From a0633c44834e18bdd6a073c4d427e5e870476636 Mon Sep 17 00:00:00 2001
From: Yuki-Imajuku <72183189+Yuki-Imajuku@users.noreply.github.com>
Date: Thu, 16 Nov 2023 03:13:52 +0900
Subject: [PATCH] Translating `en/model_doc` docs to Japanese. (#27401)
* update _toctree.yml & add albert-autoformer
* Fixed typo in docs/source/ja/model_doc/audio-spectrogram-transformer.md
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
* Delete duplicated sentence docs/source/ja/model_doc/autoformer.md
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
* Reflect reviews
* delete untranslated models from toctree
* delete all comments
* add abstract translation
---------
Co-authored-by: Steven Liu <59462357+stevhliu@users.noreply.github.com>
---
.../audio-spectrogram-transformer.md | 4 +-
docs/source/ja/_toctree.yml | 95 ++---
docs/source/ja/model_doc/albert.md | 193 +++++++++
docs/source/ja/model_doc/align.md | 104 +++++
docs/source/ja/model_doc/altclip.md | 97 +++++
.../audio-spectrogram-transformer.md | 69 ++++
docs/source/ja/model_doc/auto.md | 370 ++++++++++++++++++
docs/source/ja/model_doc/autoformer.md | 50 +++
8 files changed, 912 insertions(+), 70 deletions(-)
create mode 100644 docs/source/ja/model_doc/albert.md
create mode 100644 docs/source/ja/model_doc/align.md
create mode 100644 docs/source/ja/model_doc/altclip.md
create mode 100644 docs/source/ja/model_doc/audio-spectrogram-transformer.md
create mode 100644 docs/source/ja/model_doc/auto.md
create mode 100644 docs/source/ja/model_doc/autoformer.md
diff --git a/docs/source/en/model_doc/audio-spectrogram-transformer.md b/docs/source/en/model_doc/audio-spectrogram-transformer.md
index 587ec85d09b..3eac3781667 100644
--- a/docs/source/en/model_doc/audio-spectrogram-transformer.md
+++ b/docs/source/en/model_doc/audio-spectrogram-transformer.md
@@ -29,7 +29,7 @@ The abstract from the paper is the following:
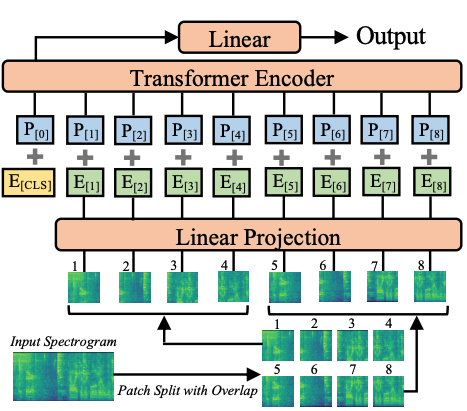 - Audio pectrogram Transformer architecture. Taken from the original paper.
+ Audio Spectrogram Transformer architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/YuanGongND/ast).
@@ -72,4 +72,4 @@ If you're interested in submitting a resource to be included here, please feel f
## ASTForAudioClassification
[[autodoc]] ASTForAudioClassification
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/ja/_toctree.yml b/docs/source/ja/_toctree.yml
index 69169d6fffc..df686b475da 100644
--- a/docs/source/ja/_toctree.yml
+++ b/docs/source/ja/_toctree.yml
@@ -29,77 +29,12 @@
title: LLM を使用した生成
title: Tutorials
- sections:
- - isExpanded: false
- # sections:
- # - local: tasks/sequence_classification
- # title: Text classification
- # - local: tasks/token_classification
- # title: Token classification
- # - local: tasks/question_answering
- # title: Question answering
- # - local: tasks/language_modeling
- # title: Causal language modeling
- # - local: tasks/masked_language_modeling
- # title: Masked language modeling
- # - local: tasks/translation
- # title: Translation
- # - local: tasks/summarization
- # title: Summarization
- # - local: tasks/multiple_choice
- # title: Multiple choice
- # title: Natural Language Processing
- # - isExpanded: false
- # sections:
- # - local: tasks/audio_classification
- # title: Audio classification
- # - local: tasks/asr
- # title: Automatic speech recognition
- # title: Audio
- # - isExpanded: false
- # sections:
- # - local: tasks/image_classification
- # title: Image classification
- # - local: tasks/semantic_segmentation
- # title: Semantic segmentation
- # - local: tasks/video_classification
- # title: Video classification
- # - local: tasks/object_detection
- # title: Object detection
- # - local: tasks/zero_shot_object_detection
- # title: Zero-shot object detection
- # - local: tasks/zero_shot_image_classification
- # title: Zero-shot image classification
- # - local: tasks/monocular_depth_estimation
- # title: Depth estimation
- # - local: tasks/image_to_image
- # title: Image-to-Image
- # - local: tasks/knowledge_distillation_for_image_classification
- # title: Knowledge Distillation for Computer Vision
- # title: Computer Vision
- # - isExpanded: false
- # sections:
- # - local: tasks/image_captioning
- # title: Image captioning
- # - local: tasks/document_question_answering
- # title: Document Question Answering
- # - local: tasks/visual_question_answering
- # title: Visual Question Answering
- # - local: tasks/text-to-speech
- # title: Text to speech
- # title: Multimodal
- isExpanded: false
sections:
- local: generation_strategies
title: 生成戦略をカスタマイズする
title: Generation
- # - isExpanded: false
- # sections:
- # - local: tasks/idefics
- # title: Image tasks with IDEFICS
- # - local: tasks/prompting
- # title: LLM prompting guide
- # title: Prompting
- title: Task Guides
+ title: Task Guides
- sections:
- local: fast_tokenizers
title: 🤗 トークナイザーの高速トークナイザーを使用する
@@ -206,8 +141,8 @@
- sections:
- local: main_classes/agent
title: エージェントとツール
- # - local: model_doc/auto
- # title: Auto Classes
+ - local: model_doc/auto
+ title: Auto Classes
- local: main_classes/callback
title: コールバック
- local: main_classes/configuration
@@ -245,6 +180,30 @@
- local: main_classes/image_processor
title: 画像処理プロセッサ
title: 主要なクラス
+ - sections:
+ - isExpanded: false
+ sections:
+ - local: model_doc/albert
+ title: ALBERT
+ title: 文章モデル
+ - isExpanded: false
+ sections:
+ - local: model_doc/audio-spectrogram-transformer
+ title: Audio Spectrogram Transformer
+ title: 音声モデル
+ - isExpanded: false
+ sections:
+ - local: model_doc/align
+ title: ALIGN
+ - local: model_doc/altclip
+ title: AltCLIP
+ title: マルチモーダルモデル
+ - isExpanded: false
+ sections:
+ - local: model_doc/autoformer
+ title: Autoformer
+ title: 時系列モデル
+ title: モデル
- sections:
- local: internal/modeling_utils
title: カスタムレイヤーとユーティリティ
diff --git a/docs/source/ja/model_doc/albert.md b/docs/source/ja/model_doc/albert.md
new file mode 100644
index 00000000000..00403ea5376
--- /dev/null
+++ b/docs/source/ja/model_doc/albert.md
@@ -0,0 +1,193 @@
+
+
+# ALBERT
+
+
+
+## 概要
+
+ALBERTモデルは、「[ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942)」という論文でZhenzhong Lan、Mingda Chen、Sebastian Goodman、Kevin Gimpel、Piyush Sharma、Radu Soricutによって提案されました。BERTのメモリ消費を減らしトレーニングを高速化するためのパラメータ削減技術を2つ示しています:
+
+- 埋め込み行列を2つの小さな行列に分割する。
+- グループ間で分割された繰り返し層を使用する。
+
+論文の要旨は以下の通りです:
+
+*自然言語表現の事前学習時にモデルのサイズを増やすと、下流タスクのパフォーマンスが向上することがしばしばあります。しかし、ある時点でさらなるモデルの増大は、GPU/TPUのメモリ制限、長い訓練時間、予期せぬモデルの劣化といった問題のために困難になります。これらの問題に対処するために、我々はBERTのメモリ消費を低減し、訓練速度を高めるための2つのパラメータ削減技術を提案します。包括的な実証的証拠は、我々の提案方法が元のBERTに比べてはるかによくスケールするモデルを生み出すことを示しています。また、文間の一貫性をモデリングに焦点を当てた自己教師あり損失を使用し、複数の文が含まれる下流タスクに一貫して助けとなることを示します。その結果、我々の最良のモデルは、BERT-largeに比べてパラメータが少ないにもかかわらず、GLUE、RACE、SQuADベンチマークで新たな最先端の結果を確立します。*
+
+このモデルは[lysandre](https://huggingface.co/lysandre)により提供されました。このモデルのjaxバージョンは[kamalkraj](https://huggingface.co/kamalkraj)により提供されました。オリジナルのコードは[こちら](https://github.com/google-research/ALBERT)で見ることができます。
+
+## 使用上のヒント
+
+- ALBERTは絶対位置埋め込みを使用するモデルなので、通常、入力を左側ではなく右側にパディングすることが推奨されます。
+- ALBERTは繰り返し層を使用するためメモリ使用量は小さくなりますが、同じ数の(繰り返し)層を反復しなければならないため、隠れ層の数が同じであればBERTのようなアーキテクチャと同様の計算コストがかかります。
+- 埋め込みサイズEは隠れサイズHと異なりますが、これは埋め込みが文脈に依存しない(一つの埋め込みベクトルが一つのトークンを表す)のに対し、隠れ状態は文脈に依存する(1つの隠れ状態がトークン系列を表す)ため、H >> Eとすることがより論理的です。また、埋め込み行列のサイズはV x Eと大きいです(Vは語彙サイズ)。E < Hであれば、パラメータは少なくなります。
+- 層はパラメータを共有するグループに分割されています(メモリ節約のため)。次文予測(NSP: Next Sentence Prediction)は文の順序予測に置き換えられます:入力では、2つの文AとB(それらは連続している)があり、Aに続いてBを与えるか、Bに続いてAを与えます。モデルはそれらが入れ替わっているかどうかを予測する必要があります。
+
+## 参考資料
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問応答タスクガイド](../tasks/question_answering)
+- [マスクされた言語モデルタスクガイド](../tasks/masked_language_modeling)
+- [多肢選択タスクガイド](../tasks/multiple_choice)
+
+## AlbertConfig
+
+[[autodoc]] AlbertConfig
+
+## AlbertTokenizer
+
+[[autodoc]] AlbertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## AlbertTokenizerFast
+
+[[autodoc]] AlbertTokenizerFast
+
+## Albert specific outputs
+
+[[autodoc]] models.albert.modeling_albert.AlbertForPreTrainingOutput
+
+[[autodoc]] models.albert.modeling_tf_albert.TFAlbertForPreTrainingOutput
+
+
+
+
+## AlbertModel
+
+[[autodoc]] AlbertModel
+ - forward
+
+## AlbertForPreTraining
+
+[[autodoc]] AlbertForPreTraining
+ - forward
+
+## AlbertForMaskedLM
+
+[[autodoc]] AlbertForMaskedLM
+ - forward
+
+## AlbertForSequenceClassification
+
+[[autodoc]] AlbertForSequenceClassification
+ - forward
+
+## AlbertForMultipleChoice
+
+[[autodoc]] AlbertForMultipleChoice
+
+## AlbertForTokenClassification
+
+[[autodoc]] AlbertForTokenClassification
+ - forward
+
+## AlbertForQuestionAnswering
+
+[[autodoc]] AlbertForQuestionAnswering
+ - forward
+
+
+
+
+
+## TFAlbertModel
+
+[[autodoc]] TFAlbertModel
+ - call
+
+## TFAlbertForPreTraining
+
+[[autodoc]] TFAlbertForPreTraining
+ - call
+
+## TFAlbertForMaskedLM
+
+[[autodoc]] TFAlbertForMaskedLM
+ - call
+
+## TFAlbertForSequenceClassification
+
+[[autodoc]] TFAlbertForSequenceClassification
+ - call
+
+## TFAlbertForMultipleChoice
+
+[[autodoc]] TFAlbertForMultipleChoice
+ - call
+
+## TFAlbertForTokenClassification
+
+[[autodoc]] TFAlbertForTokenClassification
+ - call
+
+## TFAlbertForQuestionAnswering
+
+[[autodoc]] TFAlbertForQuestionAnswering
+ - call
+
+
+
+
+## FlaxAlbertModel
+
+[[autodoc]] FlaxAlbertModel
+ - __call__
+
+## FlaxAlbertForPreTraining
+
+[[autodoc]] FlaxAlbertForPreTraining
+ - __call__
+
+## FlaxAlbertForMaskedLM
+
+[[autodoc]] FlaxAlbertForMaskedLM
+ - __call__
+
+## FlaxAlbertForSequenceClassification
+
+[[autodoc]] FlaxAlbertForSequenceClassification
+ - __call__
+
+## FlaxAlbertForMultipleChoice
+
+[[autodoc]] FlaxAlbertForMultipleChoice
+ - __call__
+
+## FlaxAlbertForTokenClassification
+
+[[autodoc]] FlaxAlbertForTokenClassification
+ - __call__
+
+## FlaxAlbertForQuestionAnswering
+
+[[autodoc]] FlaxAlbertForQuestionAnswering
+ - __call__
+
+
+
diff --git a/docs/source/ja/model_doc/align.md b/docs/source/ja/model_doc/align.md
new file mode 100644
index 00000000000..6e62c3d9f4c
--- /dev/null
+++ b/docs/source/ja/model_doc/align.md
@@ -0,0 +1,104 @@
+
+
+# ALIGN
+
+## 概要
+
+ALIGNモデルは、「[Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918)」という論文でChao Jia、Yinfei Yang、Ye Xia、Yi-Ting Chen、Zarana Parekh、Hieu Pham、Quoc V. Le、Yunhsuan Sung、Zhen Li、Tom Duerigによって提案されました。ALIGNはマルチモーダルな視覚言語モデルです。これは画像とテキストの類似度や、ゼロショット画像分類に使用できます。ALIGNは[EfficientNet](efficientnet)を視覚エンコーダーとして、[BERT](bert)をテキストエンコーダーとして搭載したデュアルエンコーダー構造を特徴とし、対照学習によって視覚とテキストの表現を整合させることを学びます。それまでの研究とは異なり、ALIGNは巨大でノイジーなデータセットを活用し、コーパスのスケールを利用して単純な方法ながら最先端の表現を達成できることを示しています。
+
+論文の要旨は以下の通りです:
+
+*事前学習された表現は、多くの自然言語処理(NLP)および知覚タスクにとって重要になっています。NLPにおける表現学習は、人間のアノテーションのない生のテキストでの学習へと移行していますが、視覚および視覚言語の表現は依然として精巧な学習データセットに大きく依存しており、これは高価であったり専門知識を必要としたりします。視覚アプリケーションの場合、ImageNetやOpenImagesのような明示的なクラスラベルを持つデータセットを使用して学習されることがほとんどです。視覚言語の場合、Conceptual Captions、MSCOCO、CLIPなどの人気のあるデータセットはすべて、それぞれ無視できないデータ収集(およびクリーニング)プロセスを含みます。このコストのかかるキュレーションプロセスはデータセットのサイズを制限し、訓練されたモデルのスケーリングを妨げます。本論文では、Conceptual Captionsデータセットの高価なフィルタリングや後処理ステップなしで得られた、10億を超える画像alt-textペアのノイズの多いデータセットを活用します。シンプルなデュアルエンコーダーアーキテクチャは、対照損失を使用して画像とテキストペアの視覚的および言語的表現を整合させることを学習します。我々は、コーパスの規模がそのノイズを補い、このような単純な学習スキームでも最先端の表現につながることを示します。我々の視覚表現は、ImageNetやVTABなどの分類タスクへの転移において強力な性能を発揮します。整合した視覚的および言語的表現は、ゼロショット画像分類を可能にし、また、より洗練されたクロスアテンションモデルと比較しても、Flickr30KおよびMSCOCO画像テキスト検索ベンチマークにおいて新たな最先端の結果を達成します。また、これらの表現は、複雑なテキストおよびテキスト+画像のクエリを用いたクロスモーダル検索を可能にします。*
+
+このモデルは[Alara Dirik](https://huggingface.co/adirik)により提供されました。
+オリジナルのコードは公開されておらず、この実装は元論文に基づいたKakao Brainの実装をベースにしています。
+
+## 使用例
+
+ALIGNはEfficientNetを使用して視覚的特徴を、BERTを使用してテキスト特徴を取得します。テキストと視覚の両方の特徴は、同一の次元を持つ潜在空間に射影されます。射影された画像とテキスト特徴間のドット積が類似度スコアとして使用されます。
+
+[`AlignProcessor`]は、テキストのエンコードと画像の前処理を両方行うために、[`EfficientNetImageProcessor`]と[`BertTokenizer`]を単一のインスタンスにラップします。以下の例は、[`AlignProcessor`]と[`AlignModel`]を使用して画像-テキスト類似度スコアを取得する方法を示しています。
+
+```python
+import requests
+import torch
+from PIL import Image
+from transformers import AlignProcessor, AlignModel
+
+processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
+model = AlignModel.from_pretrained("kakaobrain/align-base")
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+candidate_labels = ["an image of a cat", "an image of a dog"]
+
+inputs = processor(text=candidate_labels, images=image, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+# これは画像-テキスト類似度スコア
+logits_per_image = outputs.logits_per_image
+
+# Softmaxを取ることで各ラベルの確率を得られる
+probs = logits_per_image.softmax(dim=1)
+print(probs)
+```
+
+## 参考資料
+
+ALIGNの使用を開始するのに役立つ公式のHugging Faceとコミュニティ(🌎で示されている)の参考資料の一覧です。
+
+- [ALIGNとCOYO-700Mデータセット](https://huggingface.co/blog/vit-align)に関するブログ投稿。
+- ゼロショット画像分類[デモ](https://huggingface.co/spaces/adirik/ALIGN-zero-shot-image-classification)。
+- `kakaobrain/align-base` モデルの[モデルカード](https://huggingface.co/kakaobrain/align-base)。
+
+ここに参考資料を提出したい場合は、気兼ねなくPull Requestを開いてください。私たちはそれをレビューいたします!参考資料は、既存のものを複製するのではなく、何か新しいことを示すことが理想的です。
+
+## AlignConfig
+
+[[autodoc]] AlignConfig
+ - from_text_vision_configs
+
+## AlignTextConfig
+
+[[autodoc]] AlignTextConfig
+
+## AlignVisionConfig
+
+[[autodoc]] AlignVisionConfig
+
+## AlignProcessor
+
+[[autodoc]] AlignProcessor
+
+## AlignModel
+
+[[autodoc]] AlignModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## AlignTextModel
+
+[[autodoc]] AlignTextModel
+ - forward
+
+## AlignVisionModel
+
+[[autodoc]] AlignVisionModel
+ - forward
diff --git a/docs/source/ja/model_doc/altclip.md b/docs/source/ja/model_doc/altclip.md
new file mode 100644
index 00000000000..232b3645544
--- /dev/null
+++ b/docs/source/ja/model_doc/altclip.md
@@ -0,0 +1,97 @@
+
+
+# AltCLIP
+
+## 概要
+
+
+AltCLIPモデルは、「[AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679v2)」という論文でZhongzhi Chen、Guang Liu、Bo-Wen Zhang、Fulong Ye、Qinghong Yang、Ledell Wuによって提案されました。AltCLIP(CLIPの言語エンコーダーの代替)は、様々な画像-テキストペアおよびテキスト-テキストペアでトレーニングされたニューラルネットワークです。CLIPのテキストエンコーダーを事前学習済みの多言語テキストエンコーダーXLM-Rに置き換えることで、ほぼ全てのタスクでCLIPに非常に近い性能を得られ、オリジナルのCLIPの能力を多言語理解などに拡張しました。
+
+論文の要旨は以下の通りです:
+
+*この研究では、強力なバイリンガルマルチモーダル表現モデルを訓練するための概念的に単純で効果的な方法を提案します。OpenAIによってリリースされたマルチモーダル表現モデルCLIPから開始し、そのテキストエンコーダを事前学習済みの多言語テキストエンコーダXLM-Rに交換し、教師学習と対照学習からなる2段階のトレーニングスキーマを用いて言語と画像の表現を整合させました。幅広いタスクの評価を通じて、我々の方法を検証します。ImageNet-CN、Flicker30k-CN、COCO-CNを含む多くのタスクで新たな最先端の性能を達成しました。さらに、ほぼすべてのタスクでCLIPに非常に近い性能を得ており、これはCLIPのテキストエンコーダを変更するだけで、多言語理解などの拡張を実現できることを示唆しています。*
+
+このモデルは[jongjyh](https://huggingface.co/jongjyh)により提供されました。
+
+## 使用上のヒントと使用例
+
+AltCLIPの使用方法はCLIPに非常に似ています。CLIPとの違いはテキストエンコーダーにあります。私たちはカジュアルアテンションではなく双方向アテンションを使用し、XLM-Rの[CLS]トークンをテキスト埋め込みを表すものとして取ることに留意してください。
+
+AltCLIPはマルチモーダルな視覚言語モデルです。これは画像とテキストの類似度や、ゼロショット画像分類に使用できます。AltCLIPはViTのようなTransformerを使用して視覚的特徴を、双方向言語モデルを使用してテキスト特徴を取得します。テキストと視覚の両方の特徴は、同一の次元を持つ潜在空間に射影されます。射影された画像とテキスト特徴間のドット積が類似度スコアとして使用されます。
+
+Transformerエンコーダーに画像を与えるには、各画像を固定サイズの重複しないパッチの系列に分割し、それらを線形に埋め込みます。画像全体を表現するための[CLS]トークンが追加されます。著者は絶対位置埋め込みも追加し、結果として得られるベクトルの系列を標準的なTransformerエンコーダーに供給します。[`CLIPImageProcessor`]を使用して、モデルのために画像のサイズ変更(または拡大縮小)と正規化を行うことができます。
+
+[`AltCLIPProcessor`]は、テキストのエンコードと画像の前処理を両方行うために、[`CLIPImageProcessor`]と[`XLMRobertaTokenizer`]を単一のインスタンスにラップします。以下の例は、[`AltCLIPProcessor`]と[`AltCLIPModel`]を使用して画像-テキスト類似スコアを取得する方法を示しています。
+
+```python
+>>> from PIL import Image
+>>> import requests
+
+>>> from transformers import AltCLIPModel, AltCLIPProcessor
+
+>>> model = AltCLIPModel.from_pretrained("BAAI/AltCLIP")
+>>> processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
+
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # これは画像-テキスト類似度スコア
+>>> probs = logits_per_image.softmax(dim=1) # Softmaxを取ることで各ラベルの確率を得られる
+```
+
+
+
+このモデルは`CLIPModel`をベースにしており、オリジナルの[CLIP](clip)と同じように使用してください。
+
+
+
+## AltCLIPConfig
+
+[[autodoc]] AltCLIPConfig
+ - from_text_vision_configs
+
+## AltCLIPTextConfig
+
+[[autodoc]] AltCLIPTextConfig
+
+## AltCLIPVisionConfig
+
+[[autodoc]] AltCLIPVisionConfig
+
+## AltCLIPProcessor
+
+[[autodoc]] AltCLIPProcessor
+
+## AltCLIPModel
+
+[[autodoc]] AltCLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## AltCLIPTextModel
+
+[[autodoc]] AltCLIPTextModel
+ - forward
+
+## AltCLIPVisionModel
+
+[[autodoc]] AltCLIPVisionModel
+ - forward
diff --git a/docs/source/ja/model_doc/audio-spectrogram-transformer.md b/docs/source/ja/model_doc/audio-spectrogram-transformer.md
new file mode 100644
index 00000000000..efbadbd4bae
--- /dev/null
+++ b/docs/source/ja/model_doc/audio-spectrogram-transformer.md
@@ -0,0 +1,69 @@
+
+
+# Audio Spectrogram Transformer
+
+## 概要
+
+Audio Spectrogram Transformerモデルは、「[AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778)」という論文でYuan Gong、Yu-An Chung、James Glassによって提案されました。これは、音声を画像(スペクトログラム)に変換することで、音声に[Vision Transformer](vit)を適用します。このモデルは音声分類において最先端の結果を得ています。
+
+論文の要旨は以下の通りです:
+
+*過去10年間で、畳み込みニューラルネットワーク(CNN)は、音声スペクトログラムから対応するラベルへの直接的なマッピングを学習することを目指す、エンドツーエンドの音声分類モデルの主要な構成要素として広く採用されてきました。長距離のグローバルなコンテキストをより良く捉えるため、最近の傾向として、CNNの上にセルフアテンション機構を追加し、CNN-アテンションハイブリッドモデルを形成することがあります。しかし、CNNへの依存が必要かどうか、そして純粋にアテンションに基づくニューラルネットワークだけで音声分類において良いパフォーマンスを得ることができるかどうかは明らかではありません。本論文では、これらの問いに答えるため、音声分類用では最初の畳み込みなしで純粋にアテンションベースのモデルであるAudio Spectrogram Transformer(AST)を紹介します。我々はASTを様々なオーディオ分類ベンチマークで評価し、AudioSetで0.485 mAP、ESC-50で95.6%の正解率、Speech Commands V2で98.1%の正解率という新たな最先端の結果を達成しました。*
+
+
+
+ Audio Spectrogram Transformerのアーキテクチャ。元論文より抜粋。
+
+このモデルは[nielsr](https://huggingface.co/nielsr)より提供されました。
+オリジナルのコードは[こちら](https://github.com/YuanGongND/ast)で見ることができます。
+
+## 使用上のヒント
+
+- 独自のデータセットでAudio Spectrogram Transformer(AST)をファインチューニングする場合、入力の正規化(入力の平均を0、標準偏差を0.5にすること)処理することが推奨されます。[`ASTFeatureExtractor`]はこれを処理します。デフォルトではAudioSetの平均と標準偏差を使用していることに注意してください。著者が下流のデータセットの統計をどのように計算しているかは、[`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py)で確認することができます。
+- ASTは低い学習率が必要であり(著者は[PSLA論文](https://arxiv.org/abs/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
+
+## 参考資料
+
+Audio Spectrogram Transformerの使用を開始するのに役立つ公式のHugging Faceおよびコミュニティ(🌎で示されている)の参考資料の一覧です。
+
+
+
+- ASTを用いた音声分類の推論を説明するノートブックは[こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/AST)で見ることができます。
+- [`ASTForAudioClassification`]は、この[例示スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification)と[ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)によってサポートされています。
+- こちらも参照:[音声分類タスク](../tasks/audio_classification)。
+
+ここに参考資料を提出したい場合は、気兼ねなくPull Requestを開いてください。私たちはそれをレビューいたします!参考資料は、既存のものを複製するのではなく、何か新しいことを示すことが理想的です。
+
+## ASTConfig
+
+[[autodoc]] ASTConfig
+
+## ASTFeatureExtractor
+
+[[autodoc]] ASTFeatureExtractor
+ - __call__
+
+## ASTModel
+
+[[autodoc]] ASTModel
+ - forward
+
+## ASTForAudioClassification
+
+[[autodoc]] ASTForAudioClassification
+ - forward
diff --git a/docs/source/ja/model_doc/auto.md b/docs/source/ja/model_doc/auto.md
new file mode 100644
index 00000000000..b104e4c99fe
--- /dev/null
+++ b/docs/source/ja/model_doc/auto.md
@@ -0,0 +1,370 @@
+
+
+# Auto Classes
+
+多くの場合、`from_pretrained()`メソッドに与えられた事前学習済みモデルの名前やパスから、使用したいアーキテクチャを推測することができます。自動クラスはこの仕事をあなたに代わって行うためにここにありますので、事前学習済みの重み/設定/語彙への名前/パスを与えると自動的に関連するモデルを取得できます。
+
+[`AutoConfig`]、[`AutoModel`]、[`AutoTokenizer`]のいずれかをインスタンス化すると、関連するアーキテクチャのクラスが直接作成されます。例えば、
+
+```python
+model = AutoModel.from_pretrained("bert-base-cased")
+```
+
+これは[`BertModel`]のインスタンスであるモデルを作成します。
+
+各タスクごと、そして各バックエンド(PyTorch、TensorFlow、またはFlax)ごとに`AutoModel`のクラスが存在します。
+
+## 自動クラスの拡張
+
+それぞれの自動クラスには、カスタムクラスで拡張するためのメソッドがあります。例えば、`NewModel`というモデルのカスタムクラスを定義した場合、`NewModelConfig`を確保しておけばこのようにして自動クラスに追加することができます:
+
+```python
+from transformers import AutoConfig, AutoModel
+
+AutoConfig.register("new-model", NewModelConfig)
+AutoModel.register(NewModelConfig, NewModel)
+```
+
+その後、通常どおりauto classesを使用することができるようになります!
+
+
+
+あなたの`NewModelConfig`が[`~transformer.PretrainedConfig`]のサブクラスである場合、その`model_type`属性がコンフィグを登録するときに使用するキー(ここでは`"new-model"`)と同じに設定されていることを確認してください。
+
+同様に、あなたの`NewModel`が[`PreTrainedModel`]のサブクラスである場合、その`config_class`属性がモデルを登録する際に使用するクラス(ここでは`NewModelConfig`)と同じに設定されていることを確認してください。
+
+
+
+## AutoConfig
+
+[[autodoc]] AutoConfig
+
+## AutoTokenizer
+
+[[autodoc]] AutoTokenizer
+
+## AutoFeatureExtractor
+
+[[autodoc]] AutoFeatureExtractor
+
+## AutoImageProcessor
+
+[[autodoc]] AutoImageProcessor
+
+## AutoProcessor
+
+[[autodoc]] AutoProcessor
+
+## Generic model classes
+
+以下の自動クラスは、特定のヘッドを持たないベースモデルクラスをインスタンス化するために利用可能です。
+
+### AutoModel
+
+[[autodoc]] AutoModel
+
+### TFAutoModel
+
+[[autodoc]] TFAutoModel
+
+### FlaxAutoModel
+
+[[autodoc]] FlaxAutoModel
+
+## Generic pretraining classes
+
+以下の自動クラスは、事前学習ヘッドを持つモデルをインスタンス化するために利用可能です。
+
+### AutoModelForPreTraining
+
+[[autodoc]] AutoModelForPreTraining
+
+### TFAutoModelForPreTraining
+
+[[autodoc]] TFAutoModelForPreTraining
+
+### FlaxAutoModelForPreTraining
+
+[[autodoc]] FlaxAutoModelForPreTraining
+
+## Natural Language Processing
+
+以下の自動クラスは、次の自然言語処理タスクに利用可能です。
+
+### AutoModelForCausalLM
+
+[[autodoc]] AutoModelForCausalLM
+
+### TFAutoModelForCausalLM
+
+[[autodoc]] TFAutoModelForCausalLM
+
+### FlaxAutoModelForCausalLM
+
+[[autodoc]] FlaxAutoModelForCausalLM
+
+### AutoModelForMaskedLM
+
+[[autodoc]] AutoModelForMaskedLM
+
+### TFAutoModelForMaskedLM
+
+[[autodoc]] TFAutoModelForMaskedLM
+
+### FlaxAutoModelForMaskedLM
+
+[[autodoc]] FlaxAutoModelForMaskedLM
+
+### AutoModelForMaskGeneration
+
+[[autodoc]] AutoModelForMaskGeneration
+
+### TFAutoModelForMaskGeneration
+
+[[autodoc]] TFAutoModelForMaskGeneration
+
+### AutoModelForSeq2SeqLM
+
+[[autodoc]] AutoModelForSeq2SeqLM
+
+### TFAutoModelForSeq2SeqLM
+
+[[autodoc]] TFAutoModelForSeq2SeqLM
+
+### FlaxAutoModelForSeq2SeqLM
+
+[[autodoc]] FlaxAutoModelForSeq2SeqLM
+
+### AutoModelForSequenceClassification
+
+[[autodoc]] AutoModelForSequenceClassification
+
+### TFAutoModelForSequenceClassification
+
+[[autodoc]] TFAutoModelForSequenceClassification
+
+### FlaxAutoModelForSequenceClassification
+
+[[autodoc]] FlaxAutoModelForSequenceClassification
+
+### AutoModelForMultipleChoice
+
+[[autodoc]] AutoModelForMultipleChoice
+
+### TFAutoModelForMultipleChoice
+
+[[autodoc]] TFAutoModelForMultipleChoice
+
+### FlaxAutoModelForMultipleChoice
+
+[[autodoc]] FlaxAutoModelForMultipleChoice
+
+### AutoModelForNextSentencePrediction
+
+[[autodoc]] AutoModelForNextSentencePrediction
+
+### TFAutoModelForNextSentencePrediction
+
+[[autodoc]] TFAutoModelForNextSentencePrediction
+
+### FlaxAutoModelForNextSentencePrediction
+
+[[autodoc]] FlaxAutoModelForNextSentencePrediction
+
+### AutoModelForTokenClassification
+
+[[autodoc]] AutoModelForTokenClassification
+
+### TFAutoModelForTokenClassification
+
+[[autodoc]] TFAutoModelForTokenClassification
+
+### FlaxAutoModelForTokenClassification
+
+[[autodoc]] FlaxAutoModelForTokenClassification
+
+### AutoModelForQuestionAnswering
+
+[[autodoc]] AutoModelForQuestionAnswering
+
+### TFAutoModelForQuestionAnswering
+
+[[autodoc]] TFAutoModelForQuestionAnswering
+
+### FlaxAutoModelForQuestionAnswering
+
+[[autodoc]] FlaxAutoModelForQuestionAnswering
+
+### AutoModelForTextEncoding
+
+[[autodoc]] AutoModelForTextEncoding
+
+### TFAutoModelForTextEncoding
+
+[[autodoc]] TFAutoModelForTextEncoding
+
+## Computer vision
+
+以下の自動クラスは、次のコンピュータービジョンタスクに利用可能です。
+
+### AutoModelForDepthEstimation
+
+[[autodoc]] AutoModelForDepthEstimation
+
+### AutoModelForImageClassification
+
+[[autodoc]] AutoModelForImageClassification
+
+### TFAutoModelForImageClassification
+
+[[autodoc]] TFAutoModelForImageClassification
+
+### FlaxAutoModelForImageClassification
+
+[[autodoc]] FlaxAutoModelForImageClassification
+
+### AutoModelForVideoClassification
+
+[[autodoc]] AutoModelForVideoClassification
+
+### AutoModelForMaskedImageModeling
+
+[[autodoc]] AutoModelForMaskedImageModeling
+
+### TFAutoModelForMaskedImageModeling
+
+[[autodoc]] TFAutoModelForMaskedImageModeling
+
+### AutoModelForObjectDetection
+
+[[autodoc]] AutoModelForObjectDetection
+
+### AutoModelForImageSegmentation
+
+[[autodoc]] AutoModelForImageSegmentation
+
+### AutoModelForImageToImage
+
+[[autodoc]] AutoModelForImageToImage
+
+### AutoModelForSemanticSegmentation
+
+[[autodoc]] AutoModelForSemanticSegmentation
+
+### TFAutoModelForSemanticSegmentation
+
+[[autodoc]] TFAutoModelForSemanticSegmentation
+
+### AutoModelForInstanceSegmentation
+
+[[autodoc]] AutoModelForInstanceSegmentation
+
+### AutoModelForUniversalSegmentation
+
+[[autodoc]] AutoModelForUniversalSegmentation
+
+### AutoModelForZeroShotImageClassification
+
+[[autodoc]] AutoModelForZeroShotImageClassification
+
+### TFAutoModelForZeroShotImageClassification
+
+[[autodoc]] TFAutoModelForZeroShotImageClassification
+
+### AutoModelForZeroShotObjectDetection
+
+[[autodoc]] AutoModelForZeroShotObjectDetection
+
+## Audio
+
+以下の自動クラスは、次の音声タスクに利用可能です。
+
+### AutoModelForAudioClassification
+
+[[autodoc]] AutoModelForAudioClassification
+
+### AutoModelForAudioFrameClassification
+
+[[autodoc]] TFAutoModelForAudioClassification
+
+### TFAutoModelForAudioFrameClassification
+
+[[autodoc]] AutoModelForAudioFrameClassification
+
+### AutoModelForCTC
+
+[[autodoc]] AutoModelForCTC
+
+### AutoModelForSpeechSeq2Seq
+
+[[autodoc]] AutoModelForSpeechSeq2Seq
+
+### TFAutoModelForSpeechSeq2Seq
+
+[[autodoc]] TFAutoModelForSpeechSeq2Seq
+
+### FlaxAutoModelForSpeechSeq2Seq
+
+[[autodoc]] FlaxAutoModelForSpeechSeq2Seq
+
+### AutoModelForAudioXVector
+
+[[autodoc]] AutoModelForAudioXVector
+
+### AutoModelForTextToSpectrogram
+
+[[autodoc]] AutoModelForTextToSpectrogram
+
+### AutoModelForTextToWaveform
+
+[[autodoc]] AutoModelForTextToWaveform
+
+## Multimodal
+
+以下の自動クラスは、次のマルチモーダルタスクに利用可能です。
+
+### AutoModelForTableQuestionAnswering
+
+[[autodoc]] AutoModelForTableQuestionAnswering
+
+### TFAutoModelForTableQuestionAnswering
+
+[[autodoc]] TFAutoModelForTableQuestionAnswering
+
+### AutoModelForDocumentQuestionAnswering
+
+[[autodoc]] AutoModelForDocumentQuestionAnswering
+
+### TFAutoModelForDocumentQuestionAnswering
+
+[[autodoc]] TFAutoModelForDocumentQuestionAnswering
+
+### AutoModelForVisualQuestionAnswering
+
+[[autodoc]] AutoModelForVisualQuestionAnswering
+
+### AutoModelForVision2Seq
+
+[[autodoc]] AutoModelForVision2Seq
+
+### TFAutoModelForVision2Seq
+
+[[autodoc]] TFAutoModelForVision2Seq
+
+### FlaxAutoModelForVision2Seq
+
+[[autodoc]] FlaxAutoModelForVision2Seq
diff --git a/docs/source/ja/model_doc/autoformer.md b/docs/source/ja/model_doc/autoformer.md
new file mode 100644
index 00000000000..b8b0948b960
--- /dev/null
+++ b/docs/source/ja/model_doc/autoformer.md
@@ -0,0 +1,50 @@
+
+
+# Autoformer
+
+## 概要
+
+Autoformerモデルは、「[Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008)」という論文でHaixu Wu、Jiehui Xu、Jianmin Wang、Mingsheng Longによって提案されました。
+
+このモデルは、予測プロセス中にトレンドと季節性成分を逐次的に分解できる深層分解アーキテクチャとしてTransformerを増強します。
+
+論文の要旨は以下の通りです:
+
+*例えば異常気象の早期警告や長期的なエネルギー消費計画といった実応用において、予測時間を延長することは重要な要求です。本論文では、時系列の長期予測問題を研究しています。以前のTransformerベースのモデルは、長距離依存関係を発見するために様々なセルフアテンション機構を採用しています。しかし、長期未来の複雑な時間的パターンによってモデルが信頼できる依存関係を見つけることを妨げられます。また、Transformerは、長い系列の効率化のためにポイントワイズなセルフアテンションのスパースバージョンを採用する必要があり、情報利用のボトルネックとなります。Transformerを超えて、我々は自己相関機構を持つ新しい分解アーキテクチャとしてAutoformerを設計しました。系列分解の事前処理の慣行を破り、それを深層モデルの基本的な内部ブロックとして革新します。この設計は、複雑な時系列に対するAutoformerの進行的な分解能力を強化します。さらに、確率過程理論に触発されて、系列の周期性に基づいた自己相関機構を設計し、サブ系列レベルでの依存関係の発見と表現の集約を行います。自己相関は効率と精度の両方でセルフアテンションを上回ります。長期予測において、Autoformerは、エネルギー、交通、経済、気象、疾病の5つの実用的な応用をカバーする6つのベンチマークで38%の相対的な改善をもたらし、最先端の精度を達成します。*
+
+このモデルは[elisim](https://huggingface.co/elisim)と[kashif](https://huggingface.co/kashif)より提供されました。
+オリジナルのコードは[こちら](https://github.com/thuml/Autoformer)で見ることができます。
+
+## 参考資料
+
+Autoformerの使用を開始するのに役立つ公式のHugging Faceおよびコミュニティ(🌎で示されている)の参考資料の一覧です。ここに参考資料を提出したい場合は、気兼ねなくPull Requestを開いてください。私たちはそれをレビューいたします!参考資料は、既存のものを複製するのではなく、何か新しいことを示すことが理想的です。
+
+- HuggingFaceブログでAutoformerに関するブログ記事をチェックしてください:[はい、Transformersは時系列予測に効果的です(+ Autoformer)](https://huggingface.co/blog/autoformer)
+
+## AutoformerConfig
+
+[[autodoc]] AutoformerConfig
+
+## AutoformerModel
+
+[[autodoc]] AutoformerModel
+ - forward
+
+## AutoformerForPrediction
+
+[[autodoc]] AutoformerForPrediction
+ - forward
- Audio pectrogram Transformer architecture. Taken from the original paper.
+ Audio Spectrogram Transformer architecture. Taken from the original paper.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/YuanGongND/ast).
@@ -72,4 +72,4 @@ If you're interested in submitting a resource to be included here, please feel f
## ASTForAudioClassification
[[autodoc]] ASTForAudioClassification
- - forward
\ No newline at end of file
+ - forward
diff --git a/docs/source/ja/_toctree.yml b/docs/source/ja/_toctree.yml
index 69169d6fffc..df686b475da 100644
--- a/docs/source/ja/_toctree.yml
+++ b/docs/source/ja/_toctree.yml
@@ -29,77 +29,12 @@
title: LLM を使用した生成
title: Tutorials
- sections:
- - isExpanded: false
- # sections:
- # - local: tasks/sequence_classification
- # title: Text classification
- # - local: tasks/token_classification
- # title: Token classification
- # - local: tasks/question_answering
- # title: Question answering
- # - local: tasks/language_modeling
- # title: Causal language modeling
- # - local: tasks/masked_language_modeling
- # title: Masked language modeling
- # - local: tasks/translation
- # title: Translation
- # - local: tasks/summarization
- # title: Summarization
- # - local: tasks/multiple_choice
- # title: Multiple choice
- # title: Natural Language Processing
- # - isExpanded: false
- # sections:
- # - local: tasks/audio_classification
- # title: Audio classification
- # - local: tasks/asr
- # title: Automatic speech recognition
- # title: Audio
- # - isExpanded: false
- # sections:
- # - local: tasks/image_classification
- # title: Image classification
- # - local: tasks/semantic_segmentation
- # title: Semantic segmentation
- # - local: tasks/video_classification
- # title: Video classification
- # - local: tasks/object_detection
- # title: Object detection
- # - local: tasks/zero_shot_object_detection
- # title: Zero-shot object detection
- # - local: tasks/zero_shot_image_classification
- # title: Zero-shot image classification
- # - local: tasks/monocular_depth_estimation
- # title: Depth estimation
- # - local: tasks/image_to_image
- # title: Image-to-Image
- # - local: tasks/knowledge_distillation_for_image_classification
- # title: Knowledge Distillation for Computer Vision
- # title: Computer Vision
- # - isExpanded: false
- # sections:
- # - local: tasks/image_captioning
- # title: Image captioning
- # - local: tasks/document_question_answering
- # title: Document Question Answering
- # - local: tasks/visual_question_answering
- # title: Visual Question Answering
- # - local: tasks/text-to-speech
- # title: Text to speech
- # title: Multimodal
- isExpanded: false
sections:
- local: generation_strategies
title: 生成戦略をカスタマイズする
title: Generation
- # - isExpanded: false
- # sections:
- # - local: tasks/idefics
- # title: Image tasks with IDEFICS
- # - local: tasks/prompting
- # title: LLM prompting guide
- # title: Prompting
- title: Task Guides
+ title: Task Guides
- sections:
- local: fast_tokenizers
title: 🤗 トークナイザーの高速トークナイザーを使用する
@@ -206,8 +141,8 @@
- sections:
- local: main_classes/agent
title: エージェントとツール
- # - local: model_doc/auto
- # title: Auto Classes
+ - local: model_doc/auto
+ title: Auto Classes
- local: main_classes/callback
title: コールバック
- local: main_classes/configuration
@@ -245,6 +180,30 @@
- local: main_classes/image_processor
title: 画像処理プロセッサ
title: 主要なクラス
+ - sections:
+ - isExpanded: false
+ sections:
+ - local: model_doc/albert
+ title: ALBERT
+ title: 文章モデル
+ - isExpanded: false
+ sections:
+ - local: model_doc/audio-spectrogram-transformer
+ title: Audio Spectrogram Transformer
+ title: 音声モデル
+ - isExpanded: false
+ sections:
+ - local: model_doc/align
+ title: ALIGN
+ - local: model_doc/altclip
+ title: AltCLIP
+ title: マルチモーダルモデル
+ - isExpanded: false
+ sections:
+ - local: model_doc/autoformer
+ title: Autoformer
+ title: 時系列モデル
+ title: モデル
- sections:
- local: internal/modeling_utils
title: カスタムレイヤーとユーティリティ
diff --git a/docs/source/ja/model_doc/albert.md b/docs/source/ja/model_doc/albert.md
new file mode 100644
index 00000000000..00403ea5376
--- /dev/null
+++ b/docs/source/ja/model_doc/albert.md
@@ -0,0 +1,193 @@
+
+
+# ALBERT
+
+
+
+## 概要
+
+ALBERTモデルは、「[ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942)」という論文でZhenzhong Lan、Mingda Chen、Sebastian Goodman、Kevin Gimpel、Piyush Sharma、Radu Soricutによって提案されました。BERTのメモリ消費を減らしトレーニングを高速化するためのパラメータ削減技術を2つ示しています:
+
+- 埋め込み行列を2つの小さな行列に分割する。
+- グループ間で分割された繰り返し層を使用する。
+
+論文の要旨は以下の通りです:
+
+*自然言語表現の事前学習時にモデルのサイズを増やすと、下流タスクのパフォーマンスが向上することがしばしばあります。しかし、ある時点でさらなるモデルの増大は、GPU/TPUのメモリ制限、長い訓練時間、予期せぬモデルの劣化といった問題のために困難になります。これらの問題に対処するために、我々はBERTのメモリ消費を低減し、訓練速度を高めるための2つのパラメータ削減技術を提案します。包括的な実証的証拠は、我々の提案方法が元のBERTに比べてはるかによくスケールするモデルを生み出すことを示しています。また、文間の一貫性をモデリングに焦点を当てた自己教師あり損失を使用し、複数の文が含まれる下流タスクに一貫して助けとなることを示します。その結果、我々の最良のモデルは、BERT-largeに比べてパラメータが少ないにもかかわらず、GLUE、RACE、SQuADベンチマークで新たな最先端の結果を確立します。*
+
+このモデルは[lysandre](https://huggingface.co/lysandre)により提供されました。このモデルのjaxバージョンは[kamalkraj](https://huggingface.co/kamalkraj)により提供されました。オリジナルのコードは[こちら](https://github.com/google-research/ALBERT)で見ることができます。
+
+## 使用上のヒント
+
+- ALBERTは絶対位置埋め込みを使用するモデルなので、通常、入力を左側ではなく右側にパディングすることが推奨されます。
+- ALBERTは繰り返し層を使用するためメモリ使用量は小さくなりますが、同じ数の(繰り返し)層を反復しなければならないため、隠れ層の数が同じであればBERTのようなアーキテクチャと同様の計算コストがかかります。
+- 埋め込みサイズEは隠れサイズHと異なりますが、これは埋め込みが文脈に依存しない(一つの埋め込みベクトルが一つのトークンを表す)のに対し、隠れ状態は文脈に依存する(1つの隠れ状態がトークン系列を表す)ため、H >> Eとすることがより論理的です。また、埋め込み行列のサイズはV x Eと大きいです(Vは語彙サイズ)。E < Hであれば、パラメータは少なくなります。
+- 層はパラメータを共有するグループに分割されています(メモリ節約のため)。次文予測(NSP: Next Sentence Prediction)は文の順序予測に置き換えられます:入力では、2つの文AとB(それらは連続している)があり、Aに続いてBを与えるか、Bに続いてAを与えます。モデルはそれらが入れ替わっているかどうかを予測する必要があります。
+
+## 参考資料
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問応答タスクガイド](../tasks/question_answering)
+- [マスクされた言語モデルタスクガイド](../tasks/masked_language_modeling)
+- [多肢選択タスクガイド](../tasks/multiple_choice)
+
+## AlbertConfig
+
+[[autodoc]] AlbertConfig
+
+## AlbertTokenizer
+
+[[autodoc]] AlbertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## AlbertTokenizerFast
+
+[[autodoc]] AlbertTokenizerFast
+
+## Albert specific outputs
+
+[[autodoc]] models.albert.modeling_albert.AlbertForPreTrainingOutput
+
+[[autodoc]] models.albert.modeling_tf_albert.TFAlbertForPreTrainingOutput
+
+
+
+
+## AlbertModel
+
+[[autodoc]] AlbertModel
+ - forward
+
+## AlbertForPreTraining
+
+[[autodoc]] AlbertForPreTraining
+ - forward
+
+## AlbertForMaskedLM
+
+[[autodoc]] AlbertForMaskedLM
+ - forward
+
+## AlbertForSequenceClassification
+
+[[autodoc]] AlbertForSequenceClassification
+ - forward
+
+## AlbertForMultipleChoice
+
+[[autodoc]] AlbertForMultipleChoice
+
+## AlbertForTokenClassification
+
+[[autodoc]] AlbertForTokenClassification
+ - forward
+
+## AlbertForQuestionAnswering
+
+[[autodoc]] AlbertForQuestionAnswering
+ - forward
+
+
+
+
+
+## TFAlbertModel
+
+[[autodoc]] TFAlbertModel
+ - call
+
+## TFAlbertForPreTraining
+
+[[autodoc]] TFAlbertForPreTraining
+ - call
+
+## TFAlbertForMaskedLM
+
+[[autodoc]] TFAlbertForMaskedLM
+ - call
+
+## TFAlbertForSequenceClassification
+
+[[autodoc]] TFAlbertForSequenceClassification
+ - call
+
+## TFAlbertForMultipleChoice
+
+[[autodoc]] TFAlbertForMultipleChoice
+ - call
+
+## TFAlbertForTokenClassification
+
+[[autodoc]] TFAlbertForTokenClassification
+ - call
+
+## TFAlbertForQuestionAnswering
+
+[[autodoc]] TFAlbertForQuestionAnswering
+ - call
+
+
+
+
+## FlaxAlbertModel
+
+[[autodoc]] FlaxAlbertModel
+ - __call__
+
+## FlaxAlbertForPreTraining
+
+[[autodoc]] FlaxAlbertForPreTraining
+ - __call__
+
+## FlaxAlbertForMaskedLM
+
+[[autodoc]] FlaxAlbertForMaskedLM
+ - __call__
+
+## FlaxAlbertForSequenceClassification
+
+[[autodoc]] FlaxAlbertForSequenceClassification
+ - __call__
+
+## FlaxAlbertForMultipleChoice
+
+[[autodoc]] FlaxAlbertForMultipleChoice
+ - __call__
+
+## FlaxAlbertForTokenClassification
+
+[[autodoc]] FlaxAlbertForTokenClassification
+ - __call__
+
+## FlaxAlbertForQuestionAnswering
+
+[[autodoc]] FlaxAlbertForQuestionAnswering
+ - __call__
+
+
+
diff --git a/docs/source/ja/model_doc/align.md b/docs/source/ja/model_doc/align.md
new file mode 100644
index 00000000000..6e62c3d9f4c
--- /dev/null
+++ b/docs/source/ja/model_doc/align.md
@@ -0,0 +1,104 @@
+
+
+# ALIGN
+
+## 概要
+
+ALIGNモデルは、「[Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918)」という論文でChao Jia、Yinfei Yang、Ye Xia、Yi-Ting Chen、Zarana Parekh、Hieu Pham、Quoc V. Le、Yunhsuan Sung、Zhen Li、Tom Duerigによって提案されました。ALIGNはマルチモーダルな視覚言語モデルです。これは画像とテキストの類似度や、ゼロショット画像分類に使用できます。ALIGNは[EfficientNet](efficientnet)を視覚エンコーダーとして、[BERT](bert)をテキストエンコーダーとして搭載したデュアルエンコーダー構造を特徴とし、対照学習によって視覚とテキストの表現を整合させることを学びます。それまでの研究とは異なり、ALIGNは巨大でノイジーなデータセットを活用し、コーパスのスケールを利用して単純な方法ながら最先端の表現を達成できることを示しています。
+
+論文の要旨は以下の通りです:
+
+*事前学習された表現は、多くの自然言語処理(NLP)および知覚タスクにとって重要になっています。NLPにおける表現学習は、人間のアノテーションのない生のテキストでの学習へと移行していますが、視覚および視覚言語の表現は依然として精巧な学習データセットに大きく依存しており、これは高価であったり専門知識を必要としたりします。視覚アプリケーションの場合、ImageNetやOpenImagesのような明示的なクラスラベルを持つデータセットを使用して学習されることがほとんどです。視覚言語の場合、Conceptual Captions、MSCOCO、CLIPなどの人気のあるデータセットはすべて、それぞれ無視できないデータ収集(およびクリーニング)プロセスを含みます。このコストのかかるキュレーションプロセスはデータセットのサイズを制限し、訓練されたモデルのスケーリングを妨げます。本論文では、Conceptual Captionsデータセットの高価なフィルタリングや後処理ステップなしで得られた、10億を超える画像alt-textペアのノイズの多いデータセットを活用します。シンプルなデュアルエンコーダーアーキテクチャは、対照損失を使用して画像とテキストペアの視覚的および言語的表現を整合させることを学習します。我々は、コーパスの規模がそのノイズを補い、このような単純な学習スキームでも最先端の表現につながることを示します。我々の視覚表現は、ImageNetやVTABなどの分類タスクへの転移において強力な性能を発揮します。整合した視覚的および言語的表現は、ゼロショット画像分類を可能にし、また、より洗練されたクロスアテンションモデルと比較しても、Flickr30KおよびMSCOCO画像テキスト検索ベンチマークにおいて新たな最先端の結果を達成します。また、これらの表現は、複雑なテキストおよびテキスト+画像のクエリを用いたクロスモーダル検索を可能にします。*
+
+このモデルは[Alara Dirik](https://huggingface.co/adirik)により提供されました。
+オリジナルのコードは公開されておらず、この実装は元論文に基づいたKakao Brainの実装をベースにしています。
+
+## 使用例
+
+ALIGNはEfficientNetを使用して視覚的特徴を、BERTを使用してテキスト特徴を取得します。テキストと視覚の両方の特徴は、同一の次元を持つ潜在空間に射影されます。射影された画像とテキスト特徴間のドット積が類似度スコアとして使用されます。
+
+[`AlignProcessor`]は、テキストのエンコードと画像の前処理を両方行うために、[`EfficientNetImageProcessor`]と[`BertTokenizer`]を単一のインスタンスにラップします。以下の例は、[`AlignProcessor`]と[`AlignModel`]を使用して画像-テキスト類似度スコアを取得する方法を示しています。
+
+```python
+import requests
+import torch
+from PIL import Image
+from transformers import AlignProcessor, AlignModel
+
+processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
+model = AlignModel.from_pretrained("kakaobrain/align-base")
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+candidate_labels = ["an image of a cat", "an image of a dog"]
+
+inputs = processor(text=candidate_labels, images=image, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+# これは画像-テキスト類似度スコア
+logits_per_image = outputs.logits_per_image
+
+# Softmaxを取ることで各ラベルの確率を得られる
+probs = logits_per_image.softmax(dim=1)
+print(probs)
+```
+
+## 参考資料
+
+ALIGNの使用を開始するのに役立つ公式のHugging Faceとコミュニティ(🌎で示されている)の参考資料の一覧です。
+
+- [ALIGNとCOYO-700Mデータセット](https://huggingface.co/blog/vit-align)に関するブログ投稿。
+- ゼロショット画像分類[デモ](https://huggingface.co/spaces/adirik/ALIGN-zero-shot-image-classification)。
+- `kakaobrain/align-base` モデルの[モデルカード](https://huggingface.co/kakaobrain/align-base)。
+
+ここに参考資料を提出したい場合は、気兼ねなくPull Requestを開いてください。私たちはそれをレビューいたします!参考資料は、既存のものを複製するのではなく、何か新しいことを示すことが理想的です。
+
+## AlignConfig
+
+[[autodoc]] AlignConfig
+ - from_text_vision_configs
+
+## AlignTextConfig
+
+[[autodoc]] AlignTextConfig
+
+## AlignVisionConfig
+
+[[autodoc]] AlignVisionConfig
+
+## AlignProcessor
+
+[[autodoc]] AlignProcessor
+
+## AlignModel
+
+[[autodoc]] AlignModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## AlignTextModel
+
+[[autodoc]] AlignTextModel
+ - forward
+
+## AlignVisionModel
+
+[[autodoc]] AlignVisionModel
+ - forward
diff --git a/docs/source/ja/model_doc/altclip.md b/docs/source/ja/model_doc/altclip.md
new file mode 100644
index 00000000000..232b3645544
--- /dev/null
+++ b/docs/source/ja/model_doc/altclip.md
@@ -0,0 +1,97 @@
+
+
+# AltCLIP
+
+## 概要
+
+
+AltCLIPモデルは、「[AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679v2)」という論文でZhongzhi Chen、Guang Liu、Bo-Wen Zhang、Fulong Ye、Qinghong Yang、Ledell Wuによって提案されました。AltCLIP(CLIPの言語エンコーダーの代替)は、様々な画像-テキストペアおよびテキスト-テキストペアでトレーニングされたニューラルネットワークです。CLIPのテキストエンコーダーを事前学習済みの多言語テキストエンコーダーXLM-Rに置き換えることで、ほぼ全てのタスクでCLIPに非常に近い性能を得られ、オリジナルのCLIPの能力を多言語理解などに拡張しました。
+
+論文の要旨は以下の通りです:
+
+*この研究では、強力なバイリンガルマルチモーダル表現モデルを訓練するための概念的に単純で効果的な方法を提案します。OpenAIによってリリースされたマルチモーダル表現モデルCLIPから開始し、そのテキストエンコーダを事前学習済みの多言語テキストエンコーダXLM-Rに交換し、教師学習と対照学習からなる2段階のトレーニングスキーマを用いて言語と画像の表現を整合させました。幅広いタスクの評価を通じて、我々の方法を検証します。ImageNet-CN、Flicker30k-CN、COCO-CNを含む多くのタスクで新たな最先端の性能を達成しました。さらに、ほぼすべてのタスクでCLIPに非常に近い性能を得ており、これはCLIPのテキストエンコーダを変更するだけで、多言語理解などの拡張を実現できることを示唆しています。*
+
+このモデルは[jongjyh](https://huggingface.co/jongjyh)により提供されました。
+
+## 使用上のヒントと使用例
+
+AltCLIPの使用方法はCLIPに非常に似ています。CLIPとの違いはテキストエンコーダーにあります。私たちはカジュアルアテンションではなく双方向アテンションを使用し、XLM-Rの[CLS]トークンをテキスト埋め込みを表すものとして取ることに留意してください。
+
+AltCLIPはマルチモーダルな視覚言語モデルです。これは画像とテキストの類似度や、ゼロショット画像分類に使用できます。AltCLIPはViTのようなTransformerを使用して視覚的特徴を、双方向言語モデルを使用してテキスト特徴を取得します。テキストと視覚の両方の特徴は、同一の次元を持つ潜在空間に射影されます。射影された画像とテキスト特徴間のドット積が類似度スコアとして使用されます。
+
+Transformerエンコーダーに画像を与えるには、各画像を固定サイズの重複しないパッチの系列に分割し、それらを線形に埋め込みます。画像全体を表現するための[CLS]トークンが追加されます。著者は絶対位置埋め込みも追加し、結果として得られるベクトルの系列を標準的なTransformerエンコーダーに供給します。[`CLIPImageProcessor`]を使用して、モデルのために画像のサイズ変更(または拡大縮小)と正規化を行うことができます。
+
+[`AltCLIPProcessor`]は、テキストのエンコードと画像の前処理を両方行うために、[`CLIPImageProcessor`]と[`XLMRobertaTokenizer`]を単一のインスタンスにラップします。以下の例は、[`AltCLIPProcessor`]と[`AltCLIPModel`]を使用して画像-テキスト類似スコアを取得する方法を示しています。
+
+```python
+>>> from PIL import Image
+>>> import requests
+
+>>> from transformers import AltCLIPModel, AltCLIPProcessor
+
+>>> model = AltCLIPModel.from_pretrained("BAAI/AltCLIP")
+>>> processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
+
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # これは画像-テキスト類似度スコア
+>>> probs = logits_per_image.softmax(dim=1) # Softmaxを取ることで各ラベルの確率を得られる
+```
+
+
+
+このモデルは`CLIPModel`をベースにしており、オリジナルの[CLIP](clip)と同じように使用してください。
+
+
+
+## AltCLIPConfig
+
+[[autodoc]] AltCLIPConfig
+ - from_text_vision_configs
+
+## AltCLIPTextConfig
+
+[[autodoc]] AltCLIPTextConfig
+
+## AltCLIPVisionConfig
+
+[[autodoc]] AltCLIPVisionConfig
+
+## AltCLIPProcessor
+
+[[autodoc]] AltCLIPProcessor
+
+## AltCLIPModel
+
+[[autodoc]] AltCLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## AltCLIPTextModel
+
+[[autodoc]] AltCLIPTextModel
+ - forward
+
+## AltCLIPVisionModel
+
+[[autodoc]] AltCLIPVisionModel
+ - forward
diff --git a/docs/source/ja/model_doc/audio-spectrogram-transformer.md b/docs/source/ja/model_doc/audio-spectrogram-transformer.md
new file mode 100644
index 00000000000..efbadbd4bae
--- /dev/null
+++ b/docs/source/ja/model_doc/audio-spectrogram-transformer.md
@@ -0,0 +1,69 @@
+
+
+# Audio Spectrogram Transformer
+
+## 概要
+
+Audio Spectrogram Transformerモデルは、「[AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778)」という論文でYuan Gong、Yu-An Chung、James Glassによって提案されました。これは、音声を画像(スペクトログラム)に変換することで、音声に[Vision Transformer](vit)を適用します。このモデルは音声分類において最先端の結果を得ています。
+
+論文の要旨は以下の通りです:
+
+*過去10年間で、畳み込みニューラルネットワーク(CNN)は、音声スペクトログラムから対応するラベルへの直接的なマッピングを学習することを目指す、エンドツーエンドの音声分類モデルの主要な構成要素として広く採用されてきました。長距離のグローバルなコンテキストをより良く捉えるため、最近の傾向として、CNNの上にセルフアテンション機構を追加し、CNN-アテンションハイブリッドモデルを形成することがあります。しかし、CNNへの依存が必要かどうか、そして純粋にアテンションに基づくニューラルネットワークだけで音声分類において良いパフォーマンスを得ることができるかどうかは明らかではありません。本論文では、これらの問いに答えるため、音声分類用では最初の畳み込みなしで純粋にアテンションベースのモデルであるAudio Spectrogram Transformer(AST)を紹介します。我々はASTを様々なオーディオ分類ベンチマークで評価し、AudioSetで0.485 mAP、ESC-50で95.6%の正解率、Speech Commands V2で98.1%の正解率という新たな最先端の結果を達成しました。*
+
+
+
+ Audio Spectrogram Transformerのアーキテクチャ。元論文より抜粋。
+
+このモデルは[nielsr](https://huggingface.co/nielsr)より提供されました。
+オリジナルのコードは[こちら](https://github.com/YuanGongND/ast)で見ることができます。
+
+## 使用上のヒント
+
+- 独自のデータセットでAudio Spectrogram Transformer(AST)をファインチューニングする場合、入力の正規化(入力の平均を0、標準偏差を0.5にすること)処理することが推奨されます。[`ASTFeatureExtractor`]はこれを処理します。デフォルトではAudioSetの平均と標準偏差を使用していることに注意してください。著者が下流のデータセットの統計をどのように計算しているかは、[`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py)で確認することができます。
+- ASTは低い学習率が必要であり(著者は[PSLA論文](https://arxiv.org/abs/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
+
+## 参考資料
+
+Audio Spectrogram Transformerの使用を開始するのに役立つ公式のHugging Faceおよびコミュニティ(🌎で示されている)の参考資料の一覧です。
+
+
+
+- ASTを用いた音声分類の推論を説明するノートブックは[こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/AST)で見ることができます。
+- [`ASTForAudioClassification`]は、この[例示スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification)と[ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)によってサポートされています。
+- こちらも参照:[音声分類タスク](../tasks/audio_classification)。
+
+ここに参考資料を提出したい場合は、気兼ねなくPull Requestを開いてください。私たちはそれをレビューいたします!参考資料は、既存のものを複製するのではなく、何か新しいことを示すことが理想的です。
+
+## ASTConfig
+
+[[autodoc]] ASTConfig
+
+## ASTFeatureExtractor
+
+[[autodoc]] ASTFeatureExtractor
+ - __call__
+
+## ASTModel
+
+[[autodoc]] ASTModel
+ - forward
+
+## ASTForAudioClassification
+
+[[autodoc]] ASTForAudioClassification
+ - forward
diff --git a/docs/source/ja/model_doc/auto.md b/docs/source/ja/model_doc/auto.md
new file mode 100644
index 00000000000..b104e4c99fe
--- /dev/null
+++ b/docs/source/ja/model_doc/auto.md
@@ -0,0 +1,370 @@
+
+
+# Auto Classes
+
+多くの場合、`from_pretrained()`メソッドに与えられた事前学習済みモデルの名前やパスから、使用したいアーキテクチャを推測することができます。自動クラスはこの仕事をあなたに代わって行うためにここにありますので、事前学習済みの重み/設定/語彙への名前/パスを与えると自動的に関連するモデルを取得できます。
+
+[`AutoConfig`]、[`AutoModel`]、[`AutoTokenizer`]のいずれかをインスタンス化すると、関連するアーキテクチャのクラスが直接作成されます。例えば、
+
+```python
+model = AutoModel.from_pretrained("bert-base-cased")
+```
+
+これは[`BertModel`]のインスタンスであるモデルを作成します。
+
+各タスクごと、そして各バックエンド(PyTorch、TensorFlow、またはFlax)ごとに`AutoModel`のクラスが存在します。
+
+## 自動クラスの拡張
+
+それぞれの自動クラスには、カスタムクラスで拡張するためのメソッドがあります。例えば、`NewModel`というモデルのカスタムクラスを定義した場合、`NewModelConfig`を確保しておけばこのようにして自動クラスに追加することができます:
+
+```python
+from transformers import AutoConfig, AutoModel
+
+AutoConfig.register("new-model", NewModelConfig)
+AutoModel.register(NewModelConfig, NewModel)
+```
+
+その後、通常どおりauto classesを使用することができるようになります!
+
+
+
+あなたの`NewModelConfig`が[`~transformer.PretrainedConfig`]のサブクラスである場合、その`model_type`属性がコンフィグを登録するときに使用するキー(ここでは`"new-model"`)と同じに設定されていることを確認してください。
+
+同様に、あなたの`NewModel`が[`PreTrainedModel`]のサブクラスである場合、その`config_class`属性がモデルを登録する際に使用するクラス(ここでは`NewModelConfig`)と同じに設定されていることを確認してください。
+
+
+
+## AutoConfig
+
+[[autodoc]] AutoConfig
+
+## AutoTokenizer
+
+[[autodoc]] AutoTokenizer
+
+## AutoFeatureExtractor
+
+[[autodoc]] AutoFeatureExtractor
+
+## AutoImageProcessor
+
+[[autodoc]] AutoImageProcessor
+
+## AutoProcessor
+
+[[autodoc]] AutoProcessor
+
+## Generic model classes
+
+以下の自動クラスは、特定のヘッドを持たないベースモデルクラスをインスタンス化するために利用可能です。
+
+### AutoModel
+
+[[autodoc]] AutoModel
+
+### TFAutoModel
+
+[[autodoc]] TFAutoModel
+
+### FlaxAutoModel
+
+[[autodoc]] FlaxAutoModel
+
+## Generic pretraining classes
+
+以下の自動クラスは、事前学習ヘッドを持つモデルをインスタンス化するために利用可能です。
+
+### AutoModelForPreTraining
+
+[[autodoc]] AutoModelForPreTraining
+
+### TFAutoModelForPreTraining
+
+[[autodoc]] TFAutoModelForPreTraining
+
+### FlaxAutoModelForPreTraining
+
+[[autodoc]] FlaxAutoModelForPreTraining
+
+## Natural Language Processing
+
+以下の自動クラスは、次の自然言語処理タスクに利用可能です。
+
+### AutoModelForCausalLM
+
+[[autodoc]] AutoModelForCausalLM
+
+### TFAutoModelForCausalLM
+
+[[autodoc]] TFAutoModelForCausalLM
+
+### FlaxAutoModelForCausalLM
+
+[[autodoc]] FlaxAutoModelForCausalLM
+
+### AutoModelForMaskedLM
+
+[[autodoc]] AutoModelForMaskedLM
+
+### TFAutoModelForMaskedLM
+
+[[autodoc]] TFAutoModelForMaskedLM
+
+### FlaxAutoModelForMaskedLM
+
+[[autodoc]] FlaxAutoModelForMaskedLM
+
+### AutoModelForMaskGeneration
+
+[[autodoc]] AutoModelForMaskGeneration
+
+### TFAutoModelForMaskGeneration
+
+[[autodoc]] TFAutoModelForMaskGeneration
+
+### AutoModelForSeq2SeqLM
+
+[[autodoc]] AutoModelForSeq2SeqLM
+
+### TFAutoModelForSeq2SeqLM
+
+[[autodoc]] TFAutoModelForSeq2SeqLM
+
+### FlaxAutoModelForSeq2SeqLM
+
+[[autodoc]] FlaxAutoModelForSeq2SeqLM
+
+### AutoModelForSequenceClassification
+
+[[autodoc]] AutoModelForSequenceClassification
+
+### TFAutoModelForSequenceClassification
+
+[[autodoc]] TFAutoModelForSequenceClassification
+
+### FlaxAutoModelForSequenceClassification
+
+[[autodoc]] FlaxAutoModelForSequenceClassification
+
+### AutoModelForMultipleChoice
+
+[[autodoc]] AutoModelForMultipleChoice
+
+### TFAutoModelForMultipleChoice
+
+[[autodoc]] TFAutoModelForMultipleChoice
+
+### FlaxAutoModelForMultipleChoice
+
+[[autodoc]] FlaxAutoModelForMultipleChoice
+
+### AutoModelForNextSentencePrediction
+
+[[autodoc]] AutoModelForNextSentencePrediction
+
+### TFAutoModelForNextSentencePrediction
+
+[[autodoc]] TFAutoModelForNextSentencePrediction
+
+### FlaxAutoModelForNextSentencePrediction
+
+[[autodoc]] FlaxAutoModelForNextSentencePrediction
+
+### AutoModelForTokenClassification
+
+[[autodoc]] AutoModelForTokenClassification
+
+### TFAutoModelForTokenClassification
+
+[[autodoc]] TFAutoModelForTokenClassification
+
+### FlaxAutoModelForTokenClassification
+
+[[autodoc]] FlaxAutoModelForTokenClassification
+
+### AutoModelForQuestionAnswering
+
+[[autodoc]] AutoModelForQuestionAnswering
+
+### TFAutoModelForQuestionAnswering
+
+[[autodoc]] TFAutoModelForQuestionAnswering
+
+### FlaxAutoModelForQuestionAnswering
+
+[[autodoc]] FlaxAutoModelForQuestionAnswering
+
+### AutoModelForTextEncoding
+
+[[autodoc]] AutoModelForTextEncoding
+
+### TFAutoModelForTextEncoding
+
+[[autodoc]] TFAutoModelForTextEncoding
+
+## Computer vision
+
+以下の自動クラスは、次のコンピュータービジョンタスクに利用可能です。
+
+### AutoModelForDepthEstimation
+
+[[autodoc]] AutoModelForDepthEstimation
+
+### AutoModelForImageClassification
+
+[[autodoc]] AutoModelForImageClassification
+
+### TFAutoModelForImageClassification
+
+[[autodoc]] TFAutoModelForImageClassification
+
+### FlaxAutoModelForImageClassification
+
+[[autodoc]] FlaxAutoModelForImageClassification
+
+### AutoModelForVideoClassification
+
+[[autodoc]] AutoModelForVideoClassification
+
+### AutoModelForMaskedImageModeling
+
+[[autodoc]] AutoModelForMaskedImageModeling
+
+### TFAutoModelForMaskedImageModeling
+
+[[autodoc]] TFAutoModelForMaskedImageModeling
+
+### AutoModelForObjectDetection
+
+[[autodoc]] AutoModelForObjectDetection
+
+### AutoModelForImageSegmentation
+
+[[autodoc]] AutoModelForImageSegmentation
+
+### AutoModelForImageToImage
+
+[[autodoc]] AutoModelForImageToImage
+
+### AutoModelForSemanticSegmentation
+
+[[autodoc]] AutoModelForSemanticSegmentation
+
+### TFAutoModelForSemanticSegmentation
+
+[[autodoc]] TFAutoModelForSemanticSegmentation
+
+### AutoModelForInstanceSegmentation
+
+[[autodoc]] AutoModelForInstanceSegmentation
+
+### AutoModelForUniversalSegmentation
+
+[[autodoc]] AutoModelForUniversalSegmentation
+
+### AutoModelForZeroShotImageClassification
+
+[[autodoc]] AutoModelForZeroShotImageClassification
+
+### TFAutoModelForZeroShotImageClassification
+
+[[autodoc]] TFAutoModelForZeroShotImageClassification
+
+### AutoModelForZeroShotObjectDetection
+
+[[autodoc]] AutoModelForZeroShotObjectDetection
+
+## Audio
+
+以下の自動クラスは、次の音声タスクに利用可能です。
+
+### AutoModelForAudioClassification
+
+[[autodoc]] AutoModelForAudioClassification
+
+### AutoModelForAudioFrameClassification
+
+[[autodoc]] TFAutoModelForAudioClassification
+
+### TFAutoModelForAudioFrameClassification
+
+[[autodoc]] AutoModelForAudioFrameClassification
+
+### AutoModelForCTC
+
+[[autodoc]] AutoModelForCTC
+
+### AutoModelForSpeechSeq2Seq
+
+[[autodoc]] AutoModelForSpeechSeq2Seq
+
+### TFAutoModelForSpeechSeq2Seq
+
+[[autodoc]] TFAutoModelForSpeechSeq2Seq
+
+### FlaxAutoModelForSpeechSeq2Seq
+
+[[autodoc]] FlaxAutoModelForSpeechSeq2Seq
+
+### AutoModelForAudioXVector
+
+[[autodoc]] AutoModelForAudioXVector
+
+### AutoModelForTextToSpectrogram
+
+[[autodoc]] AutoModelForTextToSpectrogram
+
+### AutoModelForTextToWaveform
+
+[[autodoc]] AutoModelForTextToWaveform
+
+## Multimodal
+
+以下の自動クラスは、次のマルチモーダルタスクに利用可能です。
+
+### AutoModelForTableQuestionAnswering
+
+[[autodoc]] AutoModelForTableQuestionAnswering
+
+### TFAutoModelForTableQuestionAnswering
+
+[[autodoc]] TFAutoModelForTableQuestionAnswering
+
+### AutoModelForDocumentQuestionAnswering
+
+[[autodoc]] AutoModelForDocumentQuestionAnswering
+
+### TFAutoModelForDocumentQuestionAnswering
+
+[[autodoc]] TFAutoModelForDocumentQuestionAnswering
+
+### AutoModelForVisualQuestionAnswering
+
+[[autodoc]] AutoModelForVisualQuestionAnswering
+
+### AutoModelForVision2Seq
+
+[[autodoc]] AutoModelForVision2Seq
+
+### TFAutoModelForVision2Seq
+
+[[autodoc]] TFAutoModelForVision2Seq
+
+### FlaxAutoModelForVision2Seq
+
+[[autodoc]] FlaxAutoModelForVision2Seq
diff --git a/docs/source/ja/model_doc/autoformer.md b/docs/source/ja/model_doc/autoformer.md
new file mode 100644
index 00000000000..b8b0948b960
--- /dev/null
+++ b/docs/source/ja/model_doc/autoformer.md
@@ -0,0 +1,50 @@
+
+
+# Autoformer
+
+## 概要
+
+Autoformerモデルは、「[Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008)」という論文でHaixu Wu、Jiehui Xu、Jianmin Wang、Mingsheng Longによって提案されました。
+
+このモデルは、予測プロセス中にトレンドと季節性成分を逐次的に分解できる深層分解アーキテクチャとしてTransformerを増強します。
+
+論文の要旨は以下の通りです:
+
+*例えば異常気象の早期警告や長期的なエネルギー消費計画といった実応用において、予測時間を延長することは重要な要求です。本論文では、時系列の長期予測問題を研究しています。以前のTransformerベースのモデルは、長距離依存関係を発見するために様々なセルフアテンション機構を採用しています。しかし、長期未来の複雑な時間的パターンによってモデルが信頼できる依存関係を見つけることを妨げられます。また、Transformerは、長い系列の効率化のためにポイントワイズなセルフアテンションのスパースバージョンを採用する必要があり、情報利用のボトルネックとなります。Transformerを超えて、我々は自己相関機構を持つ新しい分解アーキテクチャとしてAutoformerを設計しました。系列分解の事前処理の慣行を破り、それを深層モデルの基本的な内部ブロックとして革新します。この設計は、複雑な時系列に対するAutoformerの進行的な分解能力を強化します。さらに、確率過程理論に触発されて、系列の周期性に基づいた自己相関機構を設計し、サブ系列レベルでの依存関係の発見と表現の集約を行います。自己相関は効率と精度の両方でセルフアテンションを上回ります。長期予測において、Autoformerは、エネルギー、交通、経済、気象、疾病の5つの実用的な応用をカバーする6つのベンチマークで38%の相対的な改善をもたらし、最先端の精度を達成します。*
+
+このモデルは[elisim](https://huggingface.co/elisim)と[kashif](https://huggingface.co/kashif)より提供されました。
+オリジナルのコードは[こちら](https://github.com/thuml/Autoformer)で見ることができます。
+
+## 参考資料
+
+Autoformerの使用を開始するのに役立つ公式のHugging Faceおよびコミュニティ(🌎で示されている)の参考資料の一覧です。ここに参考資料を提出したい場合は、気兼ねなくPull Requestを開いてください。私たちはそれをレビューいたします!参考資料は、既存のものを複製するのではなく、何か新しいことを示すことが理想的です。
+
+- HuggingFaceブログでAutoformerに関するブログ記事をチェックしてください:[はい、Transformersは時系列予測に効果的です(+ Autoformer)](https://huggingface.co/blog/autoformer)
+
+## AutoformerConfig
+
+[[autodoc]] AutoformerConfig
+
+## AutoformerModel
+
+[[autodoc]] AutoformerModel
+ - forward
+
+## AutoformerForPrediction
+
+[[autodoc]] AutoformerForPrediction
+ - forward