diff --git a/docs/source/en/model_doc/opt.md b/docs/source/en/model_doc/opt.md
index 68da201f99b..3da7b22fab7 100644
--- a/docs/source/en/model_doc/opt.md
+++ b/docs/source/en/model_doc/opt.md
@@ -62,6 +62,55 @@ The resource should ideally demonstrate something new instead of duplicating an
- A blog post on [How 🤗 Accelerate runs very large models thanks to PyTorch](https://huggingface.co/blog/accelerate-large-models) with OPT.
+
+## Combining OPT and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import OPTForCausalLM, GPT2Tokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, use_flash_attention_2=True)
+>>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
+
+>>> prompt = ("A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the "
+ "Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived "
+ "there?")
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
+>>> tokenizer.batch_decode(generated_ids)[0]
+'A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived there?\nStatue: I have lived here for about a year.\nHuman: What is your favorite place to eat?\nStatue: I love'
+```
+
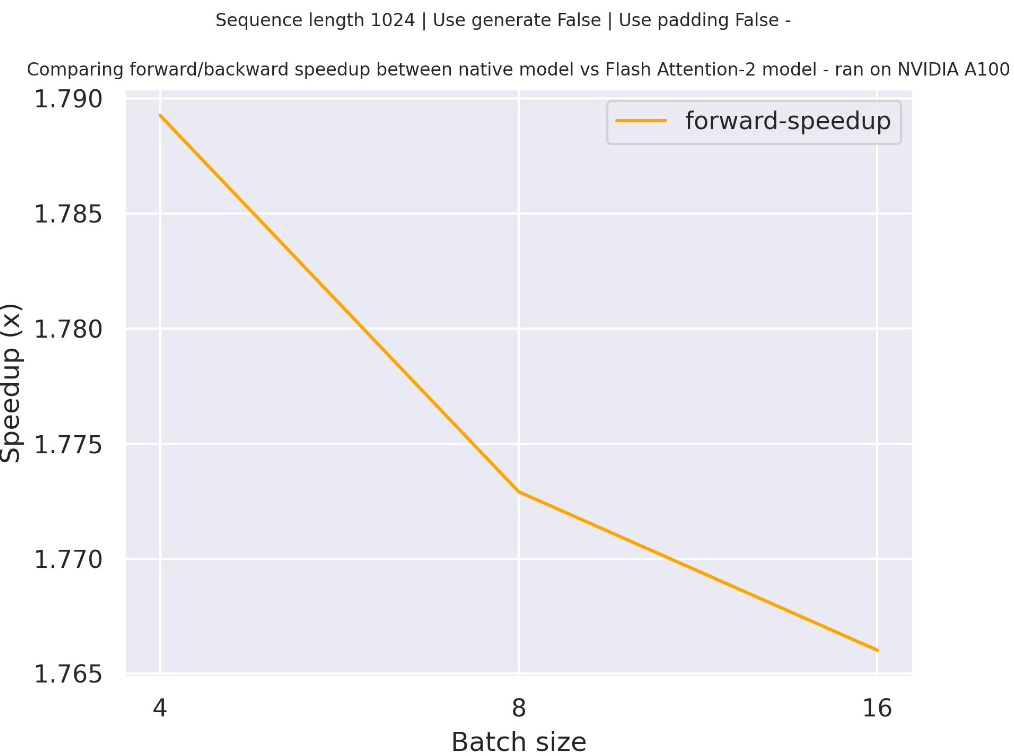
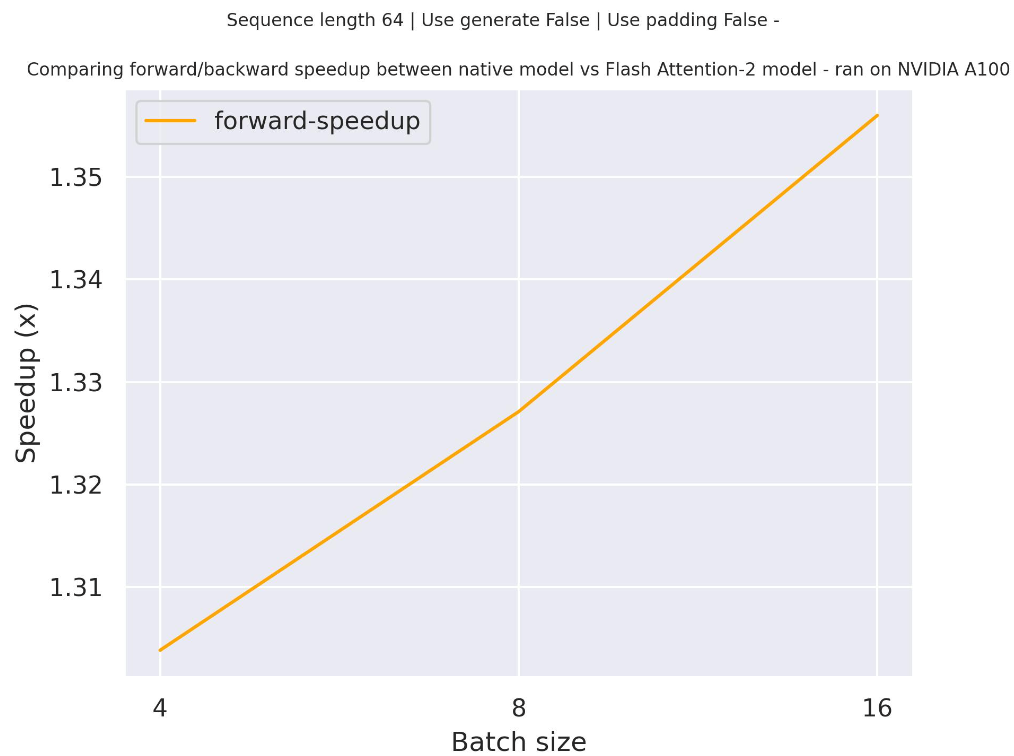
+### Expected speedups
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `facebook/opt-2.7b` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
+
+
+
+
+
+