features(self):
+ processor = MarkupLMProcessor(feature_extractor=self.get_feature_extractor(), tokenizer=self.get_tokenizer())
+ processor.save_pretrained(self.tmpdirname)
+
+ # slow tokenizer
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ feature_extractor_add_kwargs = self.get_feature_extractor(do_resize=False, size=30)
+
+ processor = MarkupLMProcessor.from_pretrained(
+ self.tmpdirname, use_fast=False, bos_token="(BOS)", eos_token="(EOS)", do_resize=False, size=30
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, MarkupLMTokenizer)
+
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.feature_extractor, MarkupLMFeatureExtractor)
+
+ # fast tokenizer
+ tokenizer_add_kwargs = self.get_rust_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ feature_extractor_add_kwargs = self.get_feature_extractor(do_resize=False, size=30)
+
+ processor = MarkupLMProcessor.from_pretrained(
+ self.tmpdirname, bos_token="(BOS)", eos_token="(EOS)", do_resize=False, size=30
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, MarkupLMTokenizerFast)
+
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.feature_extractor, MarkupLMFeatureExtractor)
+
+
+# different use cases tests
+@require_bs4
+@require_torch
+class MarkupLMProcessorIntegrationTests(unittest.TestCase):
+ @cached_property
+ def get_html_strings(self):
+ html_string_1 = """
+
+
+
+ Hello world
+
+
+
+ Welcome
+ Here is my website.
+
+
+ """
+
+ html_string_2 = """
+
+
+
+
+ HTML Images
+ HTML images are defined with the img tag:
+
+  +
+
+
+ """
+
+ return [html_string_1, html_string_2]
+
+ @cached_property
+ def get_tokenizers(self):
+ slow_tokenizer = MarkupLMTokenizer.from_pretrained("microsoft/markuplm-base")
+ fast_tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base", from_slow=True)
+ return [slow_tokenizer, fast_tokenizer]
+
+ @slow
+ def test_processor_case_1(self):
+ # case 1: web page classification (training, inference) + token classification (inference)
+
+ feature_extractor = MarkupLMFeatureExtractor()
+ tokenizers = self.get_tokenizers
+ html_strings = self.get_html_strings
+
+ for tokenizer in tokenizers:
+ processor = MarkupLMProcessor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+
+ # not batched
+ inputs = processor(html_strings[0], return_tensors="pt")
+
+ # verify keys
+ expected_keys = ["attention_mask", "input_ids", "token_type_ids", "xpath_subs_seq", "xpath_tags_seq"]
+ actual_keys = sorted(list(inputs.keys()))
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify input_ids
+ expected = [0, 31414, 232, 25194, 11773, 16, 127, 998, 4, 2]
+ self.assertSequenceEqual(inputs.input_ids.squeeze().tolist(), expected)
+
+ # batched
+ inputs = processor(html_strings, padding=True, return_tensors="pt")
+
+ # verify keys
+ expected_keys = ["attention_mask", "input_ids", "token_type_ids", "xpath_subs_seq", "xpath_tags_seq"]
+ actual_keys = sorted(list(inputs.keys()))
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify input_ids
+ expected = [0, 48085, 2209, 48085, 3156, 32, 6533, 19, 5, 48599, 6694, 35, 2]
+ self.assertSequenceEqual(inputs.input_ids[1].tolist(), expected)
+
+ @slow
+ def test_processor_case_2(self):
+ # case 2: web page classification (training, inference) + token classification (inference), parse_html=False
+
+ feature_extractor = MarkupLMFeatureExtractor()
+ tokenizers = self.get_tokenizers
+
+ for tokenizer in tokenizers:
+ processor = MarkupLMProcessor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+ processor.parse_html = False
+
+ # not batched
+ nodes = ["hello", "world", "how", "are"]
+ xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
+ inputs = processor(nodes=nodes, xpaths=xpaths, return_tensors="pt")
+
+ # verify keys
+ expected_keys = ["attention_mask", "input_ids", "token_type_ids", "xpath_subs_seq", "xpath_tags_seq"]
+ actual_keys = list(inputs.keys())
+ for key in expected_keys:
+ self.assertIn(key, actual_keys)
+
+ # verify input_ids
+ expected_decoding = "
+
+
+
+ """
+
+ return [html_string_1, html_string_2]
+
+ @cached_property
+ def get_tokenizers(self):
+ slow_tokenizer = MarkupLMTokenizer.from_pretrained("microsoft/markuplm-base")
+ fast_tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base", from_slow=True)
+ return [slow_tokenizer, fast_tokenizer]
+
+ @slow
+ def test_processor_case_1(self):
+ # case 1: web page classification (training, inference) + token classification (inference)
+
+ feature_extractor = MarkupLMFeatureExtractor()
+ tokenizers = self.get_tokenizers
+ html_strings = self.get_html_strings
+
+ for tokenizer in tokenizers:
+ processor = MarkupLMProcessor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+
+ # not batched
+ inputs = processor(html_strings[0], return_tensors="pt")
+
+ # verify keys
+ expected_keys = ["attention_mask", "input_ids", "token_type_ids", "xpath_subs_seq", "xpath_tags_seq"]
+ actual_keys = sorted(list(inputs.keys()))
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify input_ids
+ expected = [0, 31414, 232, 25194, 11773, 16, 127, 998, 4, 2]
+ self.assertSequenceEqual(inputs.input_ids.squeeze().tolist(), expected)
+
+ # batched
+ inputs = processor(html_strings, padding=True, return_tensors="pt")
+
+ # verify keys
+ expected_keys = ["attention_mask", "input_ids", "token_type_ids", "xpath_subs_seq", "xpath_tags_seq"]
+ actual_keys = sorted(list(inputs.keys()))
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify input_ids
+ expected = [0, 48085, 2209, 48085, 3156, 32, 6533, 19, 5, 48599, 6694, 35, 2]
+ self.assertSequenceEqual(inputs.input_ids[1].tolist(), expected)
+
+ @slow
+ def test_processor_case_2(self):
+ # case 2: web page classification (training, inference) + token classification (inference), parse_html=False
+
+ feature_extractor = MarkupLMFeatureExtractor()
+ tokenizers = self.get_tokenizers
+
+ for tokenizer in tokenizers:
+ processor = MarkupLMProcessor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+ processor.parse_html = False
+
+ # not batched
+ nodes = ["hello", "world", "how", "are"]
+ xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
+ inputs = processor(nodes=nodes, xpaths=xpaths, return_tensors="pt")
+
+ # verify keys
+ expected_keys = ["attention_mask", "input_ids", "token_type_ids", "xpath_subs_seq", "xpath_tags_seq"]
+ actual_keys = list(inputs.keys())
+ for key in expected_keys:
+ self.assertIn(key, actual_keys)
+
+ # verify input_ids
+ expected_decoding = "helloworldhoware"
+ decoding = processor.decode(inputs.input_ids.squeeze().tolist())
+ self.assertSequenceEqual(decoding, expected_decoding)
+
+ # batched
+ nodes = [["hello", "world"], ["my", "name", "is"]]
+ xpaths = [
+ ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span"],
+ ["html/body", "html/body/div", "html/body"],
+ ]
+ inputs = processor(nodes=nodes, xpaths=xpaths, padding=True, return_tensors="pt")
+
+ # verify keys
+ expected_keys = ["attention_mask", "input_ids", "token_type_ids", "xpath_subs_seq", "xpath_tags_seq"]
+ actual_keys = sorted(list(inputs.keys()))
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify input_ids
+ expected_decoding = "helloworld"
+ decoding = processor.decode(inputs.input_ids[0].tolist())
+ self.assertSequenceEqual(decoding, expected_decoding)
+
+ @slow
+ def test_processor_case_3(self):
+ # case 3: token classification (training), parse_html=False
+
+ feature_extractor = MarkupLMFeatureExtractor()
+ tokenizers = self.get_tokenizers
+
+ for tokenizer in tokenizers:
+ processor = MarkupLMProcessor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+ processor.parse_html = False
+
+ # not batched
+ nodes = ["hello", "world", "how", "are"]
+ xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
+ node_labels = [1, 2, 2, 1]
+ inputs = processor(nodes=nodes, xpaths=xpaths, node_labels=node_labels, return_tensors="pt")
+
+ # verify keys
+ expected_keys = [
+ "attention_mask",
+ "input_ids",
+ "labels",
+ "token_type_ids",
+ "xpath_subs_seq",
+ "xpath_tags_seq",
+ ]
+ actual_keys = sorted(list(inputs.keys()))
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify input_ids
+ expected_ids = [0, 42891, 8331, 9178, 1322, 2]
+ self.assertSequenceEqual(inputs.input_ids[0].tolist(), expected_ids)
+
+ # verify labels
+ expected_labels = [-100, 1, 2, 2, 1, -100]
+ self.assertListEqual(inputs.labels.squeeze().tolist(), expected_labels)
+
+ # batched
+ nodes = [["hello", "world"], ["my", "name", "is"]]
+ xpaths = [
+ ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span"],
+ ["html/body", "html/body/div", "html/body"],
+ ]
+ node_labels = [[1, 2], [6, 3, 10]]
+ inputs = processor(
+ nodes=nodes,
+ xpaths=xpaths,
+ node_labels=node_labels,
+ padding="max_length",
+ max_length=20,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ # verify keys
+ expected_keys = [
+ "attention_mask",
+ "input_ids",
+ "labels",
+ "token_type_ids",
+ "xpath_subs_seq",
+ "xpath_tags_seq",
+ ]
+ actual_keys = sorted(list(inputs.keys()))
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify input_ids
+ expected_ids = [0, 4783, 13650, 354, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
+ self.assertSequenceEqual(inputs.input_ids[1].tolist(), expected_ids)
+
+ # verify xpath_tags_seq
+ # fmt: off
+ expected_xpaths_tags_seq = [[216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216]] # noqa:
+ # fmt: on
+ self.assertSequenceEqual(inputs.xpath_tags_seq[1].tolist(), expected_xpaths_tags_seq)
+
+ # verify labels
+ # fmt: off
+ expected_labels = [-100, 6, 3, 10, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100]
+ # fmt: on
+ self.assertListEqual(inputs.labels[1].tolist(), expected_labels)
+
+ @slow
+ def test_processor_case_4(self):
+ # case 4: question answering (inference), parse_html=True
+
+ feature_extractor = MarkupLMFeatureExtractor()
+ tokenizers = self.get_tokenizers
+ html_strings = self.get_html_strings
+
+ for tokenizer in tokenizers:
+ processor = MarkupLMProcessor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+
+ # not batched
+ question = "What's his name?"
+ inputs = processor(html_strings[0], questions=question, return_tensors="pt")
+
+ # verify keys
+ expected_keys = ["attention_mask", "input_ids", "token_type_ids", "xpath_subs_seq", "xpath_tags_seq"]
+ actual_keys = sorted(list(inputs.keys()))
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify input_ids
+ # fmt: off
+ expected_decoding = "What's his name?Hello worldWelcomeHere is my website." # noqa: E231
+ # fmt: on
+ decoding = processor.decode(inputs.input_ids.squeeze().tolist())
+ self.assertSequenceEqual(decoding, expected_decoding)
+
+ # batched
+ questions = ["How old is he?", "what's the time"]
+ inputs = processor(
+ html_strings,
+ questions=questions,
+ padding="max_length",
+ max_length=20,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ # verify keys
+ expected_keys = ["attention_mask", "input_ids", "token_type_ids", "xpath_subs_seq", "xpath_tags_seq"]
+ actual_keys = sorted(list(inputs.keys()))
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify input_ids
+ expected_decoding = (
+ "what's the timeHTML ImagesHTML images are defined with the img tag:"
+ )
+ decoding = processor.decode(inputs.input_ids[1].tolist())
+ self.assertSequenceEqual(decoding, expected_decoding)
+
+ # verify xpath_subs_seq
+ # fmt: off
+ expected_xpath_subs_seq = [[1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 99, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 99, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 148, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 148, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 148, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 148, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 148, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 148, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 148, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 148, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 148, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001]] # noqa: E231
+ # fmt: on
+ self.assertListEqual(inputs.xpath_subs_seq[1].tolist(), expected_xpath_subs_seq)
+
+ @slow
+ def test_processor_case_5(self):
+ # case 5: question answering (inference), parse_html=False
+
+ feature_extractor = MarkupLMFeatureExtractor(parse_html=False)
+ tokenizers = self.get_tokenizers
+
+ for tokenizer in tokenizers:
+ processor = MarkupLMProcessor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+ processor.parse_html = False
+
+ # not batched
+ question = "What's his name?"
+ nodes = ["hello", "world", "how", "are"]
+ xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
+ inputs = processor(nodes=nodes, xpaths=xpaths, questions=question, return_tensors="pt")
+
+ # verify keys
+ expected_keys = ["attention_mask", "input_ids", "token_type_ids", "xpath_subs_seq", "xpath_tags_seq"]
+ actual_keys = sorted(list(inputs.keys()))
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify input_ids
+ expected_decoding = "What's his name?helloworldhoware"
+ decoding = processor.decode(inputs.input_ids.squeeze().tolist())
+ self.assertSequenceEqual(decoding, expected_decoding)
+
+ # batched
+ questions = ["How old is he?", "what's the time"]
+ nodes = [["hello", "world"], ["my", "name", "is"]]
+ xpaths = [
+ ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span"],
+ ["html/body", "html/body/div", "html/body"],
+ ]
+ inputs = processor(nodes=nodes, xpaths=xpaths, questions=questions, padding=True, return_tensors="pt")
+
+ # verify keys
+ expected_keys = ["attention_mask", "input_ids", "token_type_ids", "xpath_subs_seq", "xpath_tags_seq"]
+ actual_keys = sorted(list(inputs.keys()))
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify input_ids
+ expected_decoding = "How old is he?helloworld"
+ decoding = processor.decode(inputs.input_ids[0].tolist())
+ self.assertSequenceEqual(decoding, expected_decoding)
+
+ expected_decoding = "what's the timemynameis"
+ decoding = processor.decode(inputs.input_ids[1].tolist())
+ self.assertSequenceEqual(decoding, expected_decoding)
+
+ # verify xpath_subs_seq
+ # fmt: off
+ expected_xpath_subs_seq = [[1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001]] # noqa: E231
+ # fmt: on
+ self.assertListEqual(inputs.xpath_subs_seq[1].tolist()[-5:], expected_xpath_subs_seq)
diff --git a/tests/models/markuplm/test_tokenization_markuplm.py b/tests/models/markuplm/test_tokenization_markuplm.py
new file mode 100644
index 00000000000..e59934e4d08
--- /dev/null
+++ b/tests/models/markuplm/test_tokenization_markuplm.py
@@ -0,0 +1,2306 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+import json
+import os
+import re
+import shutil
+import tempfile
+import unittest
+from typing import List
+
+from transformers import (
+ AddedToken,
+ MarkupLMTokenizerFast,
+ SpecialTokensMixin,
+ is_tf_available,
+ is_torch_available,
+ logging,
+)
+from transformers.models.markuplm.tokenization_markuplm import VOCAB_FILES_NAMES, MarkupLMTokenizer
+from transformers.testing_utils import is_pt_tf_cross_test, require_tokenizers, require_torch, slow
+
+from ...test_tokenization_common import SMALL_TRAINING_CORPUS, TokenizerTesterMixin, merge_model_tokenizer_mappings
+
+
+logger = logging.get_logger(__name__)
+
+
+@require_tokenizers
+class MarkupLMTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ tokenizer_class = MarkupLMTokenizer
+ rust_tokenizer_class = MarkupLMTokenizerFast
+ test_rust_tokenizer = True
+ from_pretrained_kwargs = {"cls_token": ""}
+ test_seq2seq = False
+
+ def setUp(self):
+ super().setUp()
+
+ # Adapted from Sennrich et al. 2015 and https://github.com/rsennrich/subword-nmt
+ # fmt: off
+ vocab = ["l", "o", "w", "e", "r", "s", "t", "i", "d", "n", "\u0120", "\u0120l", "\u0120n", "\u0120lo", "\u0120low", "er", "\u0120lowest", "\u0120newer", "\u0120wider", "\u0120hello", "\u0120world", "",] # noqa
+ # fmt: on
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["#version: 0.2", "\u0120 l", "\u0120l o", "\u0120lo w", "e r", ""]
+ self.tags_dict = {"a": 0, "abbr": 1, "acronym": 2, "address": 3}
+ self.special_tokens_map = {"unk_token": ""}
+
+ self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ self.merges_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ self.tokenizer_config_file = os.path.join(self.tmpdirname, "tokenizer_config.json")
+
+ with open(self.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(self.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+ with open(self.tokenizer_config_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps({"tags_dict": self.tags_dict}))
+
+ def get_nodes_and_xpaths(self):
+ nodes = ["hello", "world"]
+ xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span"]
+
+ return nodes, xpaths
+
+ def get_nodes_and_xpaths_batch(self):
+ nodes = [["hello world", "running"], ["hello my name is bob"]]
+ xpaths = [
+ ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span"],
+ ["/html/body/div/li[2]/div/span"],
+ ]
+
+ return nodes, xpaths
+
+ def get_question_nodes_and_xpaths(self):
+ question = "what's his name?"
+ nodes = ["hello world"]
+ xpaths = ["/html/body/div/li[1]/div/span"] # , "/html/body/div/li[1]/div/span"]
+
+ return question, nodes, xpaths
+
+ def get_question_nodes_and_xpaths_batch(self):
+ questions = ["what's his name?", "how is he called?"]
+ nodes = [["hello world", "running"], ["hello my name is bob"]]
+ xpaths = [
+ ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span"],
+ ["/html/body/div/li[2]/div/span"],
+ ]
+
+ return questions, nodes, xpaths
+
+ def get_input_output_texts(self, tokenizer):
+ input_text = "UNwant\u00E9d,running"
+ output_text = "unwanted, running"
+ return input_text, output_text
+
+ def test_add_special_tokens(self):
+ tokenizers: List[MarkupLMTokenizer] = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ special_token = "[SPECIAL_TOKEN]"
+ special_token_xpath = "/html/body/div/li[1]/div/span"
+
+ tokenizer.add_special_tokens({"cls_token": special_token})
+ encoded_special_token = tokenizer.encode(
+ [special_token], xpaths=[special_token_xpath], add_special_tokens=False
+ )
+ self.assertEqual(len(encoded_special_token), 1)
+
+ decoded = tokenizer.decode(encoded_special_token, skip_special_tokens=True)
+ self.assertTrue(special_token not in decoded)
+
+ def test_add_tokens_tokenizer(self):
+ tokenizers: List[MarkupLMTokenizer] = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ vocab_size = tokenizer.vocab_size
+ all_size = len(tokenizer)
+
+ self.assertNotEqual(vocab_size, 0)
+
+ # We usually have added tokens from the start in tests because our vocab fixtures are
+ # smaller than the original vocabs - let's not assert this
+ # self.assertEqual(vocab_size, all_size)
+
+ new_toks = ["aaaaa", "bbbbbb", "cccccccccdddddddd"]
+ added_toks = tokenizer.add_tokens(new_toks)
+ vocab_size_2 = tokenizer.vocab_size
+ all_size_2 = len(tokenizer)
+
+ self.assertNotEqual(vocab_size_2, 0)
+ self.assertEqual(vocab_size, vocab_size_2)
+ self.assertEqual(added_toks, len(new_toks))
+ self.assertEqual(all_size_2, all_size + len(new_toks))
+
+ nodes = "aaaaa bbbbbb low cccccccccdddddddd l".split()
+ xpaths = ["/html/body/div/li[1]/div/span" for _ in range(len(nodes))]
+
+ tokens = tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+
+ self.assertGreaterEqual(len(tokens), 4)
+ self.assertGreater(tokens[0], tokenizer.vocab_size - 1)
+ self.assertGreater(tokens[-2], tokenizer.vocab_size - 1)
+
+ new_toks_2 = {"eos_token": ">>>>|||<||<<|<<", "pad_token": "<<<<<|||>|>>>>|>"}
+ added_toks_2 = tokenizer.add_special_tokens(new_toks_2)
+ vocab_size_3 = tokenizer.vocab_size
+ all_size_3 = len(tokenizer)
+
+ self.assertNotEqual(vocab_size_3, 0)
+ self.assertEqual(vocab_size, vocab_size_3)
+ self.assertEqual(added_toks_2, len(new_toks_2))
+ self.assertEqual(all_size_3, all_size_2 + len(new_toks_2))
+
+ nodes = ">>>>|||<||<<|<< aaaaabbbbbb low cccccccccdddddddd <<<<<|||>|>>>>|> l".split()
+ xpaths = ["/html/body/div/li[1]/div/span" for _ in range(len(nodes))]
+
+ tokens = tokenizer.encode(
+ nodes,
+ xpaths=xpaths,
+ add_special_tokens=False,
+ )
+
+ self.assertGreaterEqual(len(tokens), 6)
+ self.assertGreater(tokens[0], tokenizer.vocab_size - 1)
+ self.assertGreater(tokens[0], tokens[1])
+ self.assertGreater(tokens[-2], tokenizer.vocab_size - 1)
+ self.assertGreater(tokens[-2], tokens[-3])
+ self.assertEqual(tokens[0], tokenizer.eos_token_id)
+ self.assertEqual(tokens[-2], tokenizer.pad_token_id)
+
+ @require_tokenizers
+ def test_encode_decode_with_spaces(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ nodes, xpaths = self.get_nodes_and_xpaths()
+
+ new_toks = [AddedToken("[ABC]", normalized=False), AddedToken("[DEF]", normalized=False)]
+ tokenizer.add_tokens(new_toks)
+ input = "[ABC][DEF][ABC][DEF]"
+ if self.space_between_special_tokens:
+ output = "[ABC] [DEF] [ABC] [DEF]"
+ else:
+ output = input
+ encoded = tokenizer.encode(input.split(), xpaths=xpaths, add_special_tokens=False)
+ decoded = tokenizer.decode(encoded, spaces_between_special_tokens=self.space_between_special_tokens)
+ self.assertIn(decoded, [output, output.lower()])
+
+ @unittest.skip("Not implemented")
+ def test_right_and_left_truncation(self):
+ pass
+
+ def test_encode_plus_with_padding(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ nodes, xpaths = self.get_nodes_and_xpaths()
+
+ # check correct behaviour if no pad_token_id exists and add it eventually
+ self._check_no_pad_token_padding(tokenizer, nodes)
+
+ padding_size = 10
+ padding_idx = tokenizer.pad_token_id
+
+ encoded_sequence = tokenizer.encode_plus(nodes, xpaths=xpaths, return_special_tokens_mask=True)
+ input_ids = encoded_sequence["input_ids"]
+ special_tokens_mask = encoded_sequence["special_tokens_mask"]
+ sequence_length = len(input_ids)
+
+ # Test 'longest' and 'no_padding' don't do anything
+ tokenizer.padding_side = "right"
+
+ not_padded_sequence = tokenizer.encode_plus(
+ nodes,
+ xpaths=xpaths,
+ padding=False,
+ return_special_tokens_mask=True,
+ )
+ not_padded_input_ids = not_padded_sequence["input_ids"]
+
+ not_padded_special_tokens_mask = not_padded_sequence["special_tokens_mask"]
+ not_padded_sequence_length = len(not_padded_input_ids)
+
+ self.assertTrue(sequence_length == not_padded_sequence_length)
+ self.assertTrue(input_ids == not_padded_input_ids)
+ self.assertTrue(special_tokens_mask == not_padded_special_tokens_mask)
+
+ not_padded_sequence = tokenizer.encode_plus(
+ nodes,
+ xpaths=xpaths,
+ padding=False,
+ return_special_tokens_mask=True,
+ )
+ not_padded_input_ids = not_padded_sequence["input_ids"]
+
+ not_padded_special_tokens_mask = not_padded_sequence["special_tokens_mask"]
+ not_padded_sequence_length = len(not_padded_input_ids)
+
+ self.assertTrue(sequence_length == not_padded_sequence_length)
+ self.assertTrue(input_ids == not_padded_input_ids)
+ self.assertTrue(special_tokens_mask == not_padded_special_tokens_mask)
+
+ # Test right padding
+ tokenizer.padding_side = "right"
+
+ right_padded_sequence = tokenizer.encode_plus(
+ nodes,
+ xpaths=xpaths,
+ max_length=sequence_length + padding_size,
+ padding="max_length",
+ return_special_tokens_mask=True,
+ )
+ right_padded_input_ids = right_padded_sequence["input_ids"]
+
+ right_padded_special_tokens_mask = right_padded_sequence["special_tokens_mask"]
+ right_padded_sequence_length = len(right_padded_input_ids)
+
+ self.assertTrue(sequence_length + padding_size == right_padded_sequence_length)
+ self.assertTrue(input_ids + [padding_idx] * padding_size == right_padded_input_ids)
+ self.assertTrue(special_tokens_mask + [1] * padding_size == right_padded_special_tokens_mask)
+
+ # Test left padding
+ tokenizer.padding_side = "left"
+ left_padded_sequence = tokenizer.encode_plus(
+ nodes,
+ xpaths=xpaths,
+ max_length=sequence_length + padding_size,
+ padding="max_length",
+ return_special_tokens_mask=True,
+ )
+ left_padded_input_ids = left_padded_sequence["input_ids"]
+ left_padded_special_tokens_mask = left_padded_sequence["special_tokens_mask"]
+ left_padded_sequence_length = len(left_padded_input_ids)
+
+ self.assertTrue(sequence_length + padding_size == left_padded_sequence_length)
+ self.assertTrue([padding_idx] * padding_size + input_ids == left_padded_input_ids)
+ self.assertTrue([1] * padding_size + special_tokens_mask == left_padded_special_tokens_mask)
+
+ if "token_type_ids" in tokenizer.model_input_names:
+ token_type_ids = encoded_sequence["token_type_ids"]
+ left_padded_token_type_ids = left_padded_sequence["token_type_ids"]
+ right_padded_token_type_ids = right_padded_sequence["token_type_ids"]
+
+ assert token_type_ids + [0] * padding_size == right_padded_token_type_ids
+ assert [0] * padding_size + token_type_ids == left_padded_token_type_ids
+
+ if "attention_mask" in tokenizer.model_input_names:
+ attention_mask = encoded_sequence["attention_mask"]
+ right_padded_attention_mask = right_padded_sequence["attention_mask"]
+ left_padded_attention_mask = left_padded_sequence["attention_mask"]
+
+ self.assertTrue(attention_mask + [0] * padding_size == right_padded_attention_mask)
+ self.assertTrue([0] * padding_size + attention_mask == left_padded_attention_mask)
+
+ def test_internal_consistency(self):
+ tokenizers = self.get_tokenizers()
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ nodes, xpaths = self.get_nodes_and_xpaths()
+
+ tokens = []
+ for word in nodes:
+ tokens.extend(tokenizer.tokenize(word))
+ ids = tokenizer.convert_tokens_to_ids(tokens)
+ ids_2 = tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+ self.assertListEqual(ids, ids_2)
+
+ tokens_2 = tokenizer.convert_ids_to_tokens(ids)
+ self.assertNotEqual(len(tokens_2), 0)
+ text_2 = tokenizer.decode(ids)
+ self.assertIsInstance(text_2, str)
+
+ def test_mask_output(self):
+ tokenizers = self.get_tokenizers(fast=False, do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ nodes, xpaths = self.get_nodes_and_xpaths()
+
+ if (
+ tokenizer.build_inputs_with_special_tokens.__qualname__.split(".")[0] != "PreTrainedTokenizer"
+ and "token_type_ids" in tokenizer.model_input_names
+ ):
+ information = tokenizer.encode_plus(nodes, xpaths=xpaths, add_special_tokens=True)
+ sequences, mask = information["input_ids"], information["token_type_ids"]
+ self.assertEqual(len(sequences), len(mask))
+
+ def test_number_of_added_tokens(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ # test 1: single sequence
+ nodes, xpaths = self.get_nodes_and_xpaths()
+
+ sequences = tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+ attached_sequences = tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=True)
+
+ # Method is implemented (e.g. not GPT-2)
+ if len(attached_sequences) != 2:
+ self.assertEqual(
+ tokenizer.num_special_tokens_to_add(pair=False), len(attached_sequences) - len(sequences)
+ )
+
+ # test 2: two sequences
+ question, nodes, xpaths = self.get_question_nodes_and_xpaths()
+
+ sequences = tokenizer.encode(question, nodes, xpaths=xpaths, add_special_tokens=False)
+ attached_sequences = tokenizer.encode(question, nodes, xpaths=xpaths, add_special_tokens=True)
+
+ # Method is implemented (e.g. not GPT-2)
+ if len(attached_sequences) != 2:
+ self.assertEqual(
+ tokenizer.num_special_tokens_to_add(pair=True), len(attached_sequences) - len(sequences)
+ )
+
+ def test_padding_to_max_length(self):
+ """We keep this test for backward compatibility but it should be removed when `pad_to_max_length` will be deprecated"""
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ padding_size = 10
+
+ # check correct behaviour if no pad_token_id exists and add it eventually
+ self._check_no_pad_token_padding(tokenizer, nodes)
+
+ padding_idx = tokenizer.pad_token_id
+
+ # Check that it correctly pads when a maximum length is specified along with the padding flag set to True
+ tokenizer.padding_side = "right"
+ encoded_sequence = tokenizer.encode(nodes, xpaths=xpaths)
+ sequence_length = len(encoded_sequence)
+ # FIXME: the next line should be padding(max_length) to avoid warning
+ padded_sequence = tokenizer.encode(
+ nodes, xpaths=xpaths, max_length=sequence_length + padding_size, pad_to_max_length=True
+ )
+ padded_sequence_length = len(padded_sequence)
+ assert sequence_length + padding_size == padded_sequence_length
+ assert encoded_sequence + [padding_idx] * padding_size == padded_sequence
+
+ # Check that nothing is done when a maximum length is not specified
+ encoded_sequence = tokenizer.encode(nodes, xpaths=xpaths)
+ sequence_length = len(encoded_sequence)
+
+ tokenizer.padding_side = "right"
+ padded_sequence_right = tokenizer.encode(nodes, xpaths=xpaths, pad_to_max_length=True)
+ padded_sequence_right_length = len(padded_sequence_right)
+ assert sequence_length == padded_sequence_right_length
+ assert encoded_sequence == padded_sequence_right
+
+ def test_padding(self, max_length=50):
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ tokenizer_r = self.rust_tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+ tokenizer_p = self.tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+
+ self.assertEqual(tokenizer_p.pad_token_id, tokenizer_r.pad_token_id)
+ pad_token_id = tokenizer_p.pad_token_id
+
+ # Encode - Simple input
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ input_r = tokenizer_r.encode(nodes, xpaths=xpaths, max_length=max_length, pad_to_max_length=True)
+ input_p = tokenizer_p.encode(nodes, xpaths=xpaths, max_length=max_length, pad_to_max_length=True)
+ self.assert_padded_input_match(input_r, input_p, max_length, pad_token_id)
+ input_r = tokenizer_r.encode(nodes, xpaths=xpaths, max_length=max_length, padding="max_length")
+ input_p = tokenizer_p.encode(nodes, xpaths=xpaths, max_length=max_length, padding="max_length")
+ self.assert_padded_input_match(input_r, input_p, max_length, pad_token_id)
+
+ input_r = tokenizer_r.encode(nodes, xpaths=xpaths, padding="longest")
+ input_p = tokenizer_p.encode(nodes, xpaths=xpaths, padding=True)
+ self.assert_padded_input_match(input_r, input_p, len(input_r), pad_token_id)
+
+ # Encode - Pair input
+ question, nodes, xpaths = self.get_question_nodes_and_xpaths()
+ input_r = tokenizer_r.encode(
+ question, nodes, xpaths=xpaths, max_length=max_length, pad_to_max_length=True
+ )
+ input_p = tokenizer_p.encode(
+ question, nodes, xpaths=xpaths, max_length=max_length, pad_to_max_length=True
+ )
+ self.assert_padded_input_match(input_r, input_p, max_length, pad_token_id)
+ input_r = tokenizer_r.encode(
+ question, nodes, xpaths=xpaths, max_length=max_length, padding="max_length"
+ )
+ input_p = tokenizer_p.encode(
+ question, nodes, xpaths=xpaths, max_length=max_length, padding="max_length"
+ )
+ self.assert_padded_input_match(input_r, input_p, max_length, pad_token_id)
+ input_r = tokenizer_r.encode(question, nodes, xpaths=xpaths, padding=True)
+ input_p = tokenizer_p.encode(question, nodes, xpaths=xpaths, padding="longest")
+ self.assert_padded_input_match(input_r, input_p, len(input_r), pad_token_id)
+
+ # Encode_plus - Simple input
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ input_r = tokenizer_r.encode_plus(nodes, xpaths=xpaths, max_length=max_length, pad_to_max_length=True)
+ input_p = tokenizer_p.encode_plus(nodes, xpaths=xpaths, max_length=max_length, pad_to_max_length=True)
+ self.assert_padded_input_match(input_r["input_ids"], input_p["input_ids"], max_length, pad_token_id)
+ self.assertSequenceEqual(input_r["attention_mask"], input_p["attention_mask"])
+ input_r = tokenizer_r.encode_plus(nodes, xpaths=xpaths, max_length=max_length, padding="max_length")
+ input_p = tokenizer_p.encode_plus(nodes, xpaths=xpaths, max_length=max_length, padding="max_length")
+ self.assert_padded_input_match(input_r["input_ids"], input_p["input_ids"], max_length, pad_token_id)
+ self.assertSequenceEqual(input_r["attention_mask"], input_p["attention_mask"])
+
+ input_r = tokenizer_r.encode_plus(nodes, xpaths=xpaths, padding="longest")
+ input_p = tokenizer_p.encode_plus(nodes, xpaths=xpaths, padding=True)
+ self.assert_padded_input_match(
+ input_r["input_ids"], input_p["input_ids"], len(input_r["input_ids"]), pad_token_id
+ )
+
+ self.assertSequenceEqual(input_r["attention_mask"], input_p["attention_mask"])
+
+ # Encode_plus - Pair input
+ question, nodes, xpaths = self.get_question_nodes_and_xpaths()
+ input_r = tokenizer_r.encode_plus(
+ question, nodes, xpaths=xpaths, max_length=max_length, pad_to_max_length=True
+ )
+ input_p = tokenizer_p.encode_plus(
+ question, nodes, xpaths=xpaths, max_length=max_length, pad_to_max_length=True
+ )
+ self.assert_padded_input_match(input_r["input_ids"], input_p["input_ids"], max_length, pad_token_id)
+ self.assertSequenceEqual(input_r["attention_mask"], input_p["attention_mask"])
+ input_r = tokenizer_r.encode_plus(
+ question, nodes, xpaths=xpaths, max_length=max_length, padding="max_length"
+ )
+ input_p = tokenizer_p.encode_plus(
+ question, nodes, xpaths=xpaths, max_length=max_length, padding="max_length"
+ )
+ self.assert_padded_input_match(input_r["input_ids"], input_p["input_ids"], max_length, pad_token_id)
+ self.assertSequenceEqual(input_r["attention_mask"], input_p["attention_mask"])
+ input_r = tokenizer_r.encode_plus(question, nodes, xpaths=xpaths, padding="longest")
+ input_p = tokenizer_p.encode_plus(question, nodes, xpaths=xpaths, padding=True)
+ self.assert_padded_input_match(
+ input_r["input_ids"], input_p["input_ids"], len(input_r["input_ids"]), pad_token_id
+ )
+ self.assertSequenceEqual(input_r["attention_mask"], input_p["attention_mask"])
+
+ # Batch_encode_plus - Simple input
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+
+ input_r = tokenizer_r.batch_encode_plus(
+ nodes,
+ xpaths=xpaths,
+ max_length=max_length,
+ pad_to_max_length=True,
+ )
+ input_p = tokenizer_p.batch_encode_plus(
+ nodes,
+ xpaths=xpaths,
+ max_length=max_length,
+ pad_to_max_length=True,
+ )
+ self.assert_batch_padded_input_match(input_r, input_p, max_length, pad_token_id)
+
+ input_r = tokenizer_r.batch_encode_plus(
+ nodes,
+ xpaths=xpaths,
+ max_length=max_length,
+ padding="max_length",
+ )
+ input_p = tokenizer_p.batch_encode_plus(
+ nodes,
+ xpaths=xpaths,
+ max_length=max_length,
+ padding="max_length",
+ )
+ self.assert_batch_padded_input_match(input_r, input_p, max_length, pad_token_id)
+
+ input_r = tokenizer_r.batch_encode_plus(
+ nodes,
+ xpaths=xpaths,
+ max_length=max_length,
+ padding="longest",
+ )
+ input_p = tokenizer_p.batch_encode_plus(
+ nodes,
+ xpaths=xpaths,
+ max_length=max_length,
+ padding=True,
+ )
+ self.assert_batch_padded_input_match(input_r, input_p, len(input_r["input_ids"][0]), pad_token_id)
+
+ input_r = tokenizer_r.batch_encode_plus(nodes, xpaths=xpaths, padding="longest")
+ input_p = tokenizer_p.batch_encode_plus(nodes, xpaths=xpaths, padding=True)
+ self.assert_batch_padded_input_match(input_r, input_p, len(input_r["input_ids"][0]), pad_token_id)
+
+ # Batch_encode_plus - Pair input
+ questions, nodes, xpaths = self.get_question_nodes_and_xpaths_batch()
+
+ input_r = tokenizer_r.batch_encode_plus(
+ list(zip(questions, nodes)),
+ is_pair=True,
+ xpaths=xpaths,
+ max_length=max_length,
+ truncation=True,
+ padding="max_length",
+ )
+ input_p = tokenizer_p.batch_encode_plus(
+ list(zip(questions, nodes)),
+ is_pair=True,
+ xpaths=xpaths,
+ max_length=max_length,
+ truncation=True,
+ padding="max_length",
+ )
+ self.assert_batch_padded_input_match(input_r, input_p, max_length, pad_token_id)
+
+ input_r = tokenizer_r.batch_encode_plus(
+ list(zip(questions, nodes)),
+ is_pair=True,
+ xpaths=xpaths,
+ padding=True,
+ )
+ input_p = tokenizer_p.batch_encode_plus(
+ list(zip(questions, nodes)),
+ is_pair=True,
+ xpaths=xpaths,
+ padding="longest",
+ )
+ self.assert_batch_padded_input_match(input_r, input_p, len(input_r["input_ids"][0]), pad_token_id)
+
+ # Using pad on single examples after tokenization
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ input_r = tokenizer_r.encode_plus(nodes, xpaths=xpaths)
+ input_r = tokenizer_r.pad(input_r)
+
+ input_p = tokenizer_r.encode_plus(nodes, xpaths=xpaths)
+ input_p = tokenizer_r.pad(input_p)
+
+ self.assert_padded_input_match(
+ input_r["input_ids"], input_p["input_ids"], len(input_r["input_ids"]), pad_token_id
+ )
+
+ # Using pad on single examples after tokenization
+ input_r = tokenizer_r.encode_plus(nodes, xpaths=xpaths)
+ input_r = tokenizer_r.pad(input_r, max_length=max_length, padding="max_length")
+
+ input_p = tokenizer_r.encode_plus(nodes, xpaths=xpaths)
+ input_p = tokenizer_r.pad(input_p, max_length=max_length, padding="max_length")
+
+ self.assert_padded_input_match(input_r["input_ids"], input_p["input_ids"], max_length, pad_token_id)
+
+ # Using pad after tokenization
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+ input_r = tokenizer_r.batch_encode_plus(nodes, xpaths=xpaths)
+ input_r = tokenizer_r.pad(input_r)
+
+ input_p = tokenizer_r.batch_encode_plus(nodes, xpaths=xpaths)
+ input_p = tokenizer_r.pad(input_p)
+
+ self.assert_batch_padded_input_match(input_r, input_p, len(input_r["input_ids"][0]), pad_token_id)
+
+ # Using pad after tokenization
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+ input_r = tokenizer_r.batch_encode_plus(nodes, xpaths=xpaths)
+ input_r = tokenizer_r.pad(input_r, max_length=max_length, padding="max_length")
+
+ input_p = tokenizer_r.batch_encode_plus(nodes, xpaths=xpaths)
+ input_p = tokenizer_r.pad(input_p, max_length=max_length, padding="max_length")
+
+ self.assert_batch_padded_input_match(input_r, input_p, max_length, pad_token_id)
+
+ def test_call(self):
+ # Tests that all call wrap to encode_plus and batch_encode_plus
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ # Test not batched
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ encoded_sequences_1 = tokenizer.encode_plus(nodes, xpaths=xpaths)
+ encoded_sequences_2 = tokenizer(nodes, xpaths=xpaths)
+ self.assertEqual(encoded_sequences_1, encoded_sequences_2)
+
+ # Test not batched pairs
+ question, nodes, xpaths = self.get_question_nodes_and_xpaths()
+ encoded_sequences_1 = tokenizer.encode_plus(nodes, xpaths=xpaths)
+ encoded_sequences_2 = tokenizer(nodes, xpaths=xpaths)
+ self.assertEqual(encoded_sequences_1, encoded_sequences_2)
+
+ # Test batched
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+ encoded_sequences_1 = tokenizer.batch_encode_plus(nodes, is_pair=False, xpaths=xpaths)
+ encoded_sequences_2 = tokenizer(nodes, xpaths=xpaths)
+ self.assertEqual(encoded_sequences_1, encoded_sequences_2)
+
+ def test_batch_encode_plus_batch_sequence_length(self):
+ # Tests that all encoded values have the correct size
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+
+ encoded_sequences = [
+ tokenizer.encode_plus(nodes_example, xpaths=xpaths_example)
+ for nodes_example, xpaths_example in zip(nodes, xpaths)
+ ]
+ encoded_sequences_batch = tokenizer.batch_encode_plus(
+ nodes, is_pair=False, xpaths=xpaths, padding=False
+ )
+ self.assertListEqual(
+ encoded_sequences, self.convert_batch_encode_plus_format_to_encode_plus(encoded_sequences_batch)
+ )
+
+ maximum_length = len(
+ max([encoded_sequence["input_ids"] for encoded_sequence in encoded_sequences], key=len)
+ )
+
+ # check correct behaviour if no pad_token_id exists and add it eventually
+ self._check_no_pad_token_padding(tokenizer, nodes)
+
+ encoded_sequences_padded = [
+ tokenizer.encode_plus(
+ nodes_example, xpaths=xpaths_example, max_length=maximum_length, padding="max_length"
+ )
+ for nodes_example, xpaths_example in zip(nodes, xpaths)
+ ]
+
+ encoded_sequences_batch_padded = tokenizer.batch_encode_plus(
+ nodes, is_pair=False, xpaths=xpaths, padding=True
+ )
+ self.assertListEqual(
+ encoded_sequences_padded,
+ self.convert_batch_encode_plus_format_to_encode_plus(encoded_sequences_batch_padded),
+ )
+
+ # check 'longest' is unsensitive to a max length
+ encoded_sequences_batch_padded_1 = tokenizer.batch_encode_plus(
+ nodes, is_pair=False, xpaths=xpaths, padding=True
+ )
+ encoded_sequences_batch_padded_2 = tokenizer.batch_encode_plus(
+ nodes, is_pair=False, xpaths=xpaths, max_length=maximum_length + 10, padding="longest"
+ )
+ for key in encoded_sequences_batch_padded_1.keys():
+ self.assertListEqual(
+ encoded_sequences_batch_padded_1[key],
+ encoded_sequences_batch_padded_2[key],
+ )
+
+ # check 'no_padding' is unsensitive to a max length
+ encoded_sequences_batch_padded_1 = tokenizer.batch_encode_plus(
+ nodes, is_pair=False, xpaths=xpaths, padding=False
+ )
+ encoded_sequences_batch_padded_2 = tokenizer.batch_encode_plus(
+ nodes, is_pair=False, xpaths=xpaths, max_length=maximum_length + 10, padding=False
+ )
+ for key in encoded_sequences_batch_padded_1.keys():
+ self.assertListEqual(
+ encoded_sequences_batch_padded_1[key],
+ encoded_sequences_batch_padded_2[key],
+ )
+
+ @unittest.skip("batch_encode_plus does not handle overflowing tokens.")
+ def test_batch_encode_plus_overflowing_tokens(self):
+ pass
+
+ def test_batch_encode_plus_padding(self):
+ # Test that padded sequences are equivalent between batch_encode_plus and encode_plus
+
+ # Right padding tests
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+
+ max_length = 100
+
+ # check correct behaviour if no pad_token_id exists and add it eventually
+ self._check_no_pad_token_padding(tokenizer, nodes)
+
+ encoded_sequences = [
+ tokenizer.encode_plus(
+ nodes_example, xpaths=xpaths_example, max_length=max_length, padding="max_length"
+ )
+ for nodes_example, xpaths_example in zip(nodes, xpaths)
+ ]
+ encoded_sequences_batch = tokenizer.batch_encode_plus(
+ nodes, is_pair=False, xpaths=xpaths, max_length=max_length, padding="max_length"
+ )
+ self.assertListEqual(
+ encoded_sequences, self.convert_batch_encode_plus_format_to_encode_plus(encoded_sequences_batch)
+ )
+
+ # Left padding tests
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ tokenizer.padding_side = "left"
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+
+ max_length = 100
+
+ # check correct behaviour if no pad_token_id exists and add it eventually
+ self._check_no_pad_token_padding(tokenizer, nodes)
+
+ encoded_sequences = [
+ tokenizer.encode_plus(
+ nodes_example, xpaths=xpaths_example, max_length=max_length, padding="max_length"
+ )
+ for nodes_example, xpaths_example in zip(nodes, xpaths)
+ ]
+ encoded_sequences_batch = tokenizer.batch_encode_plus(
+ nodes, is_pair=False, xpaths=xpaths, max_length=max_length, padding="max_length"
+ )
+ self.assertListEqual(
+ encoded_sequences, self.convert_batch_encode_plus_format_to_encode_plus(encoded_sequences_batch)
+ )
+
+ def test_padding_to_multiple_of(self):
+ tokenizers = self.get_tokenizers()
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ if tokenizer.pad_token is None:
+ self.skipTest("No padding token.")
+ else:
+ nodes, xpaths = self.get_nodes_and_xpaths()
+
+ # empty_tokens = tokenizer([""], [[]], padding=True, pad_to_multiple_of=8)
+ normal_tokens = tokenizer(nodes, xpaths=xpaths, padding=True, pad_to_multiple_of=8)
+ # for key, value in empty_tokens.items():
+ # self.assertEqual(len(value) % 8, 0, f"BatchEncoding.{key} is not multiple of 8")
+ for key, value in normal_tokens.items():
+ self.assertEqual(len(value) % 8, 0, f"BatchEncoding.{key} is not multiple of 8")
+
+ normal_tokens = tokenizer(nodes, xpaths=xpaths, pad_to_multiple_of=8)
+ for key, value in normal_tokens.items():
+ self.assertNotEqual(len(value) % 8, 0, f"BatchEncoding.{key} is not multiple of 8")
+
+ # Should also work with truncation
+ normal_tokens = tokenizer(
+ nodes, xpaths=xpaths, padding=True, truncation=True, pad_to_multiple_of=8
+ )
+ for key, value in normal_tokens.items():
+ self.assertEqual(len(value) % 8, 0, f"BatchEncoding.{key} is not multiple of 8")
+
+ # truncation to something which is not a multiple of pad_to_multiple_of raises an error
+ self.assertRaises(
+ ValueError,
+ tokenizer.__call__,
+ nodes,
+ xpaths=xpaths,
+ padding=True,
+ truncation=True,
+ max_length=12,
+ pad_to_multiple_of=8,
+ )
+
+ def test_tokenizer_slow_store_full_signature(self):
+ signature = inspect.signature(self.tokenizer_class.__init__)
+ tokenizer = self.get_tokenizer()
+
+ for parameter_name, parameter in signature.parameters.items():
+ if parameter.default != inspect.Parameter.empty:
+ self.assertIn(parameter_name, tokenizer.init_kwargs)
+
+ def test_build_inputs_with_special_tokens(self):
+ if not self.test_slow_tokenizer:
+ # as we don't have a slow version, we can't compare the outputs between slow and fast versions
+ return
+
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ tokenizer_r = self.rust_tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+ tokenizer_p = self.tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+
+ # Input tokens id
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ input_simple = tokenizer_p.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+ input_pair = tokenizer_p.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+
+ # Generate output
+ output_r = tokenizer_r.build_inputs_with_special_tokens(input_simple)
+ output_p = tokenizer_p.build_inputs_with_special_tokens(input_simple)
+ self.assertEqual(output_p, output_r)
+
+ # Generate pair output
+ output_r = tokenizer_r.build_inputs_with_special_tokens(input_simple, input_pair)
+ output_p = tokenizer_p.build_inputs_with_special_tokens(input_simple, input_pair)
+ self.assertEqual(output_p, output_r)
+
+ def test_special_tokens_mask_input_pairs(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ encoded_sequence = tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+ encoded_sequence_dict = tokenizer.encode_plus(
+ nodes,
+ xpaths=xpaths,
+ add_special_tokens=True,
+ return_special_tokens_mask=True,
+ # add_prefix_space=False,
+ )
+ encoded_sequence_w_special = encoded_sequence_dict["input_ids"]
+ special_tokens_mask = encoded_sequence_dict["special_tokens_mask"]
+ self.assertEqual(len(special_tokens_mask), len(encoded_sequence_w_special))
+
+ filtered_sequence = [
+ (x if not special_tokens_mask[i] else None) for i, x in enumerate(encoded_sequence_w_special)
+ ]
+ filtered_sequence = [x for x in filtered_sequence if x is not None]
+ self.assertEqual(encoded_sequence, filtered_sequence)
+
+ def test_special_tokens_mask(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ # Testing single inputs
+ encoded_sequence = tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+ encoded_sequence_dict = tokenizer.encode_plus(
+ nodes, xpaths=xpaths, add_special_tokens=True, return_special_tokens_mask=True
+ )
+ encoded_sequence_w_special = encoded_sequence_dict["input_ids"]
+ special_tokens_mask = encoded_sequence_dict["special_tokens_mask"]
+ self.assertEqual(len(special_tokens_mask), len(encoded_sequence_w_special))
+
+ filtered_sequence = [x for i, x in enumerate(encoded_sequence_w_special) if not special_tokens_mask[i]]
+ self.assertEqual(encoded_sequence, filtered_sequence)
+
+ def test_save_and_load_tokenizer(self):
+ # safety check on max_len default value so we are sure the test works
+ tokenizers = self.get_tokenizers()
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ self.assertNotEqual(tokenizer.model_max_length, 42)
+
+ # Now let's start the test
+ tokenizers = self.get_tokenizers()
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ # Isolate this from the other tests because we save additional tokens/etc
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ tmpdirname = tempfile.mkdtemp()
+
+ before_tokens = tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+ before_vocab = tokenizer.get_vocab()
+ tokenizer.save_pretrained(tmpdirname)
+
+ after_tokenizer = tokenizer.__class__.from_pretrained(tmpdirname)
+ after_tokens = after_tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+ after_vocab = after_tokenizer.get_vocab()
+ self.assertListEqual(before_tokens, after_tokens)
+ self.assertDictEqual(before_vocab, after_vocab)
+
+ shutil.rmtree(tmpdirname)
+
+ def test_right_and_left_padding(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ sequence = "Sequence"
+ padding_size = 10
+
+ # check correct behaviour if no pad_token_id exists and add it eventually
+ self._check_no_pad_token_padding(tokenizer, sequence)
+
+ padding_idx = tokenizer.pad_token_id
+
+ # RIGHT PADDING - Check that it correctly pads when a maximum length is specified along with the padding flag set to True
+ tokenizer.padding_side = "right"
+ encoded_sequence = tokenizer.encode(nodes, xpaths=xpaths)
+ sequence_length = len(encoded_sequence)
+ padded_sequence = tokenizer.encode(
+ nodes, xpaths=xpaths, max_length=sequence_length + padding_size, padding="max_length"
+ )
+ padded_sequence_length = len(padded_sequence)
+ assert sequence_length + padding_size == padded_sequence_length
+ assert encoded_sequence + [padding_idx] * padding_size == padded_sequence
+
+ # LEFT PADDING - Check that it correctly pads when a maximum length is specified along with the padding flag set to True
+ tokenizer.padding_side = "left"
+ encoded_sequence = tokenizer.encode(nodes, xpaths=xpaths)
+ sequence_length = len(encoded_sequence)
+ padded_sequence = tokenizer.encode(
+ nodes, xpaths=xpaths, max_length=sequence_length + padding_size, padding="max_length"
+ )
+ padded_sequence_length = len(padded_sequence)
+ assert sequence_length + padding_size == padded_sequence_length
+ assert [padding_idx] * padding_size + encoded_sequence == padded_sequence
+
+ # RIGHT & LEFT PADDING - Check that nothing is done for 'longest' and 'no_padding'
+ encoded_sequence = tokenizer.encode(nodes, xpaths=xpaths)
+ sequence_length = len(encoded_sequence)
+
+ tokenizer.padding_side = "right"
+ padded_sequence_right = tokenizer.encode(nodes, xpaths=xpaths, padding=True)
+ padded_sequence_right_length = len(padded_sequence_right)
+ assert sequence_length == padded_sequence_right_length
+ assert encoded_sequence == padded_sequence_right
+
+ tokenizer.padding_side = "left"
+ padded_sequence_left = tokenizer.encode(nodes, xpaths=xpaths, padding="longest")
+ padded_sequence_left_length = len(padded_sequence_left)
+ assert sequence_length == padded_sequence_left_length
+ assert encoded_sequence == padded_sequence_left
+
+ tokenizer.padding_side = "right"
+ padded_sequence_right = tokenizer.encode(nodes, xpaths=xpaths)
+ padded_sequence_right_length = len(padded_sequence_right)
+ assert sequence_length == padded_sequence_right_length
+ assert encoded_sequence == padded_sequence_right
+
+ tokenizer.padding_side = "left"
+ padded_sequence_left = tokenizer.encode(nodes, xpaths=xpaths, padding=False)
+ padded_sequence_left_length = len(padded_sequence_left)
+ assert sequence_length == padded_sequence_left_length
+ assert encoded_sequence == padded_sequence_left
+
+ def test_token_type_ids(self):
+ tokenizers = self.get_tokenizers()
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ # test 1: single sequence
+ nodes, xpaths = self.get_nodes_and_xpaths()
+
+ output = tokenizer(nodes, xpaths=xpaths, return_token_type_ids=True)
+
+ # Assert that the token type IDs have the same length as the input IDs
+ self.assertEqual(len(output["token_type_ids"]), len(output["input_ids"]))
+
+ # Assert that the token type IDs have the same length as the attention mask
+ self.assertEqual(len(output["token_type_ids"]), len(output["attention_mask"]))
+
+ self.assertIn(0, output["token_type_ids"])
+ self.assertNotIn(1, output["token_type_ids"])
+
+ # test 2: two sequences (question + nodes)
+ question, nodes, xpaths = self.get_question_nodes_and_xpaths()
+
+ output = tokenizer(question, nodes, xpaths, return_token_type_ids=True)
+
+ # Assert that the token type IDs have the same length as the input IDs
+ self.assertEqual(len(output["token_type_ids"]), len(output["input_ids"]))
+
+ # Assert that the token type IDs have the same length as the attention mask
+ self.assertEqual(len(output["token_type_ids"]), len(output["attention_mask"]))
+
+ self.assertIn(0, output["token_type_ids"])
+
+ def test_offsets_mapping(self):
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ tokenizer_r = self.rust_tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+
+ text = ["a", "wonderful", "test"]
+ xpaths = ["html/body" for _ in range(len(text))]
+
+ # No pair
+ tokens_with_offsets = tokenizer_r.encode_plus(
+ text,
+ xpaths=xpaths,
+ return_special_tokens_mask=True,
+ return_offsets_mapping=True,
+ add_special_tokens=True,
+ )
+ added_tokens = tokenizer_r.num_special_tokens_to_add(False)
+ offsets = tokens_with_offsets["offset_mapping"]
+
+ # Assert there is the same number of tokens and offsets
+ self.assertEqual(len(offsets), len(tokens_with_offsets["input_ids"]))
+
+ # Assert there is online added_tokens special_tokens
+ self.assertEqual(sum(tokens_with_offsets["special_tokens_mask"]), added_tokens)
+
+ # Pairs
+ text = "what's his name"
+ pair = ["a", "wonderful", "test"]
+ xpaths = ["html/body" for _ in range(len(pair))]
+ tokens_with_offsets = tokenizer_r.encode_plus(
+ text,
+ pair,
+ xpaths=xpaths,
+ return_special_tokens_mask=True,
+ return_offsets_mapping=True,
+ add_special_tokens=True,
+ )
+ added_tokens = tokenizer_r.num_special_tokens_to_add(True)
+ offsets = tokens_with_offsets["offset_mapping"]
+
+ # Assert there is the same number of tokens and offsets
+ self.assertEqual(len(offsets), len(tokens_with_offsets["input_ids"]))
+
+ # Assert there is online added_tokens special_tokens
+ self.assertEqual(sum(tokens_with_offsets["special_tokens_mask"]), added_tokens)
+
+ @require_torch
+ @slow
+ def test_torch_encode_plus_sent_to_model(self):
+ import torch
+
+ from transformers import MODEL_MAPPING, TOKENIZER_MAPPING
+
+ MODEL_TOKENIZER_MAPPING = merge_model_tokenizer_mappings(MODEL_MAPPING, TOKENIZER_MAPPING)
+
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ if tokenizer.__class__ not in MODEL_TOKENIZER_MAPPING:
+ return
+
+ config_class, model_class = MODEL_TOKENIZER_MAPPING[tokenizer.__class__]
+ config = config_class()
+
+ if config.is_encoder_decoder or config.pad_token_id is None:
+ return
+
+ model = model_class(config)
+
+ # Make sure the model contains at least the full vocabulary size in its embedding matrix
+ is_using_common_embeddings = hasattr(model.get_input_embeddings(), "weight")
+ assert (
+ (model.get_input_embeddings().weight.shape[0] >= len(tokenizer))
+ if is_using_common_embeddings
+ else True
+ )
+
+ # Build sequence
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ encoded_sequence = tokenizer.encode_plus(nodes, xpaths=xpaths, return_tensors="pt")
+ batch_encoded_sequence = tokenizer.batch_encode_plus(
+ [nodes, nodes], [xpaths, xpaths], return_tensors="pt"
+ )
+ # This should not fail
+
+ with torch.no_grad(): # saves some time
+ model(**encoded_sequence)
+ model(**batch_encoded_sequence)
+
+ def test_rust_and_python_full_tokenizers(self):
+ if not self.test_rust_tokenizer:
+ return
+
+ if not self.test_slow_tokenizer:
+ # as we don't have a slow version, we can't compare the outputs between slow and fast versions
+ return
+
+ tokenizer = self.get_tokenizer()
+ rust_tokenizer = self.get_rust_tokenizer()
+
+ nodes, xpaths = self.get_nodes_and_xpaths()
+
+ ids = tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+ rust_ids = rust_tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+ self.assertListEqual(ids, rust_ids)
+
+ ids = tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=True)
+ rust_ids = rust_tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=True)
+ self.assertListEqual(ids, rust_ids)
+
+ def test_tokenization_python_rust_equals(self):
+ if not self.test_slow_tokenizer:
+ # as we don't have a slow version, we can't compare the outputs between slow and fast versions
+ return
+
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ tokenizer_r = self.rust_tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+ tokenizer_p = self.tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+
+ nodes, xpaths = self.get_nodes_and_xpaths()
+
+ # Ensure basic input match
+ input_p = tokenizer_p.encode_plus(nodes, xpaths=xpaths)
+ input_r = tokenizer_r.encode_plus(nodes, xpaths=xpaths)
+
+ for key in filter(
+ lambda x: x
+ in ["input_ids", "token_type_ids", "attention_mask", "xpath_tags_seq", "xpath_subs_seq"],
+ input_p.keys(),
+ ):
+ self.assertSequenceEqual(input_p[key], input_r[key])
+
+ input_pairs_p = tokenizer_p.encode_plus(nodes, xpaths=xpaths)
+ input_pairs_r = tokenizer_r.encode_plus(nodes, xpaths=xpaths)
+
+ for key in filter(
+ lambda x: x
+ in ["input_ids", "token_type_ids", "attention_mask", "xpath_tags_seq", "xpath_subs_seq"],
+ input_p.keys(),
+ ):
+ self.assertSequenceEqual(input_pairs_p[key], input_pairs_r[key])
+
+ nodes = ["hello" for _ in range(1000)]
+ xpaths = ["html/body" for _ in range(1000)]
+
+ # Ensure truncation match
+ input_p = tokenizer_p.encode_plus(nodes, xpaths=xpaths, max_length=512, truncation=True)
+ input_r = tokenizer_r.encode_plus(nodes, xpaths=xpaths, max_length=512, truncation=True)
+
+ for key in filter(
+ lambda x: x
+ in ["input_ids", "token_type_ids", "attention_mask", "xpath_tags_seq", "xpath_subs_seq"],
+ input_p.keys(),
+ ):
+ self.assertSequenceEqual(input_p[key], input_r[key])
+
+ # Ensure truncation with stride match
+ input_p = tokenizer_p.encode_plus(
+ nodes, xpaths=xpaths, max_length=512, truncation=True, stride=3, return_overflowing_tokens=True
+ )
+ input_r = tokenizer_r.encode_plus(
+ nodes, xpaths=xpaths, max_length=512, truncation=True, stride=3, return_overflowing_tokens=True
+ )
+
+ for key in filter(
+ lambda x: x
+ in ["input_ids", "token_type_ids", "attention_mask", "xpath_tags_seq", "xpath_subs_seq"],
+ input_p.keys(),
+ ):
+ self.assertSequenceEqual(input_p[key], input_r[key][0])
+
+ def test_embeded_special_tokens(self):
+ if not self.test_slow_tokenizer:
+ # as we don't have a slow version, we can't compare the outputs between slow and fast versions
+ return
+
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ tokenizer_r = self.rust_tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+ tokenizer_p = self.tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ tokens_r = tokenizer_r.encode_plus(nodes, xpaths=xpaths, add_special_tokens=True)
+ tokens_p = tokenizer_p.encode_plus(nodes, xpaths=xpaths, add_special_tokens=True)
+
+ for key in tokens_p.keys():
+ self.assertEqual(tokens_r[key], tokens_p[key])
+
+ if "token_type_ids" in tokens_r:
+ self.assertEqual(sum(tokens_r["token_type_ids"]), sum(tokens_p["token_type_ids"]))
+
+ tokens_r = tokenizer_r.convert_ids_to_tokens(tokens_r["input_ids"])
+ tokens_p = tokenizer_p.convert_ids_to_tokens(tokens_p["input_ids"])
+ self.assertSequenceEqual(tokens_r, tokens_p)
+
+ def test_compare_add_special_tokens(self):
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ tokenizer_r = self.rust_tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+
+ simple_num_special_tokens_to_add = tokenizer_r.num_special_tokens_to_add(pair=False)
+
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ # tokenize()
+ no_special_tokens = tokenizer_r.tokenize(" ".join(nodes), add_special_tokens=False)
+ with_special_tokens = tokenizer_r.tokenize(" ".join(nodes), add_special_tokens=True)
+ self.assertEqual(len(no_special_tokens), len(with_special_tokens) - simple_num_special_tokens_to_add)
+
+ # encode()
+ no_special_tokens = tokenizer_r.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+ with_special_tokens = tokenizer_r.encode(nodes, xpaths=xpaths, add_special_tokens=True)
+ self.assertEqual(len(no_special_tokens), len(with_special_tokens) - simple_num_special_tokens_to_add)
+
+ # encode_plus()
+ no_special_tokens = tokenizer_r.encode_plus(nodes, xpaths=xpaths, add_special_tokens=False)
+ with_special_tokens = tokenizer_r.encode_plus(nodes, xpaths=xpaths, add_special_tokens=True)
+ for key in no_special_tokens.keys():
+ self.assertEqual(
+ len(no_special_tokens[key]),
+ len(with_special_tokens[key]) - simple_num_special_tokens_to_add,
+ )
+
+ # # batch_encode_plus
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+
+ no_special_tokens = tokenizer_r.batch_encode_plus(nodes, xpaths=xpaths, add_special_tokens=False)
+ with_special_tokens = tokenizer_r.batch_encode_plus(nodes, xpaths=xpaths, add_special_tokens=True)
+ for key in no_special_tokens.keys():
+ for i_no, i_with in zip(no_special_tokens[key], with_special_tokens[key]):
+ self.assertEqual(len(i_no), len(i_with) - simple_num_special_tokens_to_add)
+
+ @slow
+ def test_markuplm_truncation_integration_test(self):
+ nodes, xpaths = self.get_nodes_and_xpaths()
+
+ tokenizer = MarkupLMTokenizer.from_pretrained("microsoft/markuplm-base", model_max_length=512)
+
+ for i in range(12, 512):
+ new_encoded_inputs = tokenizer.encode(nodes, xpaths=xpaths, max_length=i, truncation=True)
+
+ # Ensure that the input IDs are less than the max length defined.
+ self.assertLessEqual(len(new_encoded_inputs), i)
+
+ tokenizer.model_max_length = 20
+ new_encoded_inputs = tokenizer.encode(nodes, xpaths=xpaths, truncation=True)
+ dropped_encoded_inputs = tokenizer.encode(nodes, xpaths=xpaths, truncation=True)
+
+ # Ensure that the input IDs are still truncated when no max_length is specified
+ self.assertListEqual(new_encoded_inputs, dropped_encoded_inputs)
+ self.assertLessEqual(len(new_encoded_inputs), 20)
+
+ @is_pt_tf_cross_test
+ def test_batch_encode_plus_tensors(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+
+ # A Tensor cannot be build by sequences which are not the same size
+ self.assertRaises(ValueError, tokenizer.batch_encode_plus, nodes, xpaths=xpaths, return_tensors="pt")
+ self.assertRaises(ValueError, tokenizer.batch_encode_plus, nodes, xpaths=xpaths, return_tensors="tf")
+
+ if tokenizer.pad_token_id is None:
+ self.assertRaises(
+ ValueError,
+ tokenizer.batch_encode_plus,
+ nodes,
+ xpaths=xpaths,
+ padding=True,
+ return_tensors="pt",
+ )
+ self.assertRaises(
+ ValueError,
+ tokenizer.batch_encode_plus,
+ nodes,
+ xpaths=xpaths,
+ padding="longest",
+ return_tensors="tf",
+ )
+ else:
+ pytorch_tensor = tokenizer.batch_encode_plus(
+ nodes, xpaths=xpaths, padding=True, return_tensors="pt"
+ )
+ tensorflow_tensor = tokenizer.batch_encode_plus(
+ nodes, xpaths=xpaths, padding="longest", return_tensors="tf"
+ )
+ encoded_sequences = tokenizer.batch_encode_plus(nodes, xpaths=xpaths, padding=True)
+
+ for key in encoded_sequences.keys():
+ pytorch_value = pytorch_tensor[key].tolist()
+ tensorflow_value = tensorflow_tensor[key].numpy().tolist()
+ encoded_value = encoded_sequences[key]
+
+ self.assertEqual(pytorch_value, tensorflow_value, encoded_value)
+
+ def test_sequence_ids(self):
+ tokenizers = self.get_tokenizers()
+ for tokenizer in tokenizers:
+ if not tokenizer.is_fast:
+ continue
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ seq_0 = "Test this method."
+ seq_1 = ["With", "these", "inputs."]
+ xpaths = ["html/body" for _ in range(len(seq_1))]
+
+ # We want to have sequence 0 and sequence 1 are tagged
+ # respectively with 0 and 1 token_ids
+ # (regardless of whether the model use token type ids)
+ # We use this assumption in the QA pipeline among other place
+ output = tokenizer(seq_0.split(), xpaths=xpaths)
+ self.assertIn(0, output.sequence_ids())
+
+ output = tokenizer(seq_0, seq_1, xpaths=xpaths)
+ self.assertIn(0, output.sequence_ids())
+ self.assertIn(1, output.sequence_ids())
+
+ if tokenizer.num_special_tokens_to_add(pair=True):
+ self.assertIn(None, output.sequence_ids())
+
+ def test_special_tokens_initialization(self):
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ added_tokens = [AddedToken("", lstrip=True)]
+
+ tokenizer_r = self.rust_tokenizer_class.from_pretrained(
+ pretrained_name, additional_special_tokens=added_tokens, **kwargs
+ )
+ nodes = "Hey this is a token".split()
+ xpaths = ["html/body" for _ in range(len(nodes))]
+ r_output = tokenizer_r.encode(nodes, xpaths=xpaths)
+
+ special_token_id = tokenizer_r.encode([""], xpaths=["html/body"], add_special_tokens=False)[0]
+
+ self.assertTrue(special_token_id in r_output)
+
+ if self.test_slow_tokenizer:
+ tokenizer_cr = self.rust_tokenizer_class.from_pretrained(
+ pretrained_name, additional_special_tokens=added_tokens, **kwargs
+ )
+ tokenizer_p = self.tokenizer_class.from_pretrained(
+ pretrained_name, additional_special_tokens=added_tokens, **kwargs
+ )
+
+ nodes = "Hey this is a token".split()
+ xpaths = ["html/body" for _ in range(len(nodes))]
+
+ p_output = tokenizer_p.encode(nodes, xpaths=xpaths)
+ cr_output = tokenizer_cr.encode(nodes, xpaths=xpaths)
+
+ self.assertEqual(p_output, r_output)
+ self.assertEqual(cr_output, r_output)
+ self.assertTrue(special_token_id in p_output)
+ self.assertTrue(special_token_id in cr_output)
+
+ def test_training_new_tokenizer(self):
+ # This feature only exists for fast tokenizers
+ if not self.test_rust_tokenizer:
+ return
+
+ tokenizer = self.get_rust_tokenizer()
+ new_tokenizer = tokenizer.train_new_from_iterator(SMALL_TRAINING_CORPUS, 100)
+
+ # Test we can use the new tokenizer with something not seen during training
+ text = [["this", "is", "the"], ["how", "are", "you"]]
+ xpaths = [["html/body"] * 3, ["html/body"] * 3]
+ inputs = new_tokenizer(text, xpaths=xpaths)
+ self.assertEqual(len(inputs["input_ids"]), 2)
+ decoded_input = new_tokenizer.decode(inputs["input_ids"][0], skip_special_tokens=True)
+ expected_result = ( # original expected result "this is the" seems contradicts to roberta-based tokenizer
+ "thisisthe"
+ )
+
+ if tokenizer.backend_tokenizer.normalizer is not None:
+ expected_result = tokenizer.backend_tokenizer.normalizer.normalize_str(expected_result)
+ self.assertEqual(expected_result, decoded_input)
+
+ # We check that the parameters of the tokenizer remained the same
+ # Check we have the same number of added_tokens for both pair and non-pair inputs.
+ self.assertEqual(tokenizer.num_special_tokens_to_add(False), new_tokenizer.num_special_tokens_to_add(False))
+ self.assertEqual(tokenizer.num_special_tokens_to_add(True), new_tokenizer.num_special_tokens_to_add(True))
+
+ # Check we have the correct max_length for both pair and non-pair inputs.
+ self.assertEqual(tokenizer.max_len_single_sentence, new_tokenizer.max_len_single_sentence)
+ self.assertEqual(tokenizer.max_len_sentences_pair, new_tokenizer.max_len_sentences_pair)
+
+ # Assert the set of special tokens match as we didn't ask to change them
+ self.assertSequenceEqual(
+ tokenizer.all_special_tokens_extended,
+ new_tokenizer.all_special_tokens_extended,
+ )
+
+ self.assertDictEqual(tokenizer.special_tokens_map, new_tokenizer.special_tokens_map)
+
+ def test_training_new_tokenizer_with_special_tokens_change(self):
+ # This feature only exists for fast tokenizers
+ if not self.test_rust_tokenizer:
+ return
+
+ tokenizer = self.get_rust_tokenizer()
+ # Test with a special tokens map
+ class_signature = inspect.signature(tokenizer.__class__)
+ if "cls_token" in class_signature.parameters:
+ new_tokenizer = tokenizer.train_new_from_iterator(
+ SMALL_TRAINING_CORPUS, 100, special_tokens_map={tokenizer.cls_token: ""}
+ )
+ cls_id = new_tokenizer.get_vocab()[""]
+ self.assertEqual(new_tokenizer.cls_token, "")
+ self.assertEqual(new_tokenizer.cls_token_id, cls_id)
+
+ # Create a new mapping from the special tokens defined in the original tokenizer
+ special_tokens_list = SpecialTokensMixin.SPECIAL_TOKENS_ATTRIBUTES.copy()
+ special_tokens_list.remove("additional_special_tokens")
+ special_tokens_map = {}
+ for token in special_tokens_list:
+ # Get the private one to avoid unnecessary warnings.
+ if getattr(tokenizer, f"_{token}") is not None:
+ special_token = getattr(tokenizer, token)
+ special_tokens_map[special_token] = f"{special_token}a"
+
+ # Train new tokenizer
+ new_tokenizer = tokenizer.train_new_from_iterator(
+ SMALL_TRAINING_CORPUS, 100, special_tokens_map=special_tokens_map
+ )
+
+ # Check the changes
+ for token in special_tokens_list:
+ # Get the private one to avoid unnecessary warnings.
+ if getattr(tokenizer, f"_{token}") is None:
+ continue
+ special_token = getattr(tokenizer, token)
+ if special_token in special_tokens_map:
+ new_special_token = getattr(new_tokenizer, token)
+ self.assertEqual(special_tokens_map[special_token], new_special_token)
+
+ new_id = new_tokenizer.get_vocab()[new_special_token]
+ self.assertEqual(getattr(new_tokenizer, f"{token}_id"), new_id)
+
+ # Check if the AddedToken / string format has been kept
+ for special_token in tokenizer.all_special_tokens_extended:
+ if isinstance(special_token, AddedToken) and special_token.content not in special_tokens_map:
+ # The special token must appear identically in the list of the new tokenizer.
+ self.assertTrue(
+ special_token in new_tokenizer.all_special_tokens_extended,
+ f"'{special_token}' should be in {new_tokenizer.all_special_tokens_extended}",
+ )
+ elif isinstance(special_token, AddedToken):
+ # The special token must appear in the list of the new tokenizer as an object of type AddedToken with
+ # the same parameters as the old AddedToken except the content that the user has requested to change.
+ special_token_str = special_token.content
+ new_special_token_str = special_tokens_map[special_token_str]
+
+ find = False
+ for candidate in new_tokenizer.all_special_tokens_extended:
+ if (
+ isinstance(candidate, AddedToken)
+ and candidate.content == new_special_token_str
+ and candidate.lstrip == special_token.lstrip
+ and candidate.rstrip == special_token.rstrip
+ and candidate.normalized == special_token.normalized
+ and candidate.single_word == special_token.single_word
+ ):
+ find = True
+ break
+ self.assertTrue(
+ find,
+ f"'{new_special_token_str}' doesn't appear in the list "
+ f"'{new_tokenizer.all_special_tokens_extended}' as an AddedToken with the same parameters as "
+ f"'{special_token}' in the list {tokenizer.all_special_tokens_extended}",
+ )
+ elif special_token not in special_tokens_map:
+ # The special token must appear identically in the list of the new tokenizer.
+ self.assertTrue(
+ special_token in new_tokenizer.all_special_tokens_extended,
+ f"'{special_token}' should be in {new_tokenizer.all_special_tokens_extended}",
+ )
+
+ else:
+ # The special token must appear in the list of the new tokenizer as an object of type string.
+ self.assertTrue(special_tokens_map[special_token] in new_tokenizer.all_special_tokens_extended)
+
+ # Test we can use the new tokenizer with something not seen during training
+ nodes = [["this", "is"], ["hello", "🤗"]]
+ xpaths = [["html/body"] * 2, ["html/body"] * 2]
+ inputs = new_tokenizer(nodes, xpaths=xpaths)
+ self.assertEqual(len(inputs["input_ids"]), 2)
+ decoded_input = new_tokenizer.decode(inputs["input_ids"][0], skip_special_tokens=True)
+ expected_result = "thisis" # same as line 1399
+
+ if tokenizer.backend_tokenizer.normalizer is not None:
+ expected_result = tokenizer.backend_tokenizer.normalizer.normalize_str(expected_result)
+ self.assertEqual(expected_result, decoded_input)
+
+ def test_prepare_for_model(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ # only test prepare_for_model for the slow tokenizer
+ if tokenizer.__class__.__name__ == "MarkupLMTokenizerFast":
+ continue
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ prepared_input_dict = tokenizer.prepare_for_model(nodes, xpaths=xpaths, add_special_tokens=True)
+
+ input_dict = tokenizer.encode_plus(nodes, xpaths=xpaths, add_special_tokens=True)
+
+ self.assertEqual(input_dict, prepared_input_dict)
+
+ def test_padding_different_model_input_name(self):
+ if not self.test_slow_tokenizer:
+ # as we don't have a slow version, we can't compare the outputs between slow and fast versions
+ return
+
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ tokenizer_r = self.rust_tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+ tokenizer_p = self.tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+ self.assertEqual(tokenizer_p.pad_token_id, tokenizer_r.pad_token_id)
+ pad_token_id = tokenizer_p.pad_token_id
+
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+
+ input_r = tokenizer_r.batch_encode_plus(nodes, xpaths=xpaths)
+ input_p = tokenizer_r.batch_encode_plus(nodes, xpaths=xpaths)
+
+ # rename encoded batch to "inputs"
+ input_r["inputs"] = input_r[tokenizer_r.model_input_names[0]]
+ del input_r[tokenizer_r.model_input_names[0]]
+
+ input_p["inputs"] = input_p[tokenizer_p.model_input_names[0]]
+ del input_p[tokenizer_p.model_input_names[0]]
+
+ # Renaming `input_ids` to `inputs`
+ tokenizer_r.model_input_names = ["inputs"] + tokenizer_r.model_input_names[1:]
+ tokenizer_p.model_input_names = ["inputs"] + tokenizer_p.model_input_names[1:]
+
+ input_r = tokenizer_r.pad(input_r, padding="longest")
+ input_p = tokenizer_r.pad(input_p, padding="longest")
+
+ max_length = len(input_p["inputs"][0])
+ self.assert_batch_padded_input_match(
+ input_r, input_p, max_length, pad_token_id, model_main_input_name="inputs"
+ )
+
+ def test_batch_encode_dynamic_overflowing(self):
+ """
+ When calling batch_encode with multiple sequences, it can return different number of
+ overflowing encoding for each sequence:
+ [
+ Sequence 1: [Encoding 1, Encoding 2],
+ Sequence 2: [Encoding 1],
+ Sequence 3: [Encoding 1, Encoding 2, ... Encoding N]
+ ]
+ This needs to be padded so that it can represented as a tensor
+ """
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ tokenizer = self.rust_tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name}, {tokenizer.__class__.__name__})"):
+ if is_torch_available():
+ returned_tensor = "pt"
+ elif is_tf_available():
+ returned_tensor = "tf"
+ else:
+ returned_tensor = "jax"
+
+ # Single example
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ tokens = tokenizer.encode_plus(
+ nodes,
+ xpaths=xpaths,
+ max_length=1,
+ padding=True,
+ truncation=True,
+ return_tensors=returned_tensor,
+ return_overflowing_tokens=True,
+ )
+
+ for key in filter(lambda x: "overflow_to_sample_mapping" not in x, tokens.keys()):
+ if "xpath" not in key:
+ self.assertEqual(len(tokens[key].shape), 2)
+ else:
+ self.assertEqual(len(tokens[key].shape), 3)
+
+ # Batch of examples
+ # For these 2 examples, 3 training examples will be created
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+ tokens = tokenizer.batch_encode_plus(
+ nodes,
+ xpaths=xpaths,
+ max_length=6,
+ padding=True,
+ truncation="only_first",
+ return_tensors=returned_tensor,
+ return_overflowing_tokens=True,
+ )
+
+ for key in filter(lambda x: "overflow_to_sample_mapping" not in x, tokens.keys()):
+ if "xpath" not in key:
+ self.assertEqual(len(tokens[key].shape), 2)
+ self.assertEqual(tokens[key].shape[-1], 6)
+ else:
+ self.assertEqual(len(tokens[key].shape), 3)
+ self.assertEqual(tokens[key].shape[-2], 6)
+
+ @unittest.skip("TO DO: overwrite this very extensive test.")
+ def test_alignement_methods(self):
+ pass
+
+ def get_clean_sequence(self, tokenizer, with_prefix_space=False, max_length=20, min_length=5):
+ toks = [(i, tokenizer.decode([i], clean_up_tokenization_spaces=False)) for i in range(len(tokenizer))]
+ toks = list(filter(lambda t: re.match(r"^[ a-zA-Z]+$", t[1]), toks))
+ toks = list(
+ filter(
+ lambda t: [t[0]]
+ == tokenizer.encode(t[1].split(" "), xpaths=len(t[1]) * ["html/body"], add_special_tokens=False),
+ toks,
+ )
+ )
+ if max_length is not None and len(toks) > max_length:
+ toks = toks[:max_length]
+ if min_length is not None and len(toks) < min_length and len(toks) > 0:
+ while len(toks) < min_length:
+ toks = toks + toks
+ # toks_str = [t[1] for t in toks]
+ toks_ids = [t[0] for t in toks]
+
+ # Ensure consistency
+ output_txt = tokenizer.decode(toks_ids, clean_up_tokenization_spaces=False)
+ # an extra blank will cause inconsistency: ["a","b",] & "a b"
+ """
+ if " " not in output_txt and len(toks_ids) > 1:
+ output_txt = (
+ tokenizer.decode([toks_ids[0]], clean_up_tokenization_spaces=False)
+ + " "
+ + tokenizer.decode(toks_ids[1:], clean_up_tokenization_spaces=False)
+ )
+ """
+ if with_prefix_space:
+ output_txt = " " + output_txt
+ nodes = output_txt.split(" ")
+ xpaths = ["html/body" for i in range(len(nodes))]
+ output_ids = tokenizer.encode(nodes, xpaths=xpaths, add_special_tokens=False)
+ return nodes, xpaths, output_ids
+
+ def test_maximum_encoding_length_pair_input(self):
+ # slow part fixed, fast part not
+ tokenizers = self.get_tokenizers(do_lower_case=False, model_max_length=100)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ # Build a sequence from our model's vocabulary
+ stride = 2
+ seq_0, xpaths_0, ids = self.get_clean_sequence(tokenizer, max_length=20)
+ question_0 = " ".join(map(str, seq_0))
+ if len(ids) <= 2 + stride:
+ seq_0 = (seq_0 + " ") * (2 + stride)
+ ids = None
+
+ seq0_tokens = tokenizer(seq_0, xpaths=xpaths_0, add_special_tokens=False)
+ self.assertGreater(len(seq0_tokens["input_ids"]), 2 + stride)
+ question_1 = "This is another sentence to be encoded."
+ seq_1 = ["hello", "world"]
+ xpaths_1 = ["html/body" for i in range(len(seq_1))]
+ seq1_tokens = tokenizer(seq_1, xpaths=xpaths_1, add_special_tokens=False)
+ if abs(len(seq0_tokens["input_ids"]) - len(seq1_tokens["input_ids"])) <= 2:
+ seq1_tokens_input_ids = seq1_tokens["input_ids"] + seq1_tokens["input_ids"]
+ seq_1 = tokenizer.decode(seq1_tokens_input_ids, clean_up_tokenization_spaces=False)
+ seq_1 = seq_1.split(" ")
+ xpaths_1 = ["html/body" for i in range(len(seq_1))]
+ seq1_tokens = tokenizer(seq_1, xpaths=xpaths_1, add_special_tokens=False)
+
+ self.assertGreater(len(seq1_tokens["input_ids"]), 2 + stride)
+
+ smallest = (
+ seq1_tokens["input_ids"]
+ if len(seq0_tokens["input_ids"]) > len(seq1_tokens["input_ids"])
+ else seq0_tokens["input_ids"]
+ )
+
+ # We are not using the special tokens - a bit too hard to test all the tokenizers with this
+ # TODO try this again later
+ sequence = tokenizer(question_0, seq_1, xpaths=xpaths_1, add_special_tokens=False)
+
+ # Test with max model input length
+ model_max_length = tokenizer.model_max_length
+ self.assertEqual(model_max_length, 100)
+ seq_2 = seq_0 * model_max_length
+ question_2 = " ".join(map(str, seq_2))
+ xpaths_2 = xpaths_0 * model_max_length
+ # assertgreater -> assertgreaterequal
+ self.assertGreaterEqual(len(seq_2), model_max_length)
+
+ sequence1 = tokenizer(seq_1, xpaths=xpaths_1, add_special_tokens=False)
+ total_length1 = len(sequence1["input_ids"])
+ sequence2 = tokenizer(question_2, seq_1, xpaths=xpaths_1, add_special_tokens=False)
+ total_length2 = len(sequence2["input_ids"])
+ self.assertLess(total_length1, model_max_length, "Issue with the testing sequence, please update it.")
+ self.assertGreater(
+ total_length2, model_max_length, "Issue with the testing sequence, please update it."
+ )
+
+ # Simple
+ padding_strategies = (
+ [False, True, "longest"] if tokenizer.pad_token and tokenizer.pad_token_id >= 0 else [False]
+ )
+ for padding_state in padding_strategies:
+ with self.subTest(f"{tokenizer.__class__.__name__} Padding: {padding_state}"):
+ for truncation_state in [True, "longest_first", "only_first"]:
+ with self.subTest(f"{tokenizer.__class__.__name__} Truncation: {truncation_state}"):
+ output = tokenizer(
+ question_2,
+ seq_1,
+ xpaths=xpaths_1,
+ padding=padding_state,
+ truncation=truncation_state,
+ )
+ self.assertEqual(len(output["input_ids"]), model_max_length)
+ self.assertEqual(len(output["xpath_tags_seq"]), model_max_length)
+ self.assertEqual(len(output["xpath_subs_seq"]), model_max_length)
+
+ output = tokenizer(
+ [question_2],
+ [seq_1],
+ xpaths=[xpaths_1],
+ padding=padding_state,
+ truncation=truncation_state,
+ )
+ self.assertEqual(len(output["input_ids"][0]), model_max_length)
+ self.assertEqual(len(output["xpath_tags_seq"][0]), model_max_length)
+ self.assertEqual(len(output["xpath_subs_seq"][0]), model_max_length)
+
+ # Simple
+ output = tokenizer(
+ question_1, seq_2, xpaths=xpaths_2, padding=padding_state, truncation="only_second"
+ )
+ self.assertEqual(len(output["input_ids"]), model_max_length)
+ self.assertEqual(len(output["xpath_tags_seq"]), model_max_length)
+ self.assertEqual(len(output["xpath_subs_seq"]), model_max_length)
+
+ output = tokenizer(
+ [question_1], [seq_2], xpaths=[xpaths_2], padding=padding_state, truncation="only_second"
+ )
+ self.assertEqual(len(output["input_ids"][0]), model_max_length)
+ self.assertEqual(len(output["xpath_tags_seq"][0]), model_max_length)
+ self.assertEqual(len(output["xpath_subs_seq"][0]), model_max_length)
+
+ # Simple with no truncation
+ # Reset warnings
+ tokenizer.deprecation_warnings = {}
+ with self.assertLogs("transformers", level="WARNING") as cm:
+ output = tokenizer(
+ question_1, seq_2, xpaths=xpaths_2, padding=padding_state, truncation=False
+ )
+ self.assertNotEqual(len(output["input_ids"]), model_max_length)
+ self.assertNotEqual(len(output["xpath_tags_seq"]), model_max_length)
+ self.assertNotEqual(len(output["xpath_subs_seq"]), model_max_length)
+ self.assertEqual(len(cm.records), 1)
+ self.assertTrue(
+ cm.records[0].message.startswith(
+ "Token indices sequence length is longer than the specified maximum sequence length"
+ " for this model"
+ )
+ )
+
+ tokenizer.deprecation_warnings = {}
+ with self.assertLogs("transformers", level="WARNING") as cm:
+ output = tokenizer(
+ [question_1], [seq_2], xpaths=[xpaths_2], padding=padding_state, truncation=False
+ )
+ self.assertNotEqual(len(output["input_ids"][0]), model_max_length)
+ self.assertNotEqual(len(output["xpath_tags_seq"][0]), model_max_length)
+ self.assertNotEqual(len(output["xpath_subs_seq"][0]), model_max_length)
+ self.assertEqual(len(cm.records), 1)
+ self.assertTrue(
+ cm.records[0].message.startswith(
+ "Token indices sequence length is longer than the specified maximum sequence length"
+ " for this model"
+ )
+ )
+ # Check the order of Sequence of input ids, overflowing tokens and xpath_tags_seq sequence with truncation
+ truncated_first_sequence = (
+ tokenizer(seq_0, xpaths=xpaths_0, add_special_tokens=False)["input_ids"][:-2]
+ + tokenizer(seq_1, xpaths=xpaths_1, add_special_tokens=False)["input_ids"]
+ )
+ truncated_second_sequence = (
+ tokenizer(seq_0, xpaths=xpaths_0, add_special_tokens=False)["input_ids"]
+ + tokenizer(seq_1, xpaths=xpaths_1, add_special_tokens=False)["input_ids"][:-2]
+ )
+ truncated_longest_sequence = (
+ truncated_first_sequence if len(seq0_tokens) > len(seq1_tokens) else truncated_second_sequence
+ )
+
+ overflow_first_sequence = (
+ tokenizer(seq_0, xpaths=xpaths_0, add_special_tokens=False)["input_ids"][-(2 + stride) :]
+ + tokenizer(seq_1, xpaths=xpaths_1, add_special_tokens=False)["input_ids"]
+ )
+ overflow_second_sequence = (
+ tokenizer(seq_0, xpaths=xpaths_0, add_special_tokens=False)["input_ids"]
+ + tokenizer(seq_1, xpaths=xpaths_1, add_special_tokens=False)["input_ids"][-(2 + stride) :]
+ )
+ overflow_longest_sequence = (
+ overflow_first_sequence if len(seq0_tokens) > len(seq1_tokens) else overflow_second_sequence
+ )
+
+ xpath_tags_seq_first = [[5] * 50] * (
+ len(tokenizer(seq_0, xpaths=xpaths_0, add_special_tokens=False)["input_ids"]) - 2
+ )
+ xpath_tags_seq_first_sequence = (
+ xpath_tags_seq_first
+ + tokenizer(seq_1, xpaths=xpaths_1, add_special_tokens=False)["xpath_tags_seq"]
+ )
+ overflowing_token_xpath_tags_seq_first_sequence_slow = [[5] * 50] * (2 + stride)
+ overflowing_token_xpath_tags_seq_first_sequence_fast = [[5] * 50] * (2 + stride) + tokenizer(
+ seq_1, xpaths=xpaths_1, add_special_tokens=False
+ )["xpath_tags_seq"]
+
+ xpath_tags_seq_second = [[5] * 50] * len(
+ tokenizer(seq_0, xpaths=xpaths_0, add_special_tokens=False)["input_ids"]
+ )
+ xpath_tags_seq_second_sequence = (
+ xpath_tags_seq_second
+ + tokenizer(seq_1, xpaths=xpaths_1, add_special_tokens=False)["xpath_tags_seq"][:-2]
+ )
+ overflowing_token_xpath_tags_seq_second_sequence_slow = tokenizer(
+ seq_1, xpaths=xpaths_1, add_special_tokens=False
+ )["xpath_tags_seq"][-(2 + stride) :]
+ overflowing_token_xpath_tags_seq_second_sequence_fast = [[5] * 50] * len(
+ tokenizer(seq_0, xpaths=xpaths_0, add_special_tokens=False)["input_ids"]
+ ) + tokenizer(seq_1, xpaths=xpaths_1, add_special_tokens=False)["xpath_tags_seq"][-(2 + stride) :]
+
+ xpath_tags_seq_longest_sequence = (
+ xpath_tags_seq_first_sequence
+ if len(seq0_tokens) > len(seq1_tokens)
+ else xpath_tags_seq_second_sequence
+ )
+ overflowing_token_xpath_tags_seq_longest_sequence_fast = (
+ overflowing_token_xpath_tags_seq_first_sequence_fast
+ if len(seq0_tokens) > len(seq1_tokens)
+ else overflowing_token_xpath_tags_seq_second_sequence_fast
+ )
+
+ # Overflowing tokens are handled quite differently in slow and fast tokenizers
+ if isinstance(tokenizer, MarkupLMTokenizerFast):
+ information = tokenizer(
+ question_0,
+ seq_1,
+ xpaths=xpaths_1,
+ max_length=len(sequence["input_ids"]) - 2,
+ add_special_tokens=False,
+ stride=stride,
+ truncation="longest_first",
+ return_overflowing_tokens=True,
+ # add_prefix_space=False,
+ )
+ truncated_sequence = information["input_ids"][0]
+ overflowing_tokens = information["input_ids"][1]
+ xpath_tags_seq = information["xpath_tags_seq"][0]
+ overflowing_xpath_tags_seq = information["xpath_tags_seq"][1]
+ self.assertEqual(len(information["input_ids"]), 2)
+
+ self.assertEqual(len(truncated_sequence), len(sequence["input_ids"]) - 2)
+ self.assertEqual(truncated_sequence, truncated_longest_sequence)
+
+ self.assertEqual(len(overflowing_tokens), 2 + stride + len(smallest))
+ self.assertEqual(overflowing_tokens, overflow_longest_sequence)
+ self.assertEqual(xpath_tags_seq, xpath_tags_seq_longest_sequence)
+
+ self.assertEqual(len(overflowing_xpath_tags_seq), 2 + stride + len(smallest))
+ self.assertEqual(
+ overflowing_xpath_tags_seq, overflowing_token_xpath_tags_seq_longest_sequence_fast
+ )
+ else:
+ # No overflowing tokens when using 'longest' in python tokenizers
+ with self.assertRaises(ValueError) as context:
+ information = tokenizer(
+ question_0,
+ seq_1,
+ xpaths=xpaths_1,
+ max_length=len(sequence["input_ids"]) - 2,
+ add_special_tokens=False,
+ stride=stride,
+ truncation="longest_first",
+ return_overflowing_tokens=True,
+ # add_prefix_space=False,
+ )
+
+ self.assertTrue(
+ context.exception.args[0].startswith(
+ "Not possible to return overflowing tokens for pair of sequences with the "
+ "`longest_first`. Please select another truncation strategy than `longest_first`, "
+ "for instance `only_second` or `only_first`."
+ )
+ )
+
+ # Overflowing tokens are handled quite differently in slow and fast tokenizers
+ if isinstance(tokenizer, MarkupLMTokenizerFast):
+ information = tokenizer(
+ question_0,
+ seq_1,
+ xpaths=xpaths_1,
+ max_length=len(sequence["input_ids"]) - 2,
+ add_special_tokens=False,
+ stride=stride,
+ truncation=True,
+ return_overflowing_tokens=True,
+ )
+ truncated_sequence = information["input_ids"][0]
+ overflowing_tokens = information["input_ids"][1]
+ xpath_tags_seq = information["xpath_tags_seq"][0]
+ overflowing_xpath_tags_seq = information["xpath_tags_seq"][1]
+ self.assertEqual(len(information["input_ids"]), 2)
+
+ self.assertEqual(len(truncated_sequence), len(sequence["input_ids"]) - 2)
+ self.assertEqual(truncated_sequence, truncated_longest_sequence)
+
+ self.assertEqual(len(overflowing_tokens), 2 + stride + len(smallest))
+ self.assertEqual(overflowing_tokens, overflow_longest_sequence)
+ self.assertEqual(xpath_tags_seq, xpath_tags_seq_longest_sequence)
+ self.assertEqual(
+ overflowing_xpath_tags_seq, overflowing_token_xpath_tags_seq_longest_sequence_fast
+ )
+ else:
+ # No overflowing tokens when using 'longest' in python tokenizers
+ with self.assertRaises(ValueError) as context:
+ information = tokenizer(
+ question_0,
+ seq_1,
+ xpaths=xpaths_1,
+ max_length=len(sequence["input_ids"]) - 2,
+ add_special_tokens=False,
+ stride=stride,
+ truncation=True,
+ return_overflowing_tokens=True,
+ )
+
+ self.assertTrue(
+ context.exception.args[0].startswith(
+ "Not possible to return overflowing tokens for pair of sequences with the "
+ "`longest_first`. Please select another truncation strategy than `longest_first`, "
+ "for instance `only_second` or `only_first`."
+ )
+ )
+
+ information_first_truncated = tokenizer(
+ question_0,
+ seq_1,
+ xpaths=xpaths_1,
+ max_length=len(sequence["input_ids"]) - 2,
+ add_special_tokens=False,
+ stride=stride,
+ truncation="only_first",
+ return_overflowing_tokens=True,
+ )
+ # Overflowing tokens are handled quite differently in slow and fast tokenizers
+ if isinstance(tokenizer, MarkupLMTokenizerFast):
+ truncated_sequence = information_first_truncated["input_ids"][0]
+ overflowing_tokens = information_first_truncated["input_ids"][1]
+ xpath_tags_seq = information_first_truncated["xpath_tags_seq"][0]
+ overflowing_xpath_tags_seq = information_first_truncated["xpath_tags_seq"][1]
+ self.assertEqual(len(information_first_truncated["input_ids"]), 2)
+
+ self.assertEqual(len(truncated_sequence), len(sequence["input_ids"]) - 2)
+ self.assertEqual(truncated_sequence, truncated_first_sequence)
+
+ self.assertEqual(len(overflowing_tokens), 2 + stride + len(seq1_tokens["input_ids"]))
+ self.assertEqual(overflowing_tokens, overflow_first_sequence)
+ self.assertEqual(xpath_tags_seq, xpath_tags_seq_first_sequence)
+ # ISSUE HAPPENS HERE ↓
+ self.assertEqual(overflowing_xpath_tags_seq, overflowing_token_xpath_tags_seq_first_sequence_fast)
+ else:
+ truncated_sequence = information_first_truncated["input_ids"]
+ overflowing_tokens = information_first_truncated["overflowing_tokens"]
+ overflowing_xpath_tags_seq = information_first_truncated["overflowing_xpath_tags_seq"]
+ xpath_tags_seq = information_first_truncated["xpath_tags_seq"]
+
+ self.assertEqual(len(truncated_sequence), len(sequence["input_ids"]) - 2)
+ self.assertEqual(truncated_sequence, truncated_first_sequence)
+
+ self.assertEqual(len(overflowing_tokens), 2 + stride)
+ self.assertEqual(overflowing_tokens, seq0_tokens["input_ids"][-(2 + stride) :])
+ self.assertEqual(xpath_tags_seq, xpath_tags_seq_first_sequence)
+ self.assertEqual(overflowing_xpath_tags_seq, overflowing_token_xpath_tags_seq_first_sequence_slow)
+
+ information_second_truncated = tokenizer(
+ question_0,
+ seq_1,
+ xpaths=xpaths_1,
+ max_length=len(sequence["input_ids"]) - 2,
+ add_special_tokens=False,
+ stride=stride,
+ truncation="only_second",
+ return_overflowing_tokens=True,
+ # add_prefix_space=False,
+ )
+ # Overflowing tokens are handled quite differently in slow and fast tokenizers
+ if isinstance(tokenizer, MarkupLMTokenizerFast):
+ truncated_sequence = information_second_truncated["input_ids"][0]
+ overflowing_tokens = information_second_truncated["input_ids"][1]
+ xpath_tags_seq = information_second_truncated["xpath_tags_seq"][0]
+ overflowing_xpath_tags_seq = information_second_truncated["xpath_tags_seq"][1]
+
+ self.assertEqual(len(information_second_truncated["input_ids"]), 2)
+
+ self.assertEqual(len(truncated_sequence), len(sequence["input_ids"]) - 2)
+ self.assertEqual(truncated_sequence, truncated_second_sequence)
+
+ self.assertEqual(len(overflowing_tokens), 2 + stride + len(seq0_tokens["input_ids"]))
+ self.assertEqual(overflowing_tokens, overflow_second_sequence)
+ self.assertEqual(xpath_tags_seq, xpath_tags_seq_second_sequence)
+ self.assertEqual(overflowing_xpath_tags_seq, overflowing_token_xpath_tags_seq_second_sequence_fast)
+ else:
+ truncated_sequence = information_second_truncated["input_ids"]
+ overflowing_tokens = information_second_truncated["overflowing_tokens"]
+ xpath_tags_seq = information_second_truncated["xpath_tags_seq"]
+ overflowing_xpath_tags_seq = information_second_truncated["overflowing_xpath_tags_seq"]
+
+ self.assertEqual(len(truncated_sequence), len(sequence["input_ids"]) - 2)
+ self.assertEqual(truncated_sequence, truncated_second_sequence)
+
+ self.assertEqual(len(overflowing_tokens), 2 + stride)
+ self.assertEqual(overflowing_tokens, seq1_tokens["input_ids"][-(2 + stride) :])
+ self.assertEqual(xpath_tags_seq, xpath_tags_seq_second_sequence)
+ self.assertEqual(overflowing_xpath_tags_seq, overflowing_token_xpath_tags_seq_second_sequence_slow)
+
+ def test_maximum_encoding_length_single_input(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False, model_max_length=100)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ seq_0, xpaths_0, ids = self.get_clean_sequence(tokenizer, max_length=20)
+
+ sequence = tokenizer(seq_0, xpaths=xpaths_0, add_special_tokens=False)
+ total_length = len(sequence["input_ids"])
+
+ self.assertGreater(total_length, 4, "Issue with the testing sequence, please update it it's too short")
+
+ # Test with max model input length
+ model_max_length = tokenizer.model_max_length
+ self.assertEqual(model_max_length, 100)
+ seq_1 = seq_0 * model_max_length
+ xpaths_1 = xpaths_0 * model_max_length
+ sequence1 = tokenizer(seq_1, xpaths=xpaths_1, add_special_tokens=False)
+ total_length1 = len(sequence1["input_ids"])
+ self.assertGreater(
+ total_length1, model_max_length, "Issue with the testing sequence, please update it it's too short"
+ )
+
+ # Simple
+ padding_strategies = (
+ [False, True, "longest"] if tokenizer.pad_token and tokenizer.pad_token_id >= 0 else [False]
+ )
+ for padding_state in padding_strategies:
+ with self.subTest(f"Padding: {padding_state}"):
+ for truncation_state in [True, "longest_first", "only_first"]:
+ with self.subTest(f"Truncation: {truncation_state}"):
+ output = tokenizer(
+ seq_1,
+ xpaths=xpaths_1,
+ padding=padding_state,
+ truncation=truncation_state,
+ )
+ self.assertEqual(len(output["input_ids"]), model_max_length)
+ self.assertEqual(len(output["xpath_tags_seq"]), model_max_length)
+ self.assertEqual(len(output["xpath_subs_seq"]), model_max_length)
+
+ output = tokenizer(
+ [seq_1],
+ xpaths=[xpaths_1],
+ padding=padding_state,
+ truncation=truncation_state,
+ )
+ self.assertEqual(len(output["input_ids"][0]), model_max_length)
+ self.assertEqual(len(output["xpath_tags_seq"][0]), model_max_length)
+ self.assertEqual(len(output["xpath_subs_seq"][0]), model_max_length)
+
+ # Simple with no truncation
+ # Reset warnings
+ tokenizer.deprecation_warnings = {}
+ with self.assertLogs("transformers", level="WARNING") as cm:
+ output = tokenizer(seq_1, xpaths=xpaths_1, padding=padding_state, truncation=False)
+ self.assertNotEqual(len(output["input_ids"]), model_max_length)
+ self.assertNotEqual(len(output["xpath_tags_seq"]), model_max_length)
+ self.assertNotEqual(len(output["xpath_subs_seq"]), model_max_length)
+ self.assertEqual(len(cm.records), 1)
+ self.assertTrue(
+ cm.records[0].message.startswith(
+ "Token indices sequence length is longer than the specified maximum sequence length"
+ " for this model"
+ )
+ )
+
+ tokenizer.deprecation_warnings = {}
+ with self.assertLogs("transformers", level="WARNING") as cm:
+ output = tokenizer([seq_1], xpaths=[xpaths_1], padding=padding_state, truncation=False)
+ self.assertNotEqual(len(output["input_ids"][0]), model_max_length)
+ self.assertNotEqual(len(output["xpath_tags_seq"][0]), model_max_length)
+ self.assertNotEqual(len(output["xpath_subs_seq"][0]), model_max_length)
+ self.assertEqual(len(cm.records), 1)
+ self.assertTrue(
+ cm.records[0].message.startswith(
+ "Token indices sequence length is longer than the specified maximum sequence length"
+ " for this model"
+ )
+ )
+ # Check the order of Sequence of input ids, overflowing tokens, xpath_tags_seq and xpath_subs_seq sequence with truncation
+ stride = 2
+ information = tokenizer(
+ seq_0,
+ xpaths=xpaths_0,
+ max_length=total_length - 2,
+ add_special_tokens=False,
+ stride=stride,
+ truncation=True,
+ return_overflowing_tokens=True,
+ )
+
+ # Overflowing tokens are handled quite differently in slow and fast tokenizers
+ if isinstance(tokenizer, MarkupLMTokenizerFast):
+ truncated_sequence = information["input_ids"][0]
+ overflowing_tokens = information["input_ids"][1]
+ xpath_tags_seq = information["xpath_tags_seq"][0]
+ overflowing_xpath_tags_seq = information["xpath_tags_seq"][1]
+ self.assertEqual(len(information["input_ids"]), 2)
+
+ self.assertEqual(len(truncated_sequence), total_length - 2)
+ self.assertEqual(truncated_sequence, sequence["input_ids"][:-2])
+
+ self.assertEqual(len(overflowing_tokens), 2 + stride)
+ self.assertEqual(overflowing_tokens, sequence["input_ids"][-(2 + stride) :])
+
+ self.assertEqual(xpath_tags_seq, sequence["xpath_tags_seq"][:-2])
+ self.assertEqual(overflowing_xpath_tags_seq, sequence["xpath_tags_seq"][-(2 + stride) :])
+ else:
+ truncated_sequence = information["input_ids"]
+ overflowing_tokens = information["overflowing_tokens"]
+ xpath_tags_seq = information["xpath_tags_seq"]
+ overflowing_xpath_tags_seq = information["overflowing_xpath_tags_seq"]
+ self.assertEqual(len(truncated_sequence), total_length - 2)
+ self.assertEqual(truncated_sequence, sequence["input_ids"][:-2])
+
+ self.assertEqual(len(overflowing_tokens), 2 + stride)
+ self.assertEqual(overflowing_tokens, sequence["input_ids"][-(2 + stride) :])
+ self.assertEqual(xpath_tags_seq, sequence["xpath_tags_seq"][:-2])
+ self.assertEqual(overflowing_xpath_tags_seq, sequence["xpath_tags_seq"][-(2 + stride) :])
+
+ @unittest.skip("MarkupLM tokenizer requires xpaths besides sequences.")
+ def test_pretokenized_inputs(self):
+ pass
+
+ @unittest.skip("MarkupLM tokenizer always expects pretokenized inputs.")
+ def test_compare_pretokenized_inputs(self):
+ pass
+
+ @unittest.skip("MarkupLM fast tokenizer does not support prepare_for_model")
+ def test_compare_prepare_for_model(self):
+ pass
+
+ @slow
+ def test_only_label_first_subword(self):
+ nodes = ["hello", "niels"]
+ xpaths = ["/html/body/div/li[1]/div/span" for _ in range(len(nodes))]
+ node_labels = [0, 1]
+
+ # test slow tokenizer
+ tokenizer_p = MarkupLMTokenizer.from_pretrained("microsoft/markuplm-base")
+ encoding = tokenizer_p(nodes, xpaths=xpaths, node_labels=node_labels)
+ self.assertListEqual(encoding.labels, [-100, 0, 1, -100, -100])
+
+ tokenizer_p = MarkupLMTokenizer.from_pretrained("microsoft/markuplm-base", only_label_first_subword=False)
+ encoding = tokenizer_p(nodes, xpaths=xpaths, node_labels=node_labels)
+ self.assertListEqual(encoding.labels, [-100, 0, 1, 1, -100])
+
+ # test fast tokenizer
+ tokenizer_r = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
+ encoding = tokenizer_r(nodes, xpaths=xpaths, node_labels=node_labels)
+ self.assertListEqual(encoding.labels, [-100, 0, 1, -100, -100])
+
+ tokenizer_r = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base", only_label_first_subword=False)
+ encoding = tokenizer_r(nodes, xpaths=xpaths, node_labels=node_labels)
+ self.assertListEqual(encoding.labels, [-100, 0, 1, 1, -100])
+
+ def test_markuplm_integration_test(self):
+ tokenizer_p = MarkupLMTokenizer.from_pretrained("microsoft/markuplm-base")
+ tokenizer_r = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
+
+ # There are 3 cases:
+ # CASE 1: document image classification (training + inference), document image token classification (inference),
+ # in which case only nodes and normalized bounding xpaths are provided to the tokenizer
+ # CASE 2: document image token classification (training),
+ # in which case one also provides word labels to the tokenizer
+ # CASE 3: document image visual question answering (inference),
+ # in which case one also provides a question to the tokenizer
+
+ # We need to test all 3 cases both on batched and non-batched inputs.
+
+ # CASE 1: not batched
+ nodes, xpaths = self.get_nodes_and_xpaths()
+
+ # fmt: off
+ expected_results = {'input_ids': [0, 42891, 8331, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'xpath_tags_seq': [[216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216]], 'xpath_subs_seq': [[1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001]], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}
+ # fmt: on
+
+ encoding_p = tokenizer_p(nodes, xpaths=xpaths, padding="max_length", max_length=20)
+ encoding_r = tokenizer_r(nodes, xpaths=xpaths, padding="max_length", max_length=20)
+ self.assertDictEqual(dict(encoding_p), expected_results)
+ self.assertDictEqual(dict(encoding_r), expected_results)
+
+ # CASE 1: batched
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+
+ # fmt: off
+ expected_results = {'input_ids': [[0, 42891, 232, 12364, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 42891, 127, 766, 16, 22401, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'xpath_tags_seq': [[[216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216]], [[216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216]]], 'xpath_subs_seq': [[[1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001]], [[1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001]]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]}
+ # fmt: on
+
+ encoding_p = tokenizer_p(nodes, xpaths=xpaths, padding="max_length", max_length=20)
+ encoding_r = tokenizer_r(nodes, xpaths=xpaths, padding="max_length", max_length=20)
+ self.assertDictEqual(dict(encoding_p), expected_results)
+ self.assertDictEqual(dict(encoding_r), expected_results)
+
+ # CASE 2: not batched
+ nodes, xpaths = self.get_nodes_and_xpaths()
+ node_labels = [1, 2, 3]
+
+ # fmt: off
+ expected_results = {'input_ids': [0, 42891, 8331, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'xpath_tags_seq': [[216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216]], 'xpath_subs_seq': [[1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001]], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'labels': [-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100], 'attention_mask': [1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}
+ # fmt: on
+
+ encoding_p = tokenizer_p(nodes, xpaths=xpaths, node_labels=node_labels, padding="max_length", max_length=20)
+ encoding_r = tokenizer_r(nodes, xpaths=xpaths, node_labels=node_labels, padding="max_length", max_length=20)
+ self.assertDictEqual(dict(encoding_p), expected_results)
+ self.assertDictEqual(dict(encoding_r), expected_results)
+
+ # CASE 2: batched
+ nodes, xpaths = self.get_nodes_and_xpaths_batch()
+ node_labels = [[1, 2, 3], [2, 46, 17, 22, 3]]
+
+ # fmt: off
+ expected_results = {'input_ids': [[0, 42891, 232, 12364, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 42891, 127, 766, 16, 22401, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'xpath_tags_seq': [[[216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216]], [[216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216]]], 'xpath_subs_seq': [[[1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001]], [[1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001]]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'labels': [[-100, 1, -100, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100], [-100, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100]], 'attention_mask': [[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]}
+ # fmt: on
+
+ encoding_p = tokenizer_p(nodes, xpaths=xpaths, node_labels=node_labels, padding="max_length", max_length=20)
+ encoding_r = tokenizer_r(nodes, xpaths=xpaths, node_labels=node_labels, padding="max_length", max_length=20)
+ self.assertDictEqual(dict(encoding_p), expected_results)
+ self.assertDictEqual(dict(encoding_r), expected_results)
+
+ # CASE 3: not batched
+ question, nodes, xpaths = self.get_question_nodes_and_xpaths()
+
+ # fmt: off
+ expected_results = {'input_ids': [0, 12196, 18, 39, 766, 116, 2, 42891, 232, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ 'xpath_tags_seq': [[216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216]], 'xpath_subs_seq': [[1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001]], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}
+ # fmt: on
+
+ encoding_p = tokenizer_p(question, nodes, xpaths, padding="max_length", max_length=20)
+ encoding_r = tokenizer_r(question, nodes, xpaths, padding="max_length", max_length=20)
+ self.assertDictEqual(dict(encoding_p), expected_results)
+ self.assertDictEqual(dict(encoding_r), expected_results)
+
+ # CASE 3: batched
+ questions, nodes, xpaths = self.get_question_nodes_and_xpaths_batch()
+
+ # fmt: off
+ expected_results = {'input_ids': [[0, 12196, 18, 39, 766, 116, 2, 42891, 232, 12364, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 9178, 16, 37, 373, 116, 2, 42891, 127, 766, 16, 22401, 2, 1, 1, 1, 1, 1, 1, 1]],
+ 'xpath_tags_seq': [[[216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216]], [[216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [109, 25, 50, 120, 50, 178, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216], [216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216, 216]]],
+ 'xpath_subs_seq': [[[1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001]], [[1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [109, 25, 50, 120, 50, 178, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001], [1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001, 1001]]],
+ 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]]}
+ # fmt: on
+
+ encoding_p = tokenizer_p(questions, nodes, xpaths, padding="max_length", max_length=20)
+ encoding_r = tokenizer_r(questions, nodes, xpaths, padding="max_length", max_length=20)
+ self.assertDictEqual(dict(encoding_p), expected_results)
+ self.assertDictEqual(dict(encoding_r), expected_results)
+
+ @unittest.skip("Doesn't support another framework than PyTorch")
+ def test_np_encode_plus_sent_to_model(self):
+ pass
+
+ def test_padding_warning_message_fast_tokenizer(self):
+ if not self.test_rust_tokenizer:
+ return
+
+ nodes, xpaths = self.get_nodes_and_xpaths()
+
+ tokenizer_fast = self.get_rust_tokenizer()
+ # check correct behaviour if no pad_token_id exists and add it eventually
+ self._check_no_pad_token_padding(tokenizer_fast, nodes)
+
+ encoding_fast = tokenizer_fast(nodes, xpaths=xpaths)
+
+ with self.assertLogs("transformers", level="WARNING") as cm:
+ tokenizer_fast.pad(encoding_fast)
+ self.assertEqual(len(cm.records), 1)
+ self.assertIn(
+ "Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to"
+ " encode the text followed by a call to the `pad` method to get a padded encoding.",
+ cm.records[0].message,
+ )
+
+ if not self.test_slow_tokenizer:
+ return
+
+ tokenizer_slow = self.get_tokenizer()
+ # check correct behaviour if no pad_token_id exists and add it eventually
+ self._check_no_pad_token_padding(tokenizer_slow, nodes)
+
+ encoding_slow = tokenizer_slow(nodes, xpaths=xpaths)
+
+ with self.assertLogs(level="WARNING") as cm:
+ # We want to assert there are no warnings, but the 'assertLogs' method does not support that.
+ # Therefore, we are adding a dummy warning, and then we will assert it is the only warning.
+ logger.warning("Dummy warning")
+ tokenizer_slow.pad(encoding_slow)
+ self.assertEqual(len(cm.records), 1)
+ self.assertIn(
+ "Dummy warning",
+ cm.records[0].message,
+ )
diff --git a/utils/documentation_tests.txt b/utils/documentation_tests.txt
index eb1570d6c31..06b042c1fc0 100644
--- a/utils/documentation_tests.txt
+++ b/utils/documentation_tests.txt
@@ -3,6 +3,7 @@ docs/source/es/quicktour.mdx
docs/source/en/pipeline_tutorial.mdx
docs/source/en/autoclass_tutorial.mdx
docs/source/en/task_summary.mdx
+docs/source/en/model_doc/markuplm.mdx
docs/source/en/model_doc/speech_to_text.mdx
docs/source/en/model_doc/t5.mdx
docs/source/en/model_doc/t5v1.1.mdx
@@ -51,6 +52,7 @@ src/transformers/models/longformer/modeling_longformer.py
src/transformers/models/longformer/modeling_tf_longformer.py
src/transformers/models/longt5/modeling_longt5.py
src/transformers/models/marian/modeling_marian.py
+src/transformers/models/markuplm/modeling_markuplm.py
src/transformers/models/mbart/modeling_mbart.py
src/transformers/models/mobilebert/modeling_mobilebert.py
src/transformers/models/mobilebert/modeling_tf_mobilebert.py